出报告
上一篇把 RAGAS 的五个坑讲完了——同源偏置、单跑方差、中文 NaN、成本失控、Judge 误判。你现在知道哪些分数差异是真的,哪些是噪声,怎么用多轮取均值压制方差,怎么用人工校准修正误判。
指标也全算完了。_scores.json 里躺着十几个指标的 overall、by_intent_l1、by_intent_l2、per_sample——从意图准确率到 TTFT P50,从 faithfulness 到 answer_correctness,该有的都有了。
然后呢?
打个比方,你考完试了,答题卡已经批完了,每道题的分数都有了。但你把一张写满分数的 Excel 发到班级群里,家长看得懂吗?班主任能拿着这张表在家长会上讲两分钟吗?你自己能从里面一眼看出哪个知识点最弱、��下一步该补哪块吗?
评测报告也是一样的道理。_scores.json 是原始成绩单,但不同的人需要不同的呈现方式。CI 脚本只需要一个 JSON 判阈值,研发需要看逐样本明细找具体问题,老板需要打开浏览器看几个大数字和一张漂亮的看板。
这篇讲怎么把指标变成不同角色能消费的报告——三种人,三种产物,一套数据源。
报告产物总览
1. 三类受众,各看什么
想一想你平时工作里的场景:
- CI 流水线只需要一个 JSON,判断 Hit@5 有没有跌破 90%,跌了就阻断合入——它不需要看图表,不需要看失败样本,只需要一个布尔值
- 研发同事想知道哪几条样本最差、差在哪个环节——需要逐样本的明细表和失败归因,能直接定位到具体 query
- 技术负责人要在周会上花两分钟看一眼系统质量——需要几个大数字加一张漂亮的看板,翻几页就能讲完
一份报告服务不了这三种需求。所以评测产出拆成了五个文件,各司其职:
| 产物 | 文件路径 | 受众 | 格式 | 用途 |
|---|---|---|---|---|
_scores.json | reports/<run>/ | CI / 自动化脚本 | JSON | 所有指标的全量数据,给脚本读 |
report.md | 同目录 | 研发 / Reviewer | Markdown | 指标总览 + 意图��切片表 |
per_sample.csv | 同目录 | 研发 / Reviewer | CSV | 逐样本明细 + 人工复核列 |
failures.jsonl | 同目录 | 研发 / Reviewer | JSONL | 失败样本归因,一行一条 |
slides.html | 同目录 + reports/latest_slides.html | 老板 / 周会 | HTML | 16:9 横向翻页,浏览器全屏演示 |
所有产物都在 reports/<run>/ 目录下。<run> 是 runs 文件的名称,类似 v1_20260601_143022——哪一次录制产生的结果,一目了然。
2. 数据怎么流的:三段缓存
五个产物不是各自独立生成的,它们共享同一个数据源 _scores.json。而 _scores.json 本身也不是凭空出来的——整个评测的数据流是三段式的,每段产物独立缓存:
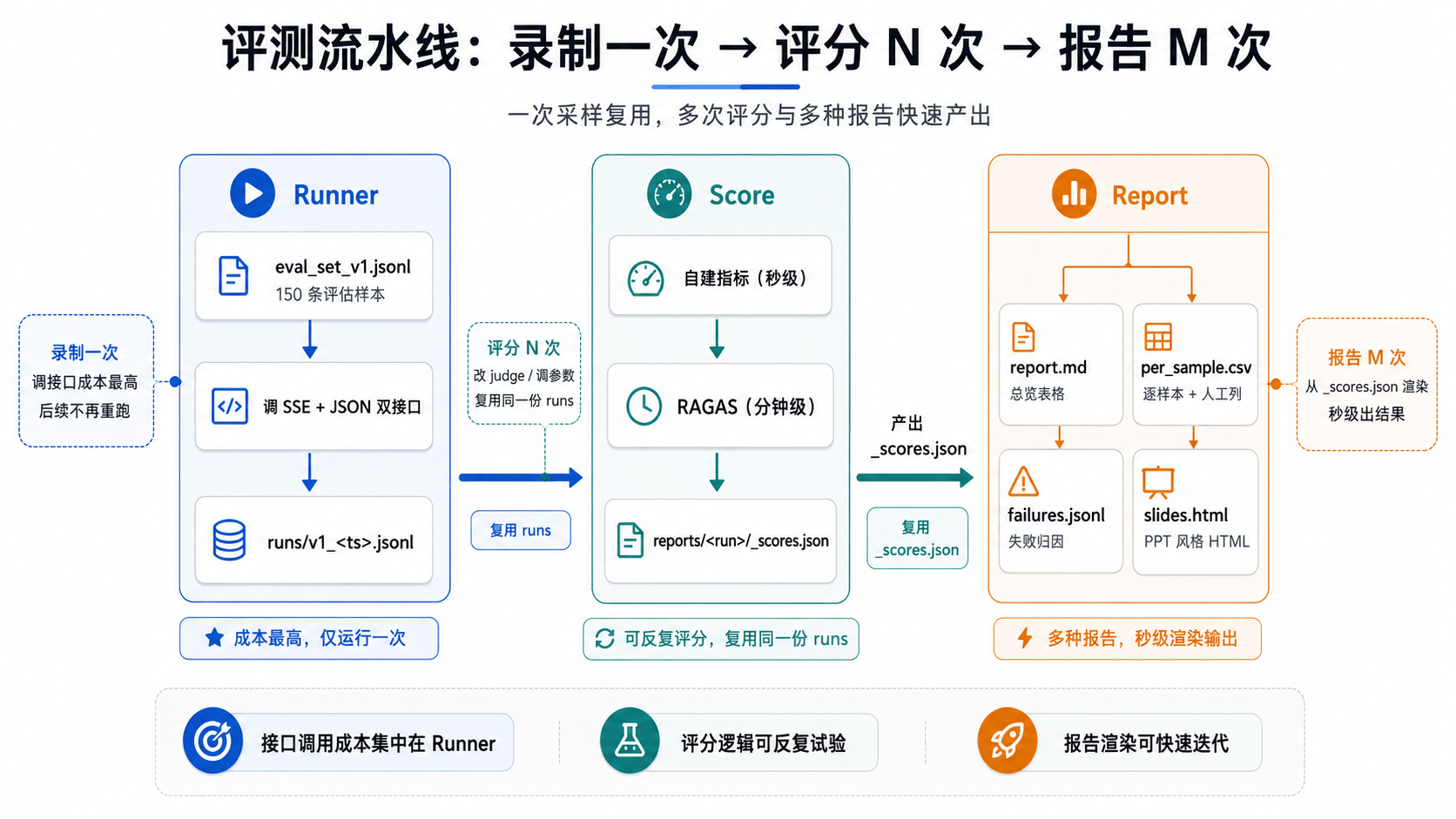
用一句话概括这个设计的核心思路:录制一次,评分 N 次,报告 M 次。
runner 跑一次调两个接口,成本最高(RAGAS 要花钱调 judge),录好之后落 runs/*.jsonl。score 阶段从 runs 文件算指标,改了 judge 模型或调了参数之后可以复用同一份 runs 重跑——不花接口费。report 阶段从 _scores.json 渲染各种产物,秒级出结果——改失败判定阈值、调报告格式、重跑人工校准,都不需要重新调被评系统的接口。
三段缓存互不耦合,这是优化过程中反复跑评测的基础。
给研发看的三份报告
研发需要的是能直接定位问题的信息:整体水平怎么样、哪个场景最差、哪几条样本出了什么问题。这三份文件从粗到细,覆盖了研发 review 评测结果的完整流程。
1. report.md:一页纸总览
report.md 由 markdown.py 的 write_all() 函数生成,包含三部分内容:
自建指标总览表:按 BASELINE_ORDER 列出 13 个自建指标——intent_top1、Hit@1/3/5/10、Recall@1/3/5/10、MRR@10、误拒率、错答率、TTFT 等,每个给出 overall 值。一眼看到系统各个环节的健康度。
RAGAS 指标表:5 个 RAGAS 指标的 overall 值——faithfulness、answer_relevancy、answer_correctness、context_precision、context_recall。语义层面的质量判断。
二级意图切片表:这是这份报告最有价值的部分。每个二级意图一行,列出该意图下的核心指标值。
切片表的价值在哪?举个例子:overall Hit@5 = 90%,看起来还不错。但切到 by_intent_l2 一看,S1_选购推荐 只有 60%,S14_退换货咨询 是 100%。退换货类问题检索得很好,但选购推荐类一半以上没命中——90% 的 overall 把一个严重问题给掩盖了。
优��化资源永远有限。切片表让你知道该把精力集中在哪几个意图场景上,而不是眉毛胡子一把抓。
2. per_sample.csv:逐样本明细 + 人工复核列
report.md 告诉你哪个意图最差,per_sample.csv 让你钻到每一条样本里去看。
每行一条评估样本,列分三组:
| 列类型 | 包含内容 |
|---|---|
| 基础信息列 | query_id、intent_l1、intent_l2、difficulty、requires_rag、final_status |
| 指标值列 | 所有指标的 per_sample 值(Hit@5 是 0 或 1、faithfulness 是 0~1 的浮点数等) |
| 人工复核列 | 5 个 *_manual 空列(对应 5 个 RAGAS 指标) |
前两组好理解,重点说人工复核列。上一篇讲过 RAGAS 偶尔会误判——judge 给某条样本的 faithfulness 打了 0.3,但你人工看过之后发现回答完全忠实于上下文,只是拆 claim 的方式有问题。这时候不需要重跑 RAGAS(贵且慢),直接在 CSV 里改就行。
2.1 人工复核的工作流程
整个流程分五步:
score阶段跑完后生成per_sample.csv,5 个 RAGAS 指标各自对应一个{metric_name}_manual列,初始为空- Reviewer 打开 CSV(Excel 或任何编辑器都行),对有疑问的样本在对应
*_manual列填入人工分数——支持0.8、80%、0.8000这几种格式 - 重跑
python -m eval rag report命令 load_manual_overrides()自动读取已填写的人工分数apply_manual_overrides()按人工列优先、空值回退 RAGAS 的策略重算——替换per_sample对应值,重算overall、by_intent_l1、by_intent_l2
重跑后的报告和 slides 自动使用修正后的分数。meta 里会记录 manual_overrides 数量和 manual_policy,所有人都能看到有多少分数被人工修正过——透明可审计。
2.2 为什么需要这个设计
听起来有点绕——为什么不直接重跑 RAGAS 让 judge 再评一次?
原因很现实:重跑一次 RAGAS 要十几分钟、花几十块钱,而且重跑也不保证 judge 这次就判对了(上一篇讲过,方差还在)。人工校准是最后一道防线——零成本、秒出、结果可控。
整个流程不需要重新调 judge API,只是在 report 阶段用人工分替换自动分再重算。
不需要每次跑完都逐条审。建议在 Release 前对低分样本抽查、在分数异常波动时查下降最多的指标、在高风险意图(售后政策、保修条款、价格类)上不管分高低都看一眼。大部分样本的自动评分是靠谱的。
3. failures.jsonl:失败样本归因
report.md 告诉你整体水平,per_sample.csv 让你逐条看分数,failures.jsonl 更进一步——直接告诉你哪些样本出了问题、问题出在哪个环节,是研发最直接的行动指引。
3.1 五种失败类型
一条样本只要命中以下任一条件就算失败:
| 失败类型 | 判定条件 | 含义 |
|---|---|---|
hit@5_miss | Hit@5 == 0 | 检索前 5 完全未命中目标文档 |
answer_correctness_low | answer_correctness < 0.5 | 端到端答案严重不对 |
faithfulness_low | faithfulness < 0.5 | 严重幻觉,过半内容没有上下文支撑 |
refused_when_required | requires_rag=true 且检索结果为空 | 应该走 RAG 但被误拒了 |
over_retrieved | requires_rag=false 且检索结果非空 | 不该走 RAG 但过召回了 |
这五种覆盖了 RAG 系统最常见的故障模式:检索没命中、答案不对、幻觉严重、误拒、过召回。
3.2 多原因合并:看到完整故障链路
关键设计:一条样本可以同时命中多条失败原因。
举个例子,某条样本的 failure_reasons 是 ["hit@5_miss", "answer_correctness_low(0.35)"]——检索前 5 完全没命中目标文档,答案正确性也只有 0.35。这两个原因不是巧合,而是因果链:检索没命中 → 给模型的上下文里没有正确信息 → 答案自然也差了。
如果只标一个原因,你可能会以为是生成环节的问题(answer_correctness 低),去调 prompt。但真正的根因在检索——多原因合并让你看到完整的故障链路,直接定位根因。
每条失败记录包含完整上下文:
{
"query_id": "S1-03",
"intent_l1": "SUPPORT",
"intent_l2": "S1_选购推荐",
"requires_rag": true,
"user_input": "3000 元左右的手机有什么推荐?",
"reference_doc_ids": ["product_phone_mid"],
"retrieved_doc_ids": ["product_phone_high", "product_phone_low"],
"first_token_ms": 2340,
"latency_ms": 8500,
"final_status": "success",
"response_preview": "为您推荐以下手机...",
"failure_reasons": ["hit@5_miss", "answer_correctness_low(0.35)"],
"scores": {"hit@5": 0.0, "answer_correctness": 0.35, "faithfulness": 0.72}
}
拿到这条记录,研发怎么用?看 failure_reasons 知道哪个环节出了问题。看 retrieved_doc_ids vs reference_doc_ids 知道召回偏了多少——该找 product_phone_mid(中端手机),实际找到了 product_phone_high 和 product_phone_low(高端和低端),价格区间路由错了。看 response_preview 知道模型具体回了什么。
一条记录,从故障现象到可能的根因,信息全了。
给负责人看的 slides.html
研发看 markdown 和 CSV 够了,但老板不会打开这些文件。周会汇报需要的是:打开浏览器,全屏,翻页,几个大数字,几张图表,两分钟讲完。
slides.html 就是干这个的。由 slides.py 的 build_slides() 函数生成,16:9 比例的横向翻页 HTML 文件,浏览器全屏打开即可演示。同时会复制一份到 reports/latest_slides.html,方便快速打开最新报告。