会话记忆持久化:用数据库存住每一轮对话
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们实现了三种记忆管理策略——滑动窗口、摘要压缩、混合策略——让 Agent 在同一个会话里能在有限的 Token 预算内保留最有用的信息。记忆管理的问题解决了,但还有一个更基础的问题没有碰过:
所有记忆都存在 JVM 内存里。
这会带来几个问题:
- 进程一重启,记忆就没了。 你跑 Demo 的时候可能没感觉,但真要上线,服务一重启,所有用户的对话历史就清零了。
- 没有用户和会话的概念。 现在的
InMemoryChatMemory就是一个裸的ArrayList,如果两个用户同时用同一个 Agent 实例,消息会混在一起——用户 A 的退款记录被用户 B 看到。 - 没法回看历史。 用户关掉客服窗口再打开,之前聊过的内容就找不到了,更别说像 ChatGPT 侧边栏那样展示历史会话列表。
这三个问题的根源都是一样的:记忆没有持久化,也没有隔离。
这一篇,咱们用 PostgreSQL 把记忆写进数据库,同时引入用户和会话两个维度的隔离,让记忆在重启后依然存在、在多实例间共享、在不同用户之间隔离。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.7.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
环境准备:启动 PostgreSQL
这一篇需要用到 PostgreSQL 数据库。如果你本地已经安装了 PostgreSQL 并且能正常使用,跳过本节即可。
最快的方式是用 Docker 一行命令启动。这里使用 pgvector/pgvector:pg16 镜像——它在官方 PostgreSQL 16 的基础上预装了 pgvector 扩展,后续做长期记忆的向量检索时会用到,提前装好省得以后再折腾:
docker run -d \
--name postgres \
-e POSTGRES_DB=tinyagent \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres \
-p 5432:5432 \
-v pgdata:/var/lib/postgresql/data \
pgvector/pgvector:pg16
各参数说明:
| 参数 | 说明 |
|---|---|
-d | 后台运行,不占终端 |
--name postgres | 容器名称,方便后续 docker stop postgres 管理 |
-e POSTGRES_DB=tinyagent | 自动创建名为 tinyagent 的数据库 |
-e POSTGRES_USER=postgres | 数据库用户名 |
-e POSTGRES_PASSWORD=postgres | 数据库密码 |
-p 5432:5432 | 将容器的 5432 端口映射到宿主机,本地程序直接连 localhost:5432 |
-v pgdata:/var/lib/postgresql/data | 数据持久化到 Docker 卷,容器删了数据还在 |
启动后,验证一下能不能连上:
docker exec -it postgres psql -U postgres -d tinyagent -c "SELECT 1"
看到返回结果就说明 PostgreSQL 已经就绪了。
如果你不熟悉 Docker,也可以直接在本地安装 PostgreSQL。macOS 用
brew install postgresql@16,Windows 去官网下安装包,装完后手动创建tinyagent数据库即可。连接参数(地址、端口、用户名、密码)配到项目根目录的.env文件里。
用户与会话:两级隔离模型
在做持久化之前,先把数据模型想清楚。
一个客服系统里,记忆的隔离至少需要两个维度:
- 用户(User):每个用户有自己独立的记忆空间,A 用户的对话历史不能被 B 用户看到。
- 会话(Session):同一个用户可以有多个会话——今天聊退款是一个会话,明天聊推荐是另一个会话。每个会话有自己独立的对话历史。
打个比方:用户就像医院的病人,会话就像每次的就诊记录。张三今天看感冒是一份病历,下周看胃病是另一份病历。两份病历都属于张三,但内容是独立的。李四的病历跟张三完全隔离。
用户 A (user_10086)
├── 会话 1 (2026-06-29):查物流 → 退款
├── 会话 2 (2026-06-30):推荐新款扫地机
└── 会话 3 (2026-07-01):问促销活动
用户 B (user_10010)
├── 会话 1 (2026-07-01):咨询智能音箱
└── 会话 2 (2026-07-02):下单 + 查物流
用 Java 来描述会话的元数据:
public record ChatSession(
String sessionId,
String userId,
String title,
LocalDateTime createdAt,
LocalDateTime updatedAt
) {}
sessionId:会话的唯一标识,用 UUID 生成。userId:所属用户,用于隔离。title:会话标题,可以从第一轮对话中自动生成(后面会讲)。createdAt/updatedAt:创建和最后更新时间,用于排序和过期清理。
PostgreSQL 表设计
两张表:chat_session 存会话元数据,chat_message 存消息明�细。
CREATE TABLE IF NOT EXISTS chat_session (
session_id VARCHAR(64) PRIMARY KEY,
user_id VARCHAR(64) NOT NULL,
title VARCHAR(256),
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX IF NOT EXISTS idx_chat_session_user_id ON chat_session(user_id);
CREATE TABLE IF NOT EXISTS chat_message (
id BIGSERIAL PRIMARY KEY,
session_id VARCHAR(64) NOT NULL,
role VARCHAR(16) NOT NULL,
content TEXT,
tool_call_id VARCHAR(64),
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX IF NOT EXISTS idx_chat_message_session_id ON chat_message(session_id);
几个设计要点:
chat_message 的主键用自增 BIGSERIAL:消息需要按插入顺序排列(对话是有序的),自增 ID 天然保证顺序,查询时 ORDER BY id ASC 就能还原对话流。
role 用 VARCHAR(16) 而不是枚举:虽然当前只有 USER、ASSISTANT、SYSTEM、TOOL 四种角色,但 VARCHAR 更灵活,后续加新角色不需要改表结构。
content 用 TEXT 而不是 VARCHAR:Agent 的回复可能很长(包含商品对比表格、故障诊断步骤等),TEXT 没有长度限制。
chat_session 上的 user_id 索引:查询用户的会话列表是高频操作(类似 ChatGPT 侧边栏的历史记录),需要索引加速。
chat_message 上的 session_id 索引:加载某个会话的所有消息是核心查询,必须有索引。
你可能注意到
chat_message没有加外键关联chat_session。这是有意为之——外键会在每次插入消息时额外检查会话是否存在,增加写入延迟。在应用层保证数据一致性就够了。
数据关系图如下所示:

JdbcChatMemory:让记忆写进数据库
1. 原理
核心思路非常直接:让 ChatMemory 接口的三个方法(add()、messages()、clear())对应到 SQL 的 INSERT、SELECT、DELETE。
add(message) → INSERT INTO chat_message ...
messages() → SELECT FROM chat_message WHERE session_id = ? ORDER BY id
clear() → DELETE FROM chat_message WHERE session_id = ?
每个 JdbcChatMemory 实例绑定一个 sessionId,所有操作都在这个会话范围内。不同会话的记忆天然隔离,因为 SQL 的 WHERE 条件保证了只能读写自己的消息。
2. 流程图示
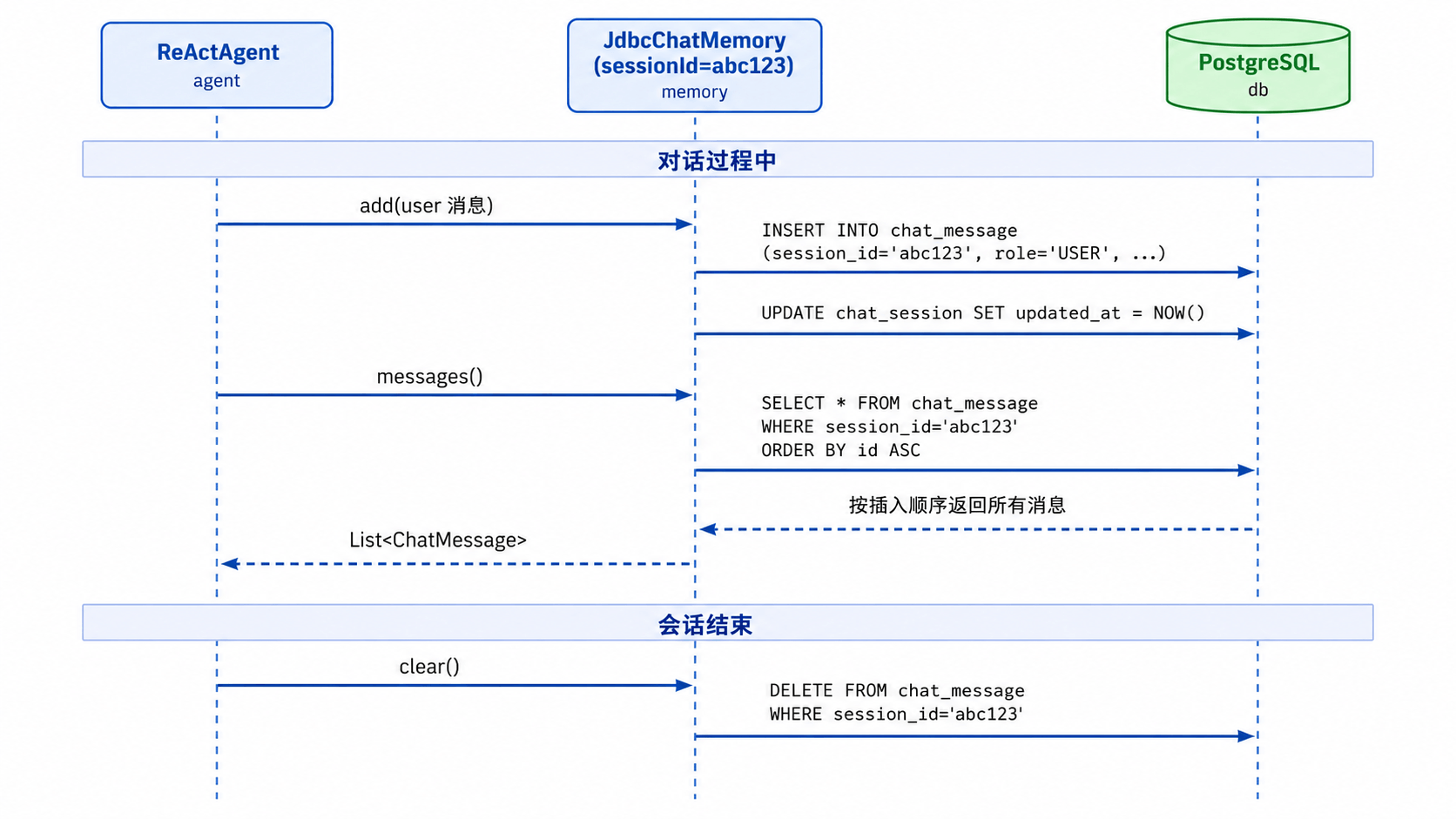
3. Java 实现
public class JdbcChatMemory implements ChatMemory {
private final DataSource dataSource;
private final String sessionId;
public JdbcChatMemory(DataSource dataSource, String sessionId) {
this.dataSource = dataSource;
this.sessionId = sessionId;
}
@Override
public void add(ChatMessage message) {
String sql = "INSERT INTO chat_message (session_id, role, content, tool_call_id) VALUES (?, ?, ?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, sessionId);
ps.setString(2, message.role().name());
ps.setString(3, message.content());
ps.setString(4, message.toolCallId());
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("写入消息失败", e);
}
String updateSql = "UPDATE chat_session SET updated_at = CURRENT_TIMESTAMP WHERE session_id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(updateSql)) {
ps.setString(1, sessionId);
ps.executeUpdate();
} catch (SQLException e) {
System.err.println("[警告] 更新会话时间失败:" + e.getMessage());
}
}
@Override
public List<ChatMessage> messages() {
String sql = "SELECT role, content, tool_call_id FROM chat_message "
+ "WHERE session_id = ? ORDER BY id ASC";
List<ChatMessage> result = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, sessionId);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
ChatMessage.Role role = ChatMessage.Role.valueOf(rs.getString("role"));
String content = rs.getString("content");
String toolCallId = rs.getString("tool_call_id");
result.add(new ChatMessage(role, content, toolCallId));
}
}
} catch (SQLException e) {
throw new RuntimeException("读取消息失败", e);
}
return Collections.unmodifiableList(result);
}
@Override
public void clear() {
String sql = "DELETE FROM chat_message WHERE session_id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, sessionId);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("清空消息失败", e);
}
}
public String getSessionId() {
return sessionId;
}
}
几个实现细节说一下:
add() 里做了两件事:先插入消息,再更新会话的 updated_at。更新会话时间是为了后续排序和过期清理——按 updated_at 降序,最近活跃的会话排在前面。更新时间失败不影响主流程,所以用 System.err 打个警告就行,不抛异常。
messages() 用 ORDER BY id ASC:这保证了消息按插入顺序返回,还原对话的时间线。如果用 created_at 排序,高并发下同一秒插入的多条消息可能顺序不对。
构造函数接收 DataSource:不是 Connection。每次操作自己从 DataSource 获取连接,用完立即关闭(try-with-resources)。这样做的好处是 JdbcChatMemory 实例可以被长期持有,不需要担心连接泄漏。生产环境给 DataSource 套上连接池(HikariCP、Druid)就行,JdbcChatMemory 不需要改动。
4. 跟 InMemoryChatMemory 的对比
| 维度 | InMemoryChatMemory | JdbcChatMemory |
|---|---|---|
| 存储介质 | JVM 堆内存 | PostgreSQL |
| 进程重启 | 数据丢失 | 数据保留 |
| 多实例部署 | 不共享,各存各的 | 共享同一个数据库 |
| 用户隔离 | 无,所有用户共用一个 List | 通过 sessionId 隔离 |
| 读写延迟 | 纳秒级(内存操作) | 毫秒级(网络 + 磁盘) |
| 实现复杂度 | 5 行代码 | 约 60 行代码 |
| 适用场景 | 开发调试、Demo 演示 | 生产环境 |
SessionManager:管理会话生命周期
有了 JdbcChatMemory 管单个会话的消息读写,还需要一个 SessionManager 来管理会话本身的生命周期——创建会话、列出历史会话、更新标题、过期清理。
public class SessionManager {
private final DataSource dataSource;
public SessionManager(DataSource dataSource) {
this.dataSource = dataSource;
}
public String createSession(String userId) {
String sessionId = UUID.randomUUID().toString().replace("-", "").substring(0, 16);
String sql = "INSERT INTO chat_session (session_id, user_id) VALUES (?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, sessionId);
ps.setString(2, userId);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("创建会话失败", e);
}
return sessionId;
}
public List<ChatSession> listSessions(String userId) {
String sql = "SELECT session_id, user_id, title, created_at, updated_at "
+ "FROM chat_session WHERE user_id = ? ORDER BY updated_at DESC";
List<ChatSession> sessions = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, userId);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
sessions.add(new ChatSession(
rs.getString("session_id"),
rs.getString("user_id"),
rs.getString("title"),
rs.getTimestamp("created_at").toLocalDateTime(),
rs.getTimestamp("updated_at").toLocalDateTime()
));
}
}
} catch (SQLException e) {
throw new RuntimeException("查询会话列表失败", e);
}
return sessions;
}
public void updateTitle(String sessionId, String title) {
String sql = "UPDATE chat_session SET title = ? WHERE session_id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, title);
ps.setString(2, sessionId);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("更新会话标题失败", e);
}
}
public void expireSessions(int maxAgeDays) {
String deleteMessages = "DELETE FROM chat_message WHERE session_id IN "
+ "(SELECT session_id FROM chat_session "
+ "WHERE updated_at < NOW() - INTERVAL '" + maxAgeDays + " days')";
String deleteSessions = "DELETE FROM chat_session "
+ "WHERE updated_at < NOW() - INTERVAL '" + maxAgeDays + " days'";
try (Connection conn = dataSource.getConnection()) {
try (PreparedStatement ps = conn.prepareStatement(deleteMessages)) {
ps.executeUpdate();
}
try (PreparedStatement ps = conn.prepareStatement(deleteSessions)) {
int deleted = ps.executeUpdate();
if (deleted > 0) {
System.out.println("[清理] 已删除 " + deleted + " 个过期会话");
}
}
} catch (SQLException e) {
throw new RuntimeException("清理过期会话失败", e);
}
}
}
四个方法各司其职:
createSession():生成一个 16 位的 sessionId(UUID 去掉短横线后截取),插入 chat_session 表。标题先留空,后面可以自动生成。
listSessions():按 updated_at 降序查某个用户的所有会话——最近活跃的排前面。这就是 ChatGPT 侧边栏历史对话的后端逻辑。
updateTitle():给会话设置一个标题。标题可以手动设,也可以在第一轮对话结束后让大模型自动生成(后面会讲)。
expireSessions():清理超过 N 天没有活跃的会话。先删消息再删会话,顺序不能反(否则消息变成孤儿数据)。这个方法适合放在定时任务里跑,比如每天凌晨清理一次超过 90 天的历史会话。
会话标题自动生成
会话创建时标题是空的,第一轮对话结束后可以让大模型自动生成一个简短的标题——就像 ChatGPT 和 DeepSeek 对话列表里那样。
public class SessionTitleGenerator {
private final LlmClient llmClient;
public SessionTitleGenerator(LlmClient llmClient) {
this.llmClient = llmClient;
}
public String generate(String userMessage, String assistantReply) {
ObjectMapper objectMapper = llmClient.getObjectMapper();
ArrayNode messages = objectMapper.createArrayNode();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content",
"请根据以下用户问题和客服回复,生成一个简短的会话标题(10 字以内)。"
+ "只输出标题文字,不要加任何标点或解释。");
ObjectNode userMsg = messages.addObject();
userMsg.put("role", "user");
userMsg.put("content", "用户:" + userMessage + "\n客服:" + assistantReply);
ChatResponse response = llmClient.chatWithTools(messages, objectMapper.createArrayNode());
String title = response.content();
if (title != null) {
title = title.strip();
if (title.length() > 20) {
title = title.substring(0, 20);
}
}
return title;
}
}
使用方式——第一轮对话结束后调一次:
String sessionId = sessionManager.createSession(userId);
ChatMemory memory = new JdbcChatMemory(dataSource, sessionId);
ReActAgent agent = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory);
String answer = agent.run("帮我查一下订单 88231 的物流到哪了");
// 第一轮结束后自动生成标题
SessionTitleGenerator titleGen = new SessionTitleGenerator(llmClient);
String title = titleGen.generate("帮我查一下订单 88231 的物流到哪了", answer);
sessionManager.updateTitle(sessionId, title);
// 标题可能是:"查询订单物流"
自动标题生成会额外调一次大模型,但输入输出都很短(几十个 Token),延迟和成本可以忽略。如果你不想要额外的 LLM 调用,也可以用简单规则:截取用户第一句话的前 15 个字做标题。
与记忆策略的组合
上一篇实现的三种记忆策略(滑动窗口、摘要压缩、混合策略)是在内存里管理消息列表的。JdbcChatMemory 做的是持久化。两者解决的是不同层次的问题,可以组合使用。
组合的思路是持久化层存完整历史,应用层按策略裁剪后注入 Agent:
┌──────────────┐
│ PostgreSQL │ ← 存完整历史(50 条消息)
└──────┬───────┘
│ SELECT all
▼
┌──────────────┐
│ 记忆策略裁剪 │ ← 滑动窗口 / 摘要压缩 / 混合
└──────┬───────┘
│ 裁剪后(10 条消息 + 1 条摘要)
▼
┌──────────────┐
│ ReActAgent │ ← 只看到裁剪后的记忆
└──────────────┘
在当前的 TinyAgent 架构里,记忆策略和持久化是两个独立的 ChatMemory 实现。要组合使用,用一个 PersistentHybridChatMemory 把两者包在一起:
public class PersistentHybridChatMemory implements ChatMemory {
private final JdbcChatMemory persistence;
private final HybridChatMemory compression;
public PersistentHybridChatMemory(DataSource dataSource, String sessionId,
LlmClient llmClient, int recentSize, int summaryThreshold) {
this.persistence = new JdbcChatMemory(dataSource, sessionId);
this.compression = new HybridChatMemory(llmClient, recentSize, summaryThreshold);
for (ChatMessage msg : persistence.messages()) {
compression.add(msg);
}
}
@Override
public void add(ChatMessage message) {
persistence.add(message);
compression.add(message);
}
@Override
public List<ChatMessage> messages() {
return compression.messages();
}
@Override
public void clear() {
persistence.clear();
compression.clear();
}
}
职责分离:persistence 管持久化(数据库存完整历史),compression 管 Token 压缩(摘要 + 最近 N 条)。add() 写两边,messages() 只返回压缩视图。构造时从数据库加载历史消息,灌入压缩引擎重建状态。
使用方式——跟之前一样传给 ReActAgent,对外还是一个 ChatMemory:
String sessionId = sessionManager.createSession(userId);
ChatMemory memory = new PersistentHybridChatMemory(dataSource, sessionId, llmClient, 6, 12);
ReActAgent agent = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory);
agent.run("帮我查一下订单 88231 的物流");
对于比特严选的场景,大部分客服会话在 5 轮以内,消息总量不超过 15 条。这个量级下,JdbcChatMemory 直接加载全量历史也够用。但如果你的业务有故障诊断、跨品类推荐等可能超过 10 轮的长会话,PersistentHybridChatMemory 就能在不丢数据的前提下自动控制 Token 消耗。
Demo:两个用户各自的会话
把所有模块串起来,模拟两个用户同时使用客服的场景:
public static void main(String[] args) {
// 初始化工具和 LLM(跟之前一样)
ToolRegistry toolRegistry = new ToolRegistry();
toolRegistry.register(new QueryOrderTool());
toolRegistry.register(new QueryLogisticsTool());
toolRegistry.register(new ApplyRefundTool());
toolRegistry.register(new SearchKnowledgeTool());
toolRegistry.register(new GetCurrentTimeTool());
Properties dotEnv = loadDotEnv();
LlmClient llmClient = new LlmClient(
setting(dotEnv, "TINYAGENT_API_URL", "..."),
requiredSetting(dotEnv, "TINYAGENT_API_KEY"),
setting(dotEnv, "TINYAGENT_MODEL", "deepseek-v4-pro")
);
// 创建数据源
PGSimpleDataSource ds = new PGSimpleDataSource();
ds.setUrl(setting(dotEnv, "TINYAGENT_DB_URL", "jdbc:postgresql://localhost:5432/tinyagent"));
ds.setUser(setting(dotEnv, "TINYAGENT_DB_USER", "postgres"));
ds.setPassword(setting(dotEnv, "TINYAGENT_DB_PASSWORD", "postgres"));
SessionManager sessionManager = new SessionManager(ds);
String userA = "user_10086";
String userB = "user_10010";
// ========== 用户 A 的会话 ==========
System.out.println("========== 用户 A 的会话 ==========");
String sessionA = sessionManager.createSession(userA);
ChatMemory memoryA = new JdbcChatMemory(ds, sessionA);
ReActAgent agentA = new ReActAgent(llmClient, toolRegistry, 10, 8000, memoryA);
String firstAnswer = agentA.run("帮我查一下订单 88231 的物流到哪了");
// 第一轮结束后自动生成会话标题
SessionTitleGenerator titleGen = new SessionTitleGenerator(llmClient);
String titleA = titleGen.generate("帮我查一下订单 88231 的物流到哪了", firstAnswer);
sessionManager.updateTitle(sessionA, titleA);
System.out.println("[会话标题] " + titleA);
agentA.run("那我要退款呢,这个扫地机不回充了");
// ========== 用户 B 的会话(完全隔离) ==========
System.out.println("\n\n========== 用户 B 的会话 ==========");
String sessionB = sessionManager.createSession(userB);
ChatMemory memoryB = new JdbcChatMemory(ds, sessionB);
ReActAgent agentB = new ReActAgent(llmClient, toolRegistry, 10, 8000, memoryB);
String firstAnswerB = agentB.run("有什么智能音箱推荐吗,500 以内的");
String titleB = titleGen.generate("有什么智能音箱推荐吗,500 以内的", firstAnswerB);
sessionManager.updateTitle(sessionB, titleB);
System.out.println("[会话标题] " + titleB);
// ========== 查看用户 A 的历史会话 ==========
System.out.println("\n\n========== 用户 A 的历史会话列表 ==========");
List<ChatSession> sessionsA = sessionManager.listSessions(userA);
for (ChatSession s : sessionsA) {
System.out.println("会话 " + s.sessionId()
+ " | 创建于 " + s.createdAt()
+ " | 标题:" + (s.title() != null ? s.title() : "(未命名)"));
}
// ========== 加载用户 A 的旧会话,记忆还在 ==========
System.out.println("\n\n========== 加载用户 A 的旧会话记忆 ==========");
ChatMemory reloadedMemory = new JdbcChatMemory(ds, sessionA);
List<ChatMessage> history = reloadedMemory.messages();
System.out.println("历史消息共 " + history.size() + " 条:");
for (ChatMessage msg : history) {
String preview = msg.content() != null && msg.content().length() > 80
? msg.content().substring(0, 80) + "..."
: msg.content();
System.out.println(" [" + msg.role() + "] " + preview);
}
}
预期行为:
- 用户 A 的会话:聊了 2 轮(查物流 + 退款),消息全部写入 PostgreSQL。
- 用户 B 的会话:聊了 1 轮(推荐智能音箱),跟用户 A 完全隔离——Agent B 不会看到用户 A 的退款记录。
- 查看历史会话:
listSessions(userA)只返回用户 A 的会话,不会返回用户 B 的。 - 加载旧会话:用同一个
sessionA新建一个JdbcChatMemory,messages()能完整返回之前聊过的所有消息——因为数据存在数据库里,不受内存生命周期影响。
工程注意事项
1. 连接池
Demo 里用的是 PGSimpleDataSource——每次 getConnection() 都创建一个新的物理连接,用完关闭。这在 Demo 里没问题,但生产环境必须换成连接池。
连接池的作用是维护一组预建好的数据库连接,应用需要时从池里借一个、用完归还,避免频繁创建和销毁连接的开销。常用的连接池有 HikariCP(Spring Boot 默认)。
// HikariCP 示例
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:postgresql://localhost:5432/tinyagent");
config.setUsername("postgres");
config.setPassword("postgres");
config.setMaximumPoolSize(10);
DataSource dataSource = new HikariDataSource(config);
// JdbcChatMemory 不需要任何修改——它只依赖 DataSource 接口
ChatMemory memory = new JdbcChatMemory(dataSource, sessionId);
2. 消息量的边界
JdbcChatMemory.messages() 每次都从数据库加载该会话的全部消息。如果一个会话聊了 100 轮(200 条消息),每次调 messages() 都要查 200 条数据。
对于比特严选这种大多数会话在 5 轮以内的场景,这完全不是问题。但如果你的业务有超长会话(比如技术支持聊了一下午),可以在 messages() 里加一个 LIMIT 只加载最近 N 条,或者结合上面提到的记忆策略做裁剪。
3. 过期清理策略
会话数据会持续增长,需要定期清理:
| 清理策略 | 建议值 | 说明 |
|---|---|---|
| 会话最大保留天数 | 90 天 | 超过 90 天未活跃的会话连同消息一起删除 |
| 清理频率 | 每天一次 | 放在凌晨低峰期执行 |
| 单次清理上限 | 1000 条 | 避免长事务锁表,分批删除 |
// 定时任务示例(每天凌晨 3 点执行)
sessionManager.expireSessions(90);
4. 跟 Redis 的分工
你可能会想:消息存 PostgreSQL 会不会太慢?
实际测算一下:一条 INSERT 操作在局域网内 PostgreSQL 上通常只需要 1-3 毫秒,一�条 SELECT 查 20 条消息约 2-5 毫秒。而 Agent 每圈循环调一次大模型 API 至少要 500-2000 毫秒。数据库的读写延迟相比大模型 API 调用,可以忽略不计。
如果你的场景确实对延迟极度敏感(比如每秒处理几千个并发会话),可以在 PostgreSQL 前面加一层 Redis 缓存:活跃会话的消息缓存在 Redis 里(读写都是亚毫秒),会话结束后异步落盘到 PostgreSQL。但对于比特严选这个体量(约 300-500 SKU 的自营商城),PostgreSQL 直连完全扛得住。
文末总结
这一篇从 InMemoryChatMemory 的三个致命问题(进程重启丢失、多实例不共享、用户无隔离)出发,用 PostgreSQL 实现了持久化的会话记忆:
- 两级隔离模型:
userId隔离用户,sessionId隔离会话。每个用户有自己独立的会话列表,每个会话有自己独立的消息历史。 - 表设计:
chat_session(会话元数据)+chat_message(消息明细)两张表,简单够用。 - JdbcChatMemory:实现
ChatMemory接口,三个方法对应三条 SQL。构造时绑定sessionId,所有操作都在会话范围内,天然隔离。 - SessionManager:管理会话的创建、列表查询、标题更新、过期清理。
- 会话标题自动生成:第一轮对话结束后让大模型生成一个简短标题,提升用户体验。
- 与记忆策略的组合:持久化层存完整历史,应用层按需裁剪。大部分短会话直接加载全量即可,长会话再叠加压缩策略。
用一句话概括:InMemoryChatMemory 解决了同一次会话内记住的问题,JdbcChatMemory 解决了跨重启、跨实例、跨用户也能记住的问题。
下一篇《长期记忆:跨会话记住用户》,咱们再往上走一层——不只是让 Agent 能加载某个会话的历史,而是让它能跨多个会话积累对用户的了解:偏好、画像、关键事实。这就需要从对话中提炼信息、用向量检索做语义匹配、按相关性筛选注入——从记住对话升级到记住用户。