ReAct 是什么?推理与行动交替运转
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们给比特严选智能体画了张蓝图:八大任务、四个复杂度等级,第一版选出四个任务和五个工具。蓝图画完,你已经知道这个智能体要解决什么问题、手里有哪些家伙事儿。
但蓝图归蓝图,真要写代码,还有一个最根本的问题没回答——Agent 循环里那个想-做-看到底是个什么范式?凭什么让大模型一边想一边干就能把事办成?
这一篇,咱们正式进入第二部分《ReAct 核心》。先不敲 Java,把 ReAct(Reasoning + Acting,推理 + 行动)这个范式的来龙去脉讲透:它从哪来、为什么管用、跟纯思维链和纯工具调用有什么本质区别。概念理清楚了,下一篇才好真刀真枪地手写循环。
先看两种走极端的做法
在讲 ReAct 之前,咱们先看看两种看起来合理、但各有硬伤的方案。还是拿比特严选那个老例子:用户说“我上周买的扫地机不回充了,修不好我想退,订单号 88231”。
1. 只想不干:纯思维链
第一种做法:让大模型使劲想,一步步推理,但不给它调工具的能力。
这就是所谓的思维链(Chain of Thought,简称 CoT)——给模型一个提示,让它把推理过程一步步写出来,最后给出答案。
你把用户的问题丢给模型,它可能会这样输出:
用户想退订单 88231 的扫地机。
我需要先确认这笔订单的状态和签收时间。
假设订单是上周下的,大概 6 月 22 日左右签收。
今天大约是 6 月 29 日,刚好在七天退货窗口内。
所以用户应该可以申请退货。
最终答案:您的订单在七天退货期内,可以申请退货。请前往 APP 的售后页面提交退货申请。
看起来挺像那么回事?但仔细一看,全是编的。
它说“假设订单是上周下的,大概 6 月 22 日左右签收”——它根本没查订单系统,怎么知道是 6 月 22 日签收的?它说“今天大约是 6 月 29 日”——模型不知道今天几号,这个日期也是猜的。最终得出“可以申请退货”——前提都是假的,结论能靠谱吗?
这就是纯思维链的要害:推理链条再漂亮,一旦中间某个环节需要真实数据,它就只能靠编。这种编�出来的数据看起来合理,但跟真实情况可能完全对不上。在客服场景里,用户听了你的话去申请退货,结果发现根本不在退货窗口内——这种体验比不回答还糟。
2. 只干不想:纯工具调用
第二种做法走另一个极端:让模型直接调工具,不用想那么多,看到关键词就调对应的工具。
这种做法有时候叫 Act-only(只行动),模型的输出大概是这样:
Action: queryOrder
Input: 88231
工具返回了订单详情,然后模型接着调:
Action: applyRefund
Input: 88231
等等,中间那步呢?模型根本没判断今天是几号、签收有没有超过七天,就直接�发起退款了。万一这笔订单签收已经超过七天了呢?退款请求要么被系统拒绝(好情况),要么真退了不该退的货(坏情况)。
纯工具调用的问题正好跟纯思维链反过来:它有手有脚,但脑子不转。工具倒是调了,但调之前没想清楚该不该调、调完之后没分析结果,就像一个不过脑子的客服,用户说退就退,连基本的判断都省了。
3. 问题的根源
把这两种做法摆在一起看,问题就清楚了:
| 做法 | 擅长 | 缺陷 | 在退款场景的表现 |
|---|---|---|---|
| 纯思维链(CoT) | 推理过程清晰、逻辑严密 | 没法获取真实数据,只能靠编 | 编了个签收日期,结论不可信 |
| 纯工具调用(Act-only) | 能查真实数据、能触发操作 | 不会分析结果、不会做判断 | 没判断退货条件就直接退款 |
一个只会想不会干,一个只会干不会想。你想要的是一个既会想又会干的——想一步,干一步,干完看看结果,再想下一步该怎么走。
这就是 ReAct。
把三种做法摆在一张图里看,差异一目了然:
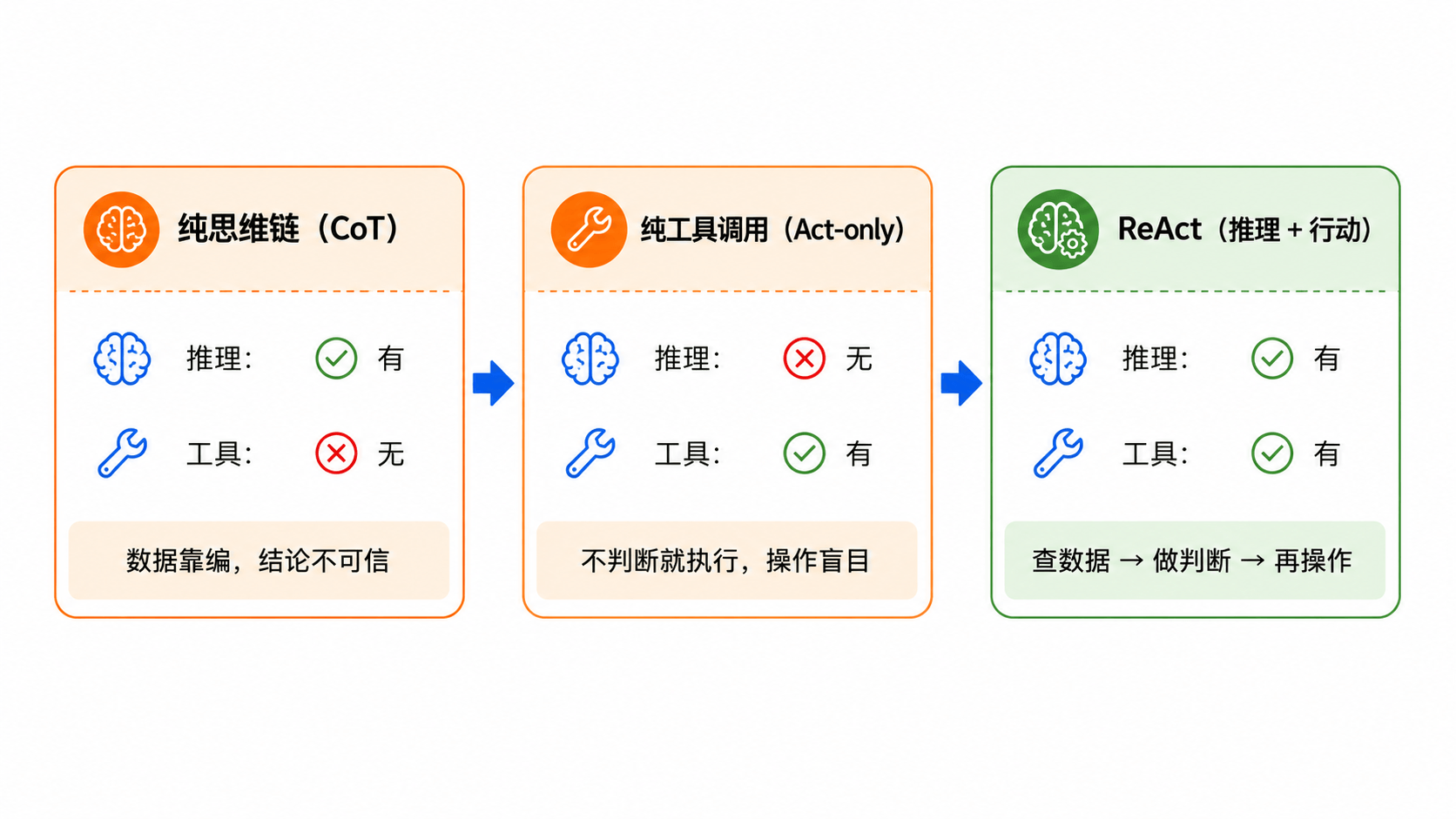
ReAct 是什么
1. 一句话定义
ReAct 是 2022 年由普林斯顿大学和 Google 的研究团队提出的一种 Agent 范式,全名是 Reasoning + Acting,直译就是推理 + 行动。核心思想用一句话概括:
让大模型把推理(Thought)和行动(Action)交替进行——先想清楚下一步该干什么,再去干,干完看结果,再想下一步。
论文标题叫《ReAct: Synergizing Reasoning and Acting in Language Models》,2022 年 10 月首次公开,后正式发表于 ICLR 2023。如果你好奇细节可以去读原文,但本篇会把核心思想讲透,不需要你啃论文。
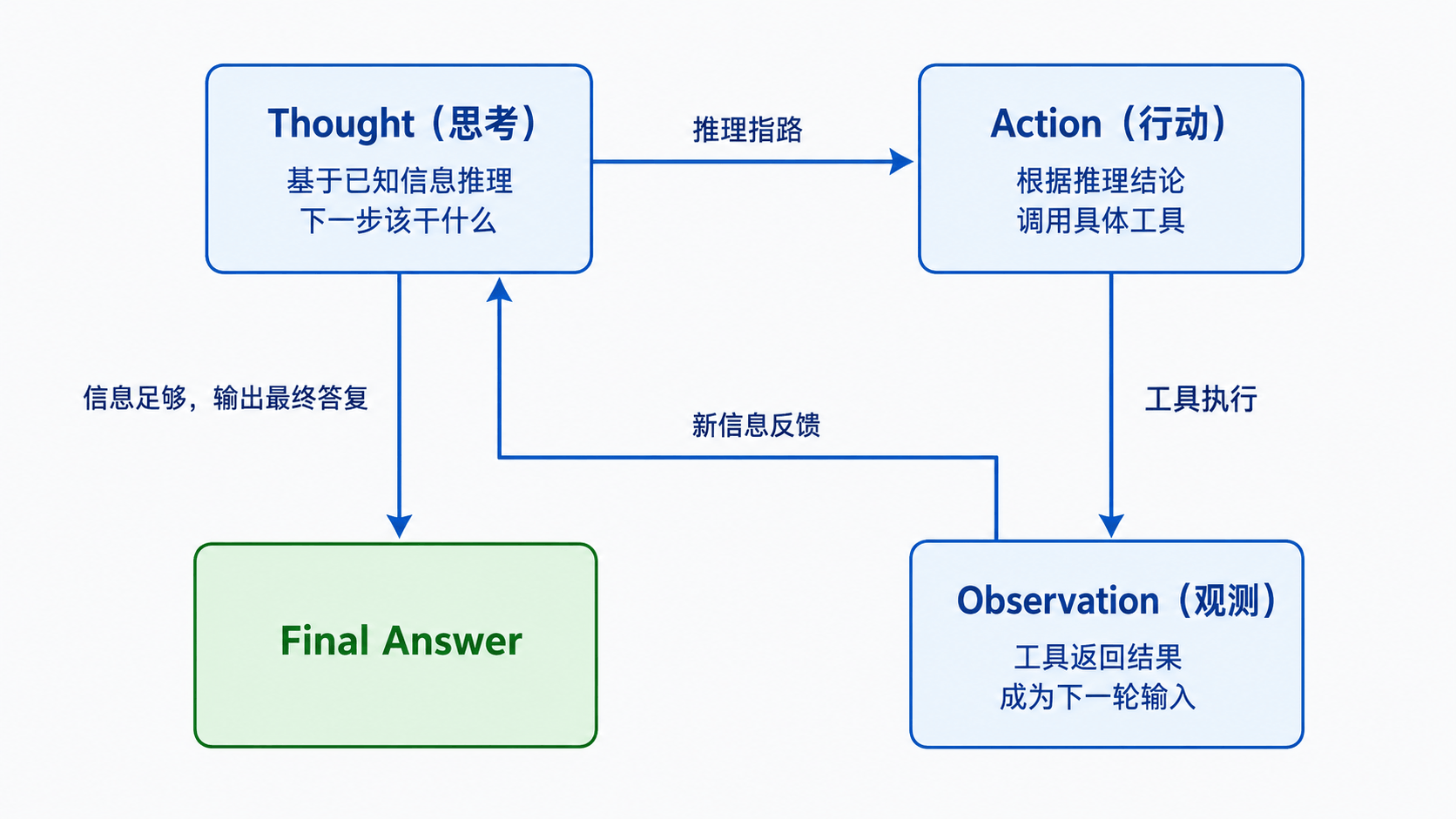
2. Thought-Action-Observation 三元组
ReAct 的运转单元是一个三元组:Thought → Action → Observation,每转一圈就是一组。
- Thought(思考):大脑基于当前已知的一切,推理出下一步该干什么。这里的关键是大脑要把推理过程说出来,不是闷在心里直接给动作。
- Action(行动):根据思考的结论,调用一个具体的工具。
- Observation(观测):工具执行后返回的结果。这个结果会被记下来,成为下一轮思考的输入。
循环就是这三步反复转:想完了干,干完了看,看完了再想。一直转到大脑认为信息够了、任务完成了,才给出最终答复。
这个循环画成图是这样的:
用比特严选退款那个例子�走一遍完整的 ReAct 格式,你就明白了。
3. 退款场景的 ReAct 完整轨迹
用户消息:「我上周买的扫地机不回充了,修不好我想退。订单号 88231。」
第一圈:
Thought: 用户想退订单 88231 的扫地机。我需要先查一下这笔订单的详情,
确认商品信息和签收时间,才能判断是否符合退货条件。
Action: queryOrder
Action Input: 88231
Observation: {"orderId":"88231","product":"比特 S10 Pro 扫地机",
"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收",
"trackingNo":"SF1234567890"}
第二圈:
Thought: 订单 88231 是比特 S10 Pro 扫地机,6 月 22 日签收,当前状态是已签收。
用户反馈商品故障,要判断能不能走质量问题退货,我需要知道今天的日期来确认是否在售后时限内。
Action: getCurrentTime
Action Input: 无
Observation: {"currentTime":"2026-06-29T14:30:00"}
第三圈:
Thought: 今天是 6 月 29 日,签收日期是 6 月 22 日,签收后第 7 天。用户反馈扫地机
无法回充且修不好,属于商品质量问题,签收 15 天内可以申请退货退款,
目前在售后时限内,符合退货条件。我现在��可以帮用户发起退款申请。
Action: applyRefund
Action Input: {"orderId":"88231","reason":"商品质量问题-扫地机无法回充,用户要求退货"}
Observation: {"success":true,"refundId":"RF20260629001","message":"退款申请已提交,
预计 1-3 个工作日到账"}
最终答复:
Thought: 退款申请已经成功提交,退款单号 RF20260629001,预计 1-3 个工作日到账。
信息齐全了,可以给用户最终答复。
Final Answer: 已经帮您提交了退款申请。您的订单 88231(比特 S10 Pro 扫地机)
属于商品质量问题,符合退货退款条件,退款单号为 RF20260629001,预计 1-3 个工作日原路退回。
如有问题可以随时联系我。
整个过程画成时序图,三圈的信息流一目了然:
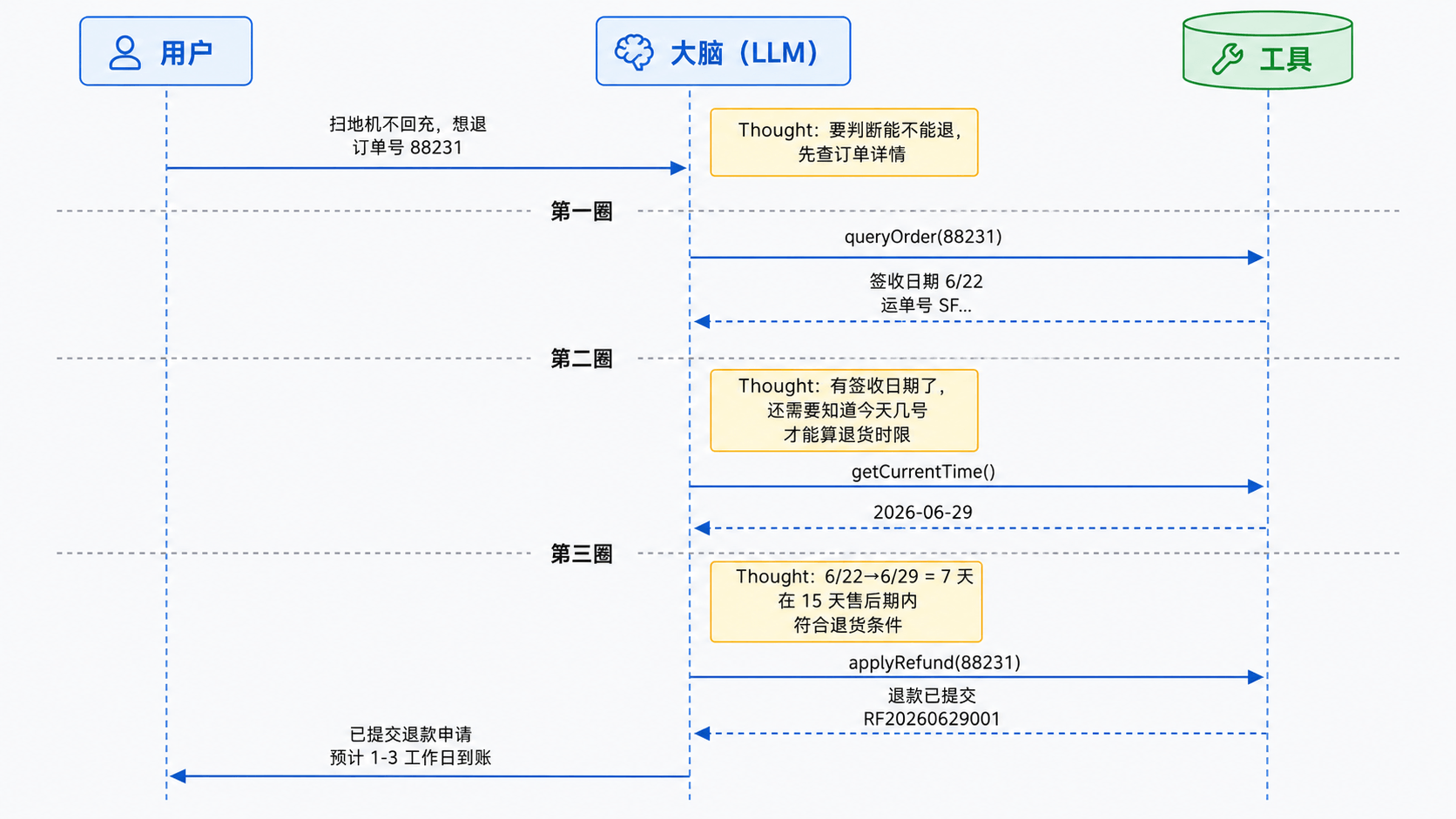
三圈循环,每一圈都是 Thought → Action → Observation。注意几个关键点:
- 每一步 Thought 都在分析当前局面:第一圈想到要先查订单,第二圈想到要知道今天日期来算时限,第三圈想到条件满足可以退款。推理不是一次性的,而是每一步都在根据新信息重新思考。
- Action 是 Thought 的直接产物:大脑想到“要查订单”,紧接着就去调
queryOrder;想到“要算时限”,就去调getCurrentTime。每个行动都有明确的推理依据。 - Observation 是下一轮 Thought 的输入:查订单拿回来的签收日期,成了第二轮推理的原材料;获取的当前时间,成了第三轮判断退货条件的依据。
对比一下前面两种极端做法:纯思维链会在第一步就编一个签收日期;纯工具调用会跳过第二步和第三步的判断直接退款。ReAct 两种能力都有,推理给行动指方向,行动给推理补信息,形成了一个正反馈循环。
为什么 ReAct 管用
1. 推理为行动指路
没有 Thought 的 Action 是盲目的。
在退款场景里,如果大脑不先想一想要判断退货条件需要知道今天日期,它就不会去调 getCurrentTime��,也就不会去算签收有没有超过七天。推理的价值在于:它让每一次工具调用都有目的,而不是碰运气。
打个比方,纯工具调用像一个拿着锤子到处找钉子的人——手里有什么工具就用什么,不管该不该用。有了 Thought,就像先看了设计图再动手——知道这颗钉子该敲在哪。
2. 行动为推理补信息
没有 Action 的 Thought 是空想。
模型再怎么推理,也推不出订单 88231 是 6 月 22 日签收的——这是存在订单系统里的真实数据,不是从已有信息能推导出来的。Action 的价值在于:它把真实世界的数据带回来,让推理建立在事实而不是幻觉之上。
还是那个比方:纯思维链像一个闭门造车的人——脑子转得飞快,但手头的信息全是自己编的。有了 Action,就像打开了窗户去看了一眼真实情况,推理才有了坚实的地基。
3. 交替形成正反馈
ReAct 最精妙的地方不是推理强,也不是行动强,而是两者交替运转形成了一个正反馈循环:
推理指出需要什么信息 → �行动去获取这个信息 → 获取的信息让推理更准确 → 更准确的推理指出下一步该做什么 → ...
每转一圈,大脑掌握的信息就多一点,判断就准一点,离最终目标就近一步。这就是为什么 ReAct 能处理多步骤、带条件判断的复杂任务——它不需要一上来就知道所有答案,而是一步步把答案拼出来。
下面这张图把这个正反馈画出来:
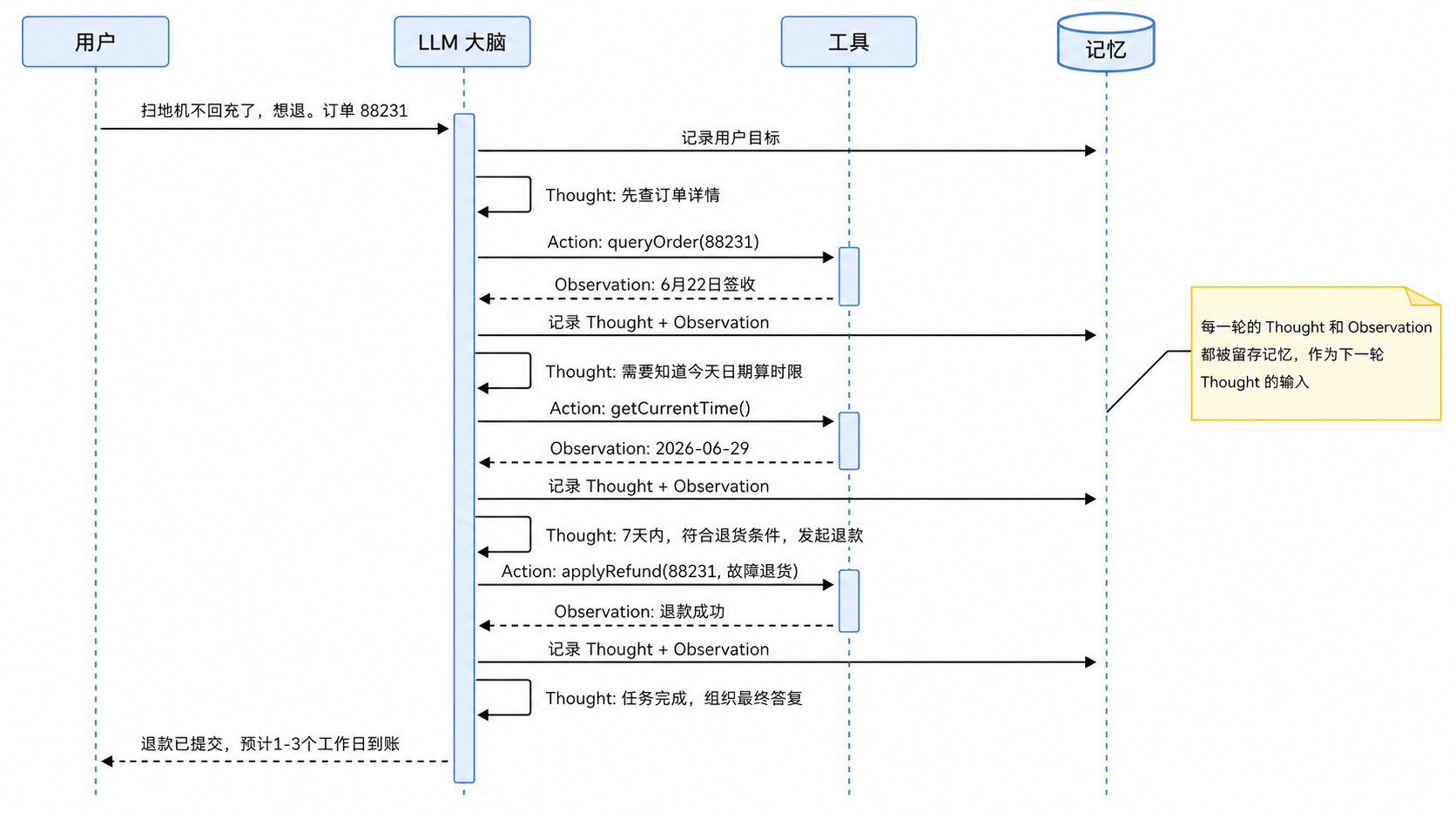
ReAct vs CoT vs Act-only:三者对比
讲到这里,三种范式的区别应该很清楚了。咱们用一张表做个全面对比:
| 维度 | 纯思维链(CoT) | 纯工具调用(Act-only) | ReAct |
|---|---|---|---|
| 推理能力 | 强,完整的推理链条 | 弱,不分析只执行 | 强,每步都有推理 |
| 工具调用 | 无,不能获取外部数据 | 有,但调用缺乏目的性 | 有,推理指导调用 |
| 幻觉风险 | 高,缺乏真实数据验证 | 低,数据来自真实系统 | 低,推理基于真实数据 |
| 盲目操作风险 | 低,不执行操作 | 高,缺乏判断就执行 | 低,先判断再执行 |
| 可解释性 | 高,推理过程清晰可读 | 低,只看到一串工具调用 | 高,每步都有推理说明 |
| 适合场景 | 纯推理题,如数学、逻辑 | 极简单的单步查询 | 多步骤、带判断的复杂任务 |
| 在退款场景的表现 | 编数据得出不可靠结论 | 跳过判断直接退款 | 查数据、做判断、再退款 |
从这张表能看出来:ReAct 不是从零发明的新东西,它本质上是把 CoT 的推理能力和工具调用的执行能力缝合在了一起。CoT 给了它想的能力,工具调用给了它干的能力,而 Thought-Action-Observation 的交替结构,把两者编织成了一个能持续推进的循环。
一句话概括:CoT 让模型会想,工具调用让模型会干,ReAct 让模型边想边干——每一步的想都基于上一步干出来的真实结果,每一步的干都有想出来的明确目的。
CoT、Act-only、ReAct 只是推理范式家族里的三个成员。学术界这几年冒出了不少变体,它们各自解决不同层面的问题。你不需要现在就搞懂每一个,但知道它们的存在和定位,后面读到相关内容时就不会懵。
按解决的问题分,可以把主流范式归成三类:
| 类别 | 范式 | 一句话说清楚 | 优势与代价 | 工程实用度 |
|---|---|---|---|---|
| 推理增强 | CoT-SC(Self-Consistency) | 同一个问题生成多条推理路径,投票选最一致的答案 | 提升推理准确率;但要多次调用 LLM,成本成倍增长 | 低——偏学术验证,Agent 工程中很少直接用 |
| ToT(Tree-of-Thoughts) | 把推理组织成树状结构,支持回溯和前瞻 | 能探索多个分支找最优解;但搜索开销大,实现复杂 | 低——适合特定推理难题,不是通用 Agent 范式 | |
| GoT(Graph-of-Thoughts) | 用图结构表达思维节点,支持聚合、循环、复用 | 比树更灵活;但复杂度进一步上升,工程落地案例极少 | 极低——目前还停留在论文阶段 | |
| 规划-执行分离 | Plan-and-Execute | 先由 Planner 制定完整计划,再由 Executor 逐步执行 | 全局视野强,减少绕弯路;但计划可能跟现实脱节,遇到意外需要重新规划 | 中高——适合流程明确的多步任务,LangGraph 等框架已内置支持 |
| ReWOO | 推理与工具调用解耦,先规划好所有步骤,再批量执行 | 大幅减少 Token 消耗和 LLM 调用次数;但执行过程中无法根据中间结果调整计划 | 中——适合步骤固定、中间结果不影响后续决策的场景 | |
| LLMCompiler | 把任务编译成 DAG(有向无环图),实现工具并行调用 | 多工具场景下显著提升执行速度;但实现门槛高,需要准确识别任务间的依赖关系 | 中低——适合工具多且可并行的场景,通用性不如前两者 | |
| 反思与自我改进 | Reflexion | Agent 执行后进行语言化反思,将经验存入记忆,指导后续尝试 | 能从失败中学习,越试越准;但需要多轮试错,时间和 Token 成本高 | 中——适合允许多次尝试的场景,如代码生成、自动化测试 |
| Self-Refine | 模型对自己的输出进行自我反馈 → 修正的循环 | 单模型闭环改进,无需额外训练;但自我评估不一定准确,可能越改越偏 | 中——适合文本润色、代码优化等输出质量可自评的场景 |
几个要点:
- 推理增强类(CoT-SC、ToT、GoT)解决的是单次推理的质量问题——怎么让大脑想得更准。它们跟 Agent 的工具调用循环是两件事,实用度低,了解即可。
- 规划-执行分离类跟 ReAct 是正面竞争的关系。ReAct 走一步算一步,灵活但可能绕弯路;Plan-and-Execute �先画全局路线图再逐步执行,高效但怕计划赶不上变化。咱们第四部分第 13 篇会专门展开对比。
- 反思类不替代 ReAct,而是给它加 buff——让 Agent 从失败中学习,下次不犯同样的错。第四部分会结合比特严选的翻车场景来讲。
本系列的主线是 ReAct,因为它是目前 Agent 工程中最主流、最实用的范式——概念简单,实现直接,绝大多数场景够用。其他范式会在后面涉及时逐一展开,这里先有个全貌就够了。
用比特严选再看一个场景
退款场景已经看过了,咱们再拿一个二星任务——T2 查物流——来感受 ReAct 的运转,看看在稍微简单一点的场景里它是怎么转的。
用户消息:「帮我看看订单 88231 的快递到哪了。」
第一圈:
Thought: 用户想查订单 88231 的物流信息。要查物流需要运单号,
但用户只给了订单号。我先查订单详情,拿到运单号。
Action: queryOrder
Action Input: 88231
Observation: {"orderId":"88231","product":"比特 S10 Pro 扫地机",
"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收",
"trackingNo":"SF1234567890"}
第二圈:
Thought: 订单 88231 的运单号是 SF1234567890,现在可以用这个运单号查物流轨迹了。
Action: queryLogistics
Action Input: SF1234567890
Observation: {"trackingNo":"SF1234567890","status":"已签收",
"latestLocation":"北京市海淀区中关村驿站",
"signTime":"2026-06-22 14:30","carrier":"顺丰速运"}
最终答复:
Thought: 物流信息已经拿到了。订单 88231 的快递由顺丰承运,运单号 SF1234567890,
6 月 22 日 14:30 已签收,签收地点是北京市海淀区中关村驿站。信息完整,可以回复用户。
Final Answer: 您的订单 88231 快递信息如下:
- 承运商:顺丰速运
- 运单号:SF1234567890
- 当前状态:已签收
- 签收时间:6 月 22 日 14:30
- 签收地点:北京市海淀区中关村驿站
只转了两圈。注意第一圈 Thought 里的推理:“要查物流需要运单号,但用户只给了订单号”——这就是推理在指路。如果是纯工具调用,模型可能直接拿订单号去调 queryLogistics,结果参数不对查不出来。有了 Thought,大脑先想清楚了数据依赖关系,知道要先查订单拿运单号,再用运单号查物流,两步串联才能拿到结果。
ReAct 提示词长什么样
你可能好奇:怎么让大模型按 Thought → Action → Observation 这种格式输出?答案是靠提示词(Prompt)约束。
提示词是 ReAct 的灵魂,后面有专门一篇《ReAct 提示词设计》来详细讲。这里先给你看一个精简版的骨架,建立个直觉:
你是比特严选的智能客服助手。你可以使用以下工具来帮助用户:
工具列表:
1. queryOrder(orderId) - 查询订单详情,返回商品名、下单时间、签收时间、状态、运单号
2. queryLogistics(trackingNo) - 查询物流轨迹,返回物流状态、最新位置、预计送达
3. applyRefund(orderId, reason) - 发起退款申请,返回申请结果
4. searchKnowledge(query) - 检索知识库,返回相关政策或FAQ内容
5. getCurrentTime() - 获取当前日期时间
请严格按照以下格式思考和行动:
Thought: <你的思考过程,分析当前局面,决定下一步做什么>
Action: <要调用的工具名>
Action Input: <传给工具的参数>
工具执行后你会收到:
Observation: <工具返回的结果>
然后继续思考下一步。重复上述过程直到你认为已经收集到足够的信息来回答用户。
当你准备好给出最终答案时,使用:
Thought: <说明为什么信息已经足够>
Final Answer: <给用户的最终回复>
注意:
- 每次只调用一个工具
- 必须先 Thought 再 Action,不要跳过思考步骤
- 如果工具返回了错误,在 Thought 中分析原因并决定下一步
用户消息:{user_message}
这段提示词做了三件关键的事:
- 告诉大脑有哪些工具:名称、参数、用途,大脑才知道手里有什么牌可以打;
- 规定输出格式:Thought → Action → Action Input,严格按格式输出,后面才好用代码解析;
- 设定终止条件:当信息足够时输出
Final Answer,循环知道什么时候该停。
这里你先感受格式就够了,提示词的打磨技巧——怎么让大脑更稳定地按格式输出、怎么加 Few-shot 示例引导、怎么防止跑偏——都是第 07 篇的内容。
用 Java 骨架感受 ReAct 循环
提示词解决了大脑怎么想的问题,那 Agent 的主��循环怎么跑?回到第一篇那段 agentRun 骨架,现在你带着 ReAct 的概念重新看一遍,每一行的意义就全对上了:
public String agentRun(String userMessage) {
// 记忆:累积整条轨迹
List<String> trace = new ArrayList<>();
trace.add("用户消息:" + userMessage);
for (int step = 0; step < MAX_STEPS; step++) {
// Thought + Action:大脑基于轨迹推理,输出思考和行动
String llmOutput = llmClient.chat(buildReActPrompt(trace));
// 判断是否输出了 Final Answer——循环终止条件
if (llmOutput.contains("Final Answer:")) {
return extractFinalAnswer(llmOutput);
}
// 记录这轮的 Thought + Action
trace.add(llmOutput);
// Observation:解析出 Action,调用工具,拿回结果
Action action = parseAction(llmOutput);
String observation = toolRegistry.execute(action);
// 把 Observation 记入轨迹,作为下一轮 Thought 的输入
trace.add("Observation: " + observation);
}
return "抱歉,超过最大步数仍未完成任务。";
}
对照 Thought-Action-Observation 三元组,这段代码的结构一目了然:
| ReAct 三元组 | 对应代码 | 做了什么 |
|---|---|---|
| Thought + Action | llmClient.chat(buildReActPrompt(trace)) | 大脑看完整条轨迹,输出推理过程和要调的工具 |
| Action 执行 | toolRegistry.execute(action) | 把大脑的决定变成真实的工具调用 |
| Observation | trace.add("Observation: " + observation) | 工具结果记入轨迹,等下一轮大脑来看 |
| 循环 | for (int step = 0; step < MAX_STEPS; step++) | 三步反复转,直到 Final Answer 或达到上限 |
这段代码还是骨架,buildReActPrompt、parseAction、toolRegistry 这些方法的实现在后面几篇手把手写出来。但你现在应该能感受到:ReAct 的实现并不复杂——一个循环、一段提示词、一组工具,三样凑齐就能跑。真正的挑战藏在每个环节的细节里——提示词怎么写、输出怎么解析、异常怎么兜底,后面几篇会逐一攻克。
ReAct 的边界
讲了这么多好处,也得说说 ReAct 的局限。没有万能的范式,知道它哪里弱,后面选型和优化才有方向。
1. 每一圈都是一次 API 调用
循环转一圈就是一次 LLM API 调用。退款场景转三圈就是三次调用,复杂的故障诊断可能要转五六圈甚至更多。每次调用都有 Token 成本和网络延迟,圈数越多花费越高、用户等得越久。
2. 上下文越滚越长
轨迹里每一轮的 Thought、Action、Observation 都在积累。第三圈的提示词里要带前两圈的全部内容,越往后输入越长。这不仅增加 Token 消耗,还可能撑爆模型的上下文窗口。
3. 走一步算一步的局限
ReAct 的规划是隐式的——走一步想一步,不会在开头列一份完整的计划。对于流程固定的批量任务,这种即兴规划可能绕弯路。比如用户说“帮我把这三个订单都退了”,ReAct 可能会一个一个查、一个一个退,而不是先统一查完再统一退。
4. 大脑跑偏的风险
大脑的推理完全依赖大模型的能力。如果模型没理解用户意图、或者对工具的描述不够清楚,大脑可能会调错工具、传错参数、甚至陷入重复调用的死循环。
这些局限不是 ReAct 的死穴,而是后面几篇要逐一解决的工程问题:
| 局限 | 对应的解决方案 | 在哪一篇 |
|---|---|---|
| Token 与延迟成本 | 记忆压缩与摘要 | 手写 Agent 记忆模块 |
| 上下文溢出 | 短期记忆截断与长期记忆持久化 | 记忆系列 |
| 隐式规划绕弯路 | Plan-and-Execute 显式规划 | Plan-and-Execute 模式 |
| 大脑跑偏 | 提示词约束、解析容错、终止控制 | 提示词 / 解析 / 终止条件 |
文末总结
这一篇咱们没写一行能跑的代码,但把 ReAct 这个范式的来龙去脉讲透了:
- 两种极端都不行:纯思维链只会想不会干,编数据导致幻觉;纯工具调用只会干不会想,缺判断导致盲目操作。
- ReAct = Reasoning + Acting:推理和行动交替进行,Thought-Action-Observation 三元组循环运转。
- 推理为行动指路,行动为推理补信息:两者交替形成正反馈循环,每转一圈掌握的信息就多一点,判断就准一点。
- 实现不复杂:一个循环、一段提示词、一组工具,三样凑齐就能跑。复杂的是每个环节的细节打磨。
- 有边界:Token 成本、上下文膨胀、隐式规划、大脑跑偏,这些是后面要解决的工程问题。
一句话收尾:ReAct 让模型边想边干——每一步的想都基于上一步干出来的真实结果,每一步的干都有想出来的明确目的。这个推理与行动交替的循环,就是 Agent 能自主把事办成的核心引擎。
下一篇,全系列的重头戏来了——手写 ReAct 循环。我们会用纯 Java + OkHttp 实现一个最小可运行的 Agent,让比特严选智能体真正跑起来。Thought-Action-Observation 不再是纸面上的格式,而是你 IDE 里能断点调试的真实代码。
我们下一篇见。