性能指标的口径选择
上一篇讲完了意图准确率和检索指标——意图 Top-1 衡量路由对不对,Hit@K / Recall@K / MRR 衡量文档找到没、找全没、排得好不好。自建指标还剩最后一组:性能。
对话产品的性能度量跟传统 API 有一个本质区别:用户不需要等完整回答出来才知道系统有没有响应。SSE 流式输出下,第一个字蹦出来的那一刻,用户的等待焦虑就解除了——后面的字像打字机一样逐个出现,体感是流畅的。所以性能指标的核心不是整流耗时,而是首字延迟——TTFT(Time To First Token)。
首字延迟相对来说是很重要的,作为一个C端用户来说,肯定是越快返回内容用户体验越好。如果问个简单问题,系��统需要10-20秒的输出才能首字响应,除非很重要的问题,否则用户是没有耐心等待的。这种会间接造成用户的购买以及好感度流式。
整流耗时的误导:答案越长越慢
先看一个对比:
| query A:简短回答 | query B:详细回答 | |
|---|---|---|
| 回复长度 | 50 字 | 500 字 |
| TTFT | 4800ms | 5100ms |
| 整流耗时 | 10s | 30s |
如果只看整流耗时(latency_ms),query B 的性能比 A 差了 3 倍。但 TTFT 几乎一样——用户等答案首字的时间差不多,都在 5 秒左右,只是 B 的答案更详细,字蹦得更久而已。
整流耗时的问题很清楚:它跟生成的 token 数量线性相关。答案越长,整流耗时越大——但这不代表用户体验差了。拿它做性能基线会误导优化方向:你会发现性能最差的 query 全是回答最详细的那些,而它们的用户体验可能恰恰最好。
用一张时间轴来看两者的覆盖范围:
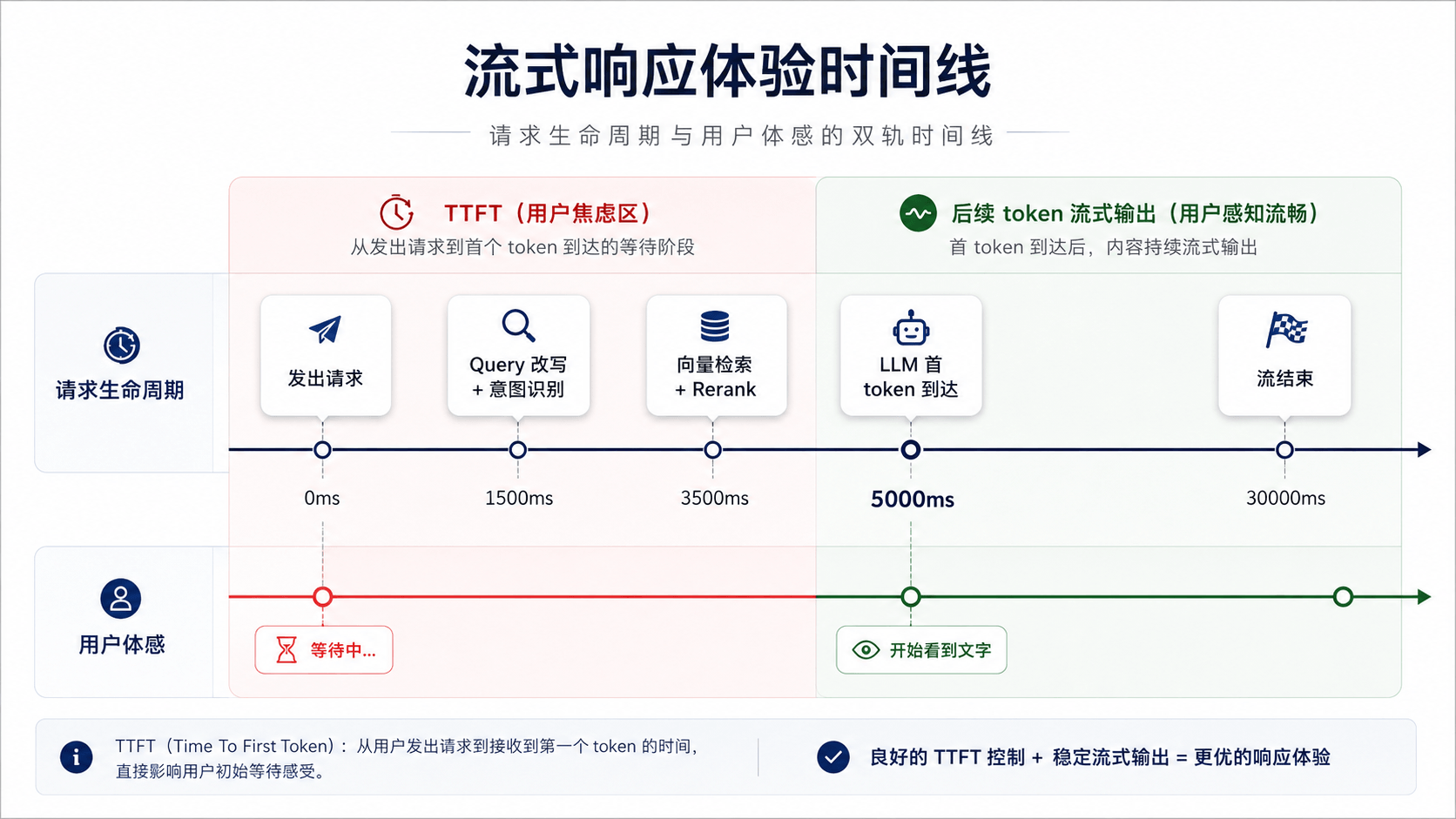
TTFT 覆盖的是从请求发出到答案首字出现的这段时间——Query 改写、意图识别、向量检索、Rerank、LLM 生成第一个 token,这些串行步骤全算在里面。这条链路走下来,5 秒左右的 TTFT 是常态。后面的 token 逐个输出只是增加了整流耗时,不影响用户对响应速度的感知。
TTFT:用户体感的唯一卡点
1. 口径回顾
TTFT 的精确采集口径在第 4 篇已经详细讲过,这里只回顾关键定义:只算 type=response 的首个非空 delta 到达时间,不算 thinking。
如果模型开了深度思考模式,thinking 首字可能 23 秒就到了,但 response 首字要等到 68 秒(思考过程本身也需要时间)。TTFT 记的是 response 首字的时间——这是用户看到答案开始出现的时间,不是思考过程开始的时间。思考链对用户来说是隐藏的,不构成体感卡点。
2. 取不到时的回退
两种情况下 first_token_ms 会是 None:
- 老版本 run 文件:早期 runner 还没实现 TTFT 采集,所有样本的
first_token_ms都为空 - 异常请求:被 reject、出错、或者全程只有 thinking 没有 response
回退逻辑只有 3 行:
def _first_token_or_total(r: EvalRecord) -> int | None:
"""老 runs 没采 first_token_ms 时回退到 latency_ms。"""
return r.first_token_ms or r.latency_ms or None
优先用 first_token_ms;没有就退回到 latency_ms(整流耗时);都没有返回 None,该样本不参与性能指标。
回退到 latency_ms 不完美——整流耗时远大于 TTFT——但有两个保底:同一批老 run 文件的所有样本都会统一回退,不会出现一半用 TTFT 一半用整流的混搭;而且只要重新跑一次 runner 就能拿到真实 TTFT,老数据只是过渡。