上下文工程:每一个 Token 都花在刀刃上
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
前面四篇咱们一步一步给 TinyAgent 搭建了完整的记忆体系——短期记忆让 Agent 在同一个会话里记住上下文(第 10、11 篇),持久化让记忆跨重启保留(第 12 篇),长期记忆让 Agent 跨会话认识用户(第 13 篇)。三层记忆各管各的,各就各位。
但如果你真的跑过上一篇的 Demo,仔细看过控制台输出,可能会发现一个问题:随着记忆越来越丰富、工具越来越多、对话越来越长,Token 预算正在被悄悄吃光。
假设比特严选的客服 Agent 配了 8000 Token 的上下文预算,用户聊到第 8 轮时,messages 数组里塞了什么?

加起来约 5600 Token,看起来还没到 8000 的上限。但这只是第 8 轮——如果对话继续下去,或者某次工具调用返回了一大段知识库内容,Token 预算随时可能爆掉。更关键的是,这 5600 Token 里有多少是当前问题真正需要的?用户第 8 轮问的是“有没有新款扫地机推荐”,但 messages 里还挂着第 2 轮查物流时的完整轨迹 JSON、第 4 轮退款的详细结果——这些对当前问题毫无帮助,白白占着空间。
记忆、工具、历史——每个模块单独看都很合理,但塞在一起就要打架。这就是上下文工程(Context Engineering)要解决的问题。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.9.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
什么是上下文工程
上下文工程这个说法,最初由 Andrej Karpathy 在 2025 年提出。他的原话大意是:与其说我们在做 Prompt Engineering(提示词工程),不如说我们在做 Context Engineering(上下文工程)——真正的挑战不是写一句好的提示词,而是在有限的上下文窗口里,把恰好需要的信息、以恰好合适的格式、放在恰好合适的位置。
用一个比喻来理解:大模型的上下文窗口就像一张办公桌。桌面大小是固定的(比如 8000 Token),你要在上面摆放所有工作材料——操作手册(系统提示词)、客户档案(长期记忆)、工具箱(工具描述)、聊天记录(对话历史)、当前任务的草稿纸(工具调用结果)。
如果你把所有东西一股脑堆上去,桌面很快就满了,你连写字的空间都没有。好的做法是:只把当前任务需要的材料放上来,其他的收进抽屉里,需要时再拿。
这就是上下文工程的核心:不是把所有信息都塞给大模型,而是精心挑选和组织信息,让每一个 Token 都花在刀刃上。
Token 是怎么被吃掉的
在动手优化之前,先把账算清楚。TinyAgent 的上下文由六个部分组成,每个部分的特征不同:
| 组成部分 | 内容 | Token 估算 | 特征 |
|---|---|---|---|
| 系统提示词 | 角色设定、行为规范 | 150-300 | 固定,每轮都一样 |
| 长期记忆 | 用户画像 + 交互记录 | 200-800 | 半固定,同用户同会话内不变 |
| 对话摘要 | HybridChatMemory 压缩的历史概要 | 200-400 | 半固定,随对话增长但增速远低于原始历史 |
| 工具描述 | 所有工具的 JSON Schema | 100-200/个 | 半固定,可按需裁剪 |
| 对话历史 | 最近几轮的 user/assistant 消息 | 400-600/轮 | 动态增长,是最大的消耗者 |
| 当前轮次 | 本轮的工具调用和 Observation | 200-1000 | 动态,取决于工具返回量 |
对话摘要和对话历史的关系在第 11 篇讲过——HybridChatMemory 的混合策略会把超出窗口的老消息压缩成摘要,注入到 messages 的 system 层。摘要本身不长(200-400 Token),但它是额外开销,不能忘了算。在后面的 ContextBudget 实现中,对话摘要和对话历史统一通过 addHistory() 计数——因为 HybridChatMemory.messages() 返回的摘要本身就混在消息列表里,不需要单独拆分。
用比特严选的实际场景算一笔账。Agent 注册了 5 个工具(查订单、查物流、申请退款、知识库检索、获取时间),用户是一个有长期记忆的回头客:
8000 Token 预算的分配现状(无优化):
系统提示词: ████░░░░░░░░░░░░░░░░ 200 Token (2.5%)
长期记忆: ██████████░░░░░░░░░░ 500 Token (6.3%)
对话摘要: ██████░░░░░░░░░░░░░░ 300 Token (3.8%)
工具描述 ×5: ████████████████░░░░ 800 Token (10%)
对话历史 ×8 轮: ████████████████████████████████████████████ 3200 Token (40%)
当前轮次: ████████████░░░░░░░░ 600 Token (7.5%)
─────────────────────────────────────
已用:5600 / 8000(70%)
剩余可用��:2400 Token(30%)← 留给后续轮次和大模型生成回复
看起来还行?但问题在于对话历史是线性增长的。每多一轮,就多 400-600 Token。到第 12 轮,光对话历史就要 4800 Token 以上,加上其他固定开销,预算直接告急。
更大的浪费在于:用户第 8 轮问“推荐新款扫地机”,但上下文里还塞着 5 个工具的完整描述——其中查物流和申请退款跟推荐毫无关系,白白占了 300 多 Token。
问题不是预算不够大,而是没有精打细算。
预算分配:先切蛋糕再吃
解决这个问题的第一步是给每个组成部分分配独立的预算上限,而不是让它们随意抢占。
打个比方:如果你的工资是 8000 块,你不会把所有钱都花在吃上面,然后发现交不起房租。正确的做法是先把房租、水电、交通这些固定开销留出来,剩下的才是吃饭和娱乐的预算。
上下文预算的分配逻辑也一样:
8000 Token 预算分配方案:
┌─────────────────────────────────────────────────┐
│ 系统提示词 ≤ 300 固定开销,不可压缩 │
│ 长期记忆 ≤ 800 封顶,超出部分丢弃 │
│ 工具描述 ≤ 1000 可动态裁剪 │
│ 当前轮次预留 ≤ 2000 给工具调用和 Observation │
│ ────────────────────────────────────────── │
│ 对话历史 = 剩余部分(8000 - 以上) │
│ = 8000 - 300 - 800 - 1000 - 2000 │
│ = 3900 Token │
└─────────────────────────────────────────────────┘
1. 关键设计决策
- 系统提示�词不可压缩:它定义了 Agent 的角色和行为边界,压缩了就不是同一个 Agent 了。
- 当前轮次必须预留:这是 Agent 正在做的事情——工具调用的结果如果放不下,Agent 就无法完成任务。预留 2000 Token 是为了保证即使工具返回了较长的结果,也有空间消化。
- 对话历史分到剩余部分:它是最大的消耗者,但也是最可压缩的——之前的会话记忆管理策略(滑动窗口、摘要压缩)已经帮它瘦身了。
- 长期记忆和工具描述有上限:超出就截断或裁剪,避免一个模块抢光预算。
2. Java 实现:ContextBudget
把分类预算的逻辑封装成 ContextBudget,替代之前 ReActAgent 里那个只会计数的内部类 TokenBudget:
public class ContextBudget {
private static final double TOKENS_PER_CHAR = 1.0;
private final int totalBudget;
private final int memoryLimit;
private final int toolDescLimit;
private final int currentTurnReserve;
private int systemPromptTokens = 0;
private int memoryTokens = 0;
private int toolDescTokens = 0;
private int historyTokens = 0;
private int currentTurnTokens = 0;
public ContextBudget(int totalBudget) {
this(totalBudget, 800, 1000, 2000);
}
public ContextBudget(int totalBudget, int memoryLimit,
int toolDescLimit, int currentTurnReserve) {
this.totalBudget = totalBudget;
this.memoryLimit = memoryLimit;
this.toolDescLimit = toolDescLimit;
this.currentTurnReserve = currentTurnReserve;
}
public void addSystemPrompt(String content) {
systemPromptTokens += estimateTokens(content);
}
public boolean tryAddMemory(String content) {
int tokens = estimateTokens(content);
if (memoryTokens + tokens > memoryLimit) {
return false;
}
memoryTokens += tokens;
return true;
}
public boolean tryAddToolDescription(String content) {
int tokens = estimateTokens(content);
if (toolDescTokens + tokens > toolDescLimit) {
return false;
}
toolDescTokens += tokens;
return true;
}
public int getHistoryBudget() {
int used = systemPromptTokens + memoryTokens + toolDescTokens;
return Math.max(0, totalBudget - used - currentTurnReserve);
}
public String getReport() {
return String.format(
"系统提示词 %d + 长期记忆 %d + 工具描述 %d + 对话历史 %d + 当前轮次 %d = %d / %d",
systemPromptTokens, memoryTokens, toolDescTokens,
historyTokens, currentTurnTokens, getTotalUsed(), totalBudget);
}
// ......
}
跟之前的 TokenBudget 相比,关键变化有三个:
分类计数而非笼统累加:各组成部分有独立的计数器,能清楚看到每一块用了多少。getReport() 输出类似 系统提示词 200 + 长期记忆 450 + 工具描述 600 + 对话历史 2800 + 当前轮次 500 = 4550 / 8000,一目了然。
tryAddMemory() 和 tryAddToolDescription() 返回 boolean:尝试添加内容,如果超出该类别的预算上限就返回 false,调用方可以选择跳过或降级。这比之前的先加再检查更主动——不是等到预算爆了才发现,而是在添加之前就做决策。
getHistoryBudget() 动态计算对话历史的可用空间:对话历史没有固定上限,它的�预算 = 总预算 - 系统提示词 - 长期记忆 - 工具描述 - 当前轮次预留。如果工具描述被裁剪了(省了 300 Token),这 300 Token 就自动留给了对话历史——预算在各个类别之间形成了有弹性的分配。
Token 估算用的是
text.length() × 1.0的粗略公式——1 个字符按 1 个 Token 粗估。跟实际分词结果会有出入,但作为预算管理的近似计算够用了。如果需要精确计算,可以接入 tiktoken 等分词工具。
组装顺序:为什么 system prompt 必须在最前面
预算分好了,下一个问题是:这六个部分按什么顺序组装到 messages 数组里?
答案不是随便排的。大模型对上下文中不同位置的信息,注意力权重是不一样的。简单来说:
- 开头的信息(system prompt):注意力最高,定义了整个对话的基调和规则。
- 末尾的信息(最近几条消息):注意力次高,是当前对话的直接上下文。
- 中间的信息(历史消息的中段):注意力最低,容易被忽略。
这就是所谓的 Lost in the Middle(中间遗忘)现象——大模型在处理长上下文时,对头部和尾部的信息记得最清楚,中间的容易丢。
基于这个特点,TinyAgent 的上下文组装顺序是:
messages 数组的组装顺序:
[0] system: 系统提示词 ← 头部:定义角色,注意力最高
[1] system: 长期记忆(画像 + 交互记录) ← 头部:背景信息,优先级高
[2] system: 对话摘要(如果有) ← 过渡区:压缩的历史
[3] user: 较早的用户消息 ← 中间:可能被遗忘
[4] assistant: 较早的 Agent 回复 ← 中间:可能被遗忘
...
[N-1] user: 上一轮用户消息 ← 尾部:注意力恢复
[N] user: 当前轮次用户输入 ← 尾部:最重要的当前问题
tools 参数(独立于 messages,但同样消耗 Token):
工具 1:查订单
工具 2:查物流
...
每个位置的设计意图:
| 位置 | 内容 | 为什么放在这 |
|---|---|---|
| 头部第 1 条 | 系统提示词 | 定义 Agent 的角色和行为规范,必须最先被理解 |
| 头部第 2 条 | 长期记忆 | 为后续对话提供用户背景,像给大脑装上“我认识这个人”的前提 |
| 头部第 3 条 | 对话摘要 | 如果有 HybridChatMemory 的摘要,放在历史消息之前做概览 |
| 中间 | 较早的对话历史 | 可能被遗忘,但有总比没有好。重要信息靠摘要兜底 |
| 尾部 | 最近的对话和当前输入 | 大模型对尾部信息的注意力最强,当前问题必须在这里 |
一个常见的错误做法是把长期记忆放在对话历史之后——这样大模型会把它当成“刚才说的话”而非“背景信息”,容易导致混淆。长期记忆是背景知识,应该放在 system 层,让大模型把它当做先验信息。
策略一:动态裁剪工具描述
工具描述是一个容易被��忽略的 Token 消耗大户。
比特严选的 Agent 注册了 5 个工具,每个工具的 JSON Schema(name + description + parameters)大约占 100-200 Token。5 个工具加起来就是 500-1000 Token。如果未来业务扩展到 15-20 个工具(加上商品对比、IoT 设备搭配、促销查询、故障诊断等),工具描述可能占到 2000-3000 Token——接近总预算的三分之一。
但大多数时候,用户的问题只涉及 1-2 个工具。用户问“帮我查订单 88231”,Agent 只需要 queryOrder 这一个工具,其他 4 个工具的描述白白占着空间,还可能干扰大模型的判断(工具越多,大模型选错的概率越高)。
1. 关键字匹配为什么不靠谱
最直觉的做法是关键字匹配——把用户输入跟工具描述做字面比较,有重叠就保留,没重叠就过滤。
用户说:“帮我查一下订单 88231 的物流”
→ “订单” 命中 queryOrder ✓
→ “物流” 命中 queryLogistics ✓
→ 看起来不错?
但换一个说法就不行了:
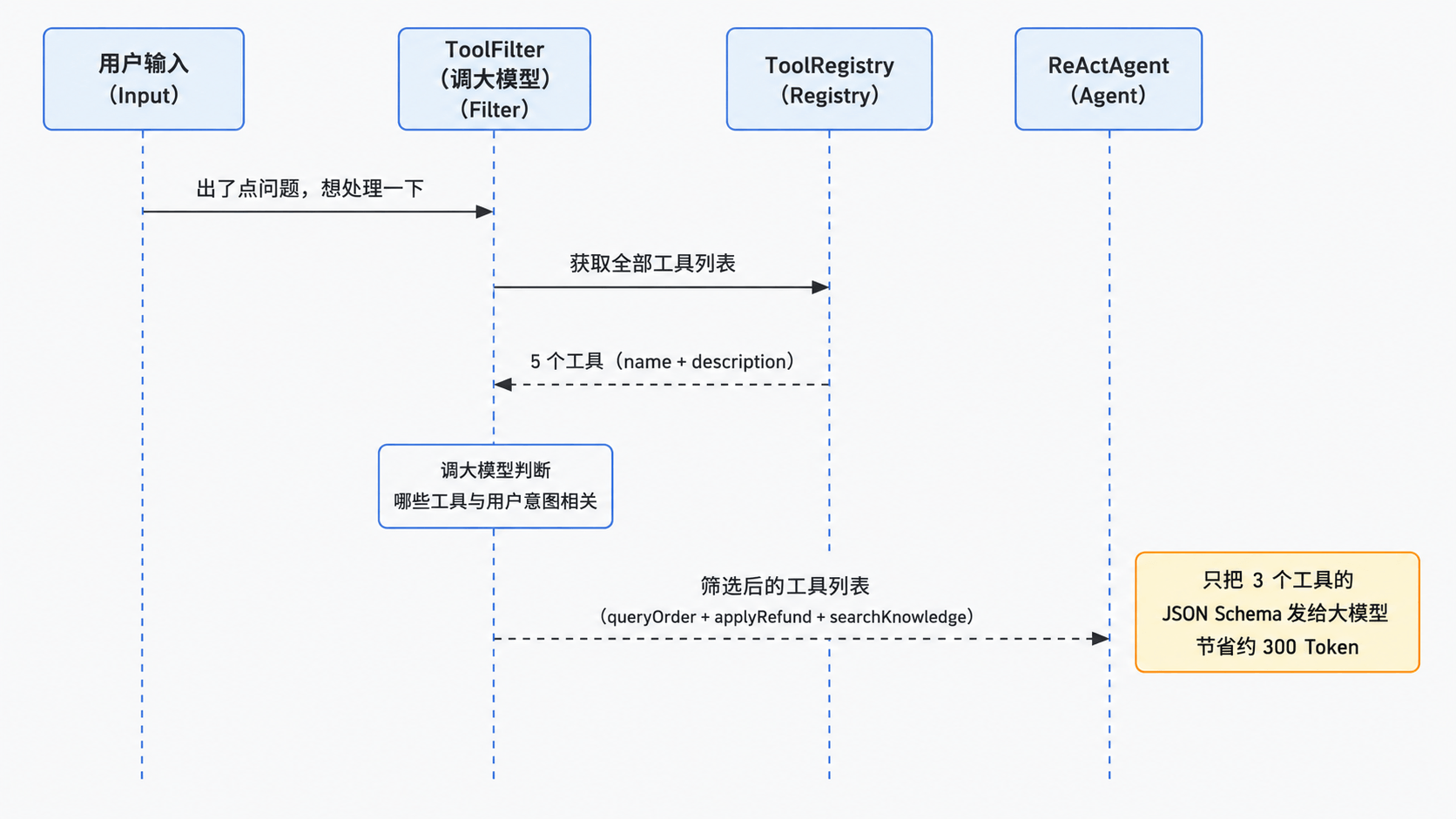
用户说:“出了点问题,想处理一下”
→ “出了”“点问”“问题”“想处”“处理” → 跟 applyRefund 的描述“发起退款申请”零重叠
→ 退款工具被过滤掉了 ✗
用户没说“退款”两个字,但意图就是退款。关键字匹配只能处理用户把工具名说出来的场景——稍微换个表达,就漏了。更极端的例子:“不好用了怎么办”→ 可能需要退款、也可能需要知识库,但跟任何工具描述都没有字面重叠。
关键字匹配做的是字面相似度,而工具筛选需要的是语义理解。 这恰好是大模型擅长的事。
2. 用大模型做工具筛选
思路很简单:在正式调用 Agent 之前,先用一次轻量的 LLM 调用,让大模型根据用户输入判断哪些工具可能用到。
用户输入:“出了点问题,想处理一下”
发给大模型:
系统提示词:你是一个工具路由助手,根据用户问题选出需要的工具。
用户消息:
用户问题:出了点问题,想处理一下
候选工具:
- queryOrder:查询订单详情
- queryLogistics:根据运单号查询物流轨迹
- applyRefund:发起退款申请
- searchKnowledge:检索比特严选知识库
- getCurrentTime:获取当前时间
大模型返回:
queryOrder
applyRefund
searchKnowledge
筛选结果:保留 3 个工具,过滤掉 queryLogistics 和 getCurrentTime
大模型能理解“出了问题”暗含售后意图,所以选了 applyRefund;同时它判断可能需要先查订单确认情况,所以也保留了 queryOrder;知识库可能有售后政策,也留着。这种语义理解是关键字匹配做不到的。
3. 流程图示
4. Java 实现
public class ToolFilter {
private final LlmClient llmClient;
public ToolFilter(LlmClient llmClient) {
this.llmClient = llmClient;
}
public List<Tool> filter(Collection<Tool> allTools, String userQuery) {
if (userQuery == null || userQuery.isBlank()) {
return new ArrayList<>(allTools);
}
// 拼接候选工具列表
StringBuilder toolList = new StringBuilder();
List<Tool> toolOrder = new ArrayList<>(allTools);
for (Tool tool : toolOrder) {
toolList.append("- ").append(tool.name())
.append(":").append(tool.description()).append("\n");
}
// 构建一次轻量的 LLM 调用
ObjectMapper objectMapper = llmClient.getObjectMapper();
ArrayNode messages = objectMapper.createArrayNode();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", """
你是一个工具路由助手。根据用户的问题,从候选工具列表中选出需要用到的工具。
只输出工具名(如 queryOrder),每行一个,不要输出任何解释。
如果不确定,宁可多选不要漏选。
如果用户的问题不需要任何工具(如打招呼、闲聊),输出 NONE。""");
ObjectNode userMsg = messages.addObject();
userMsg.put("role", "user");
userMsg.put("content",
"用户问题:" + userQuery + "\n\n候选工具列表:\n" + toolList);
try {
ChatResponse response = llmClient.chatWithTools(
messages, objectMapper.createArrayNode());
if (response.content() == null || response.content().isBlank()) {
return new ArrayList<>(allTools);
}
// 大模型判断不需要任何工具
String content = response.content().strip();
if ("NONE".equalsIgnoreCase(content)) {
return new ArrayList<>();
}
// 解析大模型返回的工具名
Set<String> selectedNames = new HashSet<>();
for (String line : content.split("\n")) {
String name = line.strip()
.replace("- ", "")
.replace("*", "");
if (!name.isBlank()) {
selectedNames.add(name);
}
}
List<Tool> result = new ArrayList<>();
for (Tool tool : toolOrder) {
if (selectedNames.contains(tool.name())) {
result.add(tool);
}
}
return result;
} catch (Exception e) {
// 筛选失败不能影响主流程,回退到全量
System.out.println("[ToolFilter] 筛选失败,回退到全量工具:" + e.getMessage());
return new ArrayList<>(allTools);
}
}
}
几个关键设计说一下:
提示词里的两条兜底规则:一是“宁可多选不要漏选”——工具筛选错杀的代价远大于多保留几个,多保留一个工��具只多占 100-200 Token,但漏掉一个关键工具,Agent 可能整个任务都完不成。二是“不需要任何工具时输出 NONE”——用户说“你好”就不应该带工具,大模型直接回复即可,硬塞工具反而可能误导 Agent 去调一个不需要的工具。
异常回退:try-catch 包住整个筛选逻辑——如果 LLM 调用失败(网络超时、返回格式异常),直接回退到全量工具。工具筛选是一个优化手段,不是核心流程,不能因为优化失败导致 Agent 整个不能用。
传入空的 tools 数组:调 chatWithTools 时传的是空的 ArrayNode——我们不需要大模型调工具,只需要它输出文本。这是一次纯文本的轻量调用,通常0.5~2秒内就能返回,取决于工具数量的多少。
5. 配合 ToolRegistry 使用
要让 ToolFilter 工作,ToolRegistry 需要暴露工具列表,并支持从筛选后的子集构建 JSON:
public class ToolRegistry {
// ... 已有代码
public Collection<Tool> getTools() {
return Collections.unmodifiableCollection(tools.values());
}
public ArrayNode buildToolsJsonArray(ObjectMapper objectMapper, Collection<Tool> toolSubset) {
ArrayNode toolsArray = objectMapper.createArrayNode();
for (Tool tool : toolSubset) {
// ... 构建逻辑跟原来一样,只是遍历的是子集
}
return toolsArray;
}
}
原来的 buildToolsJsonArray(ObjectMapper) 方法保持不变,内部委托给新的重载方法,传入全��部工具。新增的重载接收一个工具子集,只构建子集的 JSON Schema。
6. 两种方案对比
| 维度 | 关键字匹配 | 大模型筛选 |
|---|---|---|
| 准确性 | 低——只能处理字面重叠,间接意图完全漏掉 | 高——能理解“出了问题”→ 退款、“不好用了”→ 售后 |
| 额外开销 | 零——纯字符串操作 | 一次轻量 LLM 调用(0.5~2 秒 + 少量 Token) |
| 实现复杂度 | 极低 | 低——核心逻辑不到 30 行 |
| 可靠性 | 稳定,不会出错 | 有失败风险(网络、格式),需要 try-catch 兜底 |
| 适用场景 | 用户表达直接、工具少(≤ 5 个) | 用户表达模糊、工具多(5 个以上) |
对于比特严选的场景,用户说的话千变万化——“出了点问题”“不好用了”“想退了”“帮我看看这个”——这些意图都需要语义理解才能正确路由到工具。所以本项目选择大模型方案。
额外的 LLM 调用看起来是个开销,但算一笔账:筛选调用的输入很短(用户问题 + 工具列表,通常不超过 300 Token),输出也很短(几个工具名,不超过 50 Token),一次调用的成本约 0.001-0.003 元。而它省下的 300-500 Token 工具描述,在后续每一圈 ReAct 循环中都不用重复发送——如果 Agent 走了 3 圈,总共省了 900-1500 Token 的传输量。净效果是正收益。
策略二:Observation 结果折叠
Agent 每调用一次工具,工具返回的结果(Observation)就会被追加到 messages 里。这些结果的长度差异很大:
查订单结果(约 150 字符):
{"orderId":"88231","product":"比特 S10 Pro 扫地机","price":1999,...}
查物流结果(约 300 字符):
{"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收",
"traces":[{"time":"2026-06-20 18:20:00","desc":"快件已揽收"},
{"time":"2026-06-21 09:10:00","desc":"快件到达上海转运中心"},
{"time":"2026-06-22 11:35:00","desc":"快件已由�本人签收"}]}
知识库检索结果(可能 500-2000 字符):
多段商品详情、售后政策、FAQ 内容...
在 ReAct 循环中,这些 Observation 会不断累积。Agent 走了 3 圈,messages 里就挂着 3 个工具调用的完整结果。物流那条 300 字符的 traces 数组,在模型拿到运单号、承运商、签收状态之后,已经没有决策价值了——但它还占着 Token 空间。
1. 按字符截断为什么不行
最直觉的做法是设一个最大长度,超出就截断。但对 JSON 结果来说,这是最差的一种折叠:
原始结果:
{"orderId":"88231","status":"已退款","refundAmount":1999,"reason":"质量问题"}
按 60 字符截断:
{"orderId":"88231","status":"已退款","refundAmount":1999,"r...[已折叠]
三个问题:
- JSON 语法被破坏:截到一半的 JSON 既不是合法 JSON,也不是完整句子。大模型可能基于残缺结构编造后续内容,比把信息省略更危险。
- 依赖字段顺序:截断隐含了一个假设——关键字段排在前面。但不同接口、不同序列化库的输出顺序不可控。如果
status恰好排在最后面,截断后模型连订单状态都看不到。 - 无差别砍一刀:不管哪个字段重要哪个不重要,一律按字符数切。100 字符的关键状态和 100 字符的冗余轨迹,在截断逻辑眼里没有任何区别。
2. 字段级 JSON 过滤
更合理的做法是按字段类型过滤:保留所有标量字段(字符串、数字、布尔值),丢弃数组和嵌套对象。
折叠前(约 300 字符):
{"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收",
"traces":[{"time":"2026-06-20 18:20:00","desc":"快件已揽收"},
{"time":"2026-06-21 09:10:00","desc":"快件到达上海转运中心"},
{"time":"2026-06-22 11:35:00","desc":"快件已由本人签收"}]}
折叠后(约 80 字符):
{"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收"}
traces 数组被整体移除,但运单号、承运商、签收状态都完整保留。大模型看到这个结果,完全能正确回答“您的包裹已由顺丰速运送达并签收”。
为什么标量字段通常是关键信息?因为工具返回的 JSON 里,标量字段一般是结论性数据(状态、ID、金额、时间),数组和嵌套对象一般是过程性数据(轨迹列表、详情列表、变更记录)。Agent 做决策靠的是结论,不是过程。
3. Java 实现
public class ObservationFolder {
private final int maxLength;
private final ObjectMapper objectMapper;
public ObservationFolder(int maxLength) {
this.maxLength = maxLength;
this.objectMapper = new ObjectMapper();
}
public String fold(String observation) {
if (observation == null || observation.length() <= maxLength) {
return observation;
}
// 优先尝试字段级 JSON 过滤
String trimmed = observation.trim();
if (trimmed.startsWith("{")) {
String folded = foldJson(trimmed);
if (folded != null) {
// 折叠后仍超长,回退到语义边界截断
return folded.length() <= maxLength ? folded : truncateAtBoundary(folded);
}
}
// 非 JSON 内容:在语义边界处截断
return truncateAtBoundary(observation);
}
private String foldJson(String json) {
try {
JsonNode root = objectMapper.readTree(json);
if (!root.isObject()) return null;
ObjectNode summary = objectMapper.createObjectNode();
root.fields().forEachRemaining(entry -> {
JsonNode value = entry.getValue();
// 只保留标量字段(字符串、数字、布尔值)
// 丢弃数组和嵌套对象
if (value.isValueNode()) {
summary.set(entry.getKey(), value);
}
});
return objectMapper.writeValueAsString(summary);
} catch (Exception e) {
return null;
}
}
private String truncateAtBoundary(String text) {
int cutoff = Math.min(text.length(), maxLength);
// 从截断点往前找最近的语义边界(逗号、句号)
for (int i = cutoff; i > cutoff / 2; i--) {
char c = text.charAt(i - 1);
if (c == ',' || c == ',' || c == '。' || c == '}') {
return text.substring(0, i) + "...[已折叠]";
}
}
return text.substring(0, cutoff) + "...[已折叠]";
}
}
两层策略:
JSON 内容走 foldJson():用 Jackson 解析 JSON,遍历所有字段,isValueNode() 为 true 的保留(字符串、数字、布尔值、null),其余丢弃。输出的是合法的 JSON——语法完整、字段顺序不影响结果。解析失败(不是合法 JSON)就跌入下一层。
非 JSON 内容走 truncateAtBoundary():不是在任意位置切一刀,而是从截断点往前找最近��的语义边界——中文逗号、句号、JSON 的 }。比起在“快件到达上海转运中”这种半截话处断开,在一个完整句子后面断开,大模型更容易理解。
4. 折叠时机
折叠在工具结果写入 messages 之前进行。你可能会想:当前步骤刚拿到的结果也折叠,模型不是少看了信息吗?
对于字段级 JSON 过滤,这个顾虑不大。以物流查询为例,foldJson() 保留了 trackingNo、carrier、status 三个标量字段——模型需要这些来回答用户和决定下一步操作。被丢掉的 traces 数组是三条轨迹明细,模型用不上它来做决策(它不需要知道包裹 6 月 21 日 9:10 到了上海转运中心)。
如果你的工具返回的关键信息藏在嵌套对象里(比如
{"result":{"status":"已签收"}}),字段级过滤会把result整体丢掉。这种情况下需要按工具类型定制折叠逻辑,或者改工具的返回格式让关键字段平铺在顶层。比特严选的 5 个工具全部是扁平 JSON 结构,标量字段在顶层,所以通用的字段级过滤已经够用。
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 输出是合法 JSON,不会破坏语法结构 | 假设关键信息是标量字段,嵌套结构里的关键数据会丢 |
| 不依赖字段顺序,所有标量字段都保留 | 对非 JSON 内容仍需回退到截断(虽然是语义边界截断) |
| 效果显著——物流结果从 300 字符降到 80 字符 | 如果所有字段都是标量(没有数组),等于没折叠 |
| 对所有返回扁平 JSON 的工具通用 | 深度嵌套的 JSON 需要按工具定制折叠策略 |
进阶思考:按任务阶段调整 Context 组成
前面两个策略——工具裁剪和 Observation 折叠——已经能在单轮维度上有效控制 Token 开销。接下来一个自然的想法是:能不能把视角拉到整个会话周期,根据任务所处的阶段来动态调整上下文组成?
这个方向本身是合理的——任务早期偏探索(需要广度),后期偏收敛(需要聚焦),不同阶段对工具、记忆、历史的需求确实不一样。但关键问题是:怎么判断当前处于哪个阶段?
1. 用轮次当阶段的代理变量,为什么不行
最直觉的做法是按轮次划分:第 1-2 轮 = 理解阶段,第 3-5 轮 = 执行阶段,第 6 轮以后 = 收尾阶段。然后给每个阶段配不同的预算上限。
听起来很合理,但轮次和任务阶段之间没有稳定的对应关系。真实对话根本不按剧本走:
场景 1:用户第 1 轮就直奔主题
用户:“帮我退货,订单号 88231”
→ 第 1 轮就该进执行阶段,但“轮次 1-2 = 理解阶段”
的规则会保留所有工具、全量注入记忆,完全是浪费。
场景 2:用户在第 4 轮突然换话题
第 1-3 轮:查物流,问题已解决
第 4 轮:“对了,你们有没有新款耳机推荐?”
→ 应该退回理解阶段(新任务),但按轮次已经进了“执行阶段”,
工具描述预算被缩减,推荐相关的工具可能被裁掉。
场景 3:用户在第 7 轮追问一个需要查�库的细节
第 6 轮:Agent 回复退款预计 3-5 天到账
第 7 轮:“那我能改成退到另一张卡吗?”
→ 需要调用工具查询退款方式变更,但“收尾阶段”的规则
已经把工具描述预算压到了最低,关键工具被裁没了。
三个例子暴露了同一个本质问题:轮次是时间信号,不是状态信号。把预算写死到轮次上,等于赌用户按你预想的节奏走。一旦用户“越界”:
- 该有的工具被裁掉 → Agent 无法完成任务
- 该保留的记忆被缩减 → Agent 失忆
这比 Observation 折叠损失细节要严重得多——它可能直接让 Agent 丧失能力。
2. 更隐蔽的问题:预算只减不增
按轮次划分的方案还有一个结构性缺陷:预算是单调递减的。工具描述从 1200 → 800 → 500,长期记忆从 800 → 500 → 300。这隐含了一个假设——对话是线性推进、不会回头的。
但客服场景恰恰相反:话题切换、追加需求、推翻前面的结论是家常便饭。一个只减不增的预算模型,处理不了“用户在第 8 轮开启新任务”这种再普通不过的情况。
3. 和策略一的功能重叠
还有一个容易忽略的问题:如果你已经有了策略一(用大模型按语义裁剪工具),那“执行阶段裁工具”就是自动发生的——ToolFilter 每轮都会根据用户输入筛选相关工具,不需要“阶段”这个概念额外来管。
策略三在工具维度上和策略一完全重叠,徒增一层不可靠的轮次判断。 真正只有阶段感知能做、策略一做不了的,是长期记忆的预算调整——但这部分留给规模上来后再解决。
4. 如果真要做,该用什么信号
方向没错,但实现路径要换。阶段应该由任务状态驱动,不是由时间流逝(轮次)驱动。几个更可靠的信号:
| 信号 | 说明 | 示例 |
|---|---|---|
| 意图是否已确定 | 用意图识别或槽位填充来判断,而不是数轮次 | 用户说了“退货”+ 订单号 → 意图明确,进执行态 |
| 是否有待执行的工具计划 | 有明确 plan 时进执行态,plan 清空后收敛 | Plan-and-Execute 模式下天然具备这个信号 |
| 最近一轮是否引入新任务 | 检测话题切换 → 动态恢复工具全集和记忆预算 | 用“对了”“另外”开头 → 新话题,重置阶段 |
前三个都是外部可观测的确定性信号,可以直接用代码判断。还有一种�思路是让模型自己声明阶段(在 Agent 输出中加一个 phase: executing 字段),准确性比数轮次高,但本质上仍然是模型的主观判断,可靠性不如上面三个确定性信号,更适合作为兜底补充而非主要依据。
核心区别:这些信号跟轮次无关,跟任务的实际进展有关。它们天然支持回退——话题切换时阶段回退,预算重新分配,不会出现“只减不增”的问题。
5. 为什么本项目不实现
比特严选当前 5 个工具、8000 Token 预算,策略一(ToolFilter)和策略二(ObservationFolder)已经把 Token 利用率拉到了足够好的水平。硬加阶段感知是典型的过度工程——增加了一层脆弱的判断逻辑,但在当前体量下几乎看不到收益。
阶段感知真正值得投入的场景是:工具 15 个以上、对话可能 15 轮以上、长期记忆量大且内容多样(不同阶段确实只需要不同切面的记忆)。到那个规模,你也不会再用 if (step <= 2) 这种硬编码——你需要的是一个基于意图识别和计划状态的完整状态机,而下一篇要讲的 Plan-and-Execute 模式天然具备这种阶段信号,届时再落地会清晰得多。
改造 ReActAgent:集成上下文工程
把前面的两个策略集成到 ReActAgent 中。改动分两块��:新增字段和改造 run() 方法。
1. 新增字段和构造函数
public class ReActAgent {
// ... 已有字段
private final ToolFilter toolFilter;
private final ObservationFolder observationFolder;
// 保持已有构造函数不变,新增一个完整版
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry,
int maxSteps, int maxTokens, ChatMemory chatMemory,
LongTermMemoryRetriever memoryRetriever,
ToolFilter toolFilter, ObservationFolder observationFolder) {
// ... 赋值
this.toolFilter = toolFilter;
this.observationFolder = observationFolder;
}
// 已有的构造函数委托给完整版,toolFilter 和 observationFolder 传 null
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry,
int maxSteps, int maxTokens, ChatMemory chatMemory,
LongTermMemoryRetriever memoryRetriever) {
this(llmClient, toolRegistry, maxSteps, maxTokens,
chatMemory, memoryRetriever, null, null);
}
}
ToolFilter 和 ObservationFolder 都是可选的——传 null 就跟之前的行为完全一样,不影响已有的 Demo 代码。
2. 改造 run() 方法
run() 方法的改造分四个关键点,用注释标出:
public String run(String userMessage, String userId) {
ArrayNode messages = objectMapper.createArrayNode();
// 【改造点 1】用 ContextBudget 替代原来的 TokenBudget
String systemPrompt = buildSystemPrompt();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", systemPrompt);
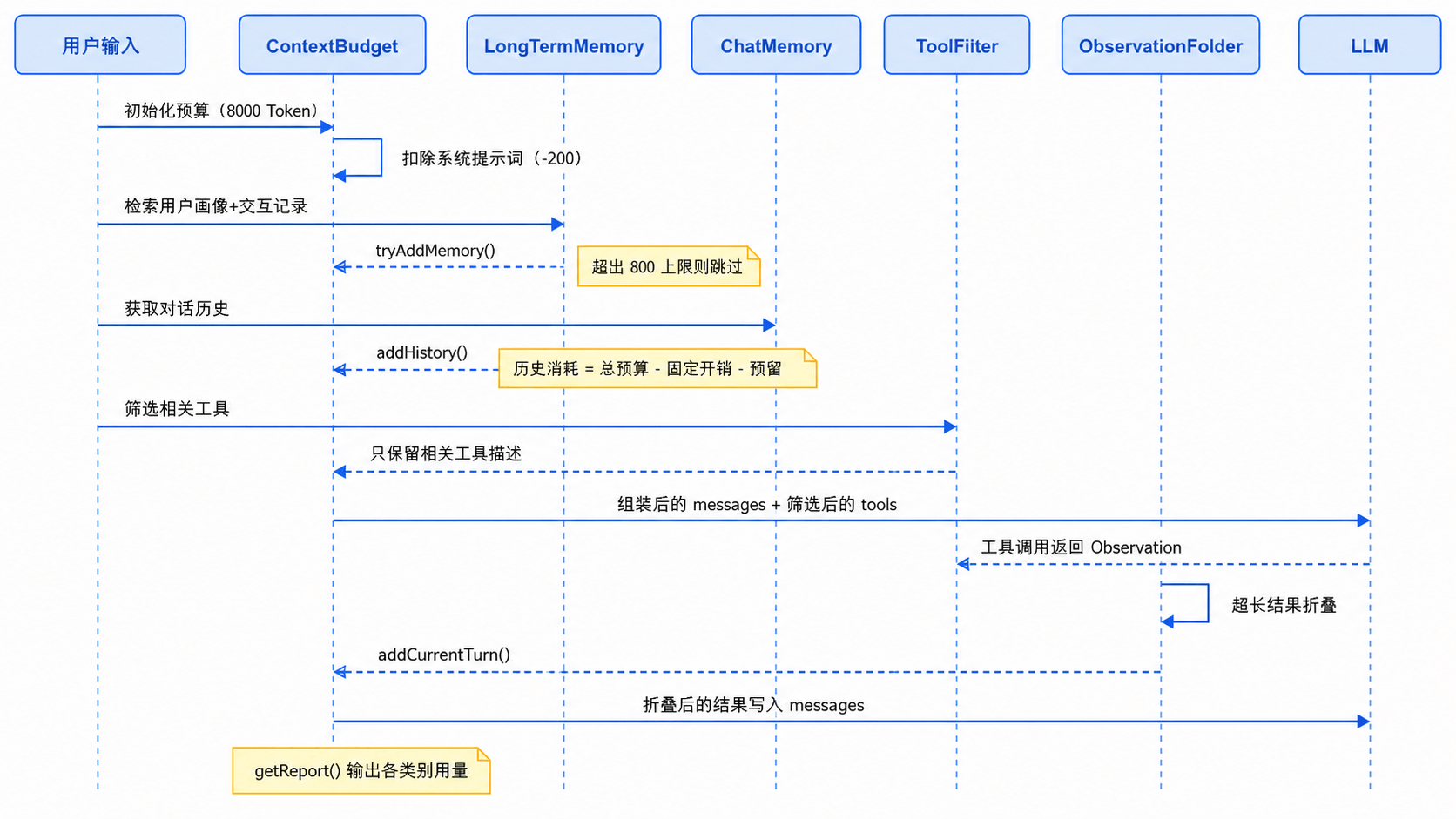
ContextBudget budget = new ContextBudget(maxTokens);
budget.addSystemPrompt(systemPrompt);
// 【改造点 2】长期记忆用 tryAddMemory() 控制预算
if (memoryRetriever != null && userId != null) {
String memoryContext = memoryRetriever.buildMemoryContext(userId, userMessage);
if (!memoryContext.isBlank()) {
String fullMemory = "以下是关于当前用户的历史信息,供你参考:\n" + memoryContext;
if (budget.tryAddMemory(fullMemory)) {
ObjectNode memoryMsg = messages.addObject();
memoryMsg.put("role", "system");
memoryMsg.put("content", fullMemory);
} else {
System.out.println("[上下文] 长期记忆超出预算,已跳过");
}
}
}
// 对话历史注入(跟之前一样,改用 budget.addHistory())
if (chatMemory != null) {
chatMemory.add(ChatMessage.user(userMessage));
for (ChatMessage mem : chatMemory.messages()) {
// ... 注入逻辑不变
budget.addHistory(mem.content());
}
// getHistoryBudget() 动态检查对话历史是否超出预算
if (budget.getHistoryTokens() > budget.getHistoryBudget()) {
System.out.println("[上下文] 对话历史超出动态预算");
}
} else {
// ... 无记忆模式,直接添加 user 消息
budget.addHistory(userMessage);
}
// 【改造点 3】工具描述动态裁剪 + 预算控制
Collection<Tool> candidateTools;
if (toolFilter != null) {
candidateTools = toolFilter.filter(
toolRegistry.getTools(), userMessage);
System.out.println("[上下文] 工具筛选:全部 "
+ toolRegistry.getTools().size()
+ " 个 → 语义匹配 " + candidateTools.size() + " 个");
} else {
candidateTools = toolRegistry.getTools();
}
// 工具描述走预算控制:超出 toolDescLimit 的工具会被跳过
List<Tool> budgetedTools = new ArrayList<>();
for (Tool tool : candidateTools) {
String toolDesc = tool.name() + ":" + tool.description()
+ (tool.parameters() != null ? tool.parameters() : "");
if (budget.tryAddToolDescription(toolDesc)) {
budgetedTools.add(tool);
}
}
ArrayNode tools = toolRegistry.buildToolsJsonArray(objectMapper, budgetedTools);
// ... 循环体内部
for (int step = 1; step <= maxSteps; step++) {
if (budget.isExceeded()) {
System.out.println("[终止] Token 预算耗尽(" + budget.getReport() + ")");
return "抱歉,本次对话信息量较大,已达到处理上限。请尝试简化问题或分多次咨询。";
}
ChatResponse response = llmClient.chatWithTools(messages, tools);
// ... 工具调用处理
for (ToolCallInfo tc : response.toolCalls()) {
String observation = toolRegistry.execute(
new Action(tc.functionName(), tc.arguments()));
// 【改造点 4】Observation 折叠
if (observationFolder != null) {
String folded = observationFolder.fold(observation);
if (folded.length() < observation.length()) {
System.out.println("[上下文] Observation 折叠:"
+ observation.length() + " → " + folded.length() + " 字符");
}
observation = folded;
}
ObjectNode toolMsg = messages.addObject();
toolMsg.put("role", "tool");
toolMsg.put("tool_call_id", tc.id());
toolMsg.put("content", observation);
budget.addCurrentTurn(observation);
}
}
}
四个改造点的效果:
ContextBudget替代TokenBudget��:从笼统计数变成分类计数,每轮结束后budget.getReport()能打印出每个类别的用量。tryAddMemory()做前置检查:如果长期记忆超出 800 Token 的上限,直接跳过,不会挤占其他部分的空间。ToolFilter+tryAddToolDescription()裁剪工具:先用ToolFilter做语义筛选,再用tryAddToolDescription()做预算控制,双重裁剪后只把相关且预算内的工具发给大模型。ObservationFolder折叠结果:工具返回的长结果在写入 messages 前被截断,控制台打印折叠比例。
Demo:上下文工程的效果
把所有组件串起来,跑一个三轮对话,观察控制台输出中的上下文工程日志:
public static void main(String[] args) {
ToolRegistry toolRegistry = new ToolRegistry();
toolRegistry.register(new QueryOrderTool());
toolRegistry.register(new QueryLogisticsTool());
toolRegistry.register(new ApplyRefundTool());
toolRegistry.register(new SearchKnowledgeTool());
toolRegistry.register(new GetCurrentTimeTool());
// ... LlmClient、DataSource 等初始化(跟之前的 Demo 一样)
// 上下文工程组件
ToolFilter toolFilter = new ToolFilter(llmClient);
ObservationFolder observationFolder = new ObservationFolder(200);
String userId = "user_10086";
String sessionId = sessionManager.createSession(userId);
ChatMemory chatMemory = new PersistentHybridChatMemory(
dataSource, sessionId, llmClient, 6, 12);
// 传入 toolFilter 和 observationFolder
ReActAgent agent = new ReActAgent(
llmClient, toolRegistry, 10, 8000,
chatMemory, retriever, toolFilter, observationFolder);
System.out.println("========== 第 1 轮:查订单 ==========");
agent.run("帮我查一下订单 88231 的物流", userId);
System.out.println("\n\n========== 第 2 轮:退款 ==========");
agent.run("那我要退款呢,这个扫地机不回充了", userId);
System.out.println("\n\n========== 第 3 轮:推荐 ==========");
agent.run("有没有新款扫地机推荐一下", userId);
}
预期控制台输出中会看到的上下文工程日志:
========== 第 1 轮:查订单 ==========
[上下文] 工具筛选:全部 5 个 → 语义匹配 2 个
===== 第 1 圈 =====
[工具调用] queryOrder({"orderId":"88231"})
[工具结果] {"orderId":"88231","product":"比特 S10 Pro 扫地机",...}
===== 第 2 圈 =====
[工具调用] queryLogistics({"trackingNo":"SF1234567890"})
[上下文] Observation 折叠:218 → 61 字符
[工具结果] {"trackingNo":"SF1234567890","carrier":"顺丰速运","status":"已签收"}
===== 第 3 圈 =====
[最终答复] 您的订单 88231 的物流信息如下...
[预算] 系统提示词 262 + 长期记忆 169 + 工具描述 412 + 对话历史 17 + 当前轮次 270 = 1130 / 8000
对比没有上下文工程的情况:
| 指标 | 无优化 | 有上下文工程 | 节省 |
|---|---|---|---|
| 工具描述 Token | ~800(5 个工具) | ~400(2 个工具) | ~400 |
| 物流 Observation | ~218 字符 | ~61 字符(字段级过滤) | ~157 |
| 第 1 轮总消耗 | ~1700 Token | ~1130 Token | ~570 |
570 Token 在 8000 的预算下是 7% 的空间。累积 8 轮对话,每轮省 300-500 Token,总共能省出 2400-4000 Token——相当于 4-6 轮对话历史的空间。这意味着 Agent 可以多记住好几轮对话,或者在对话末期仍然有足够的预算调用工具。
上下文工程的全景图
把本篇讲的所有策略放在一起,画一张完整的上下文组装流程图:
文末总结
这一篇从“Token 预算被悄悄吃光”的问题出发,讲了上下文工程的两个落地策略和一个设计思考:
- 预算分配:用
ContextBudget替代简单的计数器,给系统提示词、长期记忆、��工具描述、对话历史、当前轮次各分独立预算,tryAddMemory()和tryAddToolDescription()在添加前做前置检查,超限就主动降级。 - 动态裁剪工具描述:用
ToolFilter通过一次轻量的 LLM 调用做语义理解,只保留与用户意图相关的工具,5 个工具裁到 2-3 个能省出 300-500 Token。 - Observation 结果折叠:用
ObservationFolder做字段级 JSON 过滤——保留标量字段(结论性数据),丢弃数组和嵌套对象(过程性数据),物流结果从 218 字符降到 61 字符。 - 按任务阶段调整上下文:方向对,但“用轮次当阶段代理变量”的实现路径不可靠——轮次不等于阶段,预算只减不增无法处理话题切换。正确做法是用意图识别、计划状态等任务信号驱动,等到有了 Plan-and-Execute 基础设施再落地。
两个落地策略加在一起,让 TinyAgent 在 8000 Token 的预算下,能多支撑 3-5 轮对话,或者在对话后期仍有余力调用工具。更重要的是,ContextBudget.getReport() 让你清楚看到每一块预算花在了哪里——上下文不再是一个黑盒。
用一句话概括:上下文工程的本质不是省 Token,而是让每一个 Token 都花在当前任务真正需要的信息上。
到这里,记忆与上下文这个部分就全部完成了。从短期记忆到持久化,从长期记忆到上下文工程,TinyAgent 已经具备了完整的“记忆体系”和“空间管理”能力。但目前 Agent 的决策方式还是 ReAct 模式——一步一步走,每走一步才想下一步该干什么。这种模式适合简单任务,但面对复杂任务(比如“帮我对比三款扫地机,选一个最适合老人用的,然后下单”),一步步摸索效率太低。接下来,咱们进入规划与多工具编排——先规�划再执行的 Plan-and-Execute 模式。