10个人同时提问只有3个坑位
开篇引言
上一篇收尾了流式生成子系列,把单个请求的故事讲得比较透了——正常路径走完 finish + done 落库关连接,被取消路径走 cancel + done 保存部分内容再关连接,资源都能干净释放。镜头始终对着一个请求,从 LLM 第一个 Token 吐出到最后一个 Token 收束。
但是把镜头从单个请求拉远到整个集群,会看到完全不一样的压力面。
假设你在一家在线教育公司做开发,公司前段时间上了 RAG 智能客服,主要做课程咨询、退费政策、报名引导这类问题。日常流量不大,平均下来一台机器同时跑 5 ~ 10 个请求。但每周三下午 3 点,运营会推一个「限时五折」的活动短信,全网用户瞬间涌进来问优惠详情、能不能叠加优惠券、报名截止时间。促销那一刻同时来了 200 个 RAG 请求。
这时候问题就来了:
- 下游模型服务有并发上限——本地部署的 GPU 显存有限,同时跑几十个推理任务直接 OOM;在线 API 平台(如 SiliconFlow)也有并发限制,一下涌进 200 个请求,绝大多数会直接报
429 Too Many Requests - Tomcat 默认 200 个工作线程会被这些 SSE 长连接占满——单个 RAG 请求要跑 30 秒到 1 分钟,普通的 REST 接口都进不来了
你可能会想:那加个限流就行了呗,不是几行代码的事?听起来很合理,但实际跑起来你会发现问题没那么简单——QPS 限流挡不住长连接、本地 Semaphore 在多机部署下管不住总并发、直接拒绝(HTTP 429)的体验又特别差。RAG 这种长耗时 + 资源敏感 + 体验敏感的场景,需要的是另一套思路:排队。
本篇聚焦排队限流的为什么 + 整体架构 + 入队与立即抢占的同步路径。下一篇接着讲异步等待路径——抢不到许可的请求怎么等、跨集群怎么唤醒、超时了怎么给用户交代。
为什么不能简单地「加个 QPS 限流」
要想清楚 RAG 的限流方案,得先想清楚 RAG 请求长什么样。
1. RAG 请求的三个特殊性
1.1 长耗时
普通 REST 接口几十毫秒到几百毫秒,QPS 限流非常合适——每秒最多放进 N 个请求,超过就拒绝,N 秒后再来。
但 RAG 是长连接,单次请求 10 秒到 1 分钟。考虑两种流量:
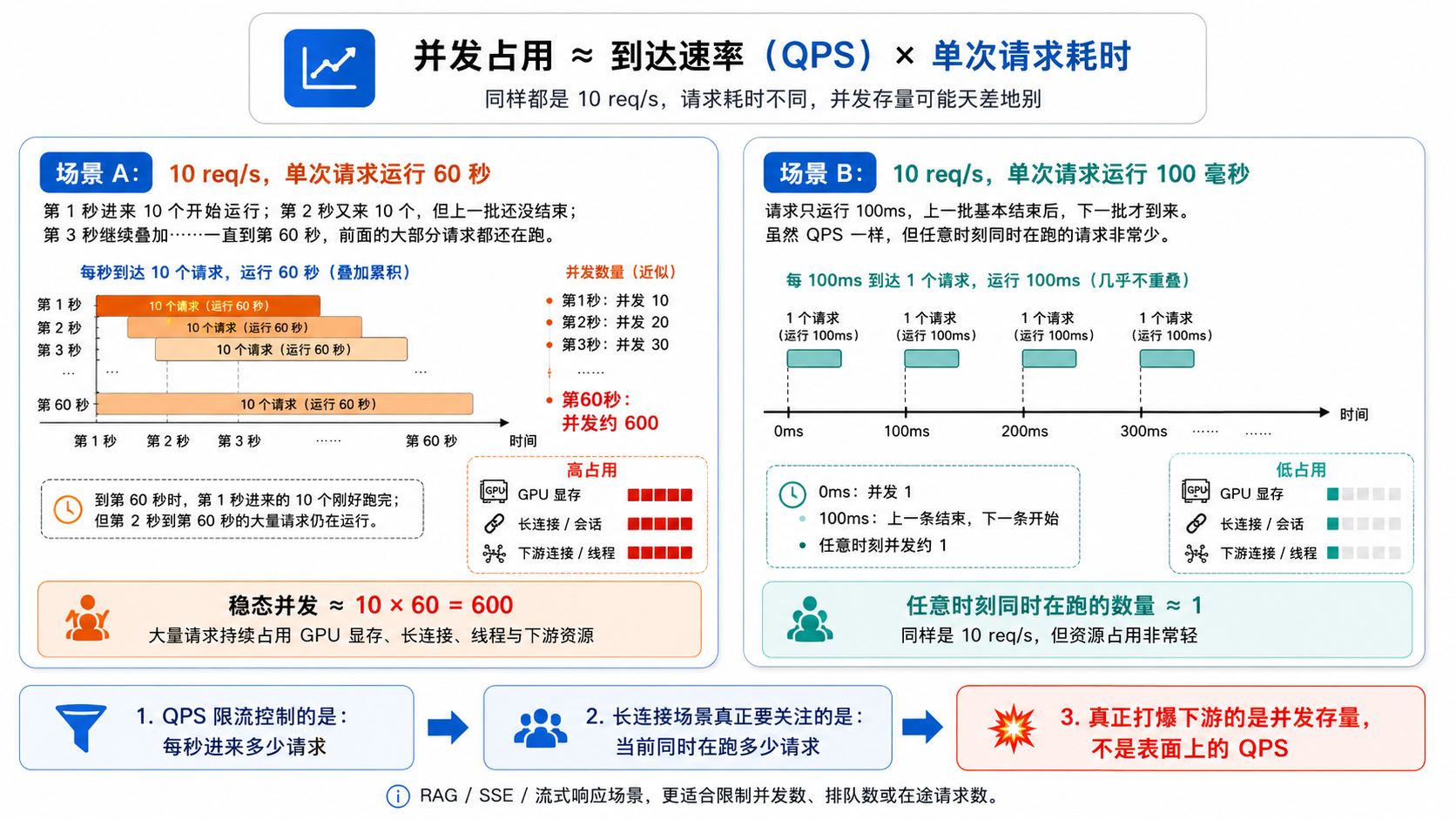
A 场景每秒来 10 个请求,每个跑 60 秒。第 1 秒进来 10 个开始跑;第 2 秒又来 10 个,但第 1 秒的还没跑完,同时在跑的变成 20 个;第 3 秒再来 10 个,堆到 30 个……一直堆积到第 60 秒,第 1 秒的 10 个刚好跑完退出,但第 2 秒到第 60 秒的还在跑——稳态并发 10 × 60 = 600。
B 场景每秒也来 10 个请求,但每个只跑 100 毫秒。请求进来 100 毫秒就结束了,下一批还没到上一批就走了,任意时刻同时在跑的最多也就 1 个。
两者的 QPS 都是 10 req/s,QPS 限流看起来一视同仁。但 A 场景任意时刻有 600 个请求同时占着 GPU 显存和连接,B 场景只有 1 个。真正打爆下游的是「同时在跑的数量」,不是「每秒进来的数量」。
QPS 限流挡的是流量速率,挡不住并发存量。
1.2 资源敏感
下游 LLM 服务有硬性的并发上限。本地部署受 GPU 显存物理瓶颈限制——以一张 A100 跑 32B 模型为例,在常见量化和上下文配置下,单卡可承载的并发通常也就在几十量级,超出后要么排队�导致延迟飙升,要么直接 OOM;在线 API 平台(如 SiliconFlow)同样设有 RPM/并发限制,超出会直接返回 429。不管是自建还是调三方,并发都有天花板,超了就是报错或拖垮延迟。
1.3 体验敏感
QPS 限流和 HTTP 429 是 REST 接口的常见组合——拒绝就拒绝了,前端弹一句「请稍后再试」,用户刷新一下重试。但 RAG 是用户已经按下回车并且看到了「思考中…」的加载圈圈。这时候直接告诉他「系统繁忙」,体验非常差——他会刷新再问,刷新再问,制造更多的请求把系统继续打爆。
2. 三种朴素方案的对比
针对上面三个特殊性,常见的三种方案各有适用场景。
| 方案 | 工作原理 | 适合场景 | RAG 是否合适 |
|---|---|---|---|
| 直接拒绝(HTTP 429) | 超过并发立即返回错误码 | 短请求、用户能快速重试的场景 | 不合适,长连接 + 用户已等待,体验差 |
| 令牌桶(Bucket4j) | 按速率匀速发令牌,无令牌排队等待或拒绝 | 短请求 + 有突发但平均速率可控 | 不合适,令牌发出后长期占用,速率算不准 |
| 排队 + 信号量 | 总并发设上限,超出的入队等待,超时再拒绝 | 长耗时 + 资源敏感 + 体验敏感 | 合适,给等待者机会、给系统喘息空间 |
排队的核心思路是:先让请求进系��统但不立刻执行,给前端一个「思考中…」的连接保持着。后台按 FIFO 顺序逐个抢许可,抢到就跑,没抢到就等,等不到就给个明确的反馈。这样既不会瞬时打爆下游,也不会粗暴拒绝用户。
3. 那用本地 Semaphore 行不行
学过并发的同学这时候会说:「我在 Java 进程里加一把 java.util.concurrent.Semaphore,构造时传 new Semaphore(N),业务方法里 acquire() / release(),不就行了?」
如果你只部署一台机器,这套方案确实能工作。但 RAG 这种长耗时服务为了高可用一定是多机部署的,本地 Semaphore 在多机部署下立刻露馅:
- 节点 A 配置
Semaphore(N),节点 B 也配置Semaphore(N),两台机器加起来集群总并发是 2N - 你想限制集群总并发为 N,就得算
N / 节点数配给每台机器;但节点数动态变化(后续的扩缩容),又得改配置 - 即使配对了,请求被负载均衡随机分发,节点 A 此刻满了节点 B 一个都没有,节点 B 的许可全在闲置,节点 A 后来的请求却被本地拒绝
本地 Semaphore 各算各的,没有全局视角。要想让整个集群按一个统一的并发上限执行,许可必须放在集群共享的地方——Redis 是最自然的选择。
Redisson 中的
RPermitExpirableSemaphore把许可放在 Redis 里集中维护,集群里任何一个节点tryAcquire()都从同一个池子里取,这样集群总并发才真正被卡住。
整体架构:五个 Redis 数据结构 + 两层本地组件
理解完为什么需要排队,现在来看整体架构。本篇的限流系统由五个 Redis 数据结构和两层本地组件构成,各司其职。
1. 一张图看完整结构
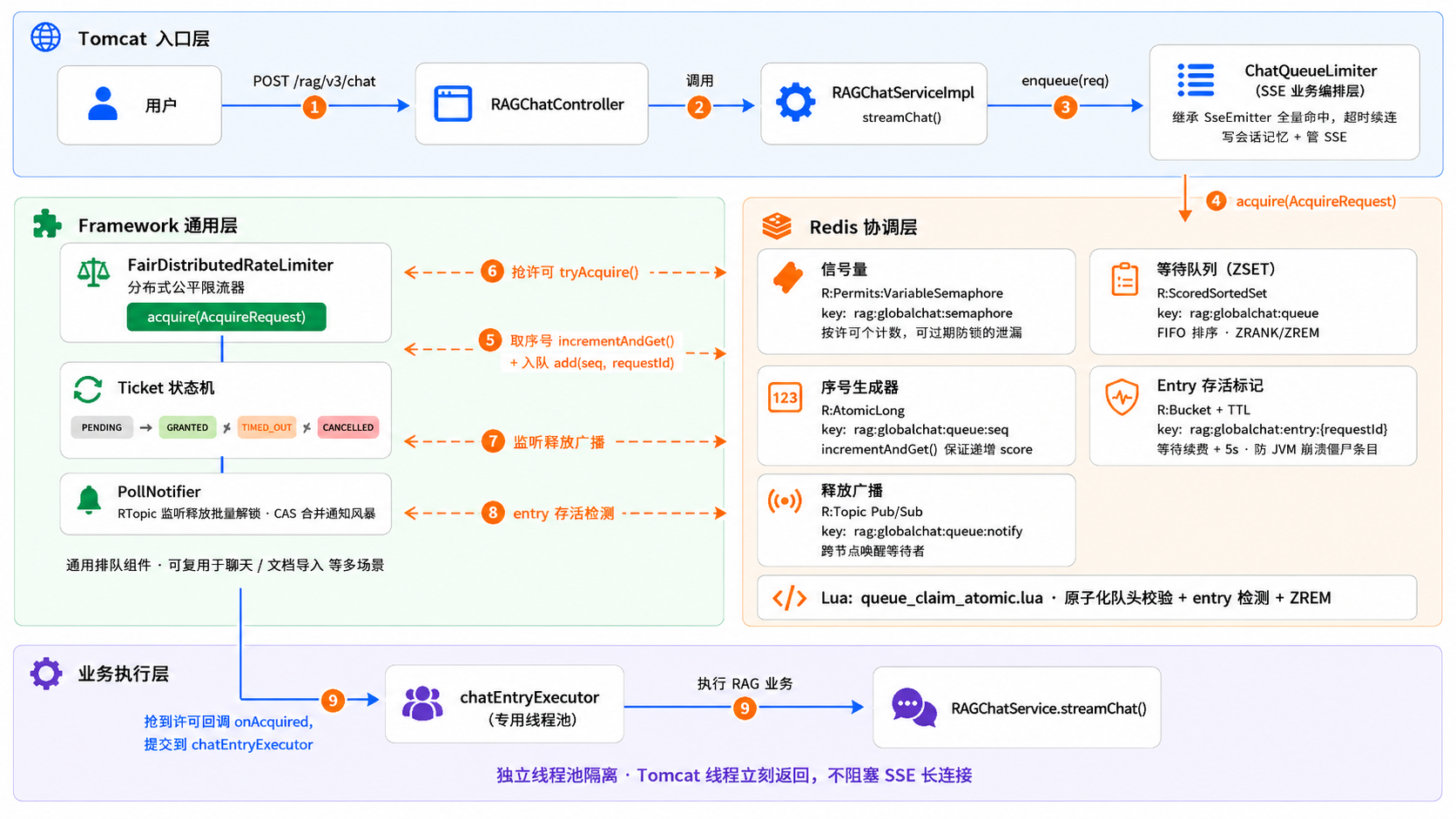
整体看下来分四段:
- Tomcat 接收 SSE 请求,
RAGChatServiceImpl.streamChat()直接调用ChatQueueLimiter.enqueue(); ChatQueueLimiter是一个轻量的 SSE 业务编排层,它不直接操作 Redis,而是把排队抢占委托给底层的FairDistributedRateLimiter——一个通用的分布式公平限流器;FairDistributedRateLimiter操作 Redis 五件套——信号量 + ZSET 队列 + 自增 seq + entry 存活标记 + Pub/Sub;- 抢到许可后,业务在专用线程池里执行,Tomcat 线程立刻返回。
为什么要拆两层?因为排队抢占的逻辑是通用的——信号量 + ZSET + Lua 原子 claim + entry 存活标记 + Pub/Sub 广播,跟 SSE、跟聊天业务没有半毛钱关系。把这套逻辑收拢到 FairDistributedRateLimiter,上层不管是 Chat 限流、文档导入限流还是其他场景,都能直接复用。ChatQueueLimiter 只负��责 SSE 特有的事情:把 SseEmitter 的生命周期绑定到排队取消、超时被拒时写会话记忆和推 SSE 事件。
2. 五个数据结构各司其职
2.1 RPermitExpirableSemaphore:集群总并发上限
第一个数据结构是 Redisson 提供的可过期信号量。它持有 N 个许可(N 由 max-concurrent 配置),代表整个集群同时能跑的最大 RAG 任务数。
为什么用「可过期」版本而不是普通 RSemaphore?后面会单独开一节讲。这里只点一句:可过期版本的许可绑定 lease(租约),如果调用方崩溃没释放,租约到期后 Redis 自动回收,避免许可永久泄漏。
2.2 ZSET 队列:等待者按 FIFO 排序
第二个数据结构是 ZSET(有序集合),用来存所有正在等待许可的请求。每个等待者用 requestId 作为成员,用一个单调递增的 seq 作为 score。score 越小排名越前,最早入队的排在最前面。
为什么不用 List?后面会有专门的对比表。这里也点一句:ZSET 支持 ZRANK 查任意成员的位置、支持 ZREM 删任意成员,恰好对应「队头窗口判断」和「请求随时取消」这两个核心需求。
2.3 自增 seq:score 不冲突
第三个数据结构是 RAtomicLong,用 incrementAndGet() 生成全局单调递增的 seq 作为 ZSET 的 score。
你可能会想:直接用 System.currentTimeMillis() 当 score 不就行了吗?看起来很合理,但实际跑起来你会发现毫秒级冲突非常常见——同一毫秒内进来的多个请求 score 完全相同,ZSET 对同 score 元素按 lex 顺序排,结果 FIFO 语义被破坏,后入队的可能反而排在前面。单调 seq 永远不会冲突,ZRANK 给出的排名就是真正的入队顺序。
2.4 Entry 存活标记(RBucket + TTL):防僵尸条目
第四个数据结构是带 TTL 的 RBucket(普通 KV),每个入队的请求在写 ZSET 之前先写一个 rag:global:chat:entry:{requestId} 的 key,值无所谓(固定写 "1"),关键是设了一个 TTL——等待预算 + 5 秒缓冲。
为什么需要这个标记?考虑一个场景:节点 A 入队后立刻崩溃(进程被 kill),ZSET 里的条目没人清理,它永久占据队头窗口,排在它后面的请求永远无法 claim。entry 标记就是这个问题的兜底——JVM 崩溃后 key 自然过期,后续的 Lua claim 脚本在扫描队头窗口时会检查每个成员的 entry 标记是否存在,不存在的视为僵尸条目直接 ZREM,把队头让给存活的请求。
简单理解:ZSET 存的是排队凭证,entry 标记存的是排队者还活着的证明。凭证还在但人已经不在了,就是僵尸。
2.5 RTopic Pub/Sub:跨集群广播
第五个是 Pub/Sub 频道,用来在「许可释放」时广播通知所有节点。节点 A 上的请求释放许可后,节点 B 上等待的请求需要被唤醒来重新抢——单靠节点 B 自己轮询太慢,靠 Pub/Sub 立刻通知最高效。
广播的具体机制和上一篇 StreamTaskManager 的取消广播是同一套套路。本篇不展开,下篇会详细讲跨集群唤醒和 PollNotifier 防惊群。
3. 配置参数一览
把抽象的架构落到具体的配置参数上:
rag:
rate-limit:
global:
enabled: true
max-concurrent: 3 # 演示用 3 个许可
max-wait-seconds: 20
lease-seconds: 600
poll-interval-ms: 200
| 参数 | 含义 | 经验值 |
|---|---|---|
enabled | 是否启用全局限流 | 生产开,本地 dev 可关 |
max-concurrent | 集群总并发上限(信号量许可数) | 按下游 LLM 并发上限设,本地 GPU 看显存,在线 API 看平台限制 |
max-wait-seconds | 单个请求最长等待时间 | 20 ~ 30 秒,超过用户体验已不可接受 |
lease-seconds | 许可租约(兜底自动回收) | 600 秒 = 10 分钟,比业务最长耗时大一些 |
poll-interval-ms | 等待者轮询间隔 | 200 ms,下篇详细讲 |
为了让后文的场景描述更具体,咱们把这家在线教育公司的配置定下来:max-concurrent=3,部署两台机器。促销时刻同时来了 10 个用户提问。本篇要回答的问题是:前 3 个请求怎么抢到许可?如果只剩 1 个许可而 10 个请求同时来抢,谁能抢到?
限流入口:streamChat 直接委托 ChatQueueLimiter
先讲入口设计,因为它�决定了业务代码长什么样。