Prompt 是 Agent 的灵魂:ReAct 提示词设计
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们用 JSON Schema 升级了工具的参数定义,大脑传参的准确率从“大部分时候对”提升到了“绝大部分时候对”。工具的入参问题基本解决了,但如果你多跑几轮不同的场景,会发现另一类问题开始冒头——大脑偶尔跳过思考直接出手、输出格式时不时跑偏、最终回复里冒出工具名和 JSON 这种用户根本不该看到的东西。
这些问题的根源不在工具,而在提示词。
从第 05 篇到现在,buildSystemPrompt() 里的系统提示词只做过一处小改动(Action Input 的格式说明加了 JSON 要求),整体还是最初那个“够用但不完美的最小版”。这一篇,咱们把它升级成一个结构化的、带 Few-shot 示例的、有负面约束的完整版——让大脑不只是“能跑”,而是“稳定地跑”。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.2.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
先看翻车现场
提示词太简陋,大脑会怎么跑偏?咱们用比特严选的场景看三个真实案例。
1. 跳过 Thought 直接出手
用户说“帮我查一下订单 88231”,大脑的理想输出应该是先想再干:
Thought: 用户想查询订单 88231 的详情,我需要调用 queryOrder 工具。
Action: queryOrder
Action Input: {"orderId":"88231"}
但有些模型(特别是参数量较小或指令跟随能力偏弱的)会直接蹦出:
Action: queryOrder
Action Input: {"orderId":"88231"}
没有 Thought,直接出手。对于“查订单”这种简单场景,跳过思考好像也没什么问题——反正结果是对的。但到了退款这种需要多步判断的场景,问题就来了。大脑不写 Thought,就跳过了“先查订单、再看签收时间、再判断是否在退货期内”这些推理步骤,可能一上来就直接调 applyRefund,连订单状态都没确认就退款。
更重要的是,Thought 是你调试 Agent 的唯一窗口。大脑为什么调了这个工具而不是那个?为什么在第三圈突然决定给最终答复?没有 Thought,你只能看到一连串工具调用,根本不知道它在想什么,出了问题也无从下手。
2. 格式漂移
提示词里写了 Thought: / Action: / Action Input: 这三个标签,但有些模型会自作主张改格式:
思考:用户要查订单,我先看看订单信息。
操作:queryOrder
输入:{"orderId":"88231"}
中文标签、不同的冒号格式,甚至有时候大小写也不一致(action: 而不是 Action:)。咱们的 parseAction() 是按 Action: 和 Action Input: 这两个精确前缀来匹配的,换了标签就解析不出来。解析不出工具名,兜底逻辑把整段文字当最终答复返回——用户看到的是一段莫名其妙的内部推理过程。
3. 最终回复暴露内部细节
退款场景跑完四圈工具调用后,大脑给出 Final Answer:
Final Answer: 我通过调用 queryOrder 工具查询了您的订单 88231,返回的 JSON 数据
{"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,...} 显示订单已签收。
接着我调用 searchKnowledge 工具检索了退货政策,JSON 返回结果表明七天无理由退货...
最后通过 applyRefund 工具提交了退款申请,参数为 {"orderId":"88231","reason":"质量问题"}...
大脑把工具名、JSON 数据、参数细节全暴露给了用户。用户看到这种回复,第一反应不是“问题解决了”,而是“这什么东西?”。你希望用户看到的是“您的退款已提交,预计 1-3 个工作日到账”,而不是一堆 JSON。
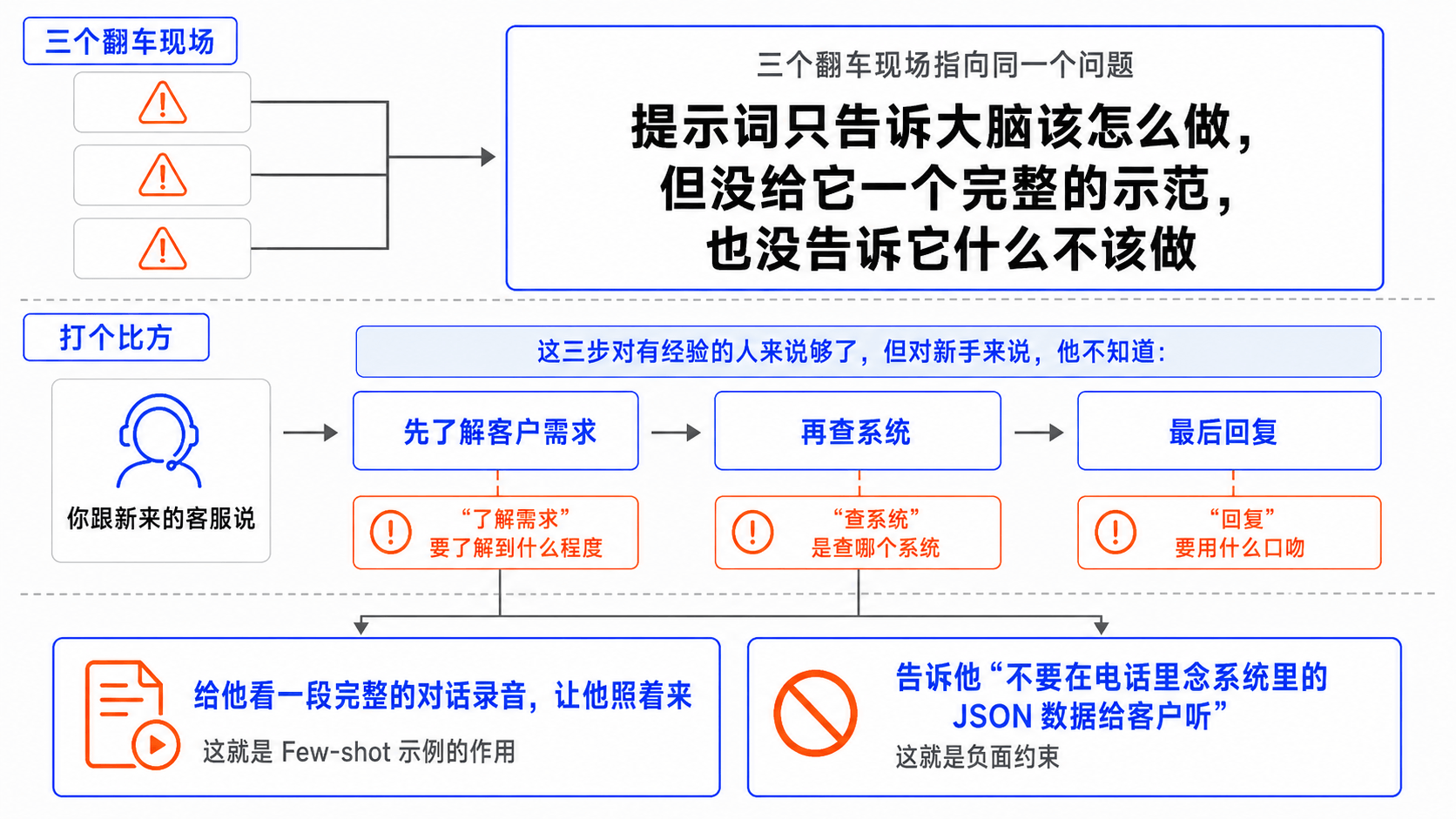
4. 三个翻车的共同根源
三个翻车现场指向同一个问题:提示词只告诉大脑该怎么做,但没给它一个完整的示范,也没告诉它什么不该做。
打个比方,你跟新来的客服说“先了解客户需求,再查系统,最后回复”。这三步对有经验的人来说够了,但对新手来说,他不知道“了解需求”要了解到什么程度、“查系统”是查哪个系统、“回复”要用什么口吻。你得给他看一段完整的对话录音,让他照着来——这就是 Few-shot 示例的作用。你还得告诉他“不要在电话里念系统里的 JSON 数据给客户听”——这就是负面约束。
把当前提示词拆开看
在动手改之前,先把当前的提示词拆解一下,看看哪些地方撑不住。
你是比特严选的智能客服助手。你可以使用以下工具来帮助用户解决问题。
工具列表��:
{工具列表}
请严格按照以下格式思考和行动:
Thought: <你的思考过程,分析当前局面,决定下一步做什么>
Action: <要调用的工具名,必须是工具列表中的一个>
Action Input: <传给工具的参数,必须严格按照工具的参数 Schema 输出 JSON 格式。如果工具无需参数,输出 {}>
工具执行后你会收到 Observation(工具返回的结果),然后继续下一轮思考。
重复上述过程,直到你收集到足够的信息来回答用户。
当你准备好给出最终答案时,使用以下格式:
Thought: <总结已有信息,说明为什么可以回答了>
Final Answer: <给用户的最终回复>
注意:
- 每次只调用一个工具
- 必须先 Thought 再 Action,不要跳过思考步骤
- Action 必须是工具列表中存在的工具名,不要编造工具
- Action Input 必须是合法 JSON,字段名和类型严格匹配工具的参数 Schema
逐块分析:
| 模块 | 现状 | 问题 |
|---|---|---|
| 身份定义 | 你是比特严选的智能客服助手 | 只有一句话,没说职责范围,不知道能管什么、不能管什么 |
| 工具列表 | 名称 + 描述 + 参数 Schema | 上一篇已经升级过,这部分没问题 |
| 格式说明 | Thought / Action / Action Input / Final Answer | 有了,但只是模板占位符,大脑没见过完整的填写示范 |
| 注意事项 | 四条规则 | 太少——没有禁止编造 Observation、没有边界情况处理、没有 Final Answer 的内容约束 |
| Few-shot 示例 | 无 | 最大的缺口,大脑只看到格式模板,没看到一个完整的从 Thought 到 Final Answer 的示范 |
缺口很明显:缺角色边界、缺示例、缺负面约束�、缺边界情况处理。
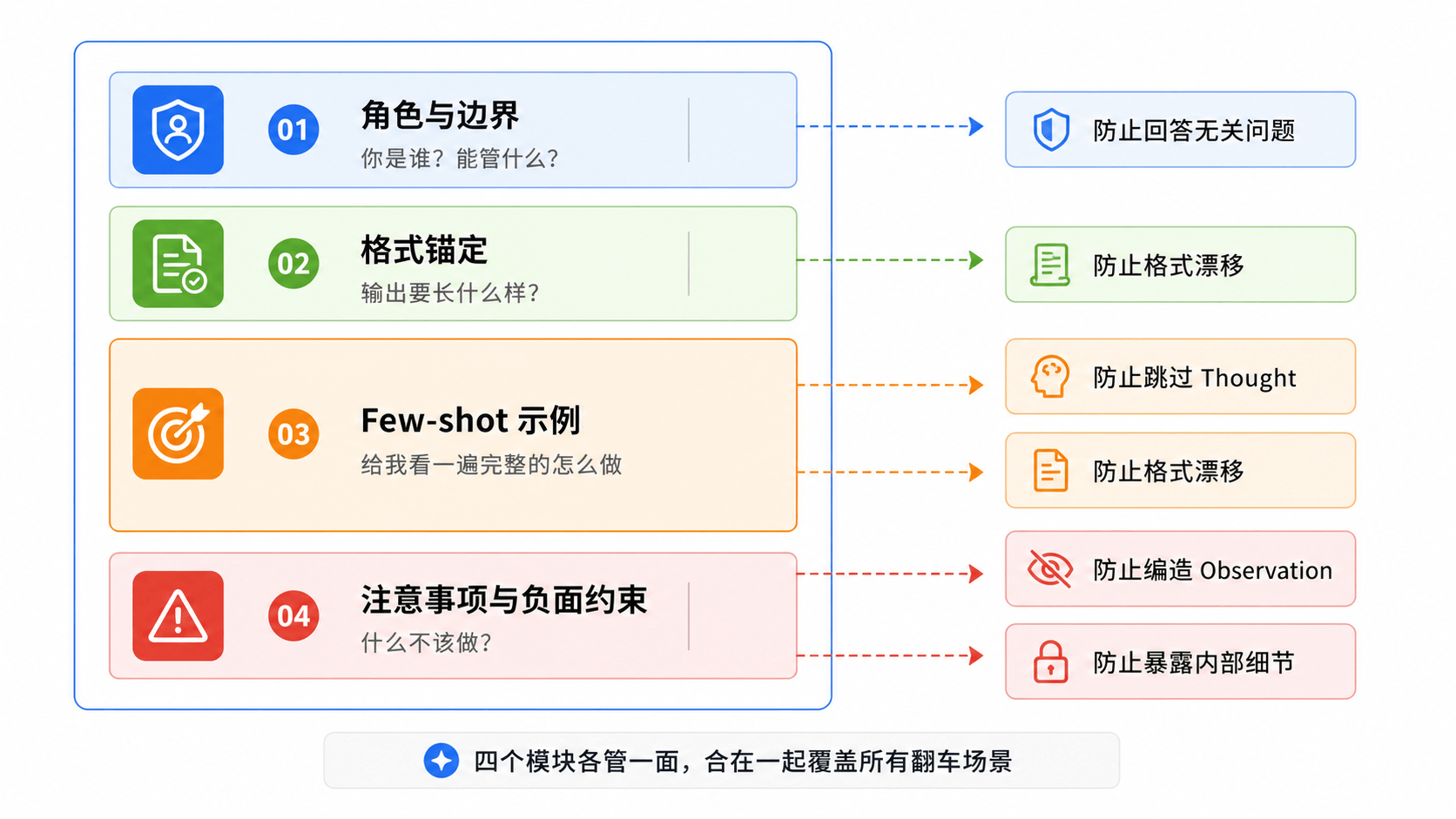
提示词的四个模块
一个稳定的 ReAct 提示词,由四个模块组成:
| 模块 | 回答的问题 | 解决的翻车 |
|---|---|---|
| 角色与边界 | 你是谁?能管什么?不能管什么? | 大脑回答与比特严选无关的问题 |
| 格式锚定 | 输出要长什么样? | 格式漂移、标签错乱 |
| Few-shot 示例 | 给我看一遍完整的怎么做 | 跳过 Thought、格式不稳定 |
| 注意事项 | 什么不该做?边界情况怎么处理? | 编造 Observation、暴露内部细节 |
多个模块各管一面,合在一起覆盖了前面三个翻车现场。用一张图来看它们之间的关系:
下面逐个展开。
模块一:角色与边界
1. 当前的问题
当前的角色定义是一句话:“你是比特严选的智能客服助手。你可以使用以下工具来帮助用户解决问题。”
这句话告诉大脑你是客服,但没说你的职责范围——你管商品咨询、订单查询、物流追踪、退款��换货,但不管帮用户写代码、聊天气、讲笑话。没有边界,大脑遇到超出范围的问题可能会硬凑一个答案,而不是告诉用户“这个我帮不了”。
2. 升级后
## 角色
你是比特严选的智能客服助手,负责帮助用户解决商品咨询、订单查询、物流追踪、退款换货等问题。
请根据用户的问题,合理选择工具获取真实信息,然后给出准确、友好的回复。
两行文字,做了三件事:
- 身份:比特严选的智能客服助手——不是通用助手,不是百科全书。
- 职责范围:商品咨询、订单查询、物流追踪、退款换货——明确列举能管的事。
- 行为准则:合理选择工具、获取真实信息、准确友好——告诉大脑怎么干活。
模块二:格式锚定
1. 当前的问题
当前的格式说明用了两段文字加尖括号占位符。问题在于,尖括号占位符只告诉大脑“这里填东西”,但大脑没见过填好之后长什么样。就像给你一张空白表格但不给你一份填好的样本——你知道每个格子要填什么类型的信息,但具体怎么写、写多长、什么语气,全靠猜。
2. 升级后
## 思考与行动格式
请严格按照以下格式交替进行思考和行动:
Thought: <分析当前局面,明确下一步要做什么以及为什么>
Action: <工具名,必须是上方工具列表中的一个>
Action Input: <严格按照工具的参数 Schema 输出 JSON。无参数的工具输出 {}>
系统会执行工具并返回 Observation(执行结果),然后你继续下一轮思考。
当你收集到足够信息可以回答用户时,使用以下格式结束:
Thought: <总结已有信息,说明为什么现在可以回答>
Final Answer: <给用户的最终回复,语气友好、内容完整>
变化不大,但有两处关键改进:
- Thought 的说明更具体:从“你的思考过程”改成“分析当前局面,明确下一步要做什么以及为什么”。加了“以及为什么”三个字,引导大脑不仅要说做什么,还要说为什么——这一步看似微小,但能显著减少“无脑调工具”的情况。
- Final Answer 加了内容要求:“语气友好、内容完整”——虽然具体的“不要暴露内部细节”放在注意事项里,但这里先锚定了最终回复的基本调性。
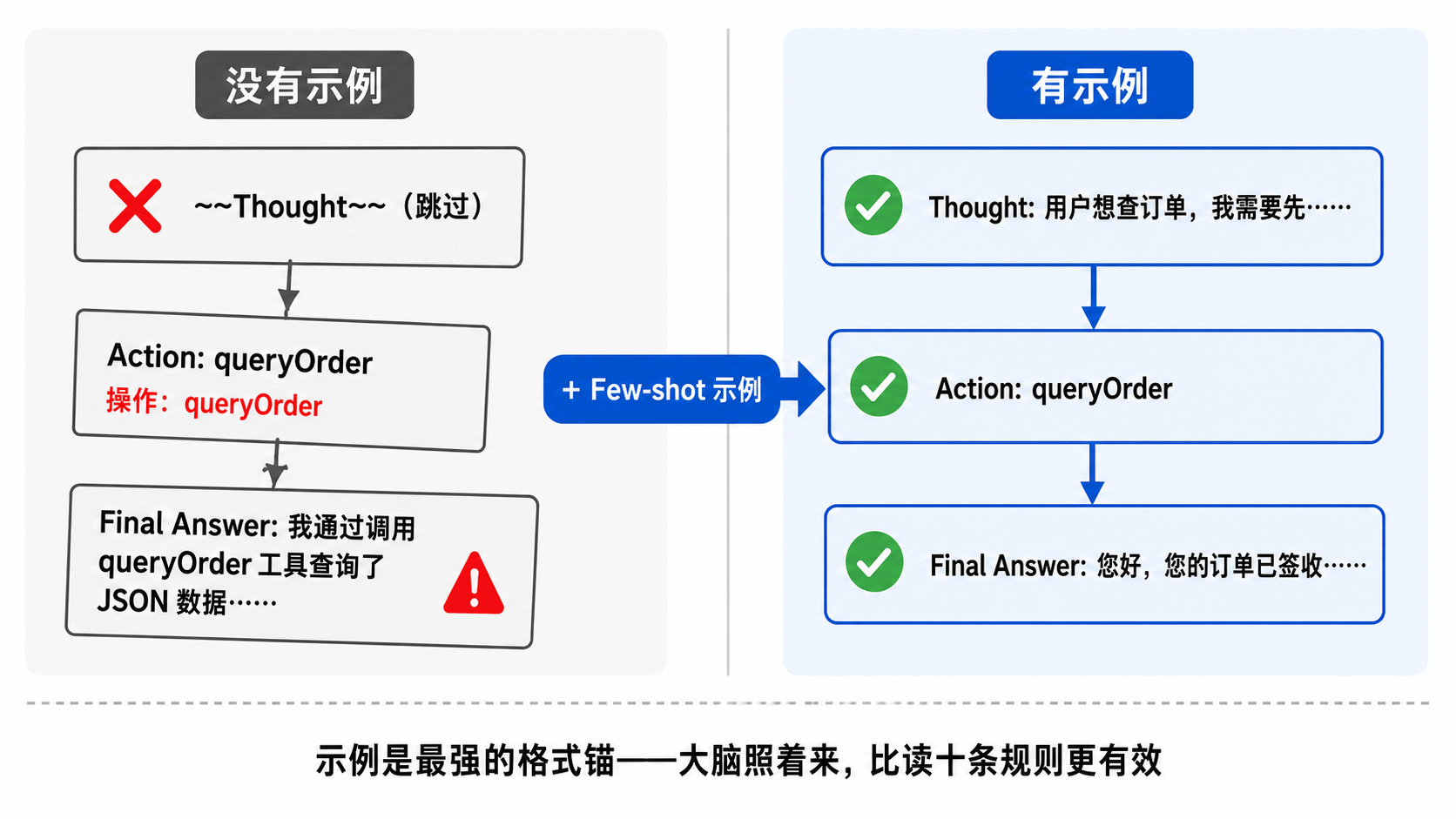
格式模板本身并不能完全解决格式漂移的问题。真正让大脑稳定输出的是下一个模块——Few-shot 示例。模板告诉大脑“应该长这样”,示例告诉大脑“就像这样”。
模块三:Few-shot 示例
这是本次升级最重�要的一个模块。
1. 为什么 Few-shot 管用
大模型本质上是一个模式匹配器——它看到什么样的输入,就倾向于输出什么样的格式。你在提示词里写十条格式规则,不如给它看一段完整的示范。
这就是 Few-shot(少样本学习)的核心思想:在提示词里放一个或几个完整的输入-输出示例,让模型照着来。在 ReAct 场景里,一个完整的示例意味着从用户提问开始,经过若干轮 Thought → Action → Action Input → Observation 循环,最后到 Final Answer 的完整过程。
举个直觉上的类比:你让新来的客服“按照流程处理退款”,他可能理解成各种样子。但你让他先旁听一通完整的退款电话——从接听到查询到回复到挂断——他立刻就知道每一步该说什么话、用什么语气、什么时候查系统。示例是最强的格式锚。
2. 选一个中等复杂度的场景
示例场景的选择有讲究。太简单(比如“获取当前时间”,一圈就结束)示范不出多步循环;太复杂(比如退款,四圈工具调用加政策判断)又会让提示词过长、消耗 Token。
查物流是个好选择——两步工具调用(先查订单拿运单号,再查物流),既展示了多轮循环,又展示了数据依�赖(第二步需要第一步的结果),复杂度刚好。
3. 完整的 Few-shot 示例
## 示例
用户:帮我查一下订单 88231 的物流到哪了。
Thought: 用户想查订单 88231 的物流信息。查物流需要运单号,我先通过 queryOrder 获取运单号。
Action: queryOrder
Action Input: {"orderId":"88231"}
Observation: {"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,
"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收",
"trackingNo":"SF1234567890"}
Thought: 拿到运单号 SF1234567890,接下来查物流轨迹。
Action: queryLogistics
Action Input: {"trackingNo":"SF1234567890"}
Observation: {"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收",
"traces":[{"time":"2026-06-20 18:20:00","desc":"快件已揽收"},
{"time":"2026-06-21 09:10:00","desc":"快件到达上海转运中心"},
{"time":"2026-06-22 11:35:00","desc":"快件已由本人签收"}]}
Thought: 已拿到完整物流信息,可以回答用户。
Final Answer: 您好,您的订单 88231(比特 S10 Pro 扫地机)的物流信息如下:
- 物流公司:顺丰速运
- 运单号:SF1234567890
- 当前状态:已签收
物流轨迹:
- 2026-06-20 18:20 快件已揽收
- 2026-06-21 09:10 快件到达上海转运中心
- 2026-06-22 11:35 快件已由本人签收
您的包裹已于 6 月 22 日签收。如有其他问题随时联系我!
这段示例一共两圈工具调用加一次 Final Answer,逐行拆解一下它教了大脑什么:
| 示范内容 | 大脑学到的 |
|---|---|
每一圈都以 Thought: 开头 | 必须先想再干,不能跳过 |
| Thought 里写了“为什么”(查物流需要运单号) | 推理要有因果,不是机械复述 |
Action Input 是标准 JSON | 参数格式不用猜,照着写 |
| Observation 是 JSON,不是大脑编的 | 工具结果由系统提供,自己不要编 |
| 第二圈用了第一圈的结果(运单号) | 数据依赖要从上一步结果中提取 |
| Final Answer 里没有工具名和 JSON | 最终回复面向用户,不暴露内部细节 |
| Final Answer 用了列表和友好语气 | 回复要有条理、语气亲切 |
一个示例,同时解决了前面三个翻车问题中的两个半——跳过 Thought(示例每圈都写了 Thought)、暴露内部细节(示例的 Final Answer 很干净)、格式漂移(示例用了标准的英文标签和冒号格式,大脑会模仿这个格式)。
4. Few-shot 示例的设计原则
写好一个 Few-shot 示例不难,但有几个原则需要注意:
选中等复杂度场景。太简单示范不出多步循环,太复杂消耗 Token。两到三步工具调用的场景最合适。
示例必须完整。从 Thought 到 Action 到 Observation 到 Final Answer,一步都不能少。少了 Observation,大脑不知道工具结果应该被谁提供(可能自己编一个);少了最后一个 Thought(总结),大脑可能在最后一步也跳过思考。
示例的数据要跟工具匹配。示例里的订单号、运单号、返回结果要跟实际工具的 Mock 数据或真实数据格式一致。如果示例里用了 orderId: "12345" 但工具的 Schema 里示例写的是“如 88231”,大脑反而会困惑。
一个示例通常够了。多个示例确实能提升稳定性,但也会大幅增加提示词长度。在比特严选这个场景里,一个涵盖多步调用的示例已经足够锚定格式。如果你发现某种特��定场景大脑反复跑偏,再加一个针对性的示例。
示例场景不要和测试场景完全一样。如果示例用退款场景,测试也用退款场景,大脑可能直接复制示例的回答而不是真的去调工具推理。选一个不同但结构相似的场景做示例,能更好地检验大脑是不是真的学会了模式。
模块四:注意事项与负面约束
1. 当前的问题
当前只有四条注意事项:每次只调一个工具、先 Thought 再 Action、不编造工具、JSON 格式匹配 Schema。这四条都是对的,但覆盖面太窄——翻车现场里的“编造 Observation”和“暴露内部细节”两个问题完全没提到。
2. 升级后
## 注意事项
- 每次只调用一个工具,等拿到 Observation 后再决定下一步
- 必须先写 Thought 再写 Action,不要跳过思考步骤
- Action 必须是工具列表中存在的工具名,不要编造不存在的工具
- Action Input 必须是合法 JSON,字段名和类型严格匹配工具的参数 Schema
- 不要自己编造 Observation,必须等系统返回真实结果
- 如果工具返回错误,在 Thought 中分析原因并尝试换一种方式解决
- 如果用户的问题超出工具能力范围,直接用 Final Answer 如实告知
- Final Answer 面向用户,不要暴露工具名、JSON、参数 Schema 等内部细节
从四条扩展到了八条,新增的四条分为两类:
负面约束(什么不该做):
| 约束 | 解决的问题 |
|---|---|
| 不要自己编造 Observation | 防止大脑自问自答,保证工具结果是真实的 |
| Final Answer 不暴露内部细节 | 防止用户看到工具名、JSON 数据等技术细节 |
边界情况处理(遇到特殊情况怎么办):
| 情况 | 指引 |
|---|---|
| 工具返回错误 | 在 Thought 里分析原因,尝试换一种方式,而不是把错误直接甩给用户 |
| 超出工具能力范围 | 直接告知用户,不要硬凑答案 |
负面约束特别重要,因为大模型有个特点:你不告诉它什么不该做,它就不知道那是不该做的。你觉得“不要编造工具结果”是常识?大模型没有常识,它只有概率。如果提示词里没有明确禁止,在某些上下文下它就是会编一个 Observation 接着往下走。
代码实战:升级 buildSystemPrompt()
四个模块讲完了,现在把它们拼到代码里。变动只在 ReActAgent 的 buildSystemPrompt() 方法:
private String buildSystemPrompt() {
return """
## 角色
你是比特严选的智能客服助手,负责帮助用户解决商品咨询、订单查询、物流追踪、退款换货等问题。
请根据用户的问题,合理选择工具获取真实信息,然后给出准确、友好的回复。
## 可用工具
%s
## 思考与行动格式
请严格按照以下格式交替进行思考和行动:
Thought: <分析当前局面,明确下一步要做什��么以及为什么>
Action: <工具名,必须是上方工具列表中的一个>
Action Input: <严格按照工具的参数 Schema 输出 JSON。无参数的工具输出 {}>
系统会执行工具并返回 Observation(执行结果),然后你继续下一轮思考。
当你收集到足够信息可以回答用户时,使用以下格式结束:
Thought: <总结已有信息,说明为什么现在可以回答>
Final Answer: <给用户的最终回复,语气友好、内容完整>
## 示例
用户:帮我查一下订单 88231 的物流到哪了。
Thought: 用户想查订单 88231 的物流信息。查物流需要运单号,我先通过 queryOrder 获取运单号。
Action: queryOrder
Action Input: {"orderId":"88231"}
Observation: {"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,"orderTime":"2026-06-20","signTime":"2026-06-22","status":"已签收","trackingNo":"SF1234567890"}
Thought: 拿到运单号 SF1234567890,接下来查物流轨迹。
Action: queryLogistics
Action Input: {"trackingNo":"SF1234567890"}
Observation: {"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收","traces":[{"time":"2026-06-20 18:20:00","desc":"快件已揽收"},{"time":"2026-06-21 09:10:00","desc":"快件到达上海转运中心"},{"time":"2026-06-22 11:35:00","desc":"快件已由本人签收"}]}
Thought: 已拿到完整物流信息,可以回答用户。
Final Answer: 您好,您的订单 88231(比特 S10 Pro 扫地机)的物流信息如下:
- 物流公司:顺丰速运
- 运单号:SF1234567890
- 当前状态:已签收
物流轨迹:
- 2026-06-20 18:20 快件已揽收
- 2026-06-21 09:10 快件到达上海转运中心
- 2026-06-22 11:35 快件已由本人签收
您的包裹已于 6 月 22 日签收。如有其他问题随时联系我!
## 注意事项
- 每次只调用一个工具,等拿到 Observation 后再决定下一步
- 必须先写 Thought 再写 Action,不要跳过思考步骤
- Action 必须是工具列表中存在的工具名,不要编造不存在的工具
- Action Input 必须是合法 JSON,字段名和类型严格匹配工具的参数 Schema
- 不要自己编造 Observation,必须等系统返回真实结果
- 如果工具返回错误,在 Thought 中分析原因并尝试换一种方式解决
- 如果用户的问题超出工具能力范围,直接用 Final Answer 如实告知
- Final Answer 面向用户,不要暴露工具名、JSON、参数 Schema 等内部细节
""".formatted(toolRegistry.buildToolList());
}
跟上一篇的版本对比,改动全在提示词文本里,Java 代码的结构没变——还是一个 String.formatted() 把工具列表塞进去。但提示词从一段连续文本变成了四个结构清晰的模块,每个模块用 ## 标题分隔。
用
##标题来分隔提示词的各个模块,不只是为了好看。大模型在处理长文本时,结构化的标题能帮助它更好地理解每个部分的用途——“角色”部分说的是身份,“示例”部分说的是格式参考,“注意事项”说的是禁区。这比一长段连续文本的理解效果更好。
升级前后完整对比
1. 提示词结构对比
| 维度 | 升级前(第 05-06 篇) | 升级后(本篇) |
|---|---|---|
| 角色定义 | 一句话,无职责边界 | 明确身份、职责范围、行为准则 |
| 工具列表 | 有(上一篇已升级为 Schema 版) | 不变 |
| 格式说明 | 尖括号占位符,无示范 | 占位符 + 完整 Few-shot 示例 |
| Few-shot 示例 | 无 | 两步工具调用的查物流示例 |
| 注意事项 | 4 条,只有正面约束 | 8 条,正面约束 + 负面约束 + 边界处理 |
| 总长度 | 约 350 字 | 约 900 字 |
2. 跑退款场景看效果
用升级后的提示词跑同一个退款场景(我上周买的扫地机不回充了,修不好我想退。订单号 88231。),观察大脑的输出变化:
Thought 质量对比:
| 圈次 | 升级前的 Thought | 升级后的 Thought |
|---|---|---|
| 第 1 圈 | 用户想退订单,需要先查订单 | 用户想退订单 88231 的扫地机,说不回充且修不好。我需要先查订单详情,确认商品信息和签收时间,判断是否符合退货条件 |
| 第 2 圈 | 需要确认当前日期 | 订单已签收,签收日期是 6 月 22 日。要判断是否在退货期内,需要知道今天的日期 |
| 第 4 圈 | 可以退款 | 签收已超 7 天无理由期限,但用户反馈的是质量问题(不回充且维修无效),根据售后政策质量问题可以申请退款 |
升级后的 Thought 更详细,推理链更完整。大脑不再是机械地说“需要做 XX”,而是说明了为什么要做、当前已知什么信息、缺什么信息。
Final Answer 质量对比:
升级前的 Final Answer 偶尔会出现“我通过 queryOrder 查询了订单”“根据 JSON 数据显示”这类内部细节。升级后,Final Answer 里工具名和 JSON 数据不再出现,回复更像一个真正的客服在跟用户说话。
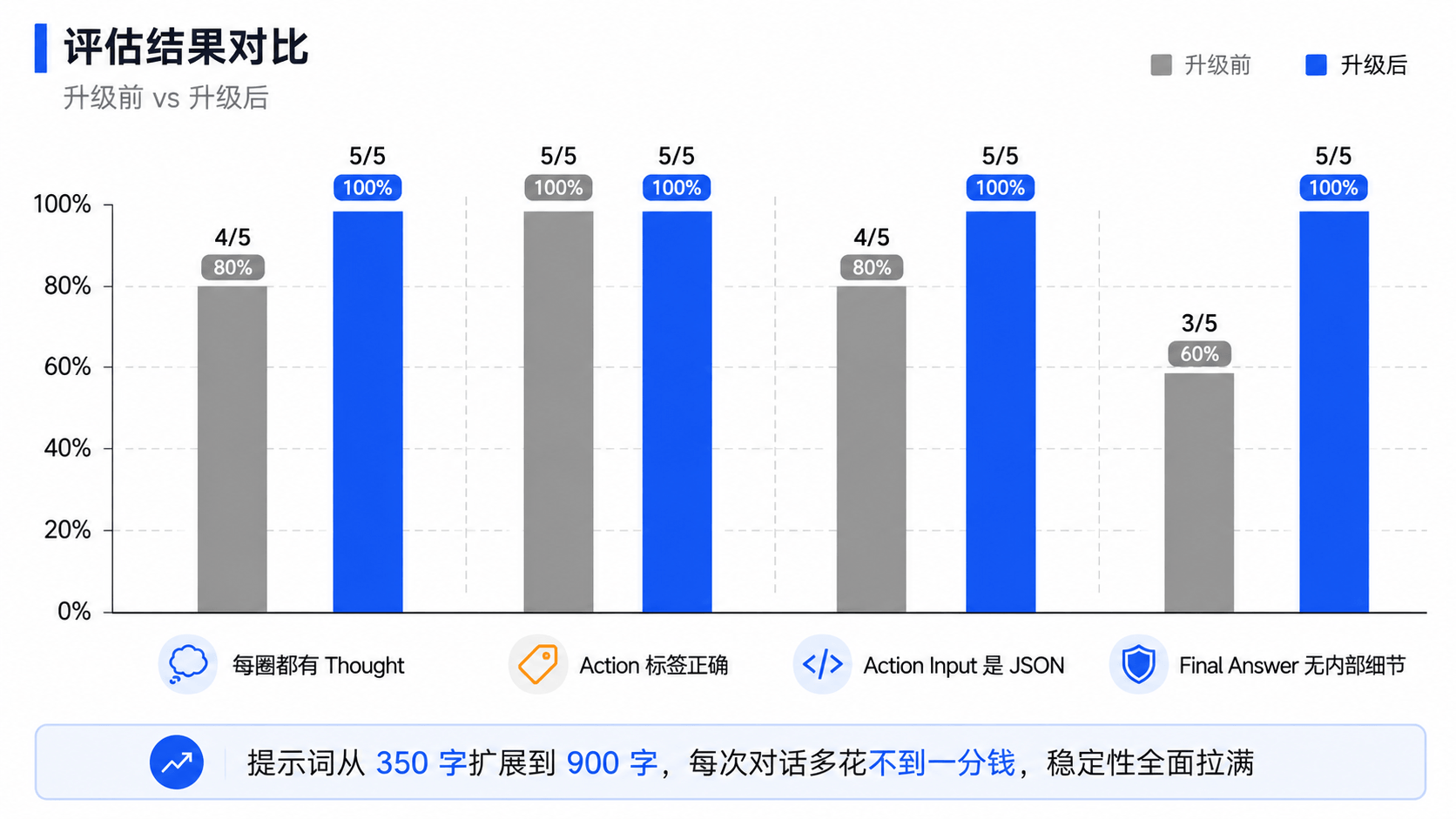
3. 稳定性提升
同一个退款场景跑五次,统计格式一致性:
| 指标 | 升级前(5 次) | 升级后(5 次) |
|---|---|---|
| 每圈都有 Thought | 4/5 | 5/5 |
| Action 标签正确 | 5/5 | 5/5 |
| Action Input 是 JSON | 4/5 | 5/5 |
| Final Answer 无内部细节 | 3/5 | 5/5 |
数据来自实际运行(使用 DeepSeek V4 Pro 模型,temperature=0.1),不同模型的结果可能有差异,但趋势一致:加了 Few-shot 示例和负面约束后,格式稳定性显著提升。
提示词 Token 成本:值不值
你可能注意到了——提示词从 350 字涨到了 900 字,多出来的主要是 Few-shot 示例那一段。这些多出来的文字都要消耗 Token,而且是每次调用都会消耗(系统提示词在每一圈循环里都会发给模型)。
值不值?算一笔账:
- 升级后的提示词大约 900 个中文字 + 工具列表(约 400 字),总计约 1300 字,折合约 1000 个 Token。
- 以通义千问为例,输入价格大约 2 元 / 百万 Token,1000 Token 约 0.002 元。
- 退款场景跑五圈,�系统提示词被发送五次,总计 5000 Token,约 0.01 元。
每次对话多花一分钱,换来的是格式稳定性从 60% 提升到 95%+。不稳定的格式意味着解析失败、重试、用户等待——这些隐性成本远高于几分钱的 Token 费用。
如果你确实对 Token 成本敏感(比如每天几十万次调用),有两个优化方向:一是用更短的示例(一步工具调用而不是两步);二是用模型厂商的提示词缓存(Prompt Caching)功能,系统提示词只在第一次请求时计费,后续请求复用缓存。但在学习和开发阶段,不要为了省 Token 而牺牲稳定性。
提示词调试的实战经验
跑了足够多的场景之后,你会积累出一些提示词调试的经验。提前总结几条:
1. 改一处测一次
提示词的修改效果不是线性叠加的。你一口气改了五个地方,跑出来效果变好了——你不知道是哪个改动起了作用,也不知道有没有哪个改动反而起了副作用。每次只改一处,跑同一个场景三次,确认效果后再改下一处。
2. 同一个场景跑多次看稳定性
大模型的输出是概率性的,即�使 temperature=0.1,同一个输入也可能产生不同的输出。跑一次恰好格式正确不代表提示词没问题——可能只是运气好。同一个场景至少跑三次,三次都稳定才算过关。
3. 不同模型需要微调
同一份提示词在不同模型上的表现可能差异很大。DeepSeek V4 Pro 对 Thought: / Action: 这套格式跟随得很好,但换一个模型可能需要加更多约束或更多示例。特别是模型大小差异明显的场景——70B 参数的模型可能一个示例就够了,7B 的可能需要两三个示例才能稳定。
4. 越短越好,但该有的不能省
长提示词消耗更多 Token,也可能让模型“信息过载”——关键指令被淹没在大段文字里反而被忽略。原则是在保证稳定性的前提下,尽量精简。具体来说:
- 角色定义:两三句话就够,不用写一大段角色扮演背景故事。
- 格式说明:模板 + 示例,不用反复解释每个标签的含义。
- 注意事项:只写大脑真的会犯的错误,不用写常识性的规则。
5. 提示词放在 system 角色里
Chat API 的消息有三种角色:system、user、assistant。提示词应该放在 system 角色的消息里,而不是拼到第一条 user 消息里。原因有两个:
- 语义正确:
system角色就是用来定义 Agent 的行为规范的,模型对system消息的指令跟随度更高。 - 位置稳定:
system消息始终在消息列表的最前面,不会被后续的多轮对话挤出模型的注意力窗口。
咱们的代码里已经是这么做的——messages.add(Map.of("role", "system", "content", buildSystemPrompt())) 就是把提示词放在 system 角色里。
虽然最新 OpenAI 的系统角色类型改成了 developer,但是目前看,绝大部分国内厂商还都适配 system,所以文中也就没有改动。
和原生 Function Call 提示词的区别
上一篇末尾提到过,原生 Function Call 方案不需要在提示词里写 Thought: / Action: 格式约束,也不需要 Few-shot 示例来锚定格式——模型 API 端保证输出结构化的 tool_calls JSON。那是不是意味着用原生 Function Call 就不需要打磨提示词了?
不是。即使用原生 Function Call,你仍然需要:
| 模块 | 文本 ReAct 提示词 | 原生 Function Call 提示词 |
|---|---|---|
| 角色与边界 | 需要 | 同样需要——大脑仍然要知道自己是谁、能管什么 |
| 格式锚定 | 需要(Thought/Action 格式) | 不需要——API 保证输出格式 |
| Few-shot 示例 | 需要 | 可选——格式已由 API 保证,但复杂推理场景仍然受益于示例 |
| 注意事项 | 需要 | 同样需要——“不要暴露内部细节”“超出范围如实告知”这些跟格式无关 |
文本 ReAct 提示词要管两件事:怎么想和怎么写。原生 Function Call 只需要管怎么想——怎么写的部分由 API 接管了。但“怎么想”恰恰是提示词里最有价值的部分。
文末总结
这一篇把系统提示词从最小版升级到了结构化的完整版:
- 翻车根源:提示词只有格式模板没有示例,缺少负面约束和边界处理,导致大脑跳过思考、格式漂移、暴露内部细节。
- 四个模块:角色与边界(你是谁)、格式锚定(怎么写)、Few-shot 示例(照着来)、注意事项(什么不该做)。
- 核心武器是 Few-shot 示例:一个完整的多步工具调用示例,同时锚定了格式、推理风格和回复调性。比十条文字规则更有效。
- 负面约束不可少:不编造 Observation、不暴露内部细节、超出能力范围如实告知——你不说,大脑就不知道。
- 代码改动只在
buildSystemPrompt():Java 代码结构不变,提示词从 350 字扩展到 900 字,用 Markdown 标题分成四个模块。 - 稳定性显著提升:同一场景多次运行,格式一致性和回复质量都明显提高,每次对��话多花不到一分钱。
一句话收尾:提示词是 Agent 的灵魂——格式模板定骨架,Few-shot 示例定肌肉,负面约束定边界。三样东西配齐,大脑才能稳定地想、稳定地干、稳定地给出用户满意的答复。
下一篇咱们换个思路——前面几篇一直在跟文本解析较劲:按行扫描、前缀匹配、多行 JSON 拼接……费了不少力气,但大模型输出稍有偏差就可能崩。有没有办法让模型直接返回结构化的工具调用,彻底绕开文本解析?有,这就是 Function Calling。**第 08 篇,咱们把 TinyAgent 从正则解析升级到 Function Calling,扔掉 parseAction(),让模型原生返回结构化调用。**我们下一篇见。