多维度终止控制:让 Agent 运行更安全
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们把 TinyAgent 从文本解析升级到了 Function Calling——工具调用的通信方式从自由文本协议换成了 API 结构化协议,parseAction() 和 stop 序列全部删掉,代码更简洁、格式 100% 稳定。
但如果你回头看目前的 ReActAgent.run(),会发现循环的退出条件非常粗暴——只有两个出口:
- 模型不再调工具(
hasToolCalls()返回false)——正常结束。 - 跑满
MAX_STEPS = 10圈——兜底超时,返回一句“我思考了太多步”。
这两个条件够吗?跑简单场景没问题,但稍微复杂一点的情况就会暴露问题:
- 用户说了句“你好”,大脑直接回复不需要调工具——没问题,走第一个出口。
- 退款流程 4 圈搞定——没问题。
- 但如果某个工具返回的结果不够用,大脑又找不到别的办法,它会用同样的参数反复调同一个工具——第 3 圈调、第 4 圈还在调,期待一个不会变的结果里刷出新内容。Token 在烧,任务没有推进,而
MAX_STEPS要等到第 10 圈才兜底。 - 又或者,一个跨品类对比的任务确实需要 8 圈工具调用,每圈的消息列表越来越长,Token 消耗加速增长——等你反应过来,上下文窗口已经快撑爆了。
这一篇,咱们系统地解决这个问题:Agent 循环什么时候停,不能只靠一个硬编码的最大步数。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.4.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
先把问题分个类
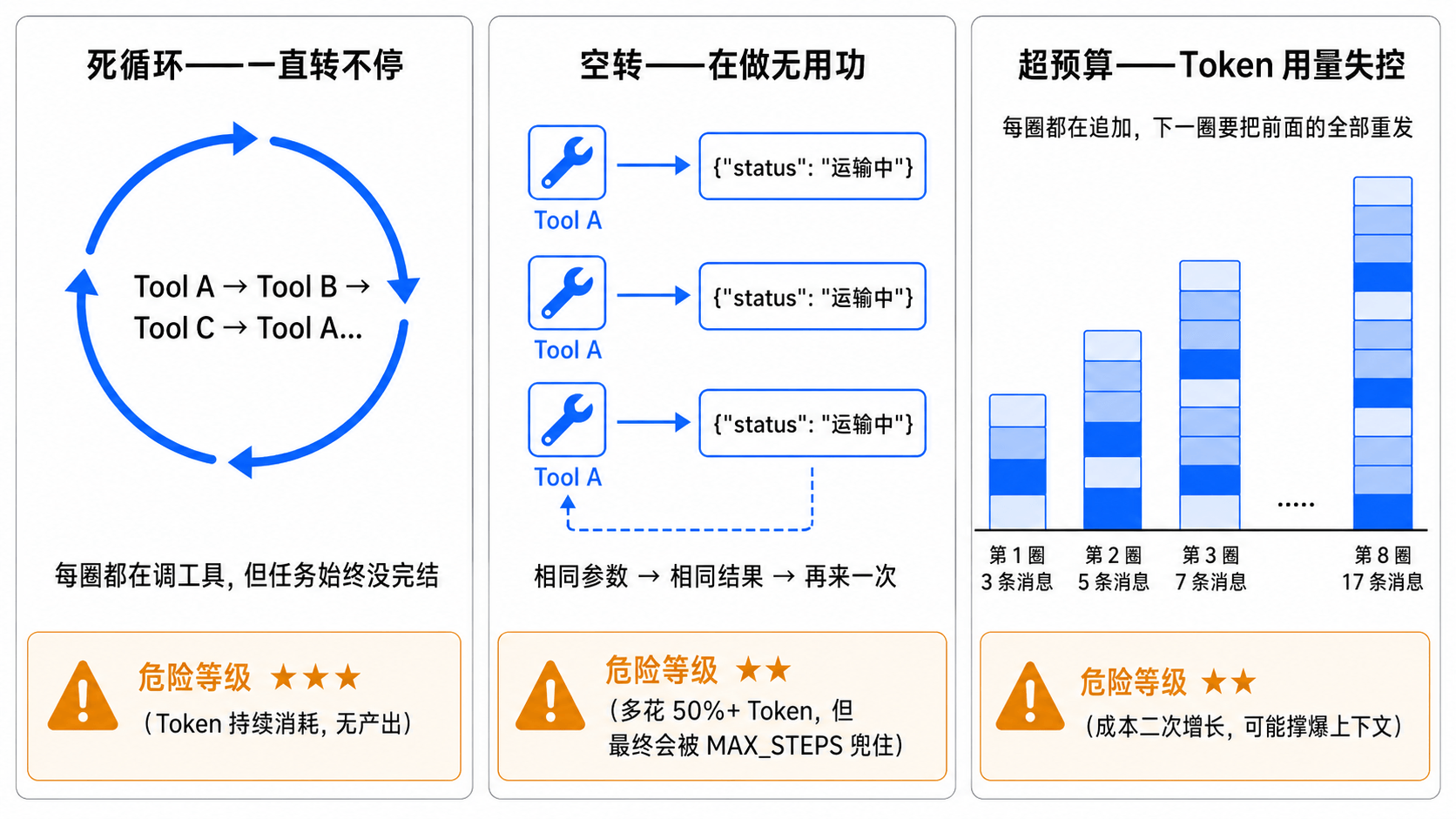
在写代码之前,先想清楚 Agent 循环可能以哪些方式不正常地跑下去。归纳一下,无非三类:
1. 死循环:一直转不停
大脑每圈都决定调工具,但任务始终没有完结。比如用户问了一个超出工具能力范围的问题,大脑反复尝试不同的工具组合,希望能拼凑出答案——结果每次都不对,但它就是不肯说“我不知道”。
这是最危险的情况:Token 不断消耗,用户在等,服务器资源被占用,但没有任何产出。
2. 空转:在做无用功
大脑在调工具,但做的是重复劳动。最典型的场景:连续两圈用相同的参数调了同一个工具,拿到了一模一样的结果。
为什么大脑会做这种明显没意义的事?根本原因是工具返回的结果不足以让大脑推进到下一步,但它又不知道该换什么思路。大脑拿到一个结果,发现回答不了用户的问题,于是本能地重试——就像��一个人对着自动售货机反复按同一个按钮,期待掉出不同的东西。
打个比方:用户问“订单 88231 的物流到哪了”,大脑第 1 圈调 queryOrder 查到了运单号,第 2 圈调 queryLogistics,结果返回的是 {"status": "运输中"}——只有一个笼统的状态,没有具体位置、没有预计到达时间。大脑觉得光回复运输中太敷衍,但手头又没有其他工具能查到更详细的信息,于是第 3 圈用同样的运单号又调了一遍 queryLogistics,拿到了一模一样的结果。对于咱们比特严选的这些查询工具来说,同一个运单号在几秒钟内查出来的结果不会变——但大脑不理解这一点,它只会反复尝试。
空转不像死循环那么致命,但在生产环境里,一个空转 3 圈的请求比正常请求多花 50% 以上的 Token 成本——量大了很心疼。
3. 超预算:Token 用量失控
即使每圈都在做有意义的事,累计的 Token 消耗也可能超出预期。Agent 循环有一个让人容易忽略的特性:消息列表是累积增长的。每圈循环往消息列表里追加 assistant 消息和 tool 消息,下一圈调 API 时要把整个消息列表都发过去。
第 1 圈发 3 条消息(system + user + assistant),第 2 圈发 5 条,第 3 圈发 7 条……到第 8 圈就是 17 条消息。如果每个工具结果返回 500 字,8 圈下来光工具结果就 4000 字。再加上系统提示词和用户消息,输入 Token 可能已经到了大几千。
更麻烦的是,有些工具返回的数据量不可控——比如知识库搜索可能返回一大段文档,物�流轨迹可能包含十几条记录。一旦某个工具返回了超长结果,后续每圈的输入 Token 都会被这段长文本拖累。
下面这张图把三类问题放在一起对比,帮你建立一个直觉——它们的危险程度和表现形式完全不同,所以后面的防线也不是一招通吃:
四道防线
针对上面三类问题,咱们设计四道防线,从粗到细依次拦截:
| 防线 | 解决的问题 | 原理 | 实现复杂度 |
|---|---|---|---|
| 最大步数 | 死循环 | 硬编码上限,超过就强制停止 | 最简单 |
| 重复调用检测 | 空转 | 连续 N 圈调同一个工具 + 同样参数 → 先提醒后停止 | 简单 |
| Token 预算 | 超预算 | 估算累计 Token,超过阈值 → 强制停止 | 中等 |
| 无进展检测 | 空转 + 死循环 | 连续 N 圈大脑的 content 高度相似 → 强制停止 | 中等 |
下面逐个拆解,每道防线都给出原理、代码实现和实际效果。
第一道防线:最大步数(已有)
这是最粗暴也最可靠的兜底——不管发生什么,跑满 N 圈就停。
目前代码里已经有了:
private static final int MAX_STEPS = 10;
for (int step = 1; step <= MAX_STEPS; step++) {
// ... 循环体
}
return "抱歉,我思考了太多步仍未完成任务,请尝试换一种方式描述您的问题。";
这道防线的价值不在于精确——它拦不住空转,也拦不住超预算——而在于确定性。不管其他检测机制有没有 bug,最大步数保证 Agent 一定会停。
1. MAX_STEPS 设多少合适
10 是一个经验值。太小会截断正常的多步任务,太大又起不到保护作用。用比特严选的场景做个参考:
| 场景 | 典型步数 | 说明 |
|---|---|---|
| 查订单状态 | 1-2 步 | 查订单 → 回复 |
| 查物流轨迹 | 2-3 步 | 查订单拿运单号 → 查物流 → 回复 |
| 退款流程 | 3-4 步 | 查订单 + 查政策 + 查时间 + 申请退款 |
| 跨品类对比 | 4-6 步 | 查多个商品 → 对比 → 推荐 |
| 复杂售后诊断 | 5-8 步 | 查订单 → 查保修 → 逐步诊断 → 推荐方案 |
最复杂的场景大约需要 8 步,MAX_STEPS = 10 留了 2 步的余量。如果你的业务场景工具链路更长,可以适当调大,但一般不建议超过 15——超过 15 步的任务,往往需要重新拆解需求或引入 Plan-and-Execute 模式(第 13 篇会讲)。
最大步数是兜底线,不是目标线。正常任务应该在
MAX_STEPS之前就通过其他条件正常退出。如果你发现大量请求都跑到了MAX_STEPS才停,说明要么MAX_STEPS设太小了,要么 Agent 的工具设计或提示词有问题。
2. 把它变成可配置的
硬编码 MAX_STEPS = 10 在 demo 里没问题,但生产环境里不同场景可能需要不同的上限。把它改成构造参数:
public class ReActAgent {
private static final int DEFAULT_MAX_STEPS = 10;
private final LlmClient llmClient;
private final ToolRegistry toolRegistry;
private final ObjectMapper objectMapper;
private final int maxSteps;
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry) {
this(llmClient, toolRegistry, DEFAULT_MAX_STEPS);
}
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry, int maxSteps) {
this.llmClient = llmClient;
this.toolRegistry = toolRegistry;
this.objectMapper = llmClient.getObjectMapper();
this.maxSteps = maxSteps;
}
}
改动很小,但给了调用方灵活性:简单查询场景可以设 maxSteps = 5,复杂诊断场景可以设 maxSteps = 15。
第二道防线:重复调用检测
大脑连续两圈用相同的工具名 + 相同的参数调同一个工具——对于确定性的只读查询来说,这几乎可以断定是空转。但检测到就直接掐掉未免可惜——大脑手里已经有前几圈收集到的信息,给它一句提醒,往往就能自己组织出一个有用的回复。所以咱们的策略是先提醒、再停止。
1. 检测逻辑
记录上一圈的工具调用信息(工具名 + 参数),跟当前圈对比。如果完全一致,计数器加 1;如果不一致,计数器清零。检测到重复后分两步处理:
- 第一次重复(计数器 = 1)——提醒:不执行工具,把工具结果替换成一段提示文本,告诉大脑"你已经用相同的参数调过这个工具了,结果不会变,请根据已有信息直接回复用户"。这相当于给大脑一个台阶——它手里已经有前几圈收集到的信息,很多时候一句�提醒就够让它收手了。
- 第二次重复(计数器 ≥ 2)——停止:提醒过了还在重复,说明大脑真的卡住了,强制停止循环。
用一张时序图看这个两阶段策略的完整过程:
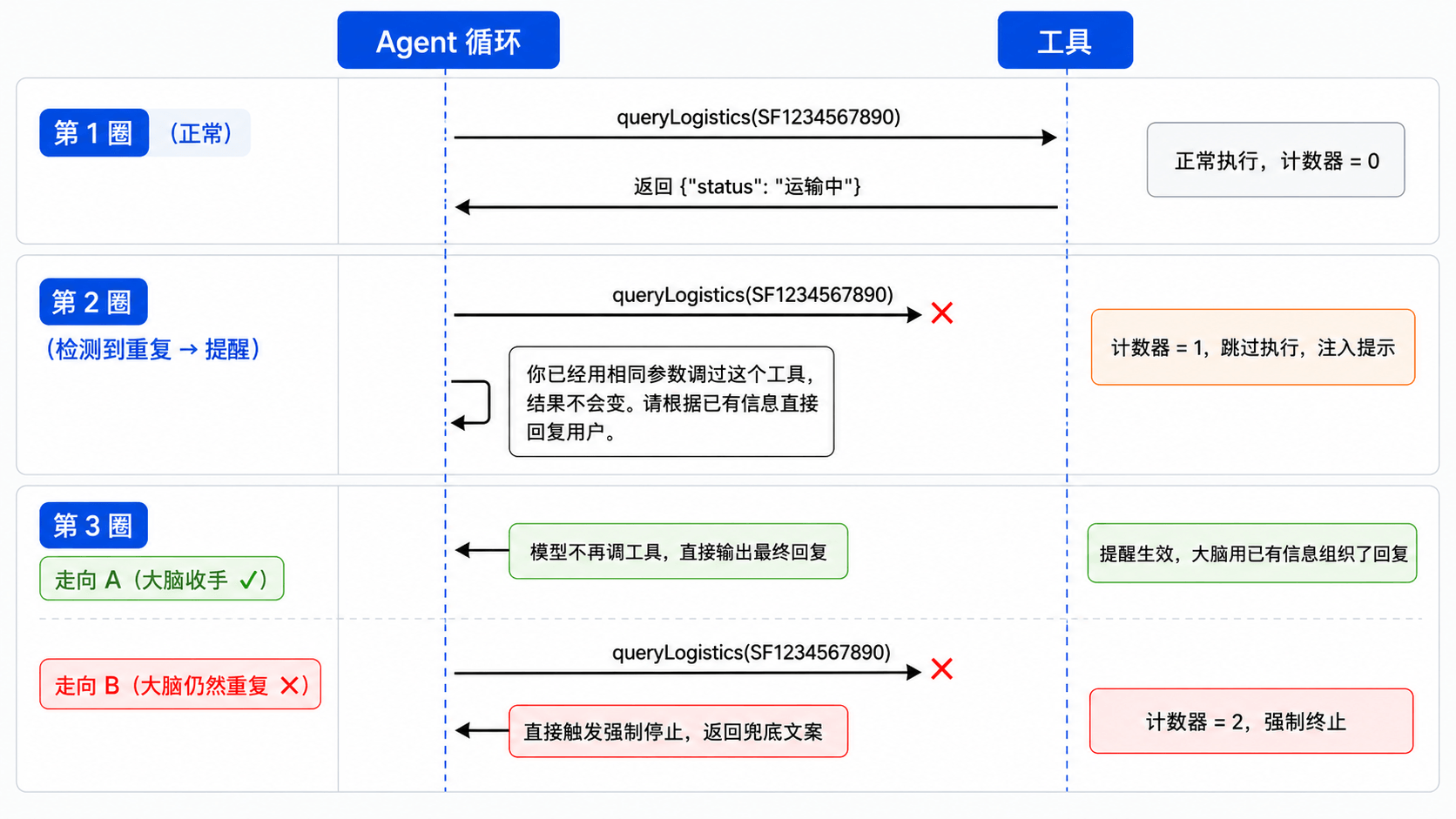
如果两次相同调用之间穿插了一次不同的调用——比如先查订单、再查物流、然后又查了一遍订单想确认信息——计数器会被中间那次不同的调用清零,不会误判。只有连续重复才会触发提醒。
2. 实现代码
用一个枚举表示检测结果,用一个内部类封装检测逻辑:
private enum RepeatAction {
NORMAL, WARN, STOP
}
private static class RepeatDetector {
private String lastCallSignature = "";
private int repeatCount = 0;
RepeatAction check(List<ToolCallInfo> toolCalls) {
String currentSignature = buildSignature(toolCalls);
if (currentSignature.equals(lastCallSignature)) {
repeatCount++;
} else {
repeatCount = 0;
lastCallSignature = currentSignature;
}
if (repeatCount >= 2) {
return RepeatAction.STOP;
}
if (repeatCount == 1) {
return RepeatAction.WARN;
}
return RepeatAction.NORMAL;
}
private String buildSignature(List<ToolCallInfo> toolCalls) {
StringBuilder sb = new StringBuilder();
for (ToolCallInfo tc : toolCalls) {
sb.append(tc.functionName()).append(":").append(tc.arguments()).append(";");
}
return sb.toString();
}
}
buildSignature() 把一圈里所有的工具调用拼成一个字符串签名——工具名和参数用冒号分隔,多个调用用分号分隔。这样即使一圈里调了多个工具,也能精确比较是否跟上一圈完全一致。
3. 集成到主循环
在循环里加入检测和两阶段处理:
RepeatDetector repeatDetector = new RepeatDetector();
for (int step = 1; step <= maxSteps; step++) {
// ... 调模型、判断是否结束
RepeatAction repeatAction = repeatDetector.check(response.toolCalls());
// 第二次重复:强制停止
if (repeatAction == RepeatAction.STOP) {
System.out.println("[终止] 提醒后仍重复调用,强制停止");
return "抱歉,我在处理您的问题时遇到了困难。请尝试换一种方式描述,或联系人工客服获取帮助。";
}
// ... 追加 assistant 消息到消息列表(WARN 和 NORMAL 都需要)
// 第一次重复:注入提示,跳过工具执行
if (repeatAction == RepeatAction.WARN) {
System.out.println("[提醒] 检测到重复调用,注入提示");
String hint = "你已经用相同的参数调用过这个工具,结果不会变化。"
+ "请根据已有信息直接回复用户,不要重复调用。";
for (ToolCallInfo tc : response.toolCalls()) {
ObjectNode toolMsg = messages.addObject();
toolMsg.put("role", "tool");
toolMsg.put("tool_call_id", tc.id());
toolMsg.put("content", hint);
}
continue;
}
// ... 正常执行工具、追加消息
}
关键在 WARN 分支的处理:不执行工具,而是把每个 tool_call 对应的 tool 消息替换成一段提示文本。对模型来说,这就像工具返回了一条"别再调了"的结果——它会基于这个"结果"重新推理,大概率会切换到总结模式,用已有信息给用户一个回复。
注意:跳过执行、注入提示的策略,前提是工具是确定性的只读操作(如
queryOrder、queryLogistics)。如果工具有副作用(如applyRefund提交退款),重复调用可能导致重复扣款——这类工具即使参数相同也不能跳过,而应该用幂等键去重。如果工具结果随时间变化(如实时库存查询),重复调用可能拿到不同结果,不算空转。生产环境里,建议在工具注册时标记deterministic和readOnly属性,只对确定性只读工具启用跳过执行策略。
第三道防线:Token 预算控制
Agent 循环的 Token 消耗有一个容易被忽略的特性:它不是线性增长,而是二次增长。
每圈循环往消息列表里追加 2-3 条消息(assistant + tool),下一圈的输入 Token 就增加了这些消息的长度。假设每圈新增 500 Token 的消息:
| 圈数 | 新增消息 Token | 累计消息 Token | 本圈输入 Token |
|---|---|---|---|
| 第 1 圈 | 500 | 500 | 500 |
| 第 2 圈 | 500 | 1000 | 1000 |
| 第 3 圈 | 500 | 1500 | 1500 |
| 第 5 圈 | 500 | 2500 | 2500 |
| 第 8 圈 | 500 | 4000 | 4000 |
| 第 10 圈 | 500 | 5000 | 5000 |
10 圈下来,总输入 Token 不是 5000,而是 500 + 1000 + 1500 + … + 5000 = 27500。如果每圈新增的不是 500 而是 1000(工具返回了较长的数据),10 圈的总输入就是 55000 Token。
这还没算输出 Token。加上模型每圈的回复,实际消耗更高。
下面这张图把消息累积的过程画出来——重点不是每圈新增了多少,而是每圈要把前面所有消息重新发一遍:
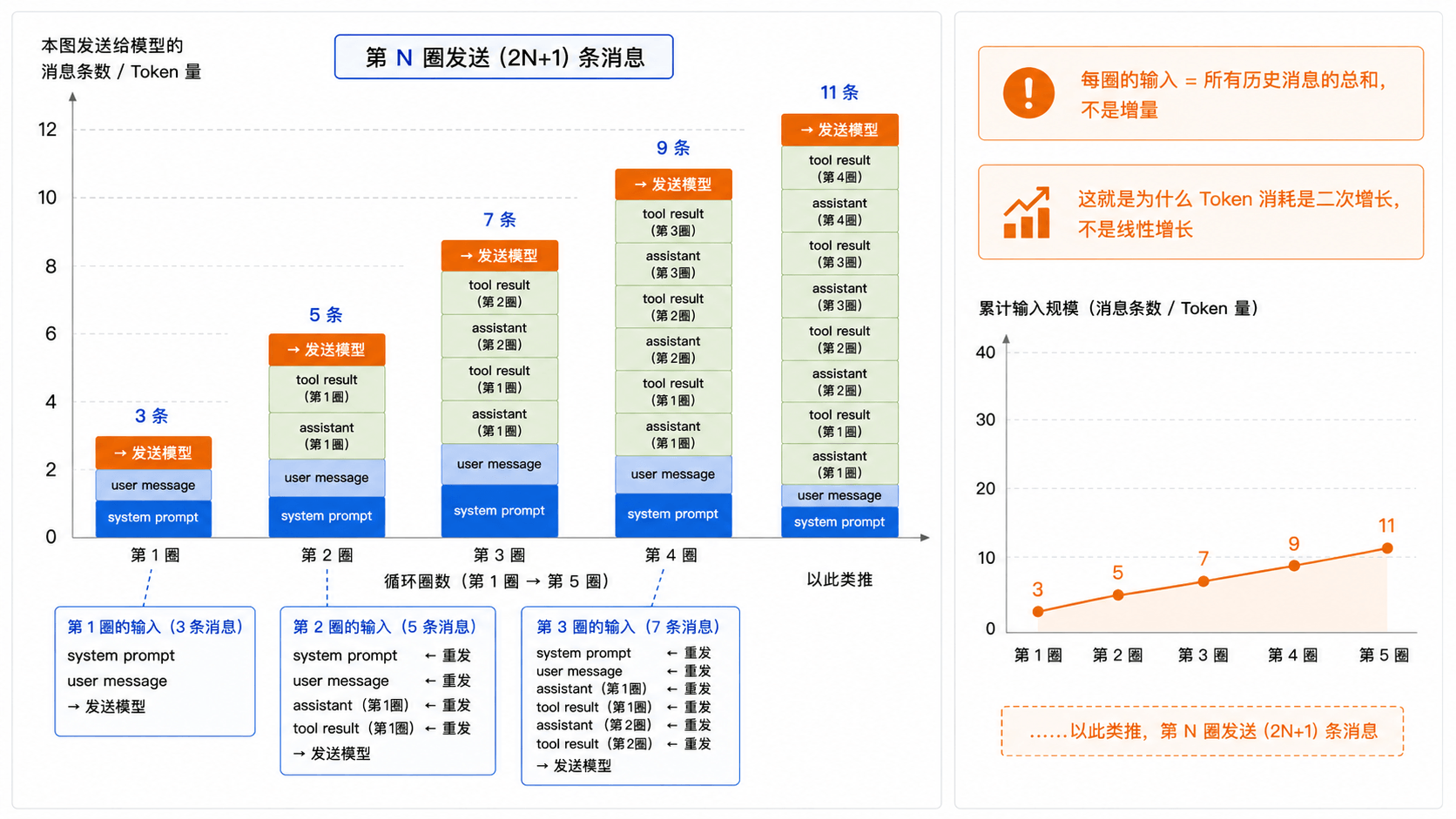
所以 Token 预算要控制的核心是单次请求的上下文大小——也就是消息列表的总长度。上下文越大,单次调用越贵、延迟越高、模型注意力也越分散。只要卡住上下文大小,二次增长的总成本也就被间接控制住了。至于精确的 Token 成本核算,生产环境里一般直接读 API 响应里的 usage 字段(包含 prompt_tokens 和 completion_tokens),比自己估算靠谱得多。
1. 估算策略
精确计算 Token 数量需要 Tokenizer(分词器),不同模型的 Tokenizer 不一样,引入依赖太重。工程上通常用一个简单的估算规则:
OpenAI 官方给出的英文粗略估算是:1 token ≈ 4 个英文字符,或 100 tokens ≈ 75 个英文单词。因此英文可粗略理解为 1 个单词 ≈ 1.3 tokens。中文没有官方统一换算,不同模型和 tokenizer 差异较大,工程估算时可以保守按 1 个汉字约 1~2 tokens 预估;精确数量应使用 OpenAI Tokenizer 或
tiktoken按目标模型实际计算。
这个估算不精确——只覆盖消息正文内容,不算结构开销和输出——但用来做粗粒度的安全阈值够用了。咱们要的是别撑爆上下文,不是精确到个位数。
实现上,直接用字符数乘以一个系数来估算:
private static class TokenBudget {
private static final double TOKENS_PER_CHAR = 1.0;
private final int maxTokens;
private int estimatedTokens = 0;
TokenBudget(int maxTokens) {
this.maxTokens = maxTokens;
}
void addMessage(String content) {
if (content != null) {
estimatedTokens += estimateTokens(content);
}
}
boolean isExceeded() {
return estimatedTokens >= maxTokens;
}
int getEstimatedTokens() {
return estimatedTokens;
}
private int estimateTokens(String text) {
return (int) Math.ceil(text.length() * TOKENS_PER_CHAR);
}
}
TOKENS_PER_CHAR = 1.0 是一个折中估算:按照上面的规则,中文 1 个汉字约 1~2 Token,这里取下限 1;英文 1 个字符约 0.25 Token,用 1 会偏高,但对预算控制来说宁可多算。咱们的客服场景以中文为主,夹杂少量英文字段名和 JSON 数据,整体用 1.0 不会差太远。另外这里只估算了消息的文本内容,没有算工具定义(tool schema)、请求结构(role、tool_calls JSON)、输出 Token 和推理 Token。精确数字要靠 API 返回的 usage 字段,这里只是做一个量级上的安全阈值——宁可早停一步,不要撑爆上下文。
2. 预算上限设多少
先看主流大模型当前的上下文窗口大小(截至 2026 年 7 月,以各厂商官方文档为准,可能随版本更新变化):
| 模型 / 系列 | 上下文窗口 | 备注 |
|---|---|---|
| DeepSeek V4 Flash / Pro | 1M Token | 官方 API 文档标注 deepseek-v4-flash、deepseek-v4-pro 均为 1M 上下文,最大输出上限为 384K;deepseek-chat / deepseek-reasoner 后续会作为 V4 Flash 的非思考 / 思考模式兼容名。 |
| 通义千问 Qwen3.7 Max / Plus | 1M Token | 阿里云百炼文档标注 qwen3.7-max、qwen3.7-plus 均为 1M 上下文;同时也提醒常规任务 128K~256K 已经足够。 |
| OpenAI GPT-5.5 / GPT-5.4 | 1M Token | OpenAI 模型文档标注 GPT-5.5、GPT-5.4 为 1M 上下文,最大输出 128K。 |
| Claude Opus 4.8、Claude Sonnet 5 | 1M Token | Anthropic 模型概览页标注 Opus 4.8、Sonnet 5 为 1M 上下文;其他型号(如 Sonnet 4.5)多数为 200K,具体以 Models API 查询为准。 |
但要注意:上下文窗口不等于业务预算上限。
上下文窗口只是模型一次请求理论上能接收的最大 Token 数,实际请求里还要放:
- system prompt
- 用户问题
- 历史对话
- 工具定义
- 工具返回结果
- RAG 检索片段
- 模型最终回复
- reasoning / thinking token(如果使用思考模型)
Anthropic 文档也明确提醒:context window 包含模型生成的回复本身;并且上下文越长并不一定越好,Token 数增长后,准确率和召回可能下降,也就是所谓的 context rot。
所以预算不要简单按上下文窗口的 30%~50% 来设。这个规则在 32K / 64K 时代还可以粗略参考,但在 1M 上下文时代会过大。比如 1M 的 30% 就是 300K Token,对普通客服、商品咨询、订单查询场景完全没有必要,反而会增加成本、延迟和干扰信息。
更推荐按场景分层设置:
| 场景 | 建议 Token 预算 |
|---|---|
| 普通客服对话 / 订单查询 / 物流查询 | 4K~8K |
| 带少量历史对话 + 工具调用 | 8K~16K |
| RAG 问答,检索 3~8 个知识片段 | 16K~32K |
| 长文档问答 / 多文档总结 | 32K~128K |
| 大型代码库 / 超长合同 / 多轮复杂 Agent | 128K~256K 起步,按需放大 |
| 真正的超长上下文任务 | 再考虑 300K、500K 甚至 1M |
对于比特严选这种客服场景,单次对话通常不需要很大的上下文。用户问题、最近几轮历史、工具 schema、工具返回结果等真实上下文加起来,大多数��情况下 8K Token 以内就够(注意:代码里的 TokenBudget 只统计消息正文,没有算工具 schema 和 tool_calls 结构,实际统计值会比真实上下文偏小。但 8K 是按真实场景定的安全线,偏小的估算不会让预算失去保护作用,只是触发时机会比实际消耗略滞后)。
因此建议这样设:
private static final int DEFAULT_MAX_TOKENS = 8000;
如果后续加入知识库检索,可以放宽到:
private static final int DEFAULT_MAX_TOKENS = 16000;
// 或者 RAG 场景使用 32000 等
最终原则是:
上下文窗口是模型能力上限,不是你应该塞满的目标。业务里的 Token 预算应该从任务需要出发,而不是从模型最大窗口出发。
对于 TinyAgent 当前的客服 Agent,DEFAULT_MAX_TOKENS = 8000 作为安全线是合理的;如果后续加入大量知识库片段、长文档处理或复杂多工具 Agent,再按场景升级到 16K、32K 或更高。
3. 集成到主循环
在循环体里,每次追加消息后更新 Token 估算,在调模型前检查预算:
TokenBudget tokenBudget = new TokenBudget(maxTokens);
tokenBudget.addMessage(buildSystemPrompt());
tokenBudget.addMessage(userMessage);
for (int step = 1; step <= maxSteps; step++) {
// Token 预算检查
if (tokenBudget.isExceeded()) {
System.out.println("[终止] Token 预算耗尽(约 " + tokenBudget.getEstimatedTokens() + " Token)");
return "抱歉,本次对话信息量较大,已达到处理上限。以下是我目前了解到的信息,请参考。";
}
ChatResponse response = llmClient.chatWithTools(messages, tools);
// ... 追加 assistant 消息
tokenBudget.addMessage(response.content());
// ... 执行工具、追加 tool 消息
for (ToolCallInfo tc : response.toolCalls()) {
String observation = toolRegistry.execute(new Action(tc.functionName(), tc.arguments()));
tokenBudget.addMessage(observation);
// ...
}
}
注意检查时机:在调模型之前检查,而不是之后。因为调模型是最贵的操作——如果预算已经超了,不要再花 Token 去调一次。
第四道防线:无进展检测
重复调用检测能抓住同一个工具 + 同样参数的空转,但有一种更隐蔽的空转它抓不住:大脑每圈调的工具不一样,但推理内容来来回回就那几句话,任务实际上没有推进。
举个例子:用户问“3000 元以内适合老人用的手机推荐一下”,大脑第 1 圈搜索知识库查了“老人手机推荐”,第 2 圈查了“3000 元以内手机”,第 3 圈又查了“适合老人的手机 3000 元以下”——三次调用的工具名和参数都不同,重复调用检测抓不住,但实际上大脑在兜圈子,每次的 Thought 都在说“我需要帮用户找适合老人的手机”。
1. 检测逻辑
记录最近 N 圈大脑的 content(思考内容),如果连续 N 圈的内容高度相似,判定为无进展。
怎么判断高度相似?最简单的方式:关键词重合度。把每圈的 content 分词后取关键词,计算相邻两圈关键词的重合比例。如果连续 3 圈重合度都超过 70%,判定为无进展。
不过对于咱们这个场景,有一种更工程化的做法:直接让大脑来判断。在系统提示词里加一条规则,告诉大脑“如果你发现自己在做重复的事情,直接告诉用户你无法完成”。这种方式把检测逻辑从代码搬到了提示词——实现简单,但依赖大脑的自觉性。
这里咱们选一种折中方案:用代码做轻量级的相似度检测,作为安全网。如果大脑自己没意识到在兜圈子,代码来兜底。
2. 实现代码
private static class ProgressDetector {
private final int windowSize;
private final List<String> recentContents = new ArrayList<>();
ProgressDetector(int windowSize) {
this.windowSize = windowSize;
}
boolean isStuck(String content) {
if (content == null || content.isBlank()) {
return false;
}
recentContents.add(content.strip());
if (recentContents.size() < windowSize) {
return false;
}
if (recentContents.size() > windowSize) {
recentContents.remove(0);
}
for (int i = 1; i < recentContents.size(); i++) {
if (computeSimilarity(recentContents.get(i - 1), recentContents.get(i)) < 0.7) {
return false;
}
}
return true;
}
private double computeSimilarity(String a, String b) {
Set<Character> setA = toCharSet(a);
Set<Character> setB = toCharSet(b);
Set<Character> intersection = new HashSet<>(setA);
intersection.retainAll(setB);
Set<Character> union = new HashSet<>(setA);
union.addAll(setB);
if (union.isEmpty()) {
return 0.0;
}
return (double) intersection.size() / union.size();
}
private Set<Character> toCharSet(String text) {
Set<Character> set = new HashSet<>();
for (char c : text.toCharArray()) {
if (!Character.isWhitespace(c)) {
set.add(c);
}
}
return set;
}
}
用的是 Jaccard 相似度(Jaccard Similarity)——两个集合的交集大小除以并集大小。这里把每圈 content 的字符集合做交并集运算,算出相似度。
为什么用字符集合而不是分词?因为中文分词需要引入额外依赖(如 jieba),而字符级别的 Jaccard 相似度对于检测说来说去都是那些话已经够用了。两段内容如果核心词汇一样,字符集合的重合度一定很高。
windowSize = 3 意味着需要连续 3 圈的内容都高度相似才触发——避免偶尔一次相似的 Thought 导致误判。
3. 集成到主循环
ProgressDetector progressDetector = new ProgressDetector(3);
for (int step = 1; step <= maxSteps; step++) {
// ...
ChatResponse response = llmClient.chatWithTools(messages, tools);
if (!response.hasToolCalls()) {
// 正常结束
return response.content();
}
// 无进展检测
if (progressDetector.isStuck(response.content())) {
System.out.println("[终止] 检测到无进展,连续多圈推理内容高度相似");
return "抱歉,我在处理您的问题时遇到了困难,无法进一步推进。请尝试换一种方式描述,或联系人工客服获取帮助。";
}
// ... 执行工具
}
需要注意:Function Calling 模式下,模型发起工具调用时
content字段经常为空——真正的推理过程对调用方不可见。这意味着ProgressDetector在很多模型上可能不会触发,因为isStuck()对空content直接返回false。再加上重复调用检测只比较相邻两圈的签名,对 A → B → A → B 这种交替循环也抓不住。也就是说,FC 模式下的隐蔽空转和交替循环空转,实际靠的是 Token 预算和 MAX_STEPS 兜底——这也是为什么前面强调最大步数是"最粗暴也最可靠"的防线。无进展检测的定位是 best-effort 的安全网:有content就检测,没有就跳过,不影响其他防线。如果你的场景需要更可靠的空转检测,可以考虑用工具调用序列的滑动窗口做模��式匹配——比如最近 4~6 步的调用序列出现重复模式(工具名序列重复、参数集合没有新增),就判定为空转。
四道防线的优先级
四道防线不是互斥的,它们同时生效,按检测顺序依次判断:
每圈循环开始
├── ① Token 预算是否超了? → 超了就停
├── 调模型拿响应
├── ② 模型是否不再调工具? → 正常结束
├── ③ 重复调用? → 提醒后仍重复则停止
├── ④ 是否无进展? → 兜圈子就停
├── 追加 assistant 消息
├── ③' 首次重复? → 注入提示代替工具结果,回到循环
├── 执行工具
└── 回到循环开始,步数 +1 → ⑤ 超过 MAX_STEPS? → 超了就停
用一张流程图看完整的决策链路:
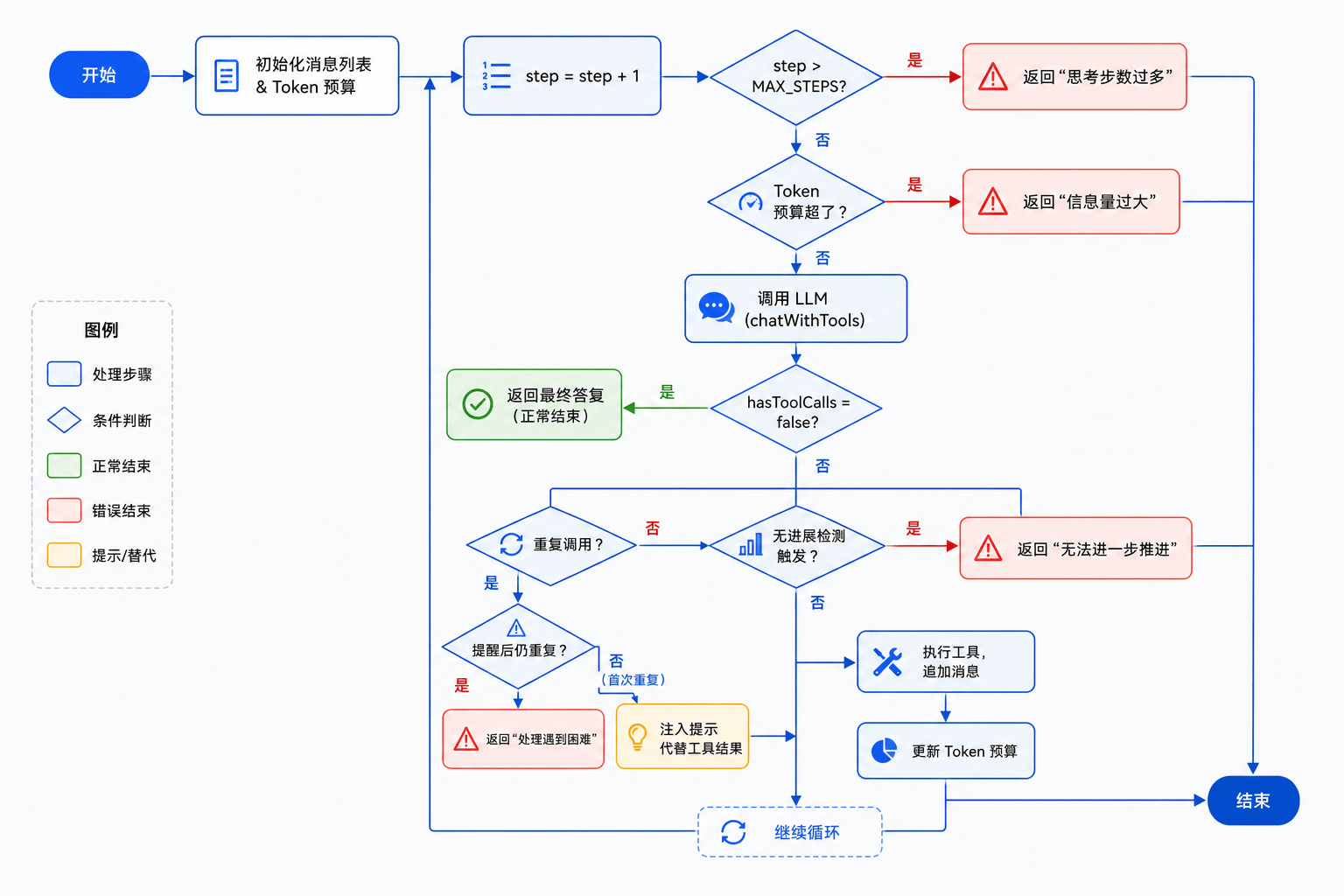
这个顺序是有讲究的:
- Token 预算放最前面:在调模型之前检查,因为调模型是最贵的操作。如果预算已经不够了,不值得再花 Token。
- 正常结束放第二:模型认为任务完成了,这是最理想的退出路径,优先响应。
- 重复调用和无进展放中间:这两个检测需要看到当前圈的响应才能判断。
- 最大步数放在循环条件上:作为最后的兜底,不管上面的检测有没有触发。
完整代码:升级后的 ReActAgent
把四道防线整合到 ReActAgent 里,完整代码如下:
public class ReActAgent {
private static final int DEFAULT_MAX_STEPS = 10;
private static final int DEFAULT_MAX_TOKENS = 8000;
private final LlmClient llmClient;
private final ToolRegistry toolRegistry;
private final ObjectMapper objectMapper;
private final int maxSteps;
private final int maxTokens;
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry) {
this(llmClient, toolRegistry, DEFAULT_MAX_STEPS, DEFAULT_MAX_TOKENS);
}
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry,
int maxSteps, int maxTokens) {
this.llmClient = llmClient;
this.toolRegistry = toolRegistry;
this.objectMapper = llmClient.getObjectMapper();
this.maxSteps = maxSteps;
this.maxTokens = maxTokens;
}
public String run(String userMessage) {
ArrayNode messages = objectMapper.createArrayNode();
String systemPrompt = buildSystemPrompt();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", systemPrompt);
ObjectNode userMsg = messages.addObject();
userMsg.put("role", "user");
userMsg.put("content", userMessage);
ArrayNode tools = toolRegistry.buildToolsJsonArray(objectMapper);
TokenBudget tokenBudget = new TokenBudget(maxTokens);
tokenBudget.addMessage(systemPrompt);
tokenBudget.addMessage(userMessage);
RepeatDetector repeatDetector = new RepeatDetector();
ProgressDetector progressDetector = new ProgressDetector(3);
for (int step = 1; step <= maxSteps; step++) {
System.out.println("\n===== 第 " + step + " 圈 =====");
if (tokenBudget.isExceeded()) {
System.out.println("[终止] Token 预算耗尽(约 "
+ tokenBudget.getEstimatedTokens() + " Token)");
return "抱歉,本次对话信息量较大,已达到处理上限。请尝试简化问题或分多次咨询。";
}
ChatResponse response = llmClient.chatWithTools(messages, tools);
if (!response.hasToolCalls()) {
String answer = response.content() != null ? response.content() : "";
System.out.println("[最终答复] " + answer);
return answer;
}
if (response.content() != null && !response.content().isBlank()) {
System.out.println("[大脑] " + response.content().strip());
}
RepeatAction repeatAction = repeatDetector.check(response.toolCalls());
if (repeatAction == RepeatAction.STOP) {
System.out.println("[终止] 提醒后仍重复调用,强制停止");
return "��抱歉,我在处理您的问题时遇到了困难。请尝试换一种方式描述,或联系人工客服获取帮助。";
}
if (progressDetector.isStuck(response.content())) {
System.out.println("[终止] 检测到无进展,连续多圈推理内容高度相似");
return "抱歉,我在处理您的问题时遇到了困难,无法进一步推进。请尝试换一种方式描述,或联系人工客服获取帮助。";
}
// 把 assistant 消息追加到消息列表
ObjectNode assistantMsg = messages.addObject();
assistantMsg.put("role", "assistant");
if (response.content() != null) {
assistantMsg.put("content", response.content());
} else {
assistantMsg.putNull("content");
}
ArrayNode tcArray = assistantMsg.putArray("tool_calls");
for (ToolCallInfo tc : response.toolCalls()) {
ObjectNode tcNode = tcArray.addObject();
tcNode.put("id", tc.id());
tcNode.put("type", "function");
ObjectNode funcNode = tcNode.putObject("function");
funcNode.put("name", tc.functionName());
funcNode.put("arguments", tc.arguments());
}
tokenBudget.addMessage(response.content());
// 第一次重复:注入提示,跳过工具执行
// 注意:跳过执行仅适用于确定性只读工具(queryOrder、queryLogistics 等)
// 副作用工具(如 applyRefund)不能跳过,需用幂等键去重
if (repeatAction == RepeatAction.WARN) {
System.out.println("[提醒] 检测到重复调用,注入提示");
String hint = "你已经用相同的参数调用过这个工具,结果不会变化。"
+ "请根据已有信息直接回复用户,不要重复调用。";
for (ToolCallInfo tc : response.toolCalls()) {
ObjectNode toolMsg = messages.addObject();
toolMsg.put("role", "tool");
toolMsg.put("tool_call_id", tc.id());
toolMsg.put("content", hint);
tokenBudget.addMessage(hint);
}
continue;
}
// 执行工具,结果追加到消息列表
for (ToolCallInfo tc : response.toolCalls()) {
System.out.println("[工具调用] " + tc.functionName()
+ "(" + tc.arguments() + ")");
String observation = toolRegistry.execute(
new Action(tc.functionName(), tc.arguments()));
System.out.println("[工具结果] " + observation);
ObjectNode toolMsg = messages.addObject();
toolMsg.put("role", "tool");
toolMsg.put("tool_call_id", tc.id());
toolMsg.put("content", observation);
tokenBudget.addMessage(observation);
}
}
System.out.println("[终止] 达到最大步数 " + maxSteps);
return "抱歉,我思考了太多步仍未完成任务,请尝试换一种方式描述您的问题。";
}
private String buildSystemPrompt() {
return """
你是比特严选的智能客服助手,负责帮助用户解决商品咨询、\
订单查询、物流追踪、退款换货等问题。
请根据用户的问题,合理选择工具获取真实信息,\
然后给出准确、友好的回复。
注意事项:
- 合理选择工具,每次调用后分析结果再决定下一步
- 如果工具返回错误,分析原因并尝试换一种方式解决
- 如果用户的问题超出工具能力范围,直接如实告知
- 最终回复面向用户,不要暴露工具名、JSON 数据等内部细节
- 避免重复调用相同的工具获取相同的信息
""";
}
// ==================== 内部检测器 ====================
private enum RepeatAction {
NORMAL, WARN, STOP
}
private static class RepeatDetector {
private String lastCallSignature = "";
private int repeatCount = 0;
RepeatAction check(List<ToolCallInfo> toolCalls) {
String currentSignature = buildSignature(toolCalls);
if (currentSignature.equals(lastCallSignature)) {
repeatCount++;
} else {
repeatCount = 0;
lastCallSignature = currentSignature;
}
if (repeatCount >= 2) {
return RepeatAction.STOP;
}
if (repeatCount == 1) {
return RepeatAction.WARN;
}
return RepeatAction.NORMAL;
}
private String buildSignature(List<ToolCallInfo> toolCalls) {
StringBuilder sb = new StringBuilder();
for (ToolCallInfo tc : toolCalls) {
sb.append(tc.functionName()).append(":")
.append(tc.arguments()).append(";");
}
return sb.toString();
}
}
private static class TokenBudget {
private static final double TOKENS_PER_CHAR = 1.0;
private final int maxTokens;
private int estimatedTokens = 0;
TokenBudget(int maxTokens) {
this.maxTokens = maxTokens;
}
void addMessage(String content) {
if (content != null) {
estimatedTokens += estimateTokens(content);
}
}
boolean isExceeded() {
return estimatedTokens >= maxTokens;
}
int getEstimatedTokens() {
return estimatedTokens;
}
private int estimateTokens(String text) {
return (int) Math.ceil(text.length() * TOKENS_PER_CHAR);
}
}
private static class ProgressDetector {
private final int windowSize;
private final List<String> recentContents = new ArrayList<>();
ProgressDetector(int windowSize) {
this.windowSize = windowSize;
}
boolean isStuck(String content) {
if (content == null || content.isBlank()) {
return false;
}
recentContents.add(content.strip());
if (recentContents.size() < windowSize) {
return false;
}
if (recentContents.size() > windowSize) {
recentContents.remove(0);
}
for (int i = 1; i < recentContents.size(); i++) {
if (computeSimilarity(recentContents.get(i - 1),
recentContents.get(i)) < 0.7) {
return false;
}
}
return true;
}
private double computeSimilarity(String a, String b) {
Set<Character> setA = toCharSet(a);
Set<Character> setB = toCharSet(b);
Set<Character> intersection = new HashSet<>(setA);
intersection.retainAll(setB);
Set<Character> union = new HashSet<>(setA);
union.addAll(setB);
if (union.isEmpty()) {
return 0.0;
}
return (double) intersection.size() / union.size();
}
private Set<Character> toCharSet(String text) {
Set<Character> set = new HashSet<>();
for (char c : text.toCharArray()) {
if (!Character.isWhitespace(c)) {
set.add(c);
}
}
return set;
}
}
}
跟上一篇的 ReActAgent 对比,核心变化有三处:
| 变化 | 说明 |
|---|---|
构造参数增加 maxSteps 和 maxTokens | 终止条件可配置,不再硬编码 |
| 三个内部检测器 | RepeatDetector、TokenBudget、ProgressDetector |
| 循环体内新增三个检测点 | Token 预算、重复调用、无进展——按优先级排序 |
不变的东西:Tool 接口、五个工具实现、ToolRegistry、LlmClient、BitMallAgentDemo——全都不用改。升级完全在 ReActAgent 内部完成,对外接口没有任何变化(原有的两参数构造函数保持兼容)。
这里能不改
Tool和ToolRegistry,是因为比特严选当前的五个工具里,除了applyRefund之外全是只读查询——重复调用时跳过执行不会有副作用。如果你的业务��里有更多写操作工具,就需要像前面提到的那样,给Tool接口加上deterministic/readOnly等元数据,让重复检测只对符合条件的工具启用跳过执行策略。
跑退款场景验证
升级后跑退款场景,控制台输出:
===== 第 1 圈 =====
[大脑] 您好!我来帮您处理这个问题。让我先查一下您的订单信息和相关的退货政策
[工具调用] queryOrder({"orderId": "88231"})
[工具结果] {"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收","trackingNo":"SF1234567890"}
[工具调用] searchKnowledge({"query": "扫地机 退货政策 质量问题"})
[工具结果] {"query":"扫地机 退货政策 质量问题","matched":"七天无理由退货政策","content":"签收次日起 7 天内,商品外观和主要配件完整,可申请退货;质量问题需先进行售后检测。"}
===== 第 2 圈 =====
[大脑] 好的,已查到您的订单。现在让我确认一下当前日期,看看是否还在退货时效内。
[工具调用] getCurrentTime({})
[工具结果] {"currentTime":"2026-07-01T21:23:54"}
===== 第 3 圈 =====
[大脑] 签收已超过 7 天,不适用七天无理由退货,但质量问题可以走售后检测退款流程。
[工具调用] applyRefund({"orderId": "88231", "reason": "质量问题:扫地机无法回充,已尝试维修但未修好"})
[工具结果] {"success":true,"refundId":"RF20260629001","orderId":"88231","reason":"质量问题:扫地机无法回充,已尝试维修但未修好","message":"退款申请已提交,预计 1-3 个工作日到账"}
===== 第 4 圈 =====
[最终答复] 已为您成功提交退款申请!……
4 圈正常结束——跟升级前完全一致。四道防线没有误触发,因为这个场景本身就是正常的:每圈调不同的工具、推理内容有推进、Token 消耗在预算内、步数没超限。
防线真正发挥作用的是异常场景。比如如果你手动把某个工具的返回值改成一个会让大脑困惑的内容(总是返回”请再试一次”),大脑可能会反复调同一个工具——这时候重复调用检测会在第一次重复时注入提示,大脑大概率会收手总结;如果它还是不听,第二次重复就强制停止。整个过程最多多花一圈的 Token,比傻等到第 10 圈兜底好得多。
生产环境还需要什么
四道防线解决了终止控制的核心问题,但如果你要把 Agent 部署到生产环境,还有几个值得考虑的增强点:
1. 超时控制
目前的终止条件都是基于循环次数和 Token 数量的,但没有时间维度的限制。如果某次工具调用卡住了(比如外部 API 超时),整个 Agent 就会一直等。
生产环境里,通常需要给整个 run() 方法加一个总超时——比如 60 秒。这可以用 CompletableFuture.orTimeout() 或线程池的超时机制来实现,不在 Agent 循环内部处理。
2. 分级终止
四道防线现在都是硬停止——触发后直接返回一段固定文案。更优雅的做法是分级处理:
| 级别 | 触发条件 | 处理方式 |
|---|---|---|
| 警告 | Token 消耗达到预算的 70% | 在系统提示词里追加“请尽快总结并给出回复” |
| 软停止 | 重复调用或无进展检测触发 | 把当前已有的信息拼成一个摘要返回 |
| 硬停止 | Token 预算超限或达到 MAX_STEPS | 直接返回兜底文案 |
警告级别最有意思——它不停止循环,而是在下一圈的消息里追加一条提示,告诉大脑“时间不多了,请尽快收尾”。这样大脑有机会把已经收集到的信息组织成一个有用的回复,而不是突然被截断。
3. 可观测性
现在的终止信息只是 System.out.println 打到控制台。生产环境里,你需要把这些信息记录到日志或监控系统里:
- 哪些请求触发了哪道防线
- 平均循环步数是多少
- Token 预算的使用率分布
- 重复调用和无进展的触发频率
这些数据能帮你调优参数(MAX_STEPS、maxTokens、重复检测阈值),也能发现工具设计或提示词的问题——如果某个工具的调用经常触发重复检测,说明这个工具的返回值不够明确,大脑不知道该怎么用结果。
可观测性是一个独立的大话题,后续系列会专门展开。这里先知道需要观测什么就够了。
四道防线对比总结
| 防线 | 检测目标 | 触发条件 | 误判风险 | 实现成本 | 建议优先级 |
|---|---|---|---|---|---|
| 最大步数 | 死循环 | 超过固定步数 | 极低(但可能截断正常长任务) | 最低 | 必须有 |
| 重复调用检测 | 空转 | 连续 N 次相同工具 + 参数 | 低 | 低 | 强烈建议 |
| Token 预算 | 超预算 | 估算 Token 超阈值 | 低(估算有误差但方向对) | 中 | 建议 |
| 无进展检测 | 隐蔽空转 | 连续 N 圈 content 高度相似 | 中(相似不一定是空转) | 中 | 可选 |
对于大多数场景,最大步数 + 重复调用检测两道防线就够用了。Token 预算在调用量大、成本敏感的场景下加上。无进展检测适合对质量要求高、需要兜住各种边角 case 的场景。
文末总结
这一篇系统解决了 Agent 循环的终止控制问题——从只有一个 MAX_STEPS 兜底,升级到四道防线协同工作:
- 最大步数:最粗暴也最可靠的兜底,��保证循环一定会停。从硬编码改为可配置。
- 重复调用检测:通过工具调用签名比对,抓住同一个工具 + 同样参数的空转。先注入提示给大脑一次自救机会,提醒后仍重复才强制停止。
- Token 预算:用字符数估算 Token 消耗,防止消息列表的累积增长撑爆上下文或烧钱。
- 无进展检测:用 Jaccard 相似度检测大脑是否在兜圈子,抓住重复调用检测抓不住的隐蔽空转。
- 四道防线按优先级排序:Token 预算 → 正常结束 → 重复调用 → 无进展 → 最大步数,每道防线解决一类问题,互不冲突。
一句话收尾:Agent 的能力体现在它能做多少事,Agent 的工程质量体现在它知道什么时候该停。一个不知道什么时候停的 Agent,上了生产就是一颗定时炸弹——不是在烧钱,就是在等着烧钱。
到这里,ReAct 核心部分就告一段落了。从第 04 篇讲透 ReAct 范式,到第 05 篇手写最小循环,第 06 篇加工具定义,第 07 篇打磨提示词,第 08 篇升级 Function Calling,到这一篇搞定终止控制——比特严选智能体已经有了完整的推理-行动循环、结构化的工具调用、以及稳健的终止保护。
下一篇进入第三部分——记忆与上下文。目前的 Agent 每次 run() 都是一个全新的开始,不记得之前聊过什么。如果用户先问了“订单 88231 的物流到哪了”,然后接着问“那我要退款呢”——Agent 不知道“那”指的是哪个订单。**第 10 篇,咱们给 Agent 加上记忆模块:短期记忆和长期记忆。**我们下一篇见。