为什么要设计意图树
开篇引言
上一篇讲完了查询改写,Ragent 用一次 LLM 调用同时完成了改写和拆分,输出一个 RewriteResult——改写后的完整问题加上子问题列表。每个子问题都是独立的、完整的、对检索友好的查询。
子问题列表有了,下一步做什么?意图识别——判断每个子问题应该去哪里找答案。
来看一个场景。假设你在一家电商平台做 AI 客服,平台规模不小,知识库有好几块:商品信息、售后维修、退换货政策是商品服务方向的;国内物流的配送方式和运费规则、跨境物流的海外仓和清关流程是物流方向的。除了知识库,还接了一个订单��查询的 MCP 工具,用户问“我的快递到哪了”得去调物流接口。另外还有欢迎问候、介绍助手身份这类系统交互。
用户发来一句:
跨境包裹清关一般要多久?
你作为开发者,一眼就知道该去跨境物流的清关流程知识库搜。但系统怎么知道?
基础系列里学过四种意图类型:知识检索、工具调用、闲聊对话、引导澄清。套用四分类,这个问题会被分到知识检索。没问题,但接下来呢?你有五六(可能几十)个知识库,查哪个?四分类不告诉你。
这就是本篇要解决的核心问题:当知识库数量多了,扁平的四分类不够用,需要一棵意图树来做精准路由。
本篇是意图识别子系列的第 1 篇,共 5 篇(第 5~9 篇)。本篇聚焦意图树的设计动机和数据结构——为什么需要树、树长什么样、节点上挂了什么信息、怎么存怎么读。后续第 6 篇讲怎么让大模型给节点打分,第 7 篇讲多子问题多意图的封顶算法,第 8 篇讲歧义引导,第 9 篇讲意图到检索的映射。
扁平分类的天花板
1. 四分类能做什么
基础系列的意图识别篇讲过,用户发来的消息大致可以分成四种意图:
| 意图类型 | 含义 | 典型问题 |
|---|---|---|
| 知识检索 | 去知识库里搜答案 | iPhone 16 Pro 的退货政策是什么��? |
| 工具调用 | 调外部接口拿实时数据 | 帮我查一下订单 2024112801 的物流进度 |
| 闲聊对话 | 打招呼、闲扯、感谢 | 你好、谢谢你 |
| 引导澄清 | 问题太模糊,需要反问 | 我想退货(退哪个产品?) |
知识库只有一两个的时候,这四种分类完全够用。判断出是知识检索,直接去那个知识库搜就行;判断出是工具调用,去调那个工具。分类的粒度和知识库的数量刚好匹配。
2. 知识库多了就不够用了
问题出在知识库从 2 个变成 20 个的时候。
继续用电商客服的场景。平台有商品信息、售后维修、退换货政策、国内物流配送方式、国内物流运费规则、跨境物流海外仓、跨境物流清关流程、跨境物流运费计算……光这些就有八九个知识库了。如果再加上不同品类(3C 数码、家电、服装)各自的专属知识库,轻轻松松到 20 个。
四分类告诉你这个问题属于知识检索,然后呢?
- 不知道该查哪个知识库。 四分类的知识检索只有一个大类,所有知识库都归这一类。跨境包裹清关一般要多久?和iPhone 16 Pro 的保修期多长?都是知识检索,但该去完全不同的知识库搜。
- KB 和 MCP 混在一起也区分不了。 你有订单查询的 MCP 工具,也有物流知识库。用户问我的快递到哪了该调 MCP 工具,用户问你们支持哪些快递公司该查知识库。四分类把 MCP 工具只归为一类工具调用,但你有多个 MCP 工具的话,调哪个?
- 同一个框架里处理不了多种类型。 知识检索走一套逻辑,工具调用走另一套,闲聊走第三套。四分类做完之后还需要一层路由来决定具体走哪条路径,分类和路由是割裂的。
3. 暴力全库搜索为什么不行
最直觉的方案:不管这么多,所有知识库都搜一遍,最后合在一起排序。
算一笔账。20 个知识库各取 Top-5,合计 100 条候选 chunk。Reranker 要对这 100 条做 Cross-Encoder 精排,计算量大约是单知识库的 20 倍。延迟从几十毫秒飙升到几百毫秒甚至秒级,Token 消耗也跟着翻倍。
更麻烦的是结果质量。不同知识库的内容领域差异很大,跨境物流的 chunk 和 3C 数码的 chunk 放在一起做全局排序,Reranker 容易被迷惑——一段关于国际运费的文档和一段关于手机保修的文档,在语义上可能和用户问题都沾点边,但只有一个是真正相关的。全局排序容易把不相关的 chunk 排到前面,最终答案质量反而下降。
用一句话概括:扁平分类解决了做什么的问题,但解决不了去哪找的问题。
为什么是树——三级意图结构
1. 树形结构的设计直觉
打个比方,电商平台的商品类目是怎么组织的?一级类目(数码、家电、服装)→ 二级类目(手机、耳机、电视)→ 三级类目(iPhone、华为、小米)。用户搜东西的时候,先按大方向分流,再按细方向定位。
意图识别也是一样的思路。用户的问题先按大方向分流——这是商品相关还是物流相关?再按细方向定位——是国内物流还是跨境物流?最后定位到具体知识方向——是配送方式还是运费规则?
层层递进,从粗到细,每一层都把候选范围缩小一半以上。这就是树形结构的核心价值——把一个大的匹配问题拆成多层小的匹配问题。
2. 三级结构:DOMAIN → CATEGORY → TOPIC
Ragent 用三级树来组织意图:
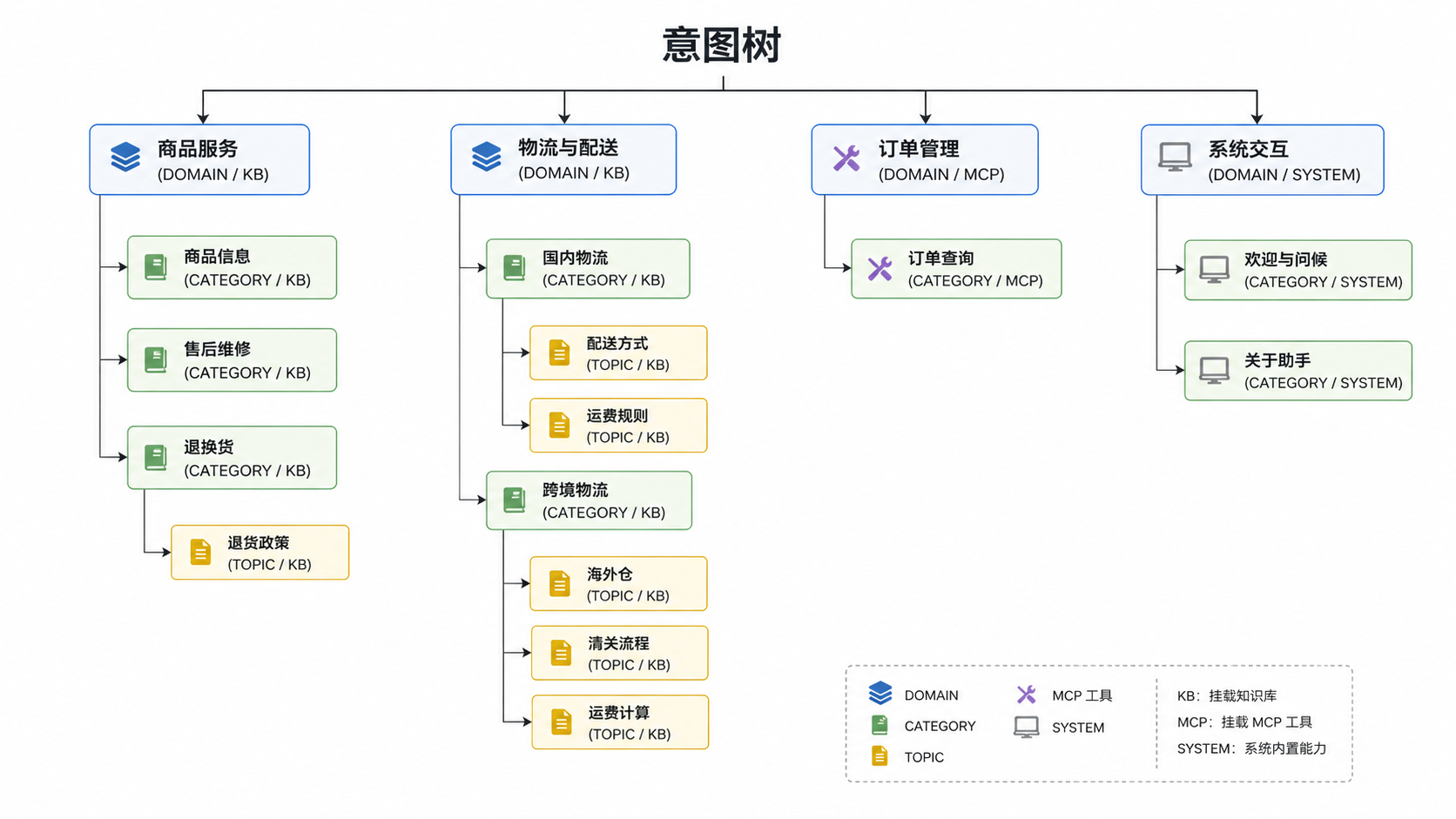
三层各司其职:
- DOMAIN(领域层): 最粗的分类维度,对应一个大的业务板块。商品服务、物流与配送、订单管理、系统交互——一眼就能看出业务的大方向。DOMAIN 层主要用于在管理后台做顶级分组,不直接参与匹配。如果领域层下没有子节点,会参与匹配
- CATEGORY(分类层): 在领域内做进一步细分,通常对应一个具体的服务方向。比如物流与配送下面分了国内物流和跨境物流,商品服务下面分了商品信息、售后维修、退换货。
- TOPIC(主题层): 最细粒度,对应一个具体的知识方向。跨境物流下面分了海外仓、清关流程、运费计算三个 TOPIC。
有一点要注意:不是所有分支都一定有三层。 商品信息、售后维修在 CATEGORY 层就是叶子节点了——它们的知识库内容比较集中,没必要再往下拆。而跨境物流下面的知识有多个明确方向(海外仓、清关、运费),需要再分一层 TOPIC 才能精准路由。
层数取决于知识库的粒度需求,不是强制三层。两层到叶子的分支和三层到叶子的分支可以同时存在。
3. 只有叶子节点参与匹配
这是整棵树最重要的一条规则:大模型打分时只看叶子节点,中间层仅用于组织和导航。
为什么这样设计?
第一,中间层没有对应的执行目标。叶子节点是最终要路由到的目标——一个具体的 Collection、一个 MCP 工具、或一个系统回复模板。而商品服务(DOMAIN)或者跨境物流(CATEGORY)这些中间层节点,命中了也不知道该干什么。
第二,如果中间层也参与打分,分数的含义会变得模糊。假设 LLM 给国内物流(CATEGORY)打了 0.8 分,给配送方式(TOPIC)打了 0.7 分,给运费规则(TOPIC)打了 0.6 分——该走哪个?走国内物流?但国内物流不是一个可执行的目标,下面还有两个 TOPIC。走配送方式?但国内物流的分数更高。逻辑就乱了。
第三,减少 LLM 需要评估的节点数。上面那棵树有 16 个节点,但叶子只有 11 个。只评估叶子,Prompt 更短,推理更快,成本更低。
所有叶��子节点会被序列化后发给 LLM,LLM 对每个叶子返回一个 0~1 的分数。具体怎么序列化、Prompt 怎么设计,第 6 篇展开。