Ragent AI 系统概述
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
集 RAG、Agent、MCP、RAGAS+ 等多种前沿 AI 技术于一体的企业级智能系统,基于 Spring Boot 构建,集成主流向量数据库,提供 智能问答、知识库管理、会话记忆、深度思考、基础架构 等核心能力。
不止于功能堆叠,更聚焦企业级 AI 落地真实难点——通过 标准化数据集测评 与 全链路生产指标监控,让 AI 落地效果 可观测、可衡量、可优化。生产落地智能体会踩的坑,这里都有对应方案,面试写进简历聊得起来。
🤝 贡献
Ragent AI 仍在持续迭代中,欢迎参与共建,一起把项目打磨得更好。 感谢各位亦菲、彦祖们对 Ragent AI 的贡献:
为什么学习 AI 项目
AI 这波浪潮,Java 程序员已经躲不过去了。
不管你现在做的是业务系统还是中间件,面试的时候多多少少都会被问到 AI 相关的东西。RAG 是什么?Agent 怎么实现?用过 MCP 吗?这些问题越来越高频。可以说,AI 已经从加分项变成了必答题。
但说实话,对于大多数应用层的开发者来说,去死磕大模型的微调、蒸馏、Transformer 原理,性价比并不高。真正实用的,是掌握 RAG 和 Agent 这些应用层的东西——能落地、能出活、面试也能聊得起来。
1. 校招现状
简历上清一色的 CRUD 项目——商城、外卖、博客,面试官早就审美疲劳了。当别人还在写基于 SpringBoot 的 XX 管理系统时,你简历上有一个完整的 AI 项目,区分度直接拉满。而且大厂校招越来越看重候选人对新技术的敏感度,AI 项目能直接证明你的学习能力和技术视野。
2. 社招现状
2024 年以来,几乎所有技术团队都在往 AI 方向靠。很多公司已经把有 AI 相关经验写进了 JD 里。你可能 Java/Go 写得很溜,但面试官会问:你对 LLM 了解多少?RAG 做过没有?向量检索怎么实现的?答不上来,直接少了一个谈薪的筹码。
说白了,学 AI 项目的核心原因就三个:
- 简历差异化。同样是后端开发,有 AI 项目经验的简历通过率明显更高。不是因为 AI 多神奇,而是它能证明你不只是在重复造轮子。
- 面试有东西聊。AI 项目涉及的技术栈足够深——Embedding、向量数据库、Prompt 工程、模型调用链路、检索策略……每一个点都能展开聊,比我用了 Redis 做缓存有意思得多。
- 实际工作用得上。AI 不是实验室里的玩具,企业已经在大规模落地了。现在学,是为了接下来三到五年的职业发展铺路。
3. 问题是,怎么学?
很多人跟着 B 站视频或者 GitHub 上的开源项目撸了一遍,以为自己懂了。结果面试一问深的,直接懵了。原因很简单:那些 Demo 级别的项目,和企业真正要用的东西,差距太大了。
还有些同学报了训练营,发现清一色是 Python。语言不熟、生态不通,学完感觉收获有限,回到 Java 这边还是不知道怎么下手。就算用 Spring AI 或者 LangChain4j,版本迭代太快,低版本功能缺,高版本升级约等于重写,也是一肚子苦水。
基于这些问题,我决定做一个 RAG 实战项目,名字叫 Ragent。
这个项目会覆盖市面上主流的 RAG 技术点,也会涉及 MCP、Agent 等场景。更重要的是,它不是我看了几篇文章拼凑出来的玩具——我在公司实际落地过 RAG 系统,解决过信息孤岛、知识检索、效率提升这些真实的业务问题。所以 Ragent 的复杂度,就是企业级项目该有的复杂度。
学完之后,你可以放心大胆地跟面试官讲:企业里就是这么做的。
项目开源地址
之前做拿个 offer 社群时,第一个业务系统 12306 选择了开源,收获了 1.5w+ Star,也得到了很多同学的认可和信任。这次 Ragent 作为社群在 AI 领域的第一个项目,同样选择开源——既然代码质量经得起检验,就没必要藏着掖着。
之所以选择开源,原因很简单:对项目质量足够自信。架构设计、代码实现、工程规范,每一行都经得起审视。不藏着掖着,好不好你 clone 下来自己看——目录结构、提交记录、注释规范,全是明牌。
市面上不少项目只敢放几张截图、讲几个概念,真正敢把代码全部摊开的并不多。Ragent 敢这么做,是因为前面讲的那些能力——多路检索、意图识别、模型容错、全链路追踪——不是 PPT 里的架构图,是你能跑起来、能断点调试、能逐行阅读的真实代码。
开源对你来说意味着什么:
- 源码即文档:想了解某个模块怎么实现的,直接翻代码,比任何教程都准确、都及时。
- 本地可调试:断点打到任意一行,跟着一次请求走完整个 RAG 链路,比看架构图理解得深十倍。
- 可参与贡献:发现 Bug 提 Issue,有优化思路提 PR。参与一个企业级 AI 开源项目,本身就是简历上的亮点。
- 持续迭代更新:项目会持续演进,Star 和 Watch 之后能第一时间获取新特性。
如果你觉得项目还不错,去 GitHub 点个 Star 支持一下,这是对开源作者最好的认可。
RAG 常见误区
市面上打着 RAG 旗号的项目不少,但很多要么是玩具级 Demo,要么是概念包装。在学之前,先把这几个误区理清楚,避免踩坑。
1. 调个 API 就算会 RAG 了
很多教程的套路是:调一下 OpenAI 的 Embedding 接口,往向量数据库里塞点数据,再用 LLM 生成答案——完事了。这顶多算跑通了一个 Demo,离会 RAG 差得远。
真正的 RAG 系统要考虑的问题多得多:文档怎么切分效果最好?检索召回率不够怎么办?多路召回怎么融合排序?幻觉怎么控制?这些才是面试官会追问的点。
跑通 Demo 和做出能上线的系统之间,差的不是代码量,是对每个环节的深入理解。
2. RAG 就是“检索 + 生成”两步走
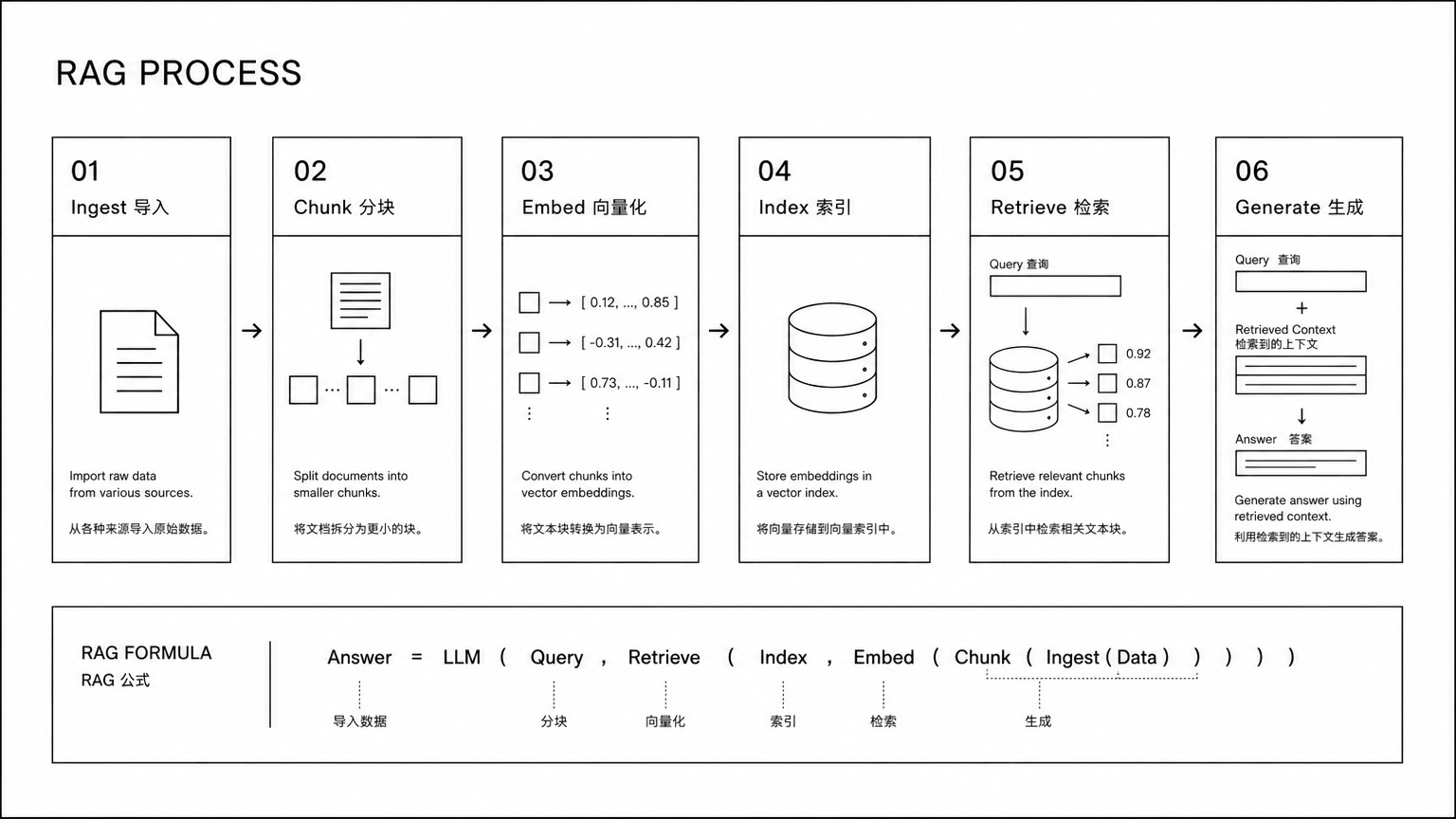
Retrieval-Augmented Generation 这个名字确实容易让人觉得就是检索加生成。但实际工程中,一个能用的 RAG 系统至少涉及这些环节:
- 数据处理:PDF、Word、PPT、网页,格式五花八门,光是解析成干净文本就是一堆脏活。PDF 里的表格、扫描件、双栏排版,每一个都是坑。
- 分块策略:切太大检索不精准,切太小上下文丢失。按段落切、按固定字数切、按语义切,不同文档可能需要不同策略。
- 问题重写:用户问�“报销咋整”,你拿这四个字去检索,效果能好吗?多轮对话里用户说“怎么申请”,不补上下文系统根本不知道在问啥。
- 意图识别:用户是想查知识库,还是要调用业务系统?是闲聊还是正经提问?走错了路,答案肯定不对。
- 检索策略:纯向量检索对精确匹配很弱,用户问一个订单号,向量检索可能完全找不到。混合检索怎么融合、top-k 选多少、要不要重排序,都是取舍。
- 会话记忆:20 轮对话全塞给模型?Token 成本扛不住。只带最近几轮?可能丢关键上下文。记忆的压缩、摘要、持久化,又是一套单独的机制。
每一环都有坑,每一环都值得深挖。面试的时候能把这些讲清楚,比背概念有用得多。
3. 用 OpenAI/LangChain 套一套就是企业级
OpenAI/LangChain 是个好工具,但直接拿来套壳不等于企业级。企业场景下要面对的是:
- 大规模文档的增量更新,不可能每次全量重建索引
- 多租户隔离和权限控制,不同部门看到的知识库不一样
- 高并发下的检索性能,模型调用的成本控制和容错
- 请求风控,防止用户套取敏感信息或恶意攻击
- 模型负载均衡,多供应商切换和降级策略
- 可观测性,效果监控和用户反馈收集
这些问题 OpenAI/LangChain 的 QuickStart 不会告诉你,但面试官和实际业务一定会考你。
4. ��只关注模型,忽略工程能力
RAG 项目的核心竞争力不在于你用了多强的模型,而在于工程化能力。同样的模型,检索策略不同、Prompt 设计不同、分块粒度不同,最终效果可以天差地别。
举个例子:用户问“打印机墨盒怎么换”,文档里写的是“墨盒更换步骤”。关键词搜索直接匹配不上,但向量检索能理解它们是一回事。这背后是 Embedding 模型的选型、向量数据库的调优、检索结果的重排序——每一步都是工程决策,不是换个更贵的模型就能解决的。
面试中能把这些工程细节讲清楚的人,远比只会说“我用了 GPT-4”的人有说服力。
Ragent 核心设计
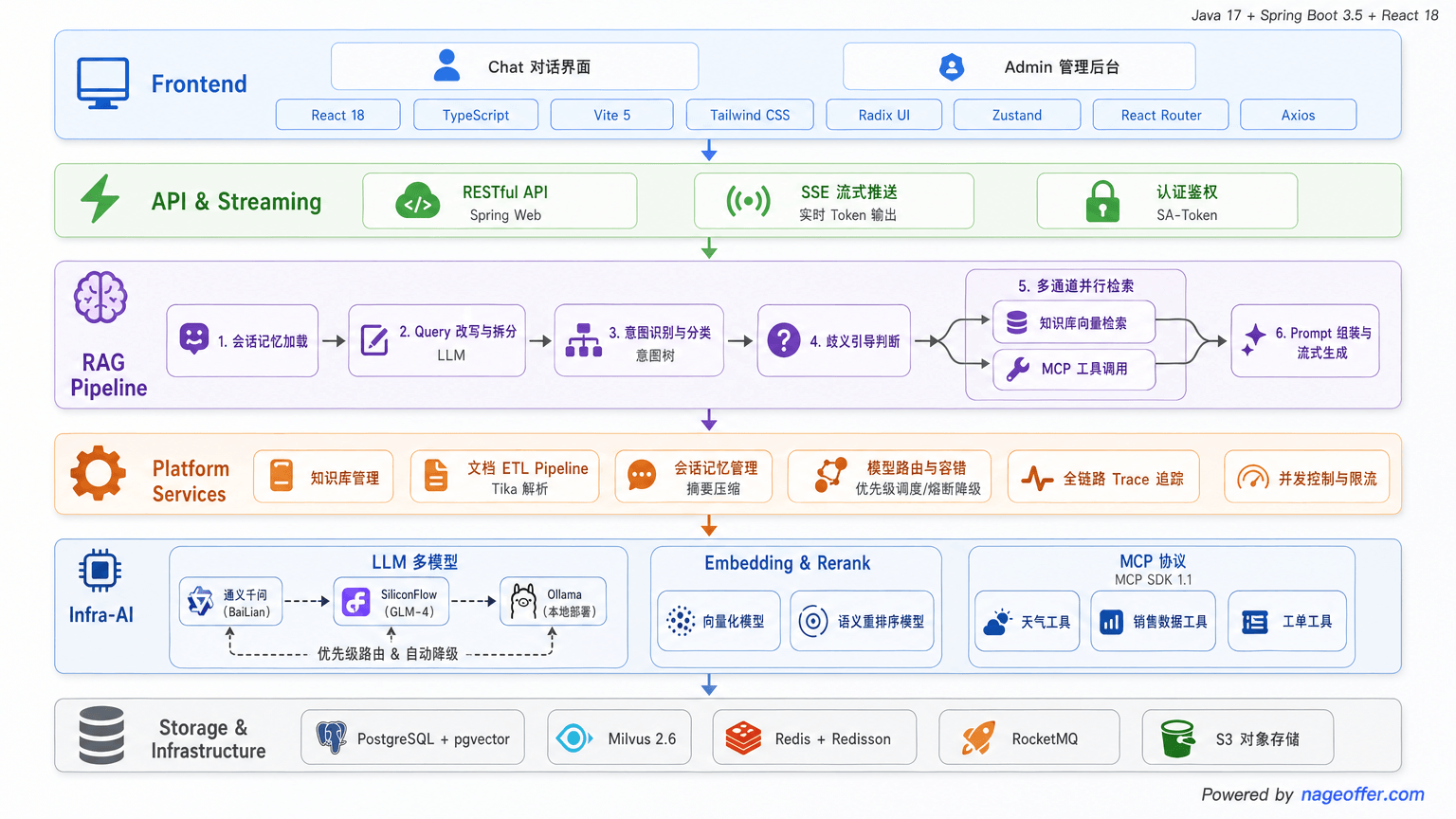
1. 技术架构
Ragent 采用前后端分离的单体架构,后端按职责分为四个 Maven 模块:
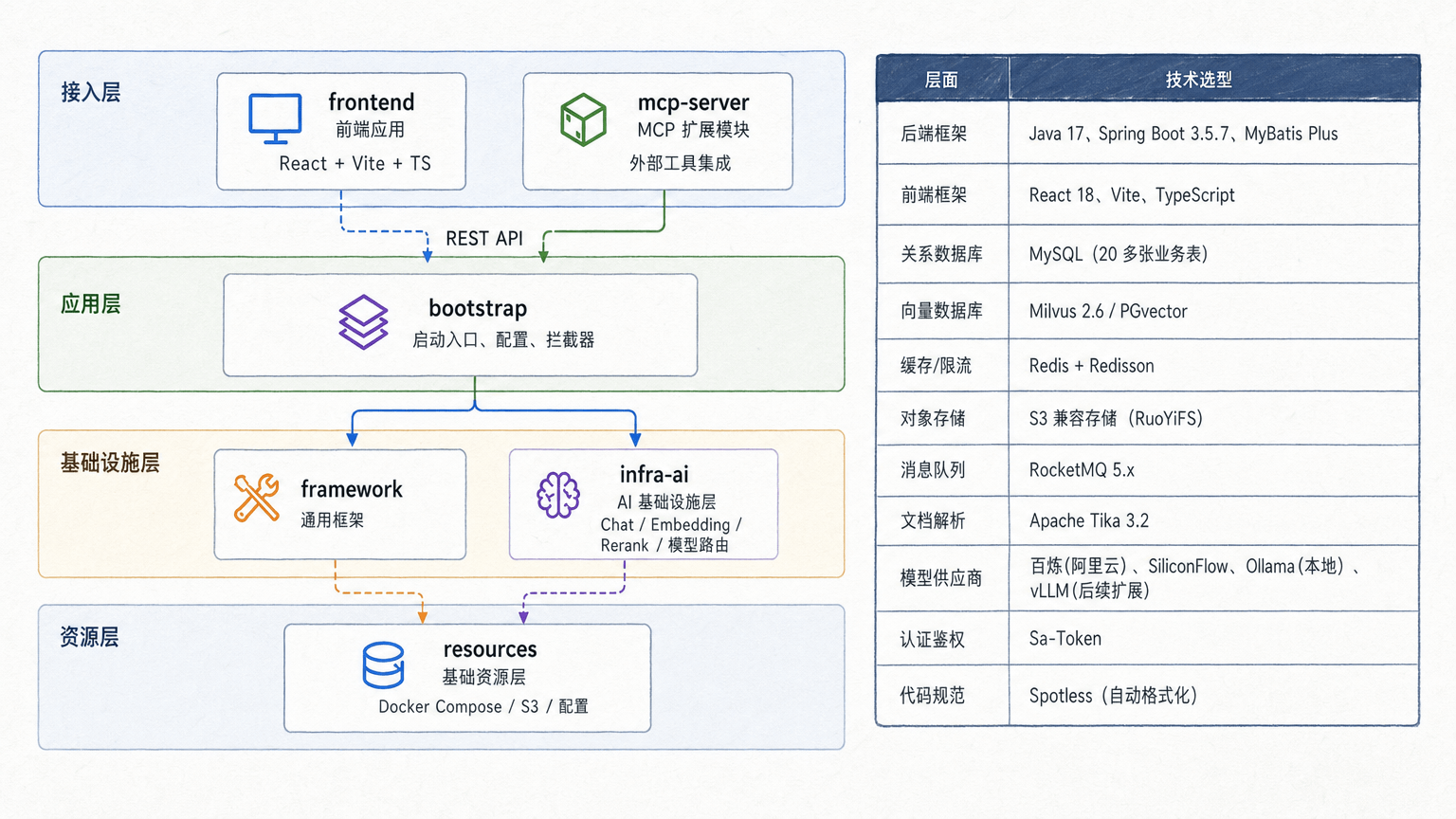
这个分层不是为了炫技,而是解决实际问题:framework 层提供与业务无关的通用能力,infra-ai 层屏蔽不同模型供应商的差异,bootstrap 层专注业务逻辑。换模型供应商不用改业务代码,换业务逻辑不用动基础设施。
技术栈选型:
| 层面 | 技术选型 |
|---|---|
| 后端框架 | Java 17、Spring Boot 3.5.7、MyBatis Plus |
| 前端框架 | React 18、Vite、TypeScript |
| 关系数据库 | MySQL(20 多张业务表) |
| 向量数据库 | Milvus 2.6 |
| 缓存/限流 | Redis + Redisson |
| 对象存储 | S3 兼容存储(RustFS) |
| 消息队列 | RocketMQ 5.x |
| 文档解析 | Apache Tika 3.2 |
| 模型供应商 | 百炼(阿里云)、SiliconFlow、Ollama(本地)、vLLM(后续扩展) |
| 认证鉴权 | Sa-Token |
| 代码规范 | Spotless(自动格式化) |
2. RAG 核心流程
2.1 Ragent 链路
一次用户提问,在 Ragent 里经过的完整链路如下:
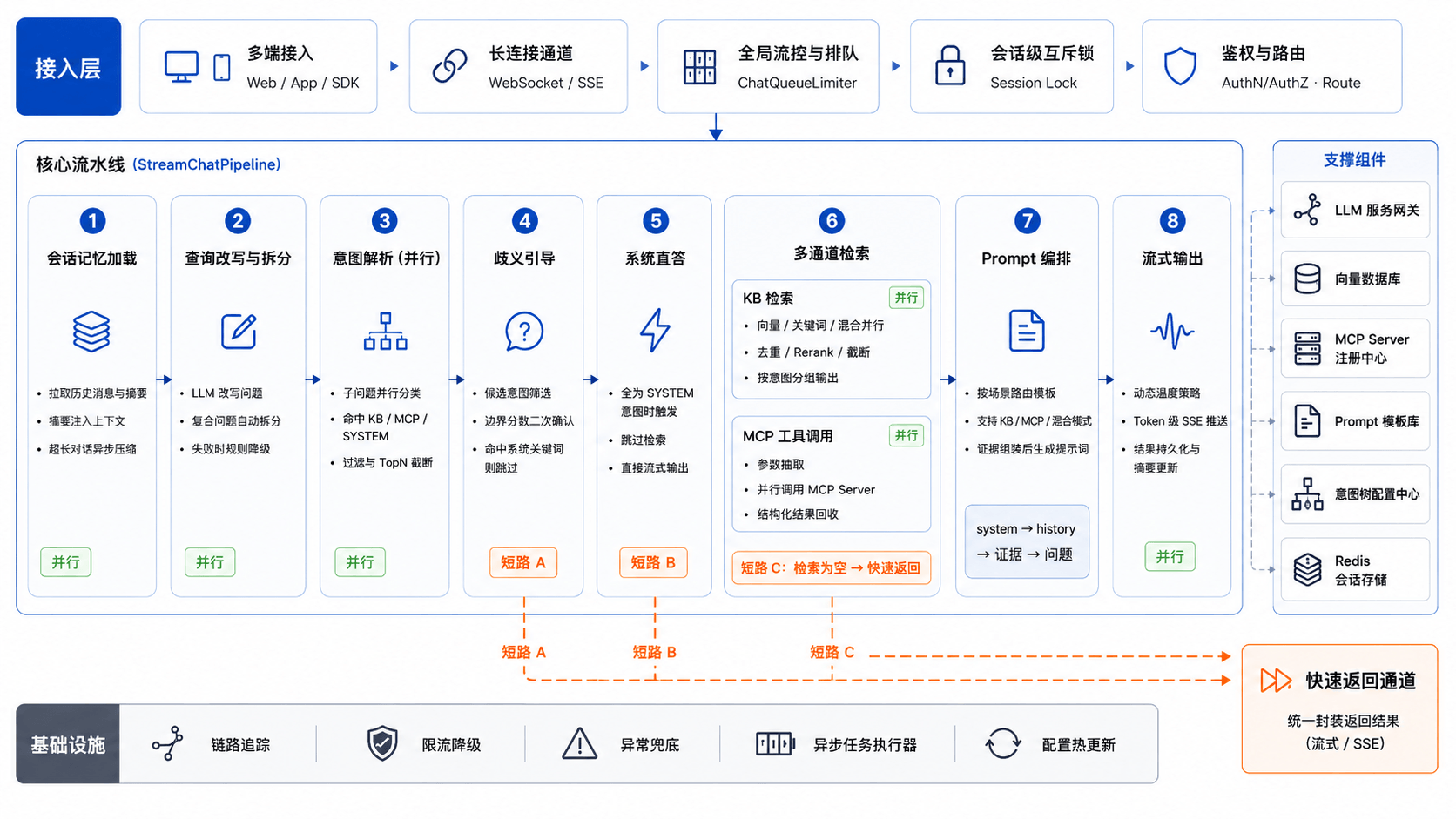
2.2 多路检索架构
检索是 RAG 系统的核心,Ragent 的检索引擎采用多通道并行 + 后处理流水线的架构:
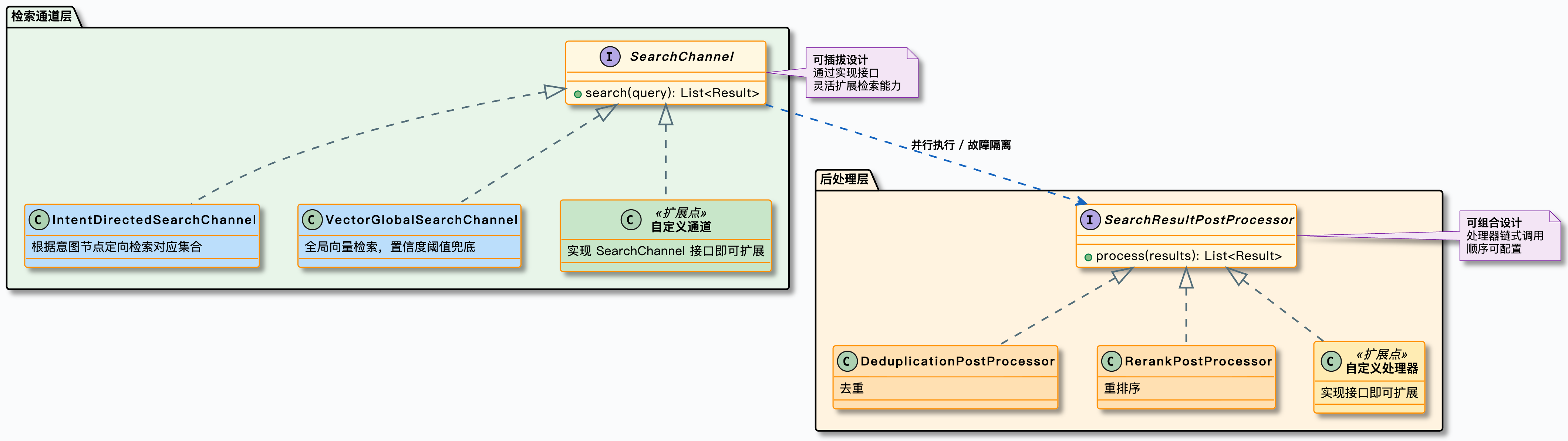
每个通道独立执行、互不影响,通过线程池并行调度。后处理器按顺序串联,像流水线一样逐步精炼检索结果。
2.3 模型路由与容错
生产环境不可能只依赖一个模型供应商,Ragent 的模型路由机制解决的就是这个问题:

关键设计:三态熔断器,用于保护系统不会持续调用已经故障的模型。

3. 文档入库流水线
文档从上传到可检索,经过一条基于节点编排的 Pipeline:
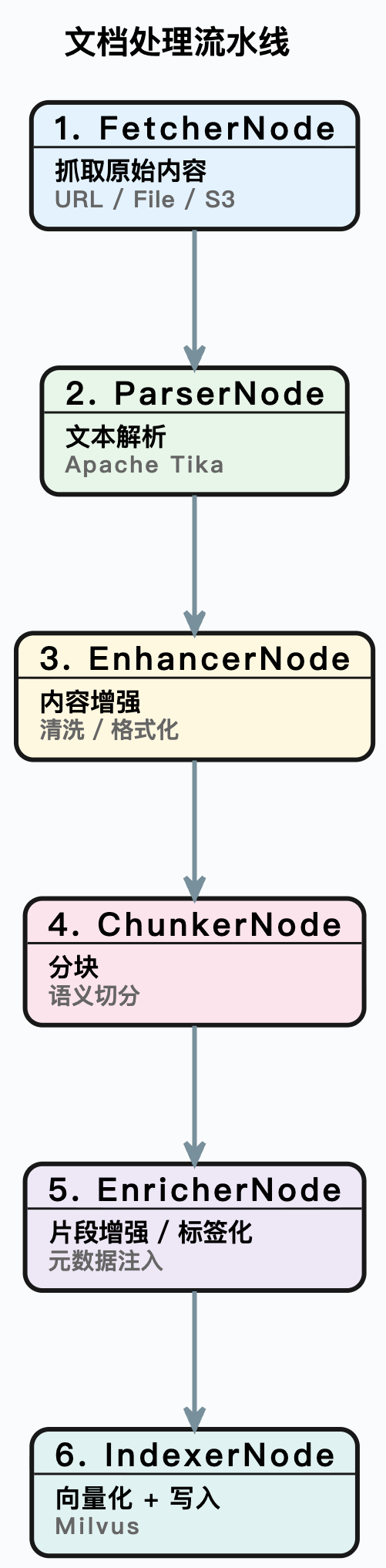
每个节点的配置存储在数据库中,支持条件执行和输出链式传递。每个任务和节点都有独立的执行日志,出了问题能精确定位到哪一步。
4. 关键设计模式
Ragent 不是为了用设计模式而用,每个模式都对应一个具体的工程问题:
| 设计模式 | 应用场景 | 解决的问题 |
|---|---|---|
| 策略模式 | SearchChannel、PostProcessor、MCPToolExecutor | 检索通道、后处理器、MCP 工具可插拔替换 |
| 工厂模式 | IntentTreeFactory、StreamCallbackFactory | 复杂对象的创建逻辑集中管理 |
| 注册表模式 | MCPToolRegistry、IntentNodeRegistry | 组件自动发现与注册,新增工具零配置 |
| 模板方法 | IngestionNode 基类 | 入库节点统一执行流程,子类只关注核心逻辑 |
| 装饰器模式 | ProbeBufferingCallback | 在不修改原有回调的前提下增加首包探测能力 |
| 责任链模式 | 后处理器链、模型降级链 | 多个处理步骤按顺序串联,灵活组合 |
| 观察者模式 | StreamCallback | 流式事件的异步通知 |
| AOP | @RagTraceNode、@ChatRateLimit | 链路追踪和限流逻辑与业务代码解耦 |
5. 核心能力
具体来说,Ragent 包含以下核心能力:
- 多路检索引擎:支持意图定向检索和全局向量检索两个通道并行执行,检索结果经过去重、重排序等后处理流水线,兼顾精准度和召回率。
- 意图识别与引导:基于树形结构的意图分类体系,支持多级意图(领域→类目→话题),识别置信度不足时主动引导用户澄清,而不是硬猜一个答案。
- 问题重写与拆分:多轮对话中自动补全上下文,复杂问题拆分为多个子问题分别检索,解决用户说的不是他想问的这个核心痛点。
- 会话记忆管理:保留最近 N 轮对话,超过阈值自动摘要压缩,既控制 Token 成本,又不丢关键上下文。
- 模型路由与容错:多模型候选、优先级调度、首包探测、健康检�查、自动降级切换,一个模型挂了不影响服务可用性。
- MCP 工具集成:当用户意图不是查知识库而是要调业务系统时,自动提取参数并执行对应工具,知识检索和工具调用在同一套流程里无缝融合。
- 文档入库流水线:基于节点编排的 Pipeline 架构,从文档抓取、解析、增强、分块、向量化到写入 Milvus,每一步可配置、可扩展、有日志。
- 全链路追踪:每次对话请求的每个环节(重写、意图、检索、生成)都有 Trace 记录,方便排查问题和优化效果。
- 管理后台:完整的 React 管理界面,涵盖知识库管理、意图树编辑、入库任务监控、链路追踪查看、系统设置等功能。
一句话总结:Ragent 是一个你可以直接拿来学习企业级 RAG 系统是怎么设计和落地的项目。
项目质量怎么样?
说一个项目是企业级,不能光靠嘴说,得看实际的工程质量。从几个维度来评估 Ragent:
1. 代码规模
- 后端 Java 代码:约 40000 行,覆盖 400+ 个源文件
- 前端 TypeScript/React 代码:约 18000 行
- 数据库设计:20 张业务表,涵盖会话、消息、知识库、文档、分块、意图树、入库流水线、链路追踪、用户等完整业务域
- 前端页面:22 个页面/组件,包含聊天界面、管理后台(仪表板、知识库管理、意图树编辑、入库监控、链路追踪、用户管理、系统设置)
这不是一个周末能撸完的 Demo,是一个有完整业务闭环的系统。
2. 工程规范
- 分层架构:framework / infra-ai / bootstrap 三层职责清晰,不存在基础设施代码和业务代码混在一起的问题。
- framework 基础设施层:独立 Maven 模块,23 个类覆盖 10 个横切关注点——三级异常体系 + 统一异常拦截、双维度幂等、Snowflake 分布式 ID 算法、用户上下文与 Trace 上下文跨线程透传、
SseEmitterSender线程安全 SSE 封装、统一响应体与错误码规范。业务模块只需引入依赖和加注解,零样板代码。 - 队列式并发限流:基于 Redis 信号 + 有序集合(ZSET)+ Pub/Sub 通知实现分布式排队限流。请求先入 ZSET 排队,通过 Lua 脚本原子判断是否在队头窗口内再出队,信号量控制最大并发数并支持许可自动过期(防死锁)。跨实例通过 Pub/Sub 广播唤醒,本地合并通知避免惊群效应。排队超时自动踢出,全程 SSE 推送排队状态。
- 8 个专用线程池 + TTL 透传:按工作负载特征配置了 8 个独立线程池(MCP 批量调用、RAG 上下文组装、多路检索、内部检索、意图分类、记忆摘要、模型流式输出、对话入口),队列类型和拒绝策略各不相同。所有线程池都用
TtlExecutors包装,确保用户上下文和 Trace 信息在异步线程中不丢失。 - 三态熔断器:实现了经典的三态熔断器(CLOSED → OPEN → HALF_OPEN),每个模型独立维护健康状态。失败次数达到阈值自动熔断,冷却期后进入半开状态放行探测请求,探测成功恢复、失败继续熔断。配合优先级降级链,一个模型挂了自动切到下一个候选,业务层无感知。
- 设计模式实战:项目中落地了多种经典设计模式——策略模式、工厂模式、观察者模式、装饰器模式、模板方法模式、责任链模式、外观模式。不是为了用模式而用,每个都解决了实际的扩展性或解耦问题。
项目中大量应用并发线程,建议配合社群里的 oneThread 动态线程池框架 搭配学习收获更多。
3. 可扩展性
这是衡量一个项目是否企业级的关键指标。Ragent 的核心模块都预留了扩展点:
- 新增检索通道:实现
SearchChannel接口,注册为 Spring Bean,自动生效。 - 新增后处理器:实现
SearchResultPostProcessor接口,自动加入处理链。 - 新增 MCP 工具:实现
MCPToolExecutor接口,自动被DefaultMCPToolRegistry发现。 - 新增入库节点:实现
IngestionNode接口,可插入 Pipeline 任意位置。 - 新增模型供应商:在
infra-ai层实现ChatClient接口,配置候选列表即可参与路由。
不需要改框架代码,不需要改配置文件里的硬编码列表,加个实现类就完事了。这才是面向接口编程的正确打开方式。
4. 生产级特性
很多开源项目做到“能跑”就停了,Ragent 还考虑了这些生产环境必须面对的问题:
- 限流:支持全局并发限制和用户级限流,防止模型调用被打爆。
- 熔断:模型健康检查 + 失败计数,自动熔断不可用的模型,避免反复超时。
- 可观测性:基于 AOP 的全链路 Trace,每个环节的耗时、输入输出、异常信息都有记录。
- 流式输出:SSE 实时推送,首包探测机制保证模型切换时用户无感知。
- 会话管理:记忆压缩、摘要持久化、TTL 过期,不会因为聊天轮次多了就 OOM 或者 Token 爆炸。
- 认证鉴权:基于 Sa-Token 的用户认证体系,不是裸奔的 API。
5. 精美控制台
Ragent 提供完整的可视化控制台,覆盖普通用户与管理员用户两类使用场景,界面简洁直观,操作高效便捷。
系统通过多轮 AI 辅助设计优化,在保证功能完整性的同时,提供更加现代化和友好的交互体验。
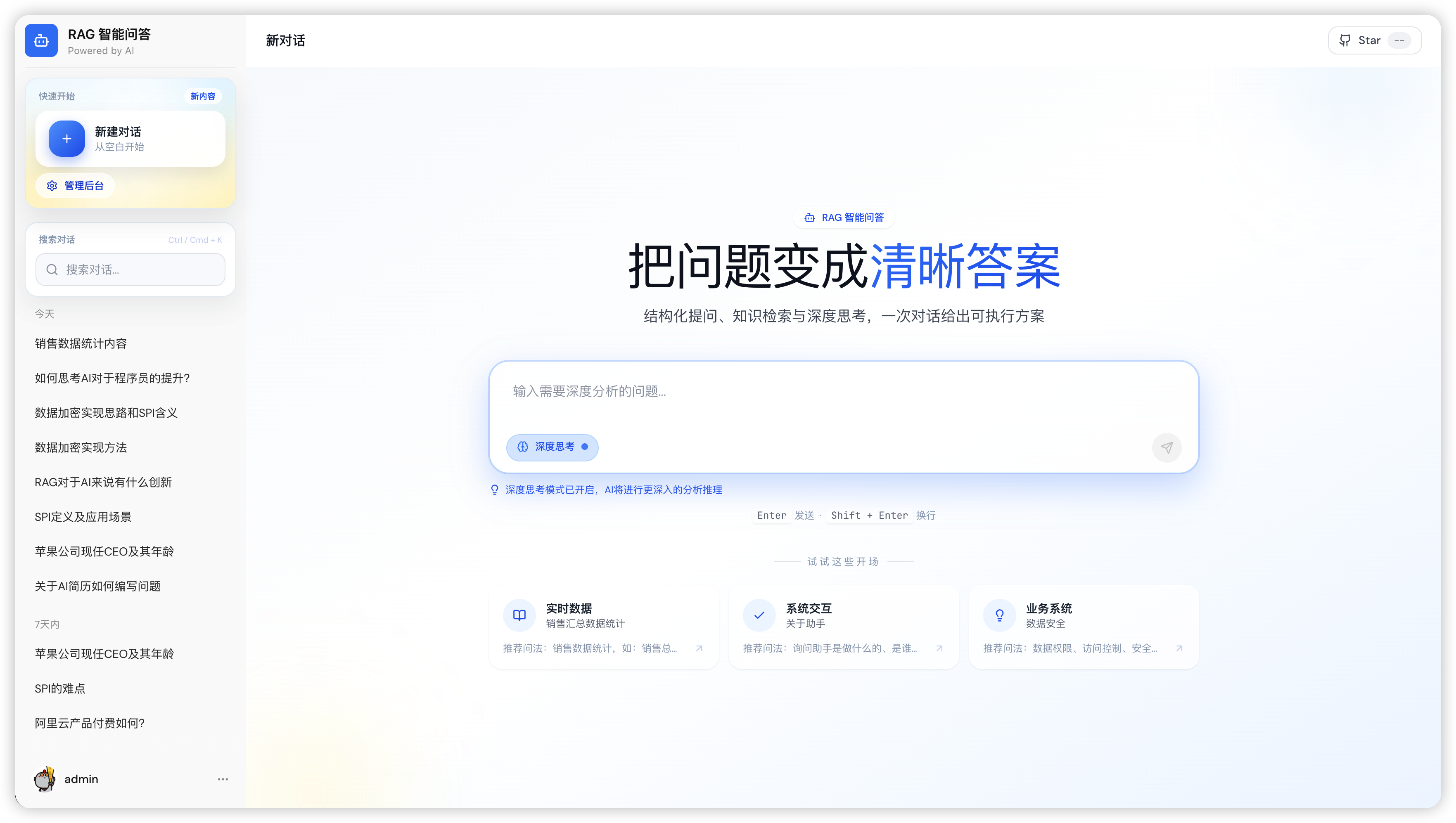
5.1 用户问答
用户访问 Ragent 首页后,可在输入框中直接输入问题发起问答,同时支持开启深度思考模式以获得更高质量的回答。
输入框下方提供示例问题标签,用户点击即可自动填充问题,方便快速体验系统能力。
系统界面如下:
- 支持自然语言输入
- 支持示例问题快速填充
- 支持深度思考模式
问答界面示例:
用户提交问题后,模型会实时生成回答结果,并提供良好的阅读体验:
- 支持 Markdown 格式渲染
- 支持图片内容展示
- 支持代码高亮显示
- 支持回答评价(点赞 / 点踩)
回答示例:
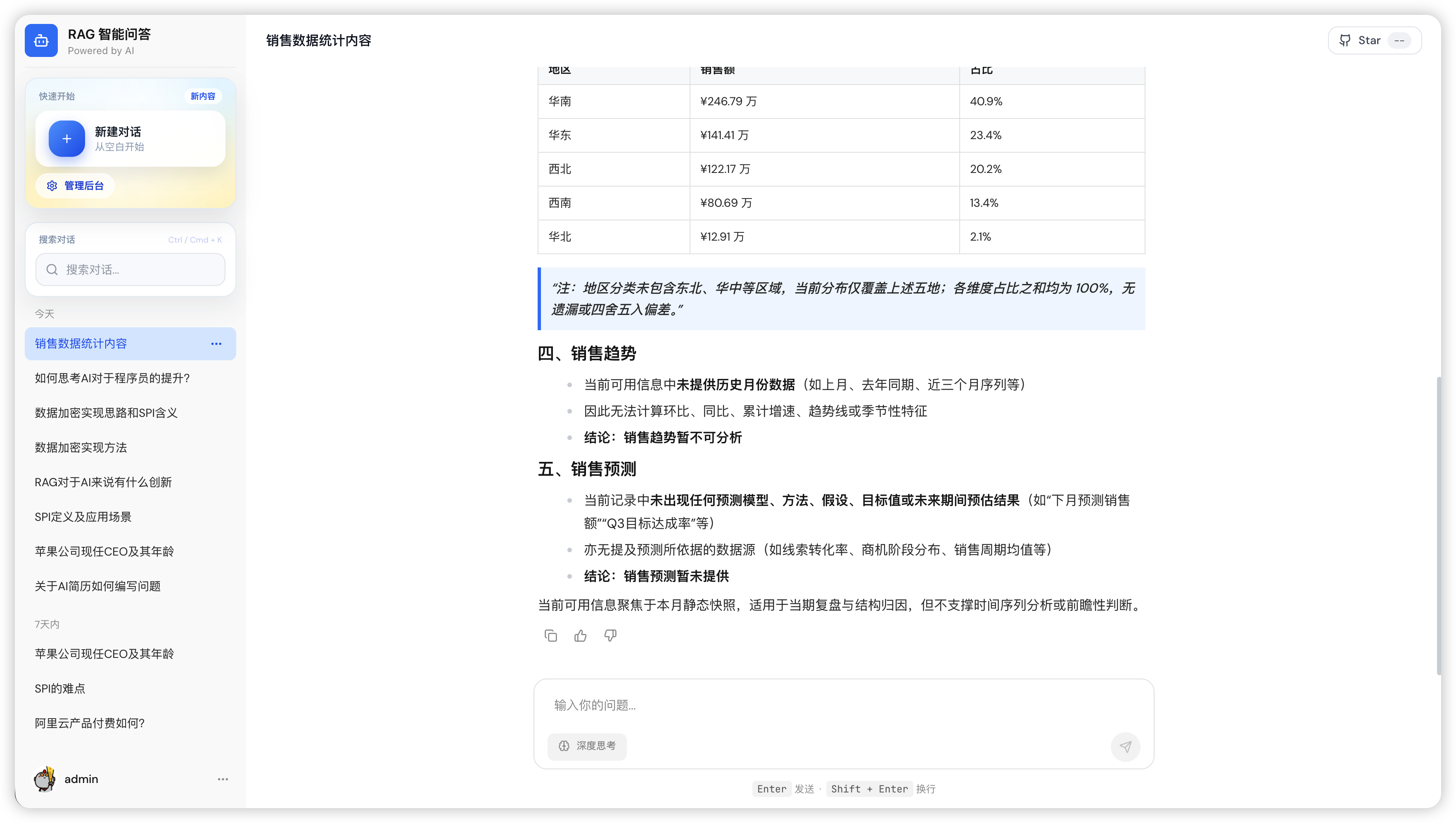
5.2 管理后台
Ragent 提供功能完善的管理后台,用于系统配置与运行管理。管理员可以通过后台完成模型管理、系统配置及数据管理等操作。
管理后台界面示例:

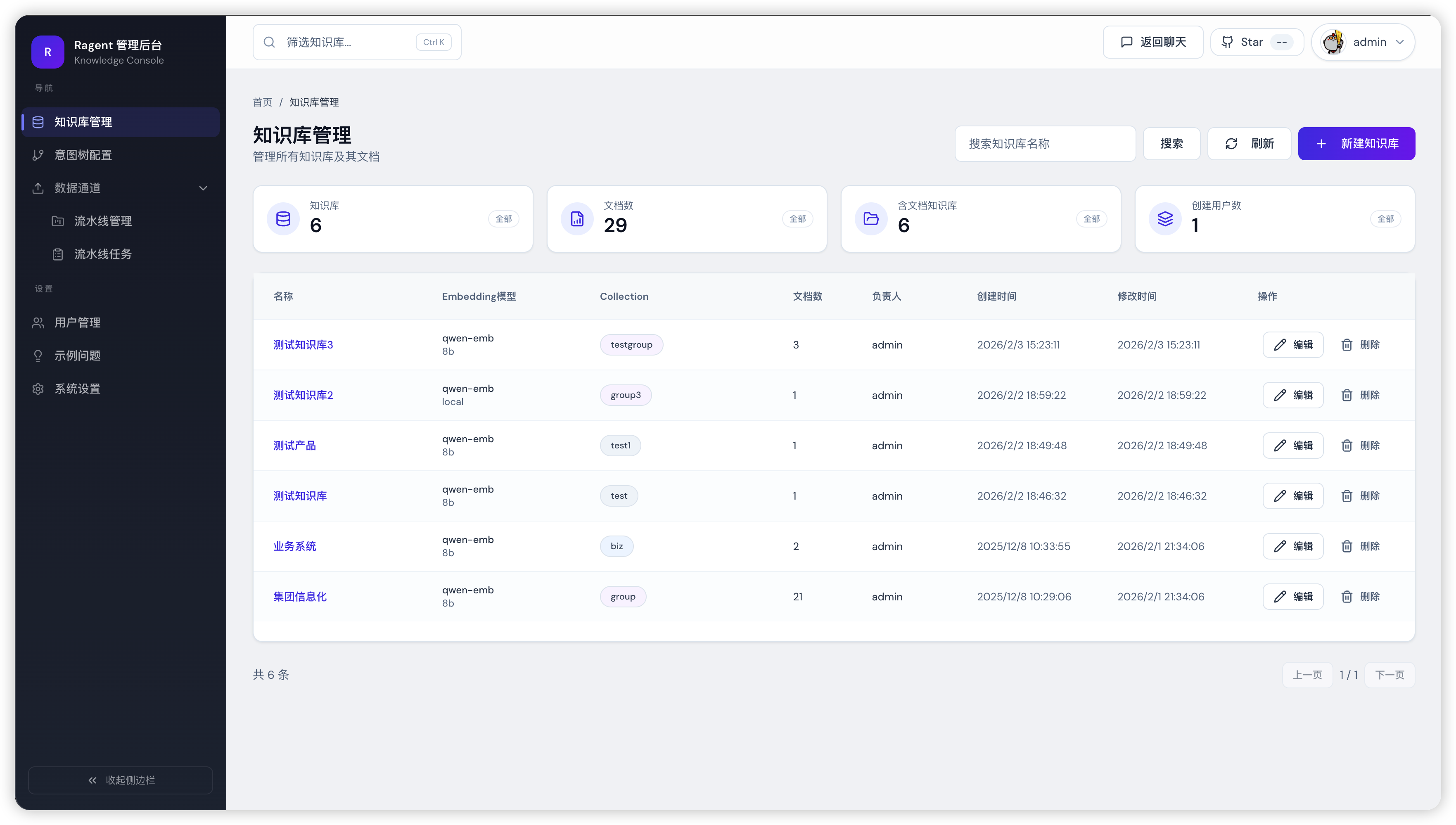
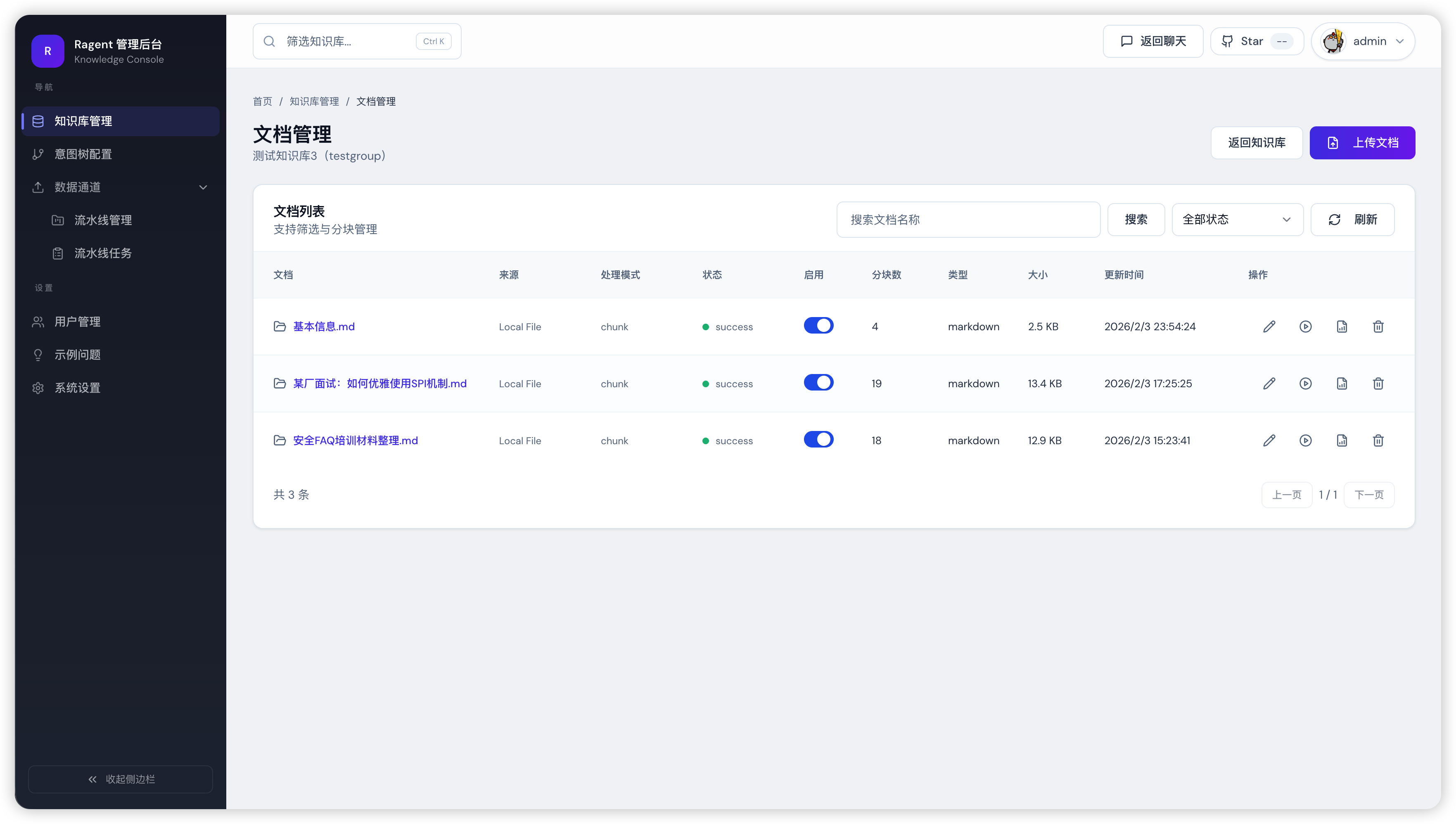

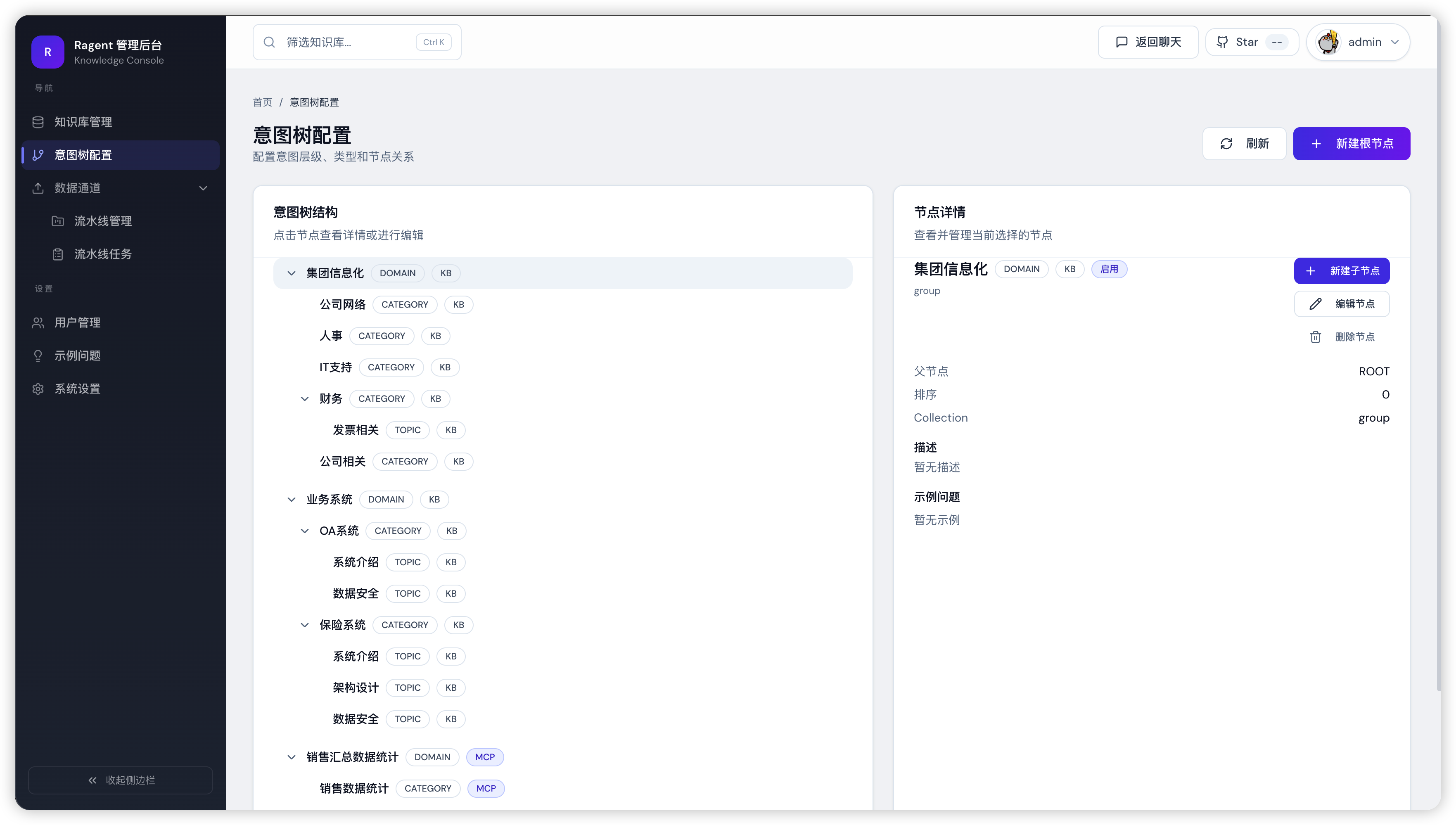

为了避免传统系统常见的“毛坯界面”体验,Ragent 的控制台经过多轮 AI 辅助设计与�优化,逐步迭代完善,最终呈现出当前简洁、美观且实用的界面效果。
6. 和市面上项目的区别
| 对比维度 | 典型 Demo 项目 | Ragent |
|---|---|---|
| 检索方式 | 单路向量检索 | 多通道并行 + 后处理流水线 |
| 意图识别 | 无 | 树形意图体系 + 歧义引导 |
| 问题处理 | 原始问题直接检索 | 重写 + 拆分 + 上下文补全 |
| 模型调用 | 单模型,挂了就挂了 | 多候选路由 + 首包探测 + 自动降级 |
| 会话记忆 | 全量塞给模型 | 滑动窗口 + 自动摘要压缩 |
| 文档入库 | 手动脚本 | 可编排的 Pipeline + 节点日志 |
| 可观测性 | 无 | 全链路 Trace |
| 工具调用 | 无 | MCP 协议集成 |
| 管理后台 | 无 | 完整的 React 管理界面 |
总结一下:Ragent 的代码量、架构设计、工程规范、扩展机制和生产级特性,都对得起企业级这三个字。它不是让你背概念用的,是让你理解企业里的 RAG 系统到底长什么样、每个设计决策背后的 why 是什么。
常见问题答疑
1. 能够学到什么?
Ragent 不只是教你调 API,而是让你理解一个 RAG 系统从 0 到 1 落地的全过程。粗略来说,你能收获这些:
- RAG 全链路工程能力:文档解析、分块策略、Embedding 向量化、多路检索、重排序、Prompt 组装、流式生成,每个环节怎么做、为什么这么做。
- AI 应用架构设计:意图识别体系、问题重写与拆分、会话记忆管理、MCP 工具调用,这些是 AI 应用区别于传统 CRUD 系统的核心能力。
- 模型工程化实践:多模型路由、优先级调度、首包探测、熔断降级,解决的是模型不稳定怎么办这个生产环境的真实问题。
- 高质量 Java 工程能力:分层架构、设计模式实战、分布式并发限流、多线程池管理与上下文透传、全链路追踪,这些能力不局限于 AI 项目,放到任何 Java 后端岗位都是加分项。
- 前后端完整项目经验:后端 Spring Boot 3 + 前端 React 18,从 API 设计到页面交互,完整的全栈项目经历。
一句话:学完 Ragent,你既能跟面试官聊 RAG 的技术深度,也能证明自己的 Java 工程化水平。
2. 适合人群
校招同学:
- Java 后端方向的在校生:简历上已经有了商城、外卖等常规项目,需要一个有区分度的项目来拉开差距。Ragent 能让你在面试中聊 AI + 工程化,而不是千篇一律的 CRUD。
- 想转 AI 应用方向的同��学:对大模型感兴趣,但不想从 Python 和算法入手。Ragent 基于 Java 技术栈,学习曲线平滑,不需要额外切换语言生态。
- 准备实习/秋招/春招的同学:大厂校招越来越看重候选人对新技术的敏感度,简历上有 AI 项目经验,能直接证明你的学习能力和技术视野。
社招同学:
- 1-3 年经验的 Java 开发:日常写业务代码,想往 AI 方向转型但不知道从哪下手。Ragent 的技术栈你都熟悉,学的是 AI 应用层的东西,上手快、能落地。
- 3-5 年经验的后端开发:技术能力不差,但面试被问到 AI 相关问题答不上来,少了一个谈薪筹码。通过 Ragent 补上 RAG、Agent、MCP 这些知识点,面试时能聊得有深度。
- 想跳槽到 AI 团队的开发者:越来越多的 JD 要求有 AI 相关经验,Ragent 能帮你快速建立 RAG 系统的全局认知,面试时不再只是纸上谈兵。