抢不到许可请求该等还是该拒
开篇引言
上一篇讲了排队限流的同步路径——streamChat 直接委托 ChatQueueLimiter.enqueue() 入队写 ZSET、tryAcquireIfReady 四阶段抢占(isPending 状态检查 / availablePermits 判断 / Lua 脚本 claim / RPermitExpirableSemaphore.tryAcquire)。镜头停在了在线教育公司促销那一刻:10 个请求同时打到两台机器,前 3 个走完四阶段拿到许可、提交到 chatEntryExecutor 跑业务。看起来挺顺。
但故事只讲了一半。第 4 到第 10 个请求呢?他们调 tryAcquireIfReady 时阶段 2 就被挡住了——availablePermits = 0,许可全��在前 3 个手里。返回 false 之后,进入了上一篇没展开的 scheduleQueuePoll。这 7 个请求安安静静地躺在 ZSET 里,前端的「思考中…」转圈圈还在转。
问题就来了:
- 他们怎么知道许可释放了?——前 3 个请求中,请求 1 是节点 B 上的,跑了 25 秒终于跑完释放了一个许可。节点 A 上等着的请求 4 怎么得到通知?
- 不通知就只能轮询吗?多久轮一次?——轮询太勤 Redis 受不了,轮询太疏用户等不起,得有个折中方案
- 等了 20 秒还没轮到自己怎么办?——总不能把 SSE 连接挂着不响应,得给用户一个明确的交代。但只关连接也太粗暴了,前端只能看到一个空白
- 如果许可被进程崩溃带走永远还不回来,集群总并发就这么一直降下去吗?——必须有兜底机制
- 应用关闭那一瞬间,还在排队的请求该怎么收尾?——daemon 线程虽然 JVM 退出会自动停,但留下半中断的状态总是不优雅
这一篇就来回答这五个问题。技术上对应五段内容——scheduleQueuePoll 调度轮询、Pub/Sub 跨集群广播 + PollNotifier 防惊群、超时拒绝写会话记忆、Ticket.cleanup() 幂等清理 + lease 兜底、Spring destroyMethod 优雅关闭。讲完之后再回头看排队限流的全链路图,最后给整个 AI 知识问答 18 篇做一次完整收束。
需要提醒一下:上一篇结尾已经讲过,异步等待路径(scheduleQueuePoll)、PollNotifier、Ticket.timeout() 等逻辑现在都住在 FairDistributedRateLimiter 里,ChatQueueLimiter 只负责 SSE 业务编排。超时拒绝的业务处理(写会话记忆、推 SSE 事件)通过 AcquireRequest.onTimeout 回调交给 ChatQueueLimiter。本篇会反复在这两层之间切换,先搞清楚谁干什么,后面读起来会顺很多。
听起来很合理,但实际跑起来你会发现细节多得吓人——光「通知所有等待者」一句话,背后就藏着跨集群广播、防惊群、防丢失、自动清理、优雅关闭好几层问题。这是排队限流「看起来很简单实际很复杂」的地方,本篇要把这几层一层一层揭开。
等待路径的入口:scheduleQueuePoll
1. 一张图看完整等待流程
先用一张活动图把单个 poller 的生命周期串起来。
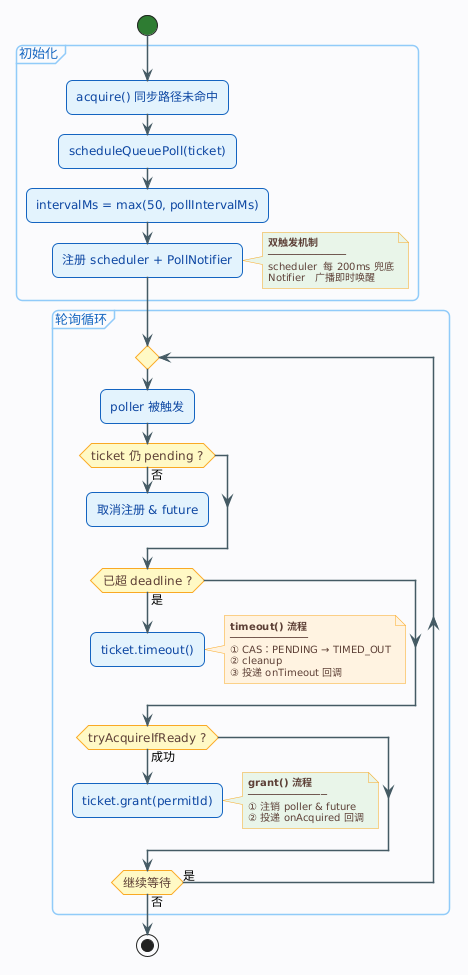
整个生命周期就三个出口:被取消、超时、抢到。Ticket 状态机保证三个出口互斥——PENDING 只能单次 CAS 转到 CANCELLED、TIMED_OUT、GRANTED 之一。无论走哪个出口,Ticket.cleanup() 都会被执行:幂等地移队、删除 entry 标记、释放许可(仅非 GRANTED 状态下)、注销 poller、取消 future。
2. scheduler 的角色
scheduleQueuePoll 用的调度器是一个小线程池,在 FairDistributedRateLimiter 的构造函数里创建:
String threadPrefix = name.replace(':', '_');
int schedulerSize = Math.min(4, Math.max(2, Runtime.getRuntime().availableProcessors() / 2));
AtomicInteger threadCounter = new AtomicInteger();
this.scheduler = new ScheduledThreadPoolExecutor(schedulerSize, r -> {
Thread t = new Thread(r);
t.setName(threadPrefix + "_scheduler_" + threadCounter.incrementAndGet());
t.setDaemon(true);
return t;
});
线程数根据 CPU 核数动态计算——Math.min(4, Math.max(2, cpu / 2)),最少 2 个、最多 4 个。线程名用限流器的 name 做前缀(冒号替换成下划线)加递增编号,比如 rag_global_chat_scheduler_1、rag_global_chat_scheduler_2——一眼就能在线程 dump 里看到是哪个限流器的第几个调度线程。
为什么不是单线程?因为这个调度器不只跑 poller 的周期任务,还被 PollNotifier 复用来跑广播触发的扫描。促销时刻广播和周期轮询同时在跑,2~4 个线程能更及时地消化任务,避免单线程排队延迟。但线程数也不需要太多——poller 本身做的事很轻:查状态、查时间、调 tryAcquireIfReady,几毫秒到几十毫秒就完事。
设为 daemon 的理由是不阻塞 JVM 退出——主线程没了 daemon 线程会自动收掉。但即使如此,本篇后面会讲 stop() 还是会主动 shutdown 一下,让正在跑的 poller 走完,不留半中断状态。
3. scheduleQueuePoll() 代码逐段解读
重构后 scheduleQueuePoll 变得非常简洁——所有状态都收拢在 Ticket 里,不再需要把 queue、requestId、permitRef、cancelled、question、conversationId、userId、emitter、onAcquire 九个参数逐个传进来。完整代码:
private void scheduleQueuePoll(Ticket ticket) {
int interval = Math.max(50, pollIntervalMsSupplier.getAsInt());
Runnable poller = () -> {
if (!ticket.isPending()) {
ticket.unregisterFromNotifier();
ticket.cancelFutureQuietly();
return;
}
if (System.currentTimeMillis() > ticket.deadline) {
ticket.timeout();
return;
}
tryAcquireIfReady(ticket);
};
ticket.future = scheduler.scheduleAtFixedRate(poller, interval, interval, TimeUnit.MILLISECONDS);
pollNotifier.register(ticket.requestId, poller);
}
下面分四块讲。
3.1 intervalMs 和 deadline
int interval = Math.max(50, pollIntervalMsSupplier.getAsInt());
interval 是轮询间隔。从配置取 poll-interval-ms(默认 200),但用 Math.max(50, ...) 兜底——配低于 50ms 的话会强制拉到 50ms。为什么?50ms 是经验值,比这个更短的轮询会让 Redis 命令频繁被触发,完全没必要——许可释放是事件级别的事,跑得再勤也快不过 Pub/Sub 的即时唤醒。
deadline 不在这里算——它已经在 Ticket 构造时就算好了:
Ticket(AcquireRequest req) {
this.req = req;
this.deadline = System.currentTimeMillis() + req.maxWaitMillis();
}
deadline 是绝对时间戳——「我最晚等到几点几分几秒几毫秒」。这样比每次比较「已等待时长 < max-wait-seconds」更直观,poller 内部一次 System.currentTimeMillis() > ticket.deadline 比较就完事。
回到在线教育公司:max-wait-seconds=20,poll-interval-ms=200。也就是说每个等待者最多等 20 秒,期间每 200ms 兜底跑一次 poller,加上 Pub/Sub 即时唤醒。20 秒 / 200ms = 100 次轮询,对单个等待者来说,开销可控。
3.2 定�义 poller lambda 的三个分支
poller 是一个 Runnable,每次被触发都跑一遍这段逻辑。三个 if 分支对应三个出口:
第一个分支处理取消或已完成:
if (!ticket.isPending()) {
ticket.unregisterFromNotifier();
ticket.cancelFutureQuietly();
return;
}
isPending() 内部就是 state.get() == State.PENDING——只有还在排队的 Ticket 才有继续抢占的必要。如果状态已经不是 PENDING(可能是 CANCELLED——前端关连接触发 ticket.cancel();也可能是 GRANTED——被别的 poller 触发路径抢先成功了),直接注销 + 取消调度走人。
和老版本用 cancelled.get() 不同,Ticket 状态机覆盖了更多终态——不只是外部取消,grant 成功后的清理也会让 isPending() 返回 false,避免重复执行。
第二个分支处理 deadline:
if (System.currentTimeMillis() > ticket.deadline) {
ticket.timeout();
return;
}
这是超时拒绝的入口。ticket.timeout() 内部做三件事:
void timeout() {
if (!state.compareAndSet(State.PENDING, State.TIMED_OUT)) {
return;
}
cleanup();
submitSafely(req.onTimeout(), "onTimeout");
}
- CAS
PENDING → TIMED_OUT:抢占终态。如果 CAS 失败说明已经被cancel()或grant()抢先了,直接 return cleanup():幂等清理——从 ZSET 移除自己、删除 entry 标记、释放已持有的许可(若有,非 GRANTED 状态下)、广播通知、注销 poller、取消 futuresubmitSafely(req.onTimeout(), "onTimeout"):把onTimeout回调提交到onAcquiredExecutor执行。在 Chat 场景里这个回调就是() -> handleReject(question, conversationId, emitter)——写会话记忆 + 推 SSE 拒绝事件
注意 cleanup() 已经包含了注销 poller 和取消 future 的动作,所以 poller lambda 里不需要再显式调一遍——timeout() 一个方法搞定一切。
第三个分支处理抢到:
tryAcquireIfReady(ticket);
调上一篇讲过的 tryAcquireIfReady 四阶段。返回 true 说明许可到手了——ticket.grant() 内部已经注销 poller、取消 future、提交业务到 chatEntryExecutor,poller 的使命结束。返回 false 说明还没轮到自己(许可没空 / claim 失败 / 二次 isPending 短路),poller 不动作,等下次触发再试。
3.3 ticket.future 赋值
ticket.future = scheduler.scheduleAtFixedRate(poller, interval, interval, TimeUnit.MILLISECONDS);
和老版本的 ScheduledFuture<?>[] futureRef = new ScheduledFuture<?>[1] 一元素数组 trick 相比,现在直接把 future 存在 Ticket 的 volatile 字段上,更直观。Ticket 是 FairDistributedRateLimiter 的内部类,poller lambda 闭包捕获的是 ticket 引用(effectively-final),通过 ticket.future 间接访问 ScheduledFuture,绕过了 lambda 闭包的 effectively-final 限制。
cancelFutureQuietly() 是 Ticket 的实例方法,做幂等取消:
void cancelFutureQuietly() {
ScheduledFuture<?> f = future;
if (f != null && !f.isCancelled()) {
f.cancel(false);
}
}
scheduleAtFixedRate(task, initialDelay, period, unit)——首次延迟 interval 后跑,之后每隔 interval 跑一次。注意这里 initialDelay 也是 interval 而不是 0——因为同步路径的 tryAcquireIfReady 刚跑过一次失败了,再立刻跑一次浪费,等 200ms 之后再试。
3.4 pollNotifier.register
最后一行:
pollNotifier.register(ticket.requestId, poller);
把 poller 注册到广播通知器。这就是「两条触发路径合并」的关键——同一个 poller,既被 scheduler 周期性调用,也被 PollNotifier 在收到广播时调用。两个路径都不会丢,重复调用也是安全的(poller 内部三个分支都是状态判断)。
4. 三个出口的清理动作
把三个出口的清理动作整理成一张表:
| 出口 | 触发条件 | 共用清理 | 额外动作 |
|---|---|---|---|
取消(CANCELLED) | 客户端断连 / SSE 超时 / 推送出错 → ticket.cancel() | ticket.cleanup()(移队 + 删 entry 标记 + 释放 permit + 广播 + 注销 poller + 取消 future) | 无(已被取消,不触发业务回调) |
超时(TIMED_OUT) | 等待超过 max-wait-seconds → ticket.timeout() | ticket.cleanup() | submitSafely(onTimeout):写记忆 + 推 SSE reject |
抢到(GRANTED) | tryAcquireIfReady → ticket.grant() | ticket.unregisterFromNotifier() + cancelFutureQuietly() | 提交 onAcquired 到 chatEntryExecutor,permit 由 try/finally 包装管理 |
和老版本相比,最大的变化是 cleanup 被统一收进了 Ticket.cleanup() 一个方法——移队、删除 entry 标记、释放许可(非 GRANTED 状态下)、广播、注销、取消 future,所有子操作各自幂等,调多少次都安全。三个出口不再需要手动拼凑清理逻辑,减少了遗漏风险。
这种「状态机 + 统一 cleanup」的模式是写多线程异步代码的好习惯。CAS 保证终态互斥(回调最多触发一次),cleanup 幂等保证资源不泄漏(调多少次都安全),两者配合让并发代码变得可推理。
Pub/Sub 跨集群广播:节点 A 怎么知道节点 B 释放了许可
scheduleQueuePoll 注册了两条触发路径,scheduler 那条已经讲完。剩下一条是 PollNotifier——靠 Redis Pub/Sub 跨集群唤醒。这一节先把广播链路讲清楚,下一节再深入 PollNotifier 的防惊群设计。