使用 OpenAI Function Calling 原生工具
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们把系统提示词从最小版升级到了结构化的完整版:角色与边界、格式锚定、Few-shot 示例、注意事项四个模块一上,格式稳定性从 60% 拉到了 95%+。大脑现在基本能稳定地按 Thought: / Action: / Action Input: 格式输出了。
但你有没有注意到一个事实——从第 05 篇到现在,咱们一直在跟文本解析较劲。第 05 篇写了 parseAction() 按行扫描提取工具名和参数,第 06 篇为了支持多行 JSON 入参把解析器改成了多行收集版,第 07 篇又花了大半篇幅打磨提示词来锚定输出格式。三篇文章、三轮加固,本质上都是在给同一个问题打补丁:大模型的输出是自由文本,而你需要从里面精确提取结构化数据。
这一篇,咱们换个思路——不再从文本里提取结构化数据,而是让模型直接返回结构化数据。这就是 Function Calling。
升级到 Function Calling 之后,TinyAgent 的循环模式和 Spring AI、LangChain4j 等主流框架完全一致——这就是现代工具调用 Agent 的工业主路径。它保留了 ReAct 的 Act → Observe → Loop 工程骨架,但模型的推理过程(Thought)从显式的文本标签变成了隐式的内部决策。换句话说,大脑还在想,只是不一定把想法写出来了。如果你的场景需要把推理过程显式拿回来做审计或调试,可以在 Function Calling 框架内加上可观测的推理通道。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.3.x,��默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
文本解析的三个硬伤
在上 Function Calling 之前,先把文本解析方案的天花板说清楚——不是做得不好,而是这条路本身有顶。
1. parseAction 永远是脆弱的
parseAction() 的核心逻辑是按行扫描,找到 Action: 开头的行提取工具名,找到 Action Input: 开头的行提取参数。这种做法有一个根本性的假设:大模型的输出严格遵循预期格式。
但大模型的输出是概率性的。即使提示词写得再严格、Few-shot 示例给得再完整,你也无法保证模型永远按格式输出。冒号从英文变成中文(Action:)、标签前多了个空格( Action:)、换了个大小写(action:)——任何一个微小偏差都可能导致解析失败。
你当然可以用正则表达式做模糊匹配、加更多的容错逻辑,但这条路越走越复杂,最终变成一个越补越大的筛子。
2. stop 序列是个 hack
第 05 篇里,咱们在 API 请求里加了 stop: ["Observation:"],防止大脑自己编造工具返回结果。这个做法管用,但本质上是一个 hack——你在用 API 的停止机制来弥补文本协议的缺陷。
如果模型输出的文本里恰好包含 Observation: 这个词(比如在 Thought 里引用了前一轮的结果),stop 序列会提前截断,导致模型的思考被意外打断。虽然概率不高,但一旦发生就很难排查。
3. 提示词被格式约束占据了大量空间
看看上一篇升级后的系统提示词——900 字里,至少有 400 字是格式约束和 Few-shot 示例。这些内容的唯一目的就是教大脑怎么输出 Thought: / Action: / Action Input: 格式。每次 API 调用都要发送这 400 字的格式教程,每一圈循环都要消耗这部分 Token。
如果有一种方式能让模型直接返回结构化的工具调用,这 400 字的格式约束、Few-shot 示例、stop 序列,全部可以删掉。
快速回顾 Function Calling
如果你跟着 RAG 系列一路走过来,Function Calling 应该不陌生——那篇文章里已经详细讲过它的原理和协议细节。这里只快速回顾核心概念,重点放在它怎么用在 Agent 循环里。
1. 核心机制
Function Calling 是 OpenAI 在 Chat Completions API 里提供的一个能力:你在请求里传入一组工具定义(tools 参数),模型分析用户问题后,如果认为需要调用工具,会在响应里返回一个结构化的 tool_calls 字段,包含函数名和参数——不是文本,是 JSON。
你的代码发送:messages + tools(工具定义)
↓
模型返回:tool_calls: [{id, function: {name, arguments}}]
↓
你的代码执行工具,把结果用 tool 角色消息发回
↓
模型看到结果,继续推理或给出最终答复
关键点:模型不执行工具,它只是告诉你应该调这个工具,参数是这些。执行工具、拿回结果、再发给模型——这些都是你的代码做的。
2. 跟文本 ReAct 的本质区别
文本 ReAct 是一种提示词协议——你在提示词里定义 Thought: / Action: / Action Input: 格式,模型照着格式输出文本,你的代码从文本里提取信息。
Function Calling 是一种 API 协议——你通过 API 参数传入工具定义,模型通过 API 响应的结构化字段返回工具调用。
打个比方:文本 ReAct 就像你跟同事约定需要我做什么就写在便利贴上,格式是工具名加参数,同事写字潦草的时候你就看不懂。Function Calling 就像公司上了一套工单系统,同事在系统里选工具、填参数、提交,你收到的永远是格式标准的工单——不存在看不懂的情况。
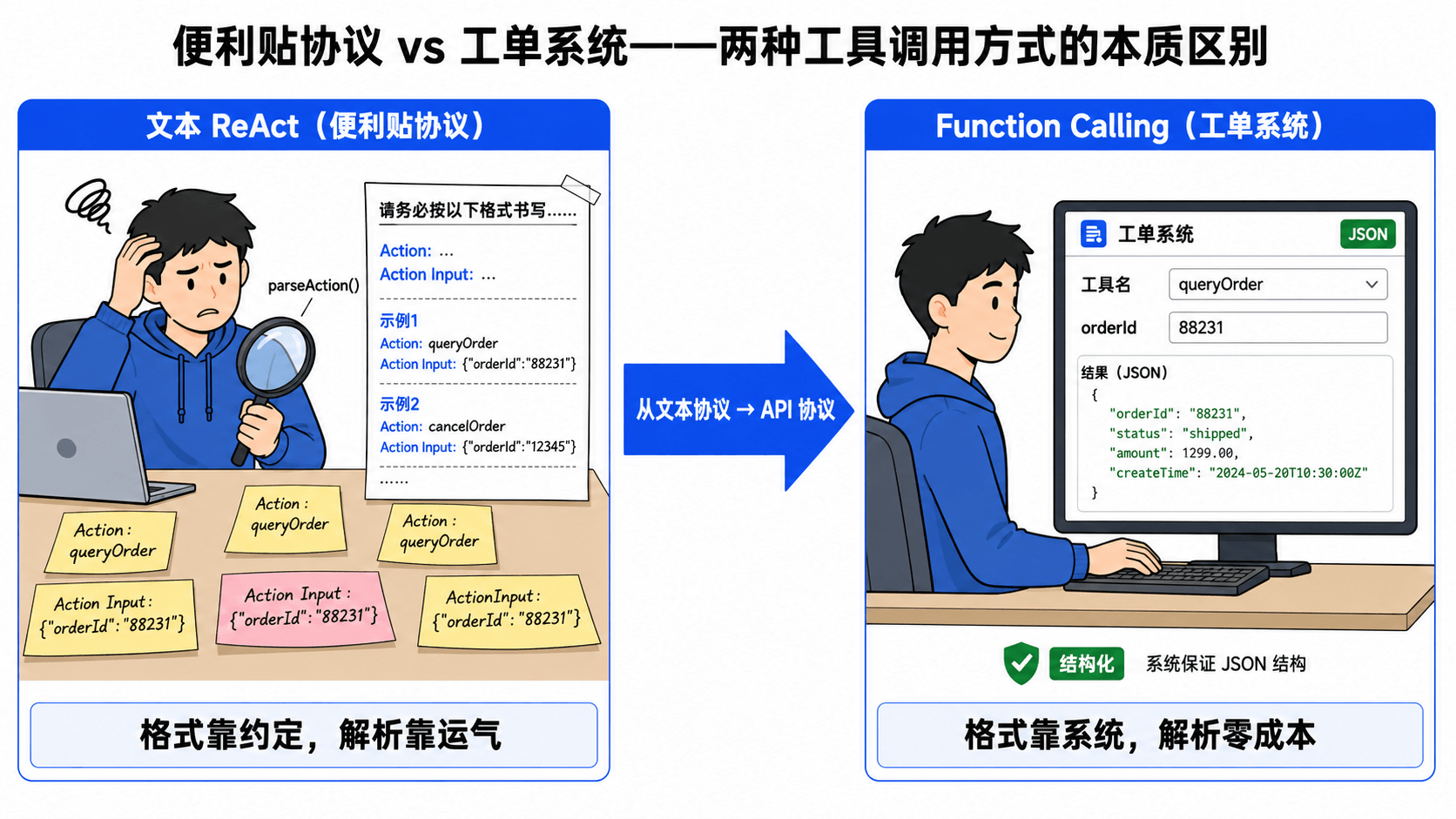
从文本 ReAct 到 Function Calling:到底改了什么
升级到 Function Calling,核心代码逻辑没变——还是 Agent 循环,还是推理-行动-观测的三元组。变的是三个东西:工具怎么告诉模型、模型怎么告诉你要调什么、工具结果怎么传回模型。
1. 工具定义:从提示词文本到 API 参数
文本 ReAct:工具定义写在系统提示词里,模型在 system 消息的文本中看到工具列表。
## 可用工具
1. queryOrder
描述:查询订单详情,返回商品名、价格、下单时间……
参数 Schema:{"type":"object","properties":{"orderId":{"type":"string",...}}}
Function Calling:工具定义通过 API 请求的 tools 参数传入,模型在 API 层面就知道有哪些工具可用。
{
"tools": [
{
"type": "function",
"function": {
"name": "queryOrder",
"description": "查询订单详情,返回商品名、价格、下单时间…�…",
"parameters": {
"type": "object",
"properties": {
"orderId": {"type": "string", "description": "订单号,如 88231"}
},
"required": ["orderId"]
}
}
}
]
}
工具的名称、描述、参数 Schema 完全一��样,只是从提示词文本搬到了 API 参数。
2. 模型输出:从文本到结构化 JSON
文本 ReAct:模型输出一段文本,里面包含 Thought:、Action:、Action Input: 标签,你的代码用 parseAction() 提取。
Thought: 用户想查订单 88231 的详情,我需要调用 queryOrder 工具。
Action: queryOrder
Action Input: {"orderId":"88231"}
Function Calling:模型返回的 JSON 响应里直接包含 tool_calls 字段,结构化的函数名和参数。
{
"choices": [{
"message": {
"role": "assistant",
"content": "用户想查订单 88231 的详情,我需要调用 queryOrder 工具。",
"tool_calls": [{
"id": "call_abc123",
"type": "function",
"function": {
"name": "queryOrder",
"arguments": "{\"orderId\":\"88231\"}"
}
}]
},
"finish_reason": "tool_calls"
}]
}
注意两个细节:
content字段:模型的思考过程(相当于 Thought)放在content里。有些模型会在这里写推理过程,有些会留空(null)。不管有没有,不影响工具调用的解析。finish_reason:当模型决定调工��具时,finish_reason是"tool_calls";当模型给出最终答复时,finish_reason是"stop"。你的代码根据这个字段判断该执行工具还是结束循环——不再需要从文本里找Final Answer:。
3. 工具结果:从 user 角色到 tool 角色
文本 ReAct:工具执行结果包在 user 角色的消息里,以 Observation: 前缀追加到消息列表。
{"role": "user", "content": "Observation: {\"orderId\":\"88231\",\"product\":\"比特 S10 Pro 扫地机\"...}"}
Function Calling:工具执行结果用专门的 tool 角色消息返回,通过 tool_call_id 与对应的工具调用关联。
{"role": "tool", "tool_call_id": "call_abc123", "content": "{\"orderId\":\"88231\",\"product\":\"比特 S10 Pro 扫地机\"...}"}
tool 角色是 Function Calling 协议专有的角色类型。模型看到 tool 角色的消息,就知道这是工具的真实返回结果,不会跟用户消息混淆。
4. 删掉的东西
升级到 Function Calling 后,以下内容全部可以删掉:
| 删除项 | 文本 ReAct 里的用途 | Function Calling 为什么不需要 |
|---|---|---|
parseAction() | 从文本提取工具名和参数 | API 直接返回结构化的 tool_calls |
extractFinalAnswer() | 从文本提取最终答复 | finish_reason="stop" 时 content 就是最终答复 |
stop: ["Observation:"] | 防止模型编造工具结果 | API 协议保证模型不会自己编 tool 角色消息 |
| 格式锚定提示词 | 教大脑按 Thought/Action 格式输出 | 工具调用格式由 API 保证 |
| Few-shot 示例 | 锚定输出格式 | 格式不再依赖示例(复杂推理场景仍可选用) |
用一张时序图看 Function Calling 模式下一圈循环的完整调用链:
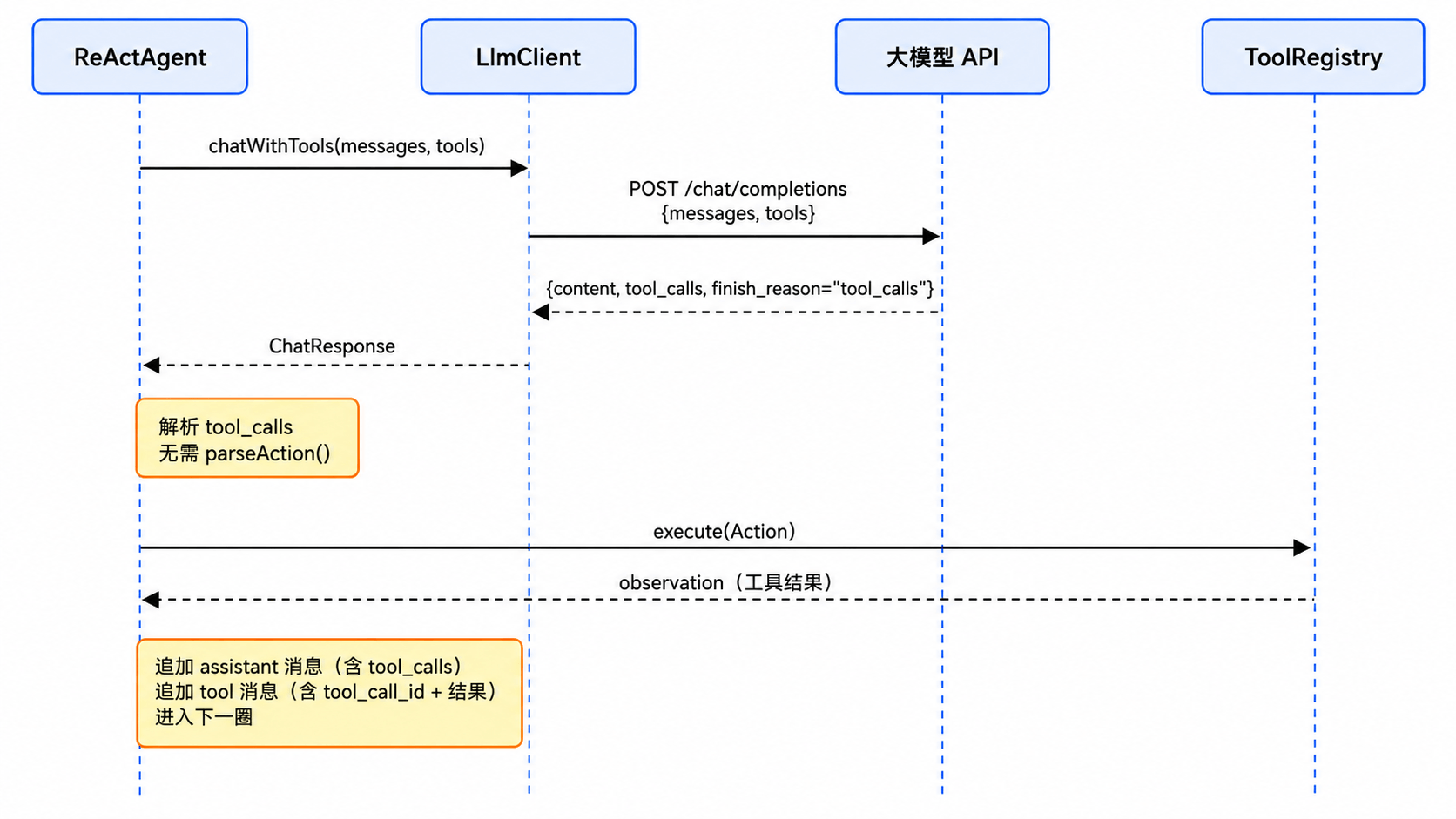
消息流对比
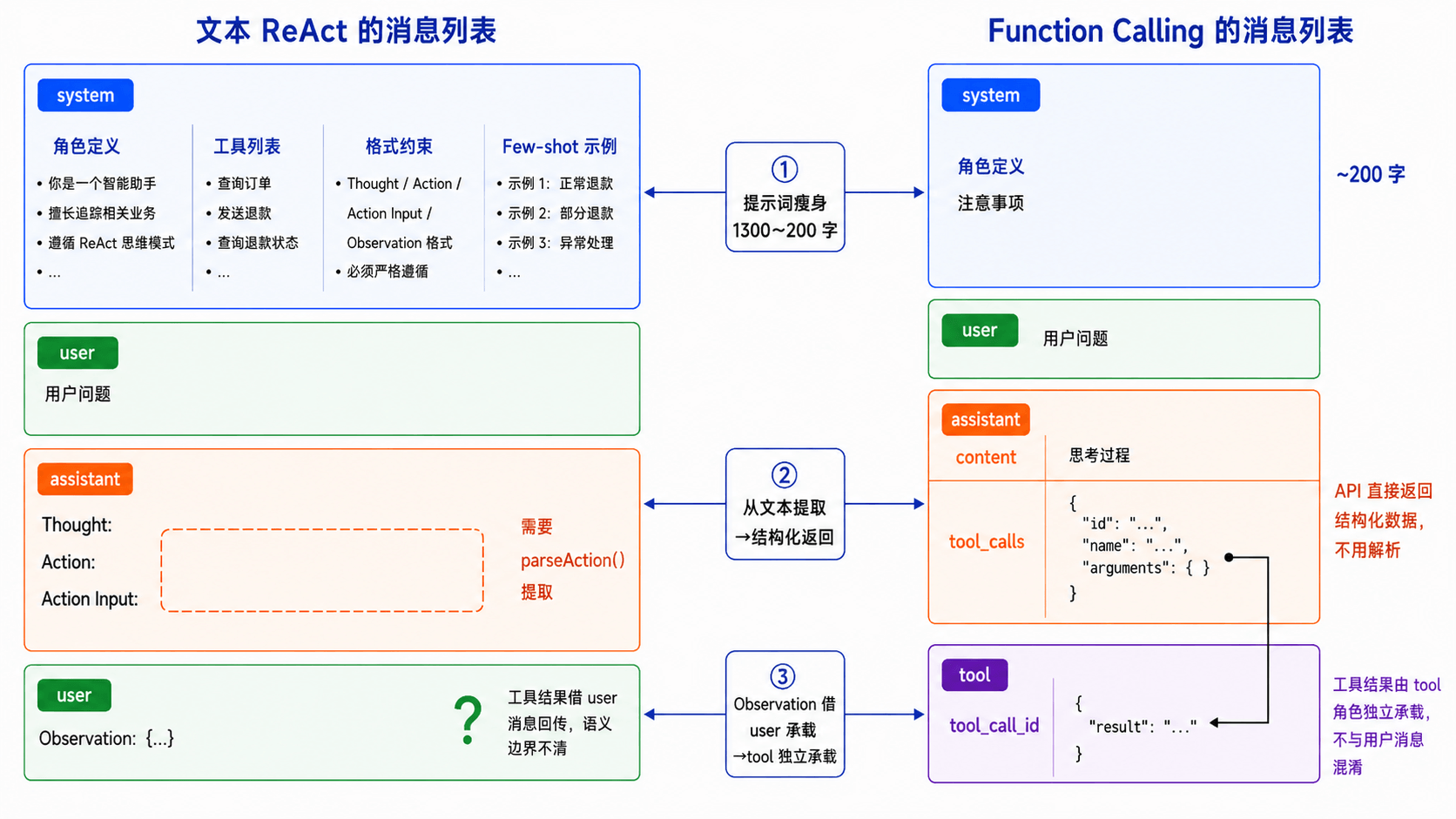
用退款场景的第一圈循环,对比两种方案的消息流:
1. 文本 ReAct 的消息列表
messages[0] = {role: "system", content: "你是比特严选的智能客服助手...(含工具列表、格式约束、Few-shot 示例,约 1300 字)"}
messages[1] = {role: "user", content: "我上周买的扫地机不回充了,修不好我想退。订单号 88231。"}
messages[2] = {role: "assistant", content: "Thought: 用户想退...\nAction: queryOrder\nAction Input: {\"orderId\":\"88231\"}"}
messages[3] = {role: "user", content: "Observation: {\"orderId\":\"88231\",\"product\":\"比特 S10 Pro 扫地机\"...}"}
2. Function Calling 的消息列表
messages[0] = {role: "system", content: "你是比特严选的智能客服助手...(仅角色+注意事项,约 200 字)"}
messages[1] = {role: "user", content: "我上周买的扫地机不回充了,修不好我想退。订单号 88231。"}
messages[2] = {role: "assistant", content: "用户想退...", tool_calls: [{id: "call_abc", function: {name: "queryOrder", arguments: "{\"orderId\":\"88231\"}"}}]}
messages[3] = {role: "tool", tool_call_id: "call_abc", content: "{\"orderId\":\"88231\",\"product\":\"比特 S10 Pro 扫地机\"...}"}
对比之下,三个变化一目了然:
| 维度 | 文本 ReAct | Function Calling |
|---|---|---|
| 系统提示词长度 | 约 1300 字(含格式约束、示例) | 约 200 字(仅角色 + 注意事项) |
| assistant 消息 | 纯文本,格式靠提示词约定 | content + tool_calls 结构化字段 |
| 工具结果消息 | user 角色 + Observation: 前缀 | tool 角色 + tool_call_id 关联 |
系统提示词从 1300 字缩减到 200 字——这不仅节省 Token,还让模型能把更多注意力放在用户问题和工具结果上,而不是格式约束上。
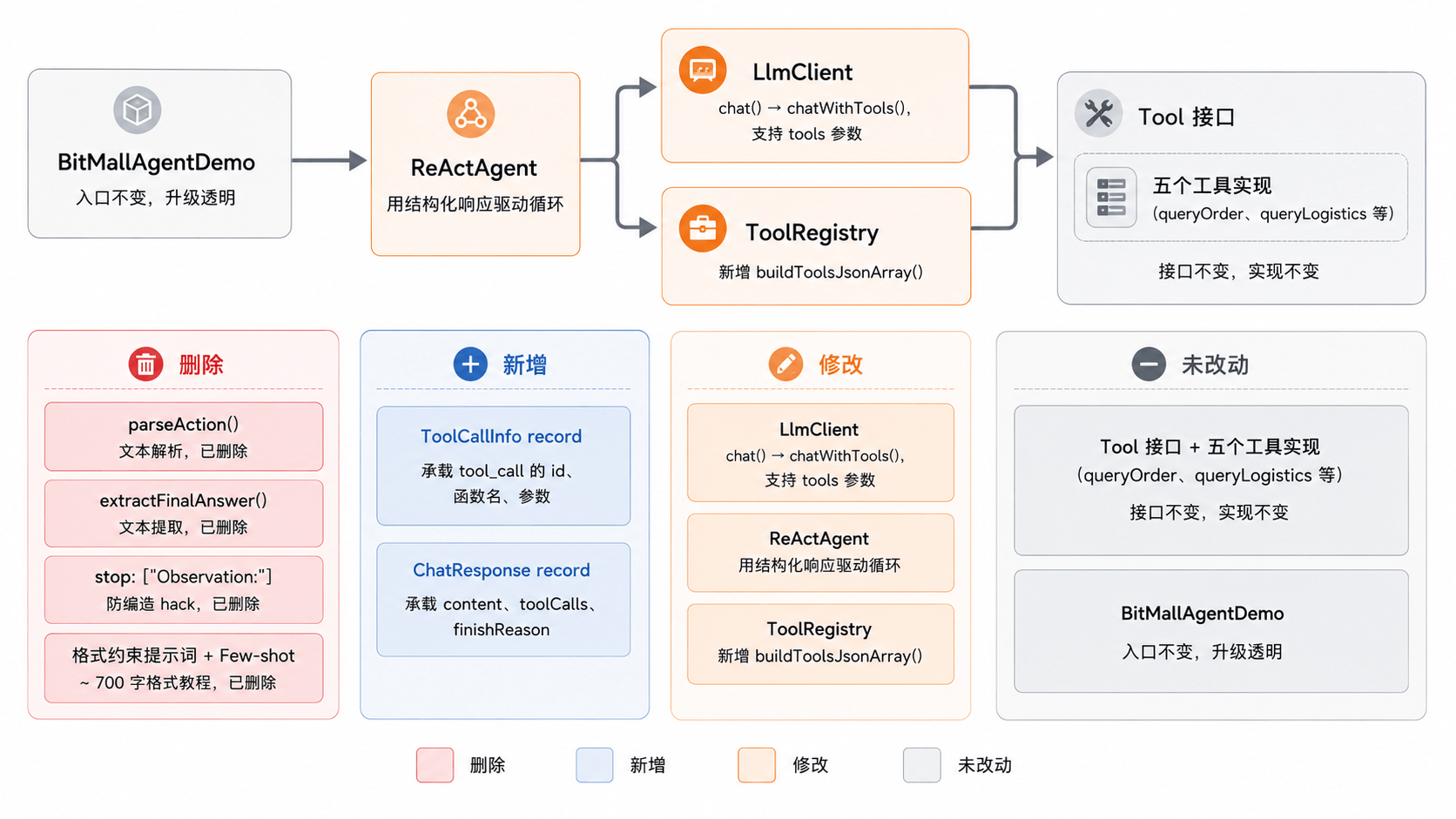
代码实战:升级 TinyAgent
概念讲完了,动手改代码。这次是直接升级现有的 react 包,而不是另起一套——Function Calling 本质上还是 ReAct 循环,只是工具调用的通信方式从文本协议换成了 API 协议。
变动涉及三个层面:新增两个数据载体(ToolCallInfo、ChatResponse),LlmClient 新增 chatWithTools() 方法,ReActAgent 用 Function Calling 替换文本解析。Tool 接口、五个工具实现、ToolRegistry(除了新增一个方法)、BitMallAgentDemo 入口——全都不用改。
1. ToolRegistry:新增 buildToolsJsonArray()
第 06 篇咱们给 ToolRegistry 加了 buildToolList(),把工具定义拼成文本塞进提示词。现在要加一个方法,把工具定义转成 API 的 tools 参数格式:
public ArrayNode buildToolsJsonArray(ObjectMapper objectMapper) {
ArrayNode toolsArray = objectMapper.createArrayNode();
for (Tool tool : tools.values()) {
ObjectNode toolNode = toolsArray.addObject();
toolNode.put("type", "function");
ObjectNode functionNode = toolNode.putObject("function");
functionNode.put("name", tool.name());
functionNode.put("description", tool.description());
String params = tool.parameters();
if (params != null && !params.isBlank()) {
try {
functionNode.set("parameters", objectMapper.readTree(params));
} catch (Exception e) {
functionNode.putObject("parameters").put("type", "object");
}
} else {
functionNode.putObject("parameters").put("type", "object");
}
}
return toolsArray;
}
这个方法遍历所有注册的工具,把每个工具的 name()、description()、parameters() 组装成 OpenAI 格式的 JSON。对比 buildToolList() 拼文本字符串,这里用 Jackson 的 ObjectNode 构建 JSON——类型安全,不用担心转义问题。
注意 parameters() 的处理:返回的是 JSON Schema 字符串,先用 readTree() 解析成 JsonNode 再设置进去。如果解析失败(Schema 格式不合法),兜底用一个空的 {"type":"object"},不至于整个请求崩掉。
生成的结果长这样:
[
{
"type": "function",
"function": {
"name": "queryOrder",
"description": "查询订单详情,返回商品名、价格、下单时间、签收时间、订单状态、运单号。",
"parameters": {
"type": "object",
"properties": {
"orderId": {"type": "string", "description": "订单号,如 88231"}
},
"required": ["orderId"]
}
}
},
{
"type": "function",
"function": {
"name": "queryLogistics",
"description": "根据运单号查询物流轨迹,返回承运商、物流状态和轨迹详情。",
"parameters": {
"type": "object",
"properties": {
"trackingNo": {"type": "string", "description": "快递运单号,如 SF1234567890"}
},
"required": ["trackingNo"]
}
}
}
]
跟第 06 篇定义的 JSON Schema 完全一致,只是外面多包了一层 type: "function" 和 function 的壳。
第 06 篇那句话现在兑现了:
parameters()返回的 JSON Schema,切换到原生 Function Call 时直接复用,改的只是调用方式和解析方式——Tool接口一行没改,五个工具实现一行没改,变的只是工具定义的传递方式。
2. 两个数据载体:ToolCallInfo 和 ChatResponse
文本 ReAct 用 Action record 承载解析出的工具名和参数。Function Calling 的响应结构更丰富,需要两个新的数据载体。
ToolCallInfo——承载一次工具调用的信息:
public record ToolCallInfo(String id, String functionName, String arguments) {
}
跟 Action 的区别是多了一个 id 字段。这个 id 是模型为每次工具调用生成的唯一标识,回传工具结果时需要用 tool_call_id 关联——模型靠这个 ID 知道哪个结果对应哪个调用。
ChatResponse——承载模型的完整响应:
public record ChatResponse(String content, List<ToolCallInfo> toolCalls,
String finishReason) {
public boolean hasToolCalls() {
return toolCalls != null && !toolCalls.isEmpty();
}
}
三个字段分别对应 API 响应里的三个关键信息:
content:模型的思考过程(类似 Thought),可能为nulltoolCalls:结构化的工具调用列表finishReason:"tool_calls"表示模型想调工具,"stop"表示模型认为任务完成
hasToolCalls() 是个便利方法,循环里用它判断这一圈是该执行工具还是该结束。
3. LlmClient:新增 chatWithTools()
原来的 chat() 方法删除,新增一个 chatWithTools() 方法支持 Function Calling:
public ChatResponse chatWithTools(ArrayNode messages, ArrayNode tools) {
try {
ObjectNode requestBody = objectMapper.createObjectNode();
requestBody.put("model", model);
requestBody.put("temperature", 0.1);
requestBody.set("messages", messages);
requestBody.set("tools", tools);
String responseText = doRequestRaw(requestBody);
JsonNode responseJson = objectMapper.readTree(responseText);
JsonNode choice = responseJson.at("/choices/0");
String finishReason = choice.path("finish_reason").asText("");
JsonNode message = choice.path("message");
String content = message.path("content").isNull()
? null : message.path("content").asText(null);
List<ToolCallInfo> toolCalls = new ArrayList<>();
JsonNode toolCallsNode = message.path("tool_calls");
if (toolCallsNode.isArray()) {
for (JsonNode tc : toolCallsNode) {
String id = tc.path("id").asText();
String funcName = tc.at("/function/name").asText();
String arguments = tc.at("/function/arguments").asText();
toolCalls.add(new ToolCallInfo(id, funcName, arguments));
}
}
return new ChatResponse(content, toolCalls, finishReason);
} catch (IOException e) {
throw new RuntimeException("调用大模型失败:" + e.getMessage(), e);
}
}
同时把原来 HTTP 调用逻辑抽到一个私有方法 doRequestRaw():
private String doRequestRaw(ObjectNode requestBody) throws IOException {
Request request = new Request.Builder()
.url(apiUrl)
.addHeader("Authorization", "Bearer " + apiKey)
.post(RequestBody.create(requestBody.toString(), JSON_MEDIA_TYPE))
.build();
try (Response response = httpClient.newCall(request).execute()) {
ResponseBody body = response.body();
String responseText = body == null ? "" : body.string();
if (!response.isSuccessful()) {
throw new RuntimeException(
"API 调用失败,状态码:" + response.code() + ",响应:" + responseText);
}
return responseText;
}
}
跟原来的 chat() 对比,chatWithTools() 有三处核心变化:
第一,请求体多了 tools 字段。工具定义不再写在系统提示词里,而是通过 API 参数传入。模型在 API 层面就知道有哪些工具可用,不需要从提示词文本里去理解。
第二,没有 stop 序列。Function Calling 模式下,模型想调工具时会通过 tool_calls 字段返回,不会在文本里输出 Observation:——因为工具结果是通过 tool 角色消息回传的,模型知道自己不该编这个。stop 序列存在的理由消失了。
第三,响应解析变了。原来是从 choices[0].message.content 提取纯文本返回字符串,现在要同时提取 content(思考过程,可能为 null)、tool_calls(工具调用列表)和 finish_reason(终止原因),封装成 ChatResponse 返回。
解析 tool_calls 的逻辑也很直白:遍历 JSON 数组,从每个元素里取 id、function.name、function.arguments,构建 ToolCallInfo。arguments 是一个 JSON 字符串,不需要在这一层解析——交给 Tool.invoke() 去处理,跟之前一样。
4. ReActAgent:用 Function Calling 驱动循环
所有零件到齐,直接升级 ReActAgent 的主循环:
public class ReActAgent {
private static final int MAX_STEPS = 10;
private final LlmClient llmClient;
private final ToolRegistry toolRegistry;
private final ObjectMapper objectMapper;
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry) {
this.llmClient = llmClient;
this.toolRegistry = toolRegistry;
this.objectMapper = llmClient.getObjectMapper();
}
public String run(String userMessage) {
// 构建消息列表
ArrayNode messages = objectMapper.createArrayNode();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", buildSystemPrompt());
ObjectNode userMsg = messages.addObject();
userMsg.put("role", "user");
userMsg.put("content", userMessage);
// 构建 tools 参��数
ArrayNode tools = toolRegistry.buildToolsJsonArray(objectMapper);
for (int step = 1; step <= MAX_STEPS; step++) {
System.out.println("\n===== 第 " + step + " 圈 =====");
ChatResponse response = llmClient.chatWithTools(messages, tools);
// 没有工具调用 → 最终答复,直接返回
if (!response.hasToolCalls()) {
String answer = response.content() != null ? response.content() : "";
System.out.println("[最终答复] " + answer);
return answer;
}
// 有工具调用时,先打印思考过程
if (response.content() != null && !response.content().isBlank()) {
System.out.println("[大脑] " + response.content().strip());
}
// 把 assistant 消息(含 tool_calls)追加到消息列表
ObjectNode assistantMsg = messages.addObject();
assistantMsg.put("role", "assistant");
if (response.content() != null) {
assistantMsg.put("content", response.content());
} else {
assistantMsg.putNull("content");
}
ArrayNode tcArray = assistantMsg.putArray("tool_calls");
for (ToolCallInfo tc : response.toolCalls()) {
ObjectNode tcNode = tcArray.addObject();
tcNode.put("id", tc.id());
tcNode.put("type", "function");
ObjectNode funcNode = tcNode.putObject("function");
funcNode.put("name", tc.functionName());
funcNode.put("arguments", tc.arguments());
}
// 执行每个工具调用,把结果用 tool 角色追加
for (ToolCallInfo tc : response.toolCalls()) {
System.out.println("[工具调用] " + tc.functionName()
+ "(" + tc.arguments() + ")");
String observation = toolRegistry.execute(
new Action(tc.functionName(), tc.arguments()));
System.out.println("[工具结果] " + observation);
ObjectNode toolMsg = messages.addObject();
toolMsg.put("role", "tool");
toolMsg.put("tool_call_id", tc.id());
toolMsg.put("content", observation);
}
}
return "抱歉,我思考了太多步仍未完成任务,请尝试换一种方式描述您的问题。";
}
private String buildSystemPrompt() {
return """
你是比特严选的智能客服助手,负责帮助用户解决商品咨询、\
订单查询、物流追踪、退款换货等问题。
请根据用户的问题,合理选择工具获取真实信息,\
然后给出准确、友好的回复。
注意事项:
- 合理选择工具,每次调用后分析结果再决定下一步
- 如果工具返回错误,分析原因并尝试换一种方式解决
- 如果用户的问题超出工具能力范围,直接如实告知
- 最终回复面向用户,不要暴露工具名、JSON 数据等内部细节
""";
}
}
跟升级前的 ReActAgent 对比,看看哪些东西消失了、哪些东西变了:
4.1 消失的东西
| 删除的代码 | 原来的用途 |
|---|---|
parseAction() | 从文本提取工具名和参数 |
extractFinalAnswer() | 从文本提取最终答复 |
isPromptSection() | 辅助多行 JSON 解析的标签判断 |
stop: ["Observation:"] | 防止模型编造工具结果(在 LlmClient.chat() 里) |
| 格式约束提示词 | Thought/Action/Action Input 格式说明 |
| Few-shot 示例 | 锚定输出格式的完整示范 |
三个解析方法全部删掉了。从第 05 篇写 parseAction() 到第 06 篇改多行版本再到现在直接删除——这就是为什么第 05 篇说"别急着修,第 08 篇咱们会用 Function Calling 彻底替掉文本解析"。
4.2 变化的东西
消息列表从 Map<String, String> 变成了 ArrayNode。文本 ReAct 用 Map.of("role", "user", "content", "...") 构建消息,每条消息只有 role 和 content 两个字符串字段。Function Calling 的 assistant 消息里多了 tool_calls 数组,tool 消息里有 tool_call_id 字段,用简单的 Map<String, String> 装不下了。所以改用 Jackson 的 ObjectNode / ArrayNode 来构建消息列表——灵活度更高,能放任意结构的 JSON 字段。
终止判断从找 Final Answer: 变成了判断 hasToolCalls()。文本 ReAct 里,你需要在模型输出中扫描 Final Answer: 字符串来判断任务是否完成。Function Calling 里更简单:response.hasToolCalls() 返回 false 就意味着模型没有要调的工具了(finish_reason="stop"),content 里就是最终答复——不需要任何文本匹配。
工具结果从 user 消息变成了 tool 消息。文本 ReAct 用 messages.add(Map.of("role", "user", "content", "Observation: " + observation)) 把工具结果当成用户消息追加。Function Calling 用 tool 角色和 tool_call_id 关联。模型能明确区分用户消息和工具返回结果,不会把两者混淆。
系统提示词从 900 字缩减到不到 200 字。没了格式约束和 Few-shot 示例,系统提示词只剩角色定义和注意事项。工具列表也不用塞进去了——通过 API 参数传入。
4.3 不变的东西
循环的骨架没变:初始化消息列表 → 调模型 → 判断是否结束 → 执行工具 → 追加结果 → 下一圈。MAX_STEPS 兜底也没变。toolRegistry.execute() 的调用方式也没变——还是传一个 Action 进去。BitMallAgentDemo 入口也完全不用改——它引用的是 LlmClient 和 ReActAgent,接口签名没变,升级对调用方透明。
跑退款场景看效果
运行 BitMallAgentDemo,退款场景的控制台输出大致如下:
===== 第 1 圈 =====
[大脑] 您好!我来帮您处理这个问题。让我先查一下您的订单信息和相关的退货政策
[工具调用] queryOrder({"orderId": "88231"})
[工具结果] {"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收","trackingNo":"SF1234567890"}
[工具调用] searchKnowledge({"query": "扫地机 退货政策 质量问题"})
[工具结果] {"query":"扫地机 退货政策 质量问题","matched":"七天无理由退货政策","content":"签收次日起 7 天内,商品外观和主要配件完整,可申请退货;质量问题需先进行售后检测。"}
===== 第 2 圈 =====
[大脑] 好的,已查到您的订单。现在让我确认一��下当前日期,看看是否还在退货时效内。
[工具调用] getCurrentTime({})
[工具结果] {"currentTime":"2026-07-01T21:23:54"}
===== 第 3 圈 =====
[大脑] 根据查询结果:
- **订单号**:88231
- **商品**:比特 S10 Pro 扫地机
- **金额**:¥1999
- **签收时间**:2026年6月22日
- **当前时间**:2026年7月1日
很遗憾,签收已超过7天,不再适用「七天无理由退货」。但您的情况属于**质量问题**(无法回充),根据政策可以走售后检测退款流程。我现在就帮您发起退款申请
[工具调用] applyRefund({"orderId": "88231", "reason": "质量问题:扫地机无法回充,已尝试维修但未修好"})
[工具结果] {"success":true,"refundId":"RF20260629001","orderId":"88231","reason":"质量问题:扫地机无法回充,已尝试维修但未修好","message":"退款申请已提交,预计 1-3 个工作日到账"}
===== 第 4 圈 =====
[最终答复] 已为您成功提交退款申请!以下是退款详情:
| 项目 | 详情 |
|------|------|
| 📦 **商品** | 比特 S10 Pro 扫地机 |
| 💰 **退款金额** | ¥1999 |
| 📋 **退款单号** | RF20260629001 |
| 🏷️ **退款原因** | 质量问题:无法回充,已尝试维修未修好 |
| ⏱️ **预计到账** | **1-3 个工作日** |
---
### 后续注意事项:
- 退款会原路退回您的支付账户,请留意到账通知。
- 平台可能会安排上门取件,届时请保持商品及配件完整。
- 如有其他问题,随时找我~
========== 最终结果 ==========
已为您成功提交退款申请!以下是退款详情:
| 项目 | 详情 |
|------|------|
| 📦 **商品** | 比特 S10 Pro 扫地机 |
| 💰 **退款金额** | ¥1999 |
| 📋 **退款单号** | RF20260629001 |
| 🏷️ **退款�原因** | 质量问题:无法回充,已尝试维修未修好 |
| ⏱️ **预计到账** | **1-3 个工作日** |
---
### 后续注意事项:
- 退款会原路退回您的支付账户,请留意到账通知。
- 平台可能会安排上门取件,届时请保持商品及配件完整。
- 如有其他问题,随时找我~
跟第 05 篇文本 ReAct 的输出对比,逻辑完全一致——四圈循环,三次工具调用,推理链路一样。区别在哪?
工具调用的参数格式稳定了。文本 ReAct 里,大脑偶尔会输出 Action Input: 88231(纯文本而非 JSON),Function Calling 里模型返回的 arguments 始终是 {"orderId":"88231"} 这样的 JSON 字符串——格式一致性从“绝大部分时候对”提升到了近 100%。
输出里没有 Thought: / Action: / Action Input: 标签了。大脑的思考过程直接显示在 [大脑] 后面,工具调用显示在 [工具调用] 后面——这些是代码里的 System.out.println 打印的,不是模型输出的格式标��签。模型输出的是结构化的 content 和 tool_calls,不需要靠文本标签来区分。
最终答复的判断更简洁了。文本 ReAct 要扫描 Final Answer: 字符串,Function Calling 只需要判断 hasToolCalls() 是否为 false。
再跑一个查物流
用简单场景验证一下:
String answer = agent.run("帮我看看订单 88231 的快递到哪了。");
控制台输出:
===== 第 1 圈 =====
[大脑] 好的,我先帮您查一下订单 88231 的详情,找到运单号后再查物流信息
[工具调用] queryOrder({"orderId": "88231"})
[工具结果] {"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收","trackingNo":"SF1234567890"}
===== 第 2 圈 =====
[大脑] 订单已显示签收,不过我再帮您查一下详细的物流轨迹,看看完整的运输过程。
[工具调用] queryLogistics({"trackingNo": "SF1234567890"})
[工具结果] {"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收","traces":[{"time":"2026-06-20 18:20:00","desc":"快件已揽收"},{"time":"2026-06-21 09:10:00","desc":"快件到达上海转运中心"},{"time":"2026-06-22 11:35:00","desc":"快件已由本人签收"}]}
===== 第 3 圈 =====
[最终答复] 您好!您查询的订单 **88231** 的快递信息如下:
| 项目 | 详情 |
|------|------|
| **商品** | 比特 S10 Pro 扫地机 |
| **金额** | ¥1,999.00 |
| **承运商** | 顺丰速运 |
| **运单号** | SF1234567890 |
| **当前状态** | ✅ 已签收 |
**物流轨迹:**
| 时间 | 状态 |
|------|------|
| 6月20日 18:20 | 快件已揽收 |
| 6月21日 09:10 | 快件到达上海转运中心 |
| 6月22日 11:35 | 快件已由本人签收 |
您的包裹已于 **6月22日上午11:35** 签收,三天时间就从发货到签收,速度还是很快的!如果您没有收到这个包裹,或者对签收有疑问,可以随时告诉我,我帮您进一步处理。
========== 最终结果 ==========
您好!您查询的订单 **88231** 的快递信息如下:
| 项目 | 详情 |
|------|------|
| **商品** | 比特 S10 Pro 扫地机 |
| **金额** | ¥1,999.00 |
| **承运商** | 顺丰速运 |
| **运单号** | SF1234567890 |
| **当前状态** | ✅ 已签收 |
**物流轨迹:**
| 时间 | 状态 |
|------|------|
| 6月20日 18:20 | 快件已揽收 |
| 6月21日 09:10 | 快件到达上海转运中心 |
| 6月22日 11:35 | 快件已由本人签收 |
您的包裹已于 **6月22日上午11:35** 签收,三天时间就从发货到签收,速度还是很快的!如果您没有收到这个包裹,或者对签收有疑问,可以随时告诉我,我帮您进一步处理。
两圈工具调用,跟文本 ReAct 的结果完全一致。
两种方案全面对比
到这里,两种方案你都手写实现过了。用一张表做个全面对比:
| 维度 | 文本 ReAct(升级前) | Function Calling(升级后) |
|---|---|---|
| 工具定�义方式 | JSON Schema 写在提示词文本里 | JSON Schema 通过 API tools 参数传入 |
| 模型输出格式 | 自由文本:Thought: / Action: / Action Input: | 结构化 JSON:content + tool_calls |
| 参数解析 | parseAction() 从文本里按行提取 | API 直接返回解析好的 JSON |
| 解析稳定性 | 依赖提示词约束,偶尔格式跑偏 | API 层面保证格式,近 100% 稳定 |
| 终止判断 | 扫描文本里的 Final Answer: 字符串 | finish_reason="stop" 或 hasToolCalls()=false |
| 工具结果传递 | user 角色 + Observation: 前缀 | tool 角色 + tool_call_id 关联 |
| 系统提示词长度 | 约 1300 字(含格式约束、Few-shot) | 约 200 字(仅角色 + 注意事项) |
| 每圈 Token 消耗 | 较高(提示词长、格式教程占空间) | 较低(提示词短) |
| Thought 可见性 | 强制每圈输出,格式统一,调试直观 | content 可能为 null,格式不固定 |
| 模型兼容性 | 所有支持聊天的模型都能用 | 需要模型 API 支持 Function Calling |
| 代码复杂度 | 需要 parseAction、stop 序列、格式提示词 | 代码更简洁,但消息构建稍复杂(ObjectNode) |
总结成一句话:Function Calling 用 API 层面的结构化保证替代了提示词层面的文本约定,稳定性更高、Token 更省、代码更简洁,但要求模型支持这个能力。
什么时候该回退到文本 ReAct
既然 Function Calling 全方位更好,是不是文本 ReAct 就没用了?不是。有两种场景你可能需要回退到文本 ReAct:
- 模型不支持 Function Calling:部分开源小模型或私有部署的模型可能没有 Function Calling 能力,这时候只能走文本协议。
- 需要自定义推理格式:比如你想让大脑在 Thought 里加一个 Confidence Score(置信度评分),或者加一个 Reflection(反思)步骤——这些自定义格式只能通过提示词协议来定义,Function Calling 的 API 协议不支持扩展。
实际工程中,主流商用模型(DeepSeek、通义千问、智谱、OpenAI)都支持 Function Calling,绝大多数场景直接用 Function Calling 就好。
还有一个实际的考量:不同模型厂商的 Function Calling 实现细节有差异。OpenAI、DeepSeek、通义千问、智谱的 API 都兼容 OpenAI 的 tools / tool_calls 协议,但有些细节不同——比如 content 字段在部分厂商的 tool_calls 响应里始终为 null,有些厂商则会填入推理文本。咱们的代码里对 content 为 null 的情况做了处理(response.content() != null 的判断),所以跨厂商切换基本不会出问题。
提示词的变化:该保留什么
从 900 字缩减到 200 字,提示词删了很多东西。但不是所有删掉的东��西都不需要了——需要区分因为格式而存在和因为质量而存在的内容:
| 提示词内容 | 文本 ReAct 里的用途 | Function Calling 里是否保留 |
|---|---|---|
| 角色定义 | 告诉大脑身份和职责 | 保留——大脑仍然需要知道自己是谁 |
| 格式约束(Thought/Action) | 规定输出格式 | 删除——API 保证格式 |
| Few-shot 示例 | 锚定格式 + 引导推理 | 可选——格式不需要了,但复杂推理场景仍然受益于示例 |
| 负面约束 | 防止暴露内部细节等 | 保留——跟格式无关的行为约束仍然需要 |
| 边界处理 | 超出范围如实告知等 | 保留——同上 |
简单说:跟怎么写相关的提示词可以删,跟怎么想和怎么回复相关的提示词要留。
文末总结
这一篇把 TinyAgent 从文本解析升级到了 Function Calling——直接改造 react 包里的 LlmClient 和 ReActAgent,让 ReAct 循环和 Function Calling 自然结合:
- 文本解析的天花板:
parseAction()依赖精确的文本格式、stop序列是个 hack、提示词被格式约束占据大量空间——三个硬伤本质上无法彻底解决。 - Function Calling 的核心:工具定义通过 API
tools参数传入,模型通过结构化的tool_calls返回工具调用,工具结果用tool角色消息回传——全程结构化,不经过文本解析。 - 代码变动:
ToolRegistry新增buildToolsJsonArray()生成 API 格式的工具定义;LlmClient新增chatWithTools()支持tools参数和tool_calls解析;ReActAgent用结构化响应驱动循环,删掉parseAction()/extractFinalAnswer()/stop序列。 - 新增两个 record:
ToolCallInfo(承载 tool_call 的 id、函数名、参数)和ChatResponse(承载 content、toolCalls、finishReason)。 - 不需要改的东西:
Tool接口、五个工具实现、BitMallAgentDemo入口——升级对它们完全透明。 - 效果:循环逻辑不变,推理链路不变,但参数格式稳定性从 95% 提升到 100%,系统提示词从 1300 字缩减到 200 字。
一句话收尾:文本 ReAct 是用提示词约定协议,Function Calling 是用 API 定义协议。前者靠大脑自觉,后者靠系统保证——工程上,能用系统保证的地方就不要靠自觉。
下一篇,咱们回到一个贯穿整个系列的问题——循环什么时候停?目前只有 MAX_STEPS 一个粗暴的兜底。如果大脑连续两圈调同一个工具拿同样的结果呢?如果 Token 用量已经快撑爆上下文了呢?如果用户只是问了句"你好"根本不需要调工具呢?**第 09 篇,咱们系统地解决终止条件问题:防死循环、防空转、防超预算。**我们下一篇见。