答案一个字一个字蹦出来流式生成的完整链路
开篇引言
上一篇把 Prompt 组装的全过程拆完了——RAGPromptService.buildStructuredMessages() 根据场景(KB_ONLY / MCP_ONLY / MIXED)选模板,把 System Prompt、对话历史、检索证据、用户问题按固定骨架拼成一个 messages 数组,再加上 temperature、topP、是否开启深度思考,封装成一个 ChatRequest。
到这一步,所有调用参数都就位了。但把 ChatRequest 发给大模型,不是一个简单的 HTTP 请求-响应——大模型不会一口气把答案全吐出来,而是一个 token 一个 token 地往外蹦。这些 token 要穿过好几层,才能最终到达用户的浏览器。
打个比方,这有点像快递的中转流程。你在网上下了单(发出请求),商家一件一件地打包(模型逐 token 生成),然后包裹经过分拣中心、中转站、末端网点(各层处理),最后一件一件送到你家门口(浏览器渲染)。每一层只管自己那段路,接力完成整个投递。
Ragent 的流式生成也是这样,从 Controller 到大模型再到浏览器,中间经过五层接力。本篇就把这条链路从头到尾拆开讲。
全景图:五层接力
1. 一张图看全链路
先上一张时序图,把流式生成的完整数据流画出来。从用户发起请求,到 token 一个个蹦到浏览器,中间经过了哪些参与者、发生了哪些关键事件,一目了然:
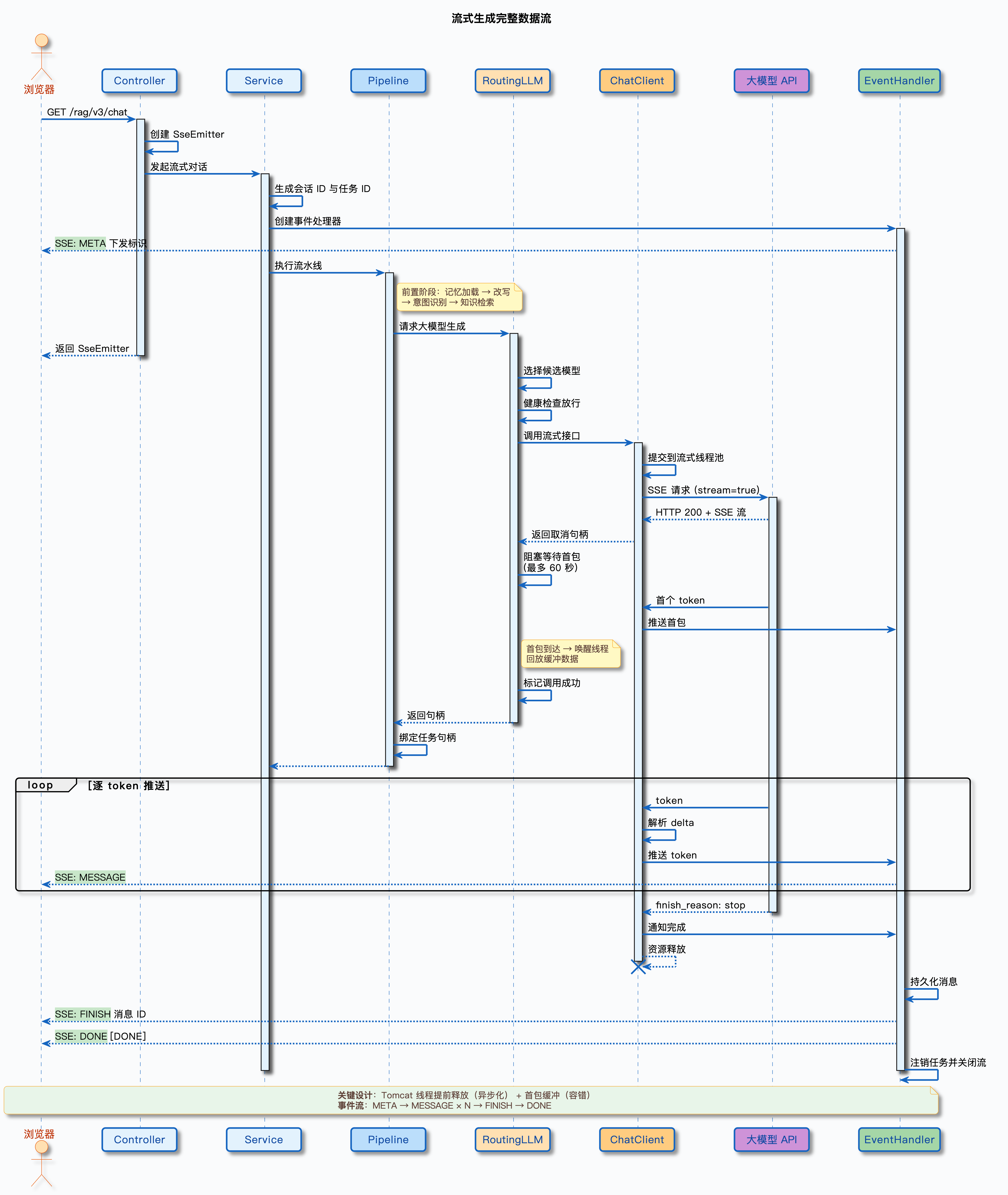
2. 五层各自负责什么
整条链路分为五层,每层职责清晰,通过 StreamCallback 接口串联:
| 层次 | 关键类 | 职责 | 输入 → 输出 |
|---|---|---|---|
| 入口层 | RAGChatController / RAGChatServiceImpl | 创建 SSE 连接、生成 ID、创建回调实例 | HTTP 请求 → SseEmitter + StreamChatContext |
| 流水线层 | StreamChatPipeline | 前置阶段 + 组装 Prompt + 调 LLM | StreamChatContext → ChatRequest |
| 调度层 | RoutingLLMService / ProbeStreamBridge / ModelHealthStore | 选模型、首包探测、容错切换、断路器 | ChatRequest → 确定可用模型并启动流式调用 |
| 客户端层 | AbstractOpenAIStyleChatClient / OpenAIStyleSseParser | OkHttp 读流、SSE 解析、delta 提取、触发回调 | HTTP SSE 流 → StreamCallback 回调 |
| 推送层 | StreamChatEventHandler / SseEmitterSender | 缓冲分块、SSE 推送、消息持久化、连接关闭 | 回调事件 → 浏览器 SSE 事件 |
这五层的串联方式很朴素——StreamCallback 接口只有四个方法:
public interface StreamCallback {
void onContent(String content);
default void onThinking(String content) {
}
void onComplete();
void onError(Throwable error);
}
onContent(String):正式回答的增量内容,模型吐一段就回调一次onThinking(String):深度思考模式下的思考过程,和回答内容分开传输,默认空实现onComplete():整个推理完成,触发持久化、发事件、关连接onError(Throwable):出错了,通知前端、释放资源
客户端层读到 token 后调 onContent(),推送层在 onContent() 里把 token 推到浏览器——中间不需要队列、不需要消息总线,一个接口方法调用就完成了层与层的衔接。
第一层:入口——从 HTTP 请求到 SSE 连接
1. Controller 创建 SseEmitter
@GetMapping(value = "/rag/v3/chat", produces = "text/event-stream;charset=UTF-8")
public SseEmitter chat(@RequestParam String question,
@RequestParam(required = false) String conversationId,
@RequestParam(required = false, defaultValue = "false") Boolean deepThinking) {
SseEmitter emitter = new SseEmitter(ragDefaultProperties.getSseTimeoutMs());
ragChatService.streamChat(question, conversationId, deepThinking, emitter);
return emitter;
}
三个要点:
produces = "text/event-stream;charset=UTF-8"告诉 Spring 这是一个 SSE 端点,响应头会自动带上Content-Type: text/event-streamSseEmitter的超时时间从配置读取,SSE 系列讲过它的核心 API,这里不再展开@IdempotentSubmit注解做了幂等保护——同一用户不能同时发起多个对话
Controller 方法的线程模型很关键:创建 SseEmitter → 交给 Service 处理 → 立即返回。Tomcat 线程在这里就释放了,不会被长时间占用。后续的流式推送发生在别的线程上,这个后面会详细讲。
2. Service 组装上下文
@Override
@ChatRateLimit
public void streamChat(String question, String conversationId, Boolean deepThinking, SseEmitter emitter) {
String actualConversationId = StrUtil.isBlank(conversationId) ? IdUtil.getSnowflakeNextIdStr() : conversationId;
String taskId = StrUtil.isBlank(RagTraceContext.getTaskId())
? IdUtil.getSnowflakeNextIdStr()
: RagTraceContext.getTaskId();
boolean thinkingEnabled = Boolean.TRUE.equals(deepThinking);
StreamCallback callback = callbackFactory.createChatEventHandler(emitter, actualConversationId, taskId);
StreamChatContext ctx = StreamChatContext.builder()
.question(question)
.conversationId(actualConversationId)
.taskId(taskId)
.deepThinking(thinkingEnabled)
.userId(UserContext.getUserId())
.callback(callback)
.build();
try {
chatPipeline.execute(ctx);
} catch (Exception e) {
callback.onError(e);
}
}
这段代码做了四件事:
生成 ID:conversationId 如果前端没传就用 Snowflake 生成一个新的,taskId 优先从 Trace 上下文拿,拿不到再生成。这两个 ID 贯穿整条链路——conversationId 标识一轮对话,taskId 标识一次生成任务。
创建回调实例:StreamCallbackFactory.createChatEventHandler() 把 SseEmitter、两个 ID、以及一堆服务依赖打包传给 StreamChatEventHandler。这个 handler 就是贯穿整条链路的回调实例——从模型调度层到客户端层到推送层,用的都是同一个对象。
public StreamCallback createChatEventHandler(SseEmitter emitter,
String conversationId,
String taskId) {
StreamChatHandlerParams params = StreamChatHandlerParams.builder()
.emitter(emitter)
.conversationId(conversationId)
.taskId(taskId)
.modelProperties(modelProperties)
.memoryService(memoryService)
.conversationGroupService(conversationGroupService)
.taskManager(taskManager)
.build();
return new StreamChatEventHandler(params);
}
构建上下文:把问题、ID、用户信息、回调实例封装成 StreamChatContext,交给流水线。
异常兜底:外层 try-catch 包住了整个 pipeline.execute()。流水线的任何阶段抛异常——检索超时、模型调用失败、Prompt 模板渲��染出错——都会被这里兜住,通过 callback.onError() 通知前端。
第二层:流水线——Prompt 拼好,调 LLM
1. streamRagResponse 发起流式调用
流水线的前七个阶段(记忆加载、改写、意图识别、检索等)在前面的系列里已经讲完了。本篇聚焦第八个阶段——streamRagResponse(),也就是 Prompt 拼好之后的事情。
private void streamRagResponse(StreamChatContext ctx, RetrievalContext retrievalCtx) {
IntentGroup mergedGroup = intentResolver.mergeIntentGroup(ctx.getSubIntents());
StreamCancellationHandle handle = streamLLMResponse(
ctx.getRewriteResult(),
retrievalCtx,
mergedGroup,
ctx.getHistory(),
ctx.isDeepThinking(),
ctx.getCallback()
);
taskManager.bindHandle(ctx.getTaskId(), handle);
}
streamLLMResponse() 里面做了两件事:第一,调上一篇讲的 promptBuilder.buildStructuredMessages() 拼消息数组、构建 ChatRequest;第二,调 llmService.streamChat(chatRequest, callback) 发起流式调用:
private StreamCancellationHandle streamLLMResponse(RewriteResult rewriteResult, RetrievalContext ctx,
IntentGroup intentGroup, List<ChatMessage> history,
boolean deepThinking, StreamCallback callback) {
PromptContext promptContext = PromptContext.builder()
.question(rewriteResult.rewrittenQuestion())
.mcpContext(ctx.getMcpContext())
.kbContext(ctx.getKbContext())
.mcpIntents(intentGroup.mcpIntents())
.kbIntents(intentGroup.kbIntents())
.intentChunks(ctx.getIntentChunks())
.build();
List<ChatMessage> messages = promptBuilder.buildStructuredMessages(
promptContext, history,
rewriteResult.rewrittenQuestion(),
rewriteResult.subQuestions()
);
ChatRequest chatRequest = ChatRequest.builder()
.messages(messages)
.thinking(deepThinking)
.temperature(ctx.hasMcp() ? 0.3D : 0D)
.topP(ctx.hasMcp() ? 0.8D : 1D)
.build();
return llmService.streamChat(chatRequest, callback);
}
注意返回值�——streamChat() 返回一个 StreamCancellationHandle,也就是取消句柄。拿到句柄后,streamRagResponse() 立即通过 taskManager.bindHandle() 把它绑定到当前任务。