记忆管理三板斧:窗口、摘要与混合策略
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们从一个多轮对话失败的场景切入,讲清楚了 Agent 为什么需要记忆——大模型没有持久记忆,它的记忆完全取决于你在 messages 数组里放了什么。然后用 ChatMemory 接口和 InMemoryChatMemory 给 TinyAgent 装上了最基础的短期记忆,让它在同一个会话里能记住之前聊过的内容。
但上一篇的结尾也埋了一个问题:InMemoryChatMemory 只追加、不删减。用户聊 5 轮没事,聊 20 轮历史消息就开始膨胀,Token 预算被大量无关的历史信息占据,Agent 能做有用工作的空间越来越小。
这一篇,咱们正式动手解决这个问题——实现三种记忆管理策略:滑动窗口、摘要压缩、混合策略,让记忆可控、可配、不爆预算。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.6.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
记忆膨胀到底有多严重
先用比特严选的实际场景算一笔账。
假设一个用户打开客服窗口,连续咨询了几个问题:
第 1 轮:帮我查一下订单 88231 的物流
第 2 轮:那我要退款呢,这个扫地机不回充了
第 3 轮:退款多久到账?
第 4 轮:你们有没有新款扫地机推荐一下
第 5 轮:S20 Pro 和 S20 Max 有什么区别
第 6 轮:S20 Pro 现在有活动吗
第 7 轮:帮我下个单吧
每轮对话产生的消息包括用户输入和 Agent 回复。保守估计,每轮平均 400-600 个 Token(用户输入约 50 Token,Agent 回复约 200-400 Token,工具调用结果如果也存到记忆里还要更多)。
| 轮次 | 单轮 Token(估) | 累计历史 Token | 占 8000 预算比例 |
|---|---|---|---|
| 第 1 轮 | 500 | 500 | 6% |
| 第 3 轮 | 500 | 1,500 | 19% |
| 第 5 轮 | 500 | 2,500 | 31% |
| 第 7 轮 | 500 | 3,500 | 44% |
| 第 10 轮 | 500 | 5,000 | 63% |
| 第 15 轮 | 500 | 7,500 | 94% |
到第 15 轮,光历史消息就吃掉了 94% 的 Token 预算。再加上系统提示词(约 200 Token)和当前轮次的工具调用,Token 预算直接爆掉——TokenBudget 检测到超限,Agent 还没开始干活就被迫终止了。
更关键的是,用户到第 7 轮问的是“帮我下个单”,跟前 2 轮的物流和退款已经没什么关系了。但那 1000 多 Token 的物流和退款历史还挂在记忆里,白白占着预算,还会分散大脑的注意力。
记忆不是越多越好,而是越精准越好。 接下来实现的三种策略,核心目标都是一个:在有限的 Token 预算内,尽可能保留对当前任务有用的信息。
策略一:滑动窗口
1. 原理
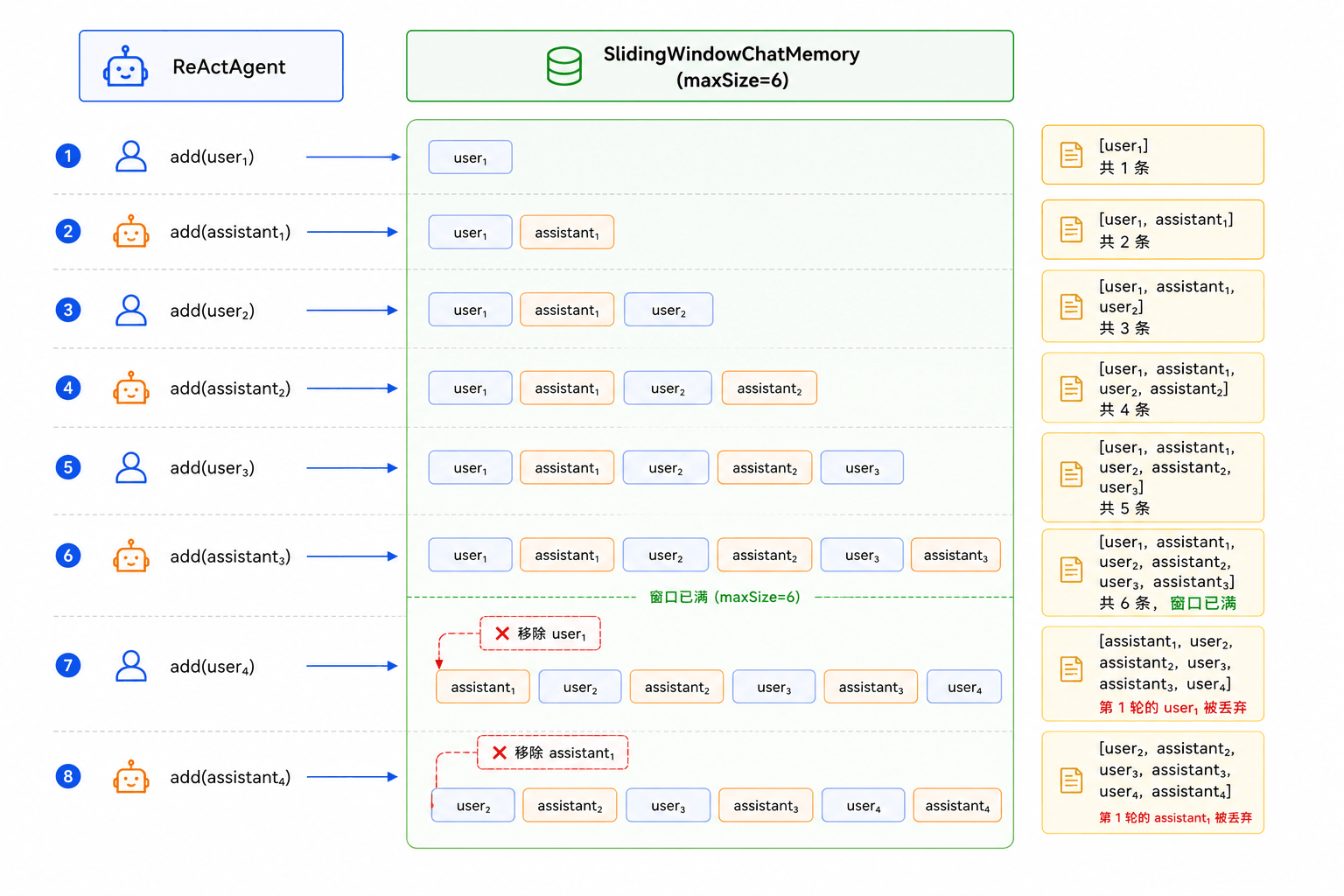
滑动窗口是最简单直观的策略——只保留最近 N 条消息,超过的自动丢弃。
打个比方:就像手机聊天记录的显示窗口,你只能看到最近几屏的内容,更早的需要往上翻。滑动窗口记忆干脆不让你翻了——超出窗口的直接扔掉。
窗口大小 N = 6
第 1 轮后:[user₁, assistant₁] → 2 条,未超限
第 2 轮后:[user₁, assistant₁, user₂, assistant₂] → 4 条,未超限
第 3 轮后:[user₁, assistant₁, user₂, assistant₂, user₃, assistant₃] → 6 条,刚好
第 4 轮后:[user₂, assistant₂, user₃, assistant₃, user₄, assistant₄] → 丢弃第 1 轮
第 4 轮开始,窗口满了,每加一条新消息就要从头部丢一条旧消息。到第 4 轮时,第 1 轮关于查物流的对话已经被丢弃——Agent 不再记得用户最初问过物流。
2. 流程图示
3. Java 实现
public class SlidingWindowChatMemory implements ChatMemory {
private final List<ChatMessage> messages = new ArrayList<>();
private final int maxSize;
public SlidingWindowChatMemory(int maxSize) {
if (maxSize < 2) {
throw new IllegalArgumentException("窗口大小至少为 2(一轮对话需要 user + assistant)");
}
this.maxSize = maxSize;
}
@Override
public void add(ChatMessage message) {
messages.add(message);
while (messages.size() > maxSize) {
messages.remove(0);
}
}
@Override
public List<ChatMessage> messages() {
return Collections.unmodifiableList(messages);
}
@Override
public void clear() {
messages.clear();
}
}
实现非常简单——add() 的时候检查是否超过 maxSize,超了就从头部移除。while 而不是 if,因为理论上可以一次性被调用多次 add()(虽然正常流程不会),用 while 更安全。
maxSize的单位是消息条数,不是对话轮数。一轮对话通常包含 1 条 user 消息和 1 条 assistant 消息,所以maxSize = 6大约保留最近 3 轮对话。如果你想按轮数控制,maxSize = 轮数 × 2即可。
4. maxSize 设多少合适
| 场景 | 建议 maxSize | 保留轮数 | 说明 |
|---|---|---|---|
| 简单问答(查订单、查物流) | 4 | 2 轮 | 任务独立性强,很少跨轮引用 |
| 退款 / 售后流程 | 8-10 | 4-5 轮 | 需要记住订单号、商品信息、政策 |
| 故障诊断 | 12-16 | 6-8 轮 | 需要记住已排除的步骤 |
| 跨品类推荐 | 10-14 | 5-7 轮 | 需要记住偏好、预算、已推荐商品 |
比特严选的客服场景,大多数任务在 5 轮内完成,maxSize = 10 是一个比较均衡的选择。
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 实现极简,几行代码搞定 | 超出窗口的信息彻底丢失,无法恢复 |
| Token 消耗完全可控,上限固定 | 窗口边界是硬切的,可能切在一个任务中间 |
| 没有额外的 LLM 调用开销 | 无法区分重要和不重要的消息,一视同仁丢弃 |
| 延迟稳定,不会因为历史过长而变慢 | 用户引用早期内�容时 Agent 会失忆 |
滑动窗口适合任务独立性强、对话较短的场景。如果用户经常在第 8 轮引用第 1 轮的内容(比如“我刚开始说的那个订单呢”),滑动窗口就会出问题——第 1 轮的信息已经被窗口滑走了。
策略二:摘要压缩
1. 原理
滑动窗口的问题是信息丢失——超出窗口的历史直接没了。摘要压缩的思路不同:不是丢掉旧消息,而是把旧消息压缩成一段摘要。
用一句话概括:把 10 句话变成 1 句话,信息量损失一些,但关键信息保留下来。
还是用比特严选的场景举例:
原始历史消息(4 轮,约 2000 Token):
user: 帮我查一下订单 88231 的物流
assistant: 您的比特 S10 Pro 扫地机已到达杭州转运中心...
user: 那我要退款呢,这个扫地机不回充了
assistant: 已为您提交退款申请,退款编号 RF20260629001...
user: 退款多久到账?
assistant: 退款将在 3-5 个工作日内原路退回...
user: 你们有没有新款扫地机推荐一下
assistant: 目前有 S20 Pro 和 S20 Max 两款...
压缩后的摘要(约 200 Token):
[对话摘要] 用户查询了订单 88231(比特 S10 Pro 扫地机),物流已签收。
因扫地机不回充问题申请退款(编号 RF20260629001),退款 3-5 个工作日到账。
随后咨询新款扫地机,已推荐 S20 Pro 和 S20 Max。
2000 Token 压缩到 200 Token,省了 90% 的空间,但关键信息都在——订单号、商品名、退款编号、推荐过的商品。如果用户后面问“刚才那个退款编号是多少”,Agent 从摘要里就能找到答案。
2. 触发时机
摘要压缩不是每条消�息都做——那样太频繁了,而且每次压缩都要调一次 LLM,有额外的延迟和成本。合理的做法是设一个阈值,消息条数超过阈值时触发一次压缩。
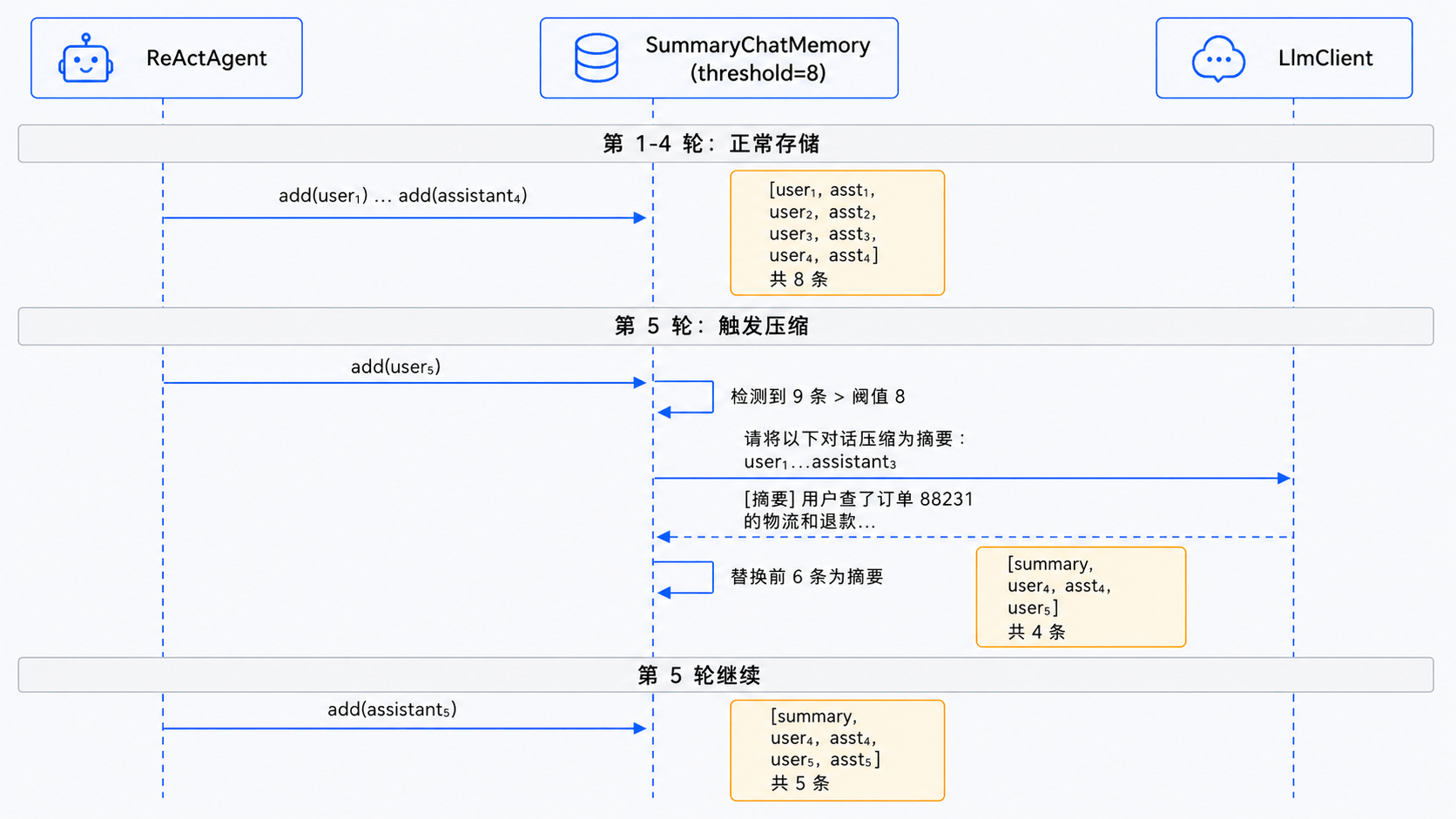
阈值 = 8 条消息,压缩后保留摘要 + 最近 2 条
第 1-4 轮(8 条消息):正常存储,不触发压缩
第 5 轮(add 第 9 条时):
→ 检测到超过 8 条
→ 把前 6 条(第 1-3 轮)发给 LLM 压缩成一段摘要
→ 记忆变成:[摘要, user₄, assistant₄, user₅]
→ 从 9 条变成 4 条
第 6-8 轮(又积累了 8 条):再次触发压缩
→ 把前面的摘要 + 中间几条一起压缩成新摘要
3. 流程图�示
4. Java 实现
摘要压缩需要调用 LLM 来生成摘要,所以 SummaryChatMemory 需要持有一个 LlmClient 的引用:
public class SummaryChatMemory implements ChatMemory {
private final List<ChatMessage> messages = new ArrayList<>();
private final int threshold;
private final int keepRecent;
private final LlmClient llmClient;
public SummaryChatMemory(LlmClient llmClient, int threshold, int keepRecent) {
if (threshold < 4) {
throw new IllegalArgumentException("阈值至少为 4(至少 2 轮对话才有压缩意义)");
}
if (keepRecent < 2) {
throw new IllegalArgumentException("至少保留 2 条最近消息(1 轮对话)");
}
if (keepRecent >= threshold) {
throw new IllegalArgumentException("保留条数必须小于阈值,否则永远不会触发压缩");
}
this.llmClient = llmClient;
this.threshold = threshold;
this.keepRecent = keepRecent;
}
@Override
public void add(ChatMessage message) {
messages.add(message);
if (messages.size() > threshold) {
compress();
}
}
@Override
public List<ChatMessage> messages() {
return Collections.unmodifiableList(messages);
}
@Override
public void clear() {
messages.clear();
}
private void compress() {
int compressEnd = messages.size() - keepRecent;
if (compressEnd <= 0) {
return;
}
List<ChatMessage> toCompress = new ArrayList<>(messages.subList(0, compressEnd));
List<ChatMessage> toKeep = new ArrayList<>(messages.subList(compressEnd, messages.size()));
String summary = callLlmForSummary(toCompress);
messages.clear();
messages.add(ChatMessage.system("[对话摘要] " + summary));
messages.addAll(toKeep);
}
private String callLlmForSummary(List<ChatMessage> toCompress) {
ObjectMapper objectMapper = llmClient.getObjectMapper();
ArrayNode apiMessages = objectMapper.createArrayNode();
ObjectNode systemMsg = apiMessages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content",
"你是一个对话摘要助手。请将以下客服对话压缩为简洁的摘要,"
+ "保留关键信息(订单号、商品名、金额、操作结果、用户诉求),"
+ "去掉寒暄和重复内容。输出纯文本摘要,不要加任何格式标记。");
StringBuilder conversation = new StringBuilder();
for (ChatMessage msg : toCompress) {
switch (msg.role()) {
case USER -> conversation.append("用户:").append(msg.content()).append("\n");
case ASSISTANT -> conversation.append("客服:").append(msg.content()).append("\n");
case SYSTEM -> conversation.append("系统信息:").append(msg.content()).append("\n");
default -> { }
}
}
ObjectNode userMsg = apiMessages.addObject();
userMsg.put("role", "user");
userMsg.put("content", "请压缩以下对话:\n\n" + conversation);
ChatResponse response = llmClient.chatWithTools(apiMessages, objectMapper.createArrayNode());
return response.content() != null ? response.content() : "";
}
}
几个关键设计决策说一下:
threshold 和 keepRecent 的分工:threshold 控制什么时候触发压缩(消息条数超过这个值),keepRecent 控制压缩时保留多少条最近的原始消息不动。比如 threshold = 8, keepRecent = 4,意味着消息超过 8 条时,把前面的压缩成摘要,保留最近 4 条原文。
摘要存为 SYSTEM 角色:压缩后的摘要以 ChatMessage.system("[对话摘要] ...") 的形式存储。为什么用 SYSTEM 而不是 USER 或 ASSISTANT?因为摘要不是用户说的话,也不是 Agent 的回复,而是一段背景信息——用 SYSTEM 角色放在消息列表开头,大脑会把它当做上下文参考,而不是当做对话的一部分。
摘要提示词的设计:提示词里明确要求保留订单号、商品名、金额、操作结果、用户诉求这些关键信息。这是根据比特严选的业务特点定制的——如果你的场景不同(比如医疗问诊),要保留的关键信息也不同。
你可能会担心:摘要本身的质量靠谱吗?会不会丢掉重要信息?这确实是摘要压缩的核心风险。实践中的经验是——用主流模型做短对话摘要(5-10 轮),关键信息的保留率很高,因为对话本身就是结构化的(问-答-问-答),模型很容易提取关键信息。但如果对话超长(30 轮以上),建议分段压缩而不是一次性压缩,避免遗漏。
5. 摘要压缩的参数选择
| 参数 | 建议值 | 说明 |
|---|---|---|
| threshold | 8-12 | 太小会频繁压缩(增加延迟和成本),太大会积累太多历史 |
| keepRecent | 4-6 | 太小会导致最近的上下文不够,太大则压缩效果不明显 |
| 摘要模型 | 与主模型相同或更轻量 | 摘要是辅助任务,可以用更便宜的模型 |
对于比特严选,threshold = 10, keepRecent = 4 是一个不错的起点:积累 5 轮对话后触发压缩,保留最近 2 轮的原文。
6. 优缺点
| 优点 | 缺点 |
|---|---|
| 保留了早期对话的关键信息,不会彻底失忆 | 每次压缩需要额外调一次 LLM,增加延迟和成本 |
| Token 消耗可控,摘要通常比原文短 80-90% | 摘要可能丢失细节(如具体的工具调用参数) |
| 支持渐进式压缩,摘要可以叠加更新 | 实现比滑动窗口复杂,需要持有 LlmClient |
| 适合长对话场景 | 摘要质量��依赖 LLM,极端情况下可能不准 |
策略三:混合策略
1. 原理
滑动窗口简单但会丢信息,摘要压缩保留信息但有额外成本。有没有办法把两者的优点结合起来?
混合策略的思路是:最近 N 条消息保持原文(像滑动窗口),更早的消息压缩成摘要(像摘要压缩)。
打个比方:你去看病,医生的电脑上有两部分信息——一部分是你今天的就诊记录原文(最近的,详细的),另一部分是你过往的病历摘要(早期的,概括的)。这就是混合策略。
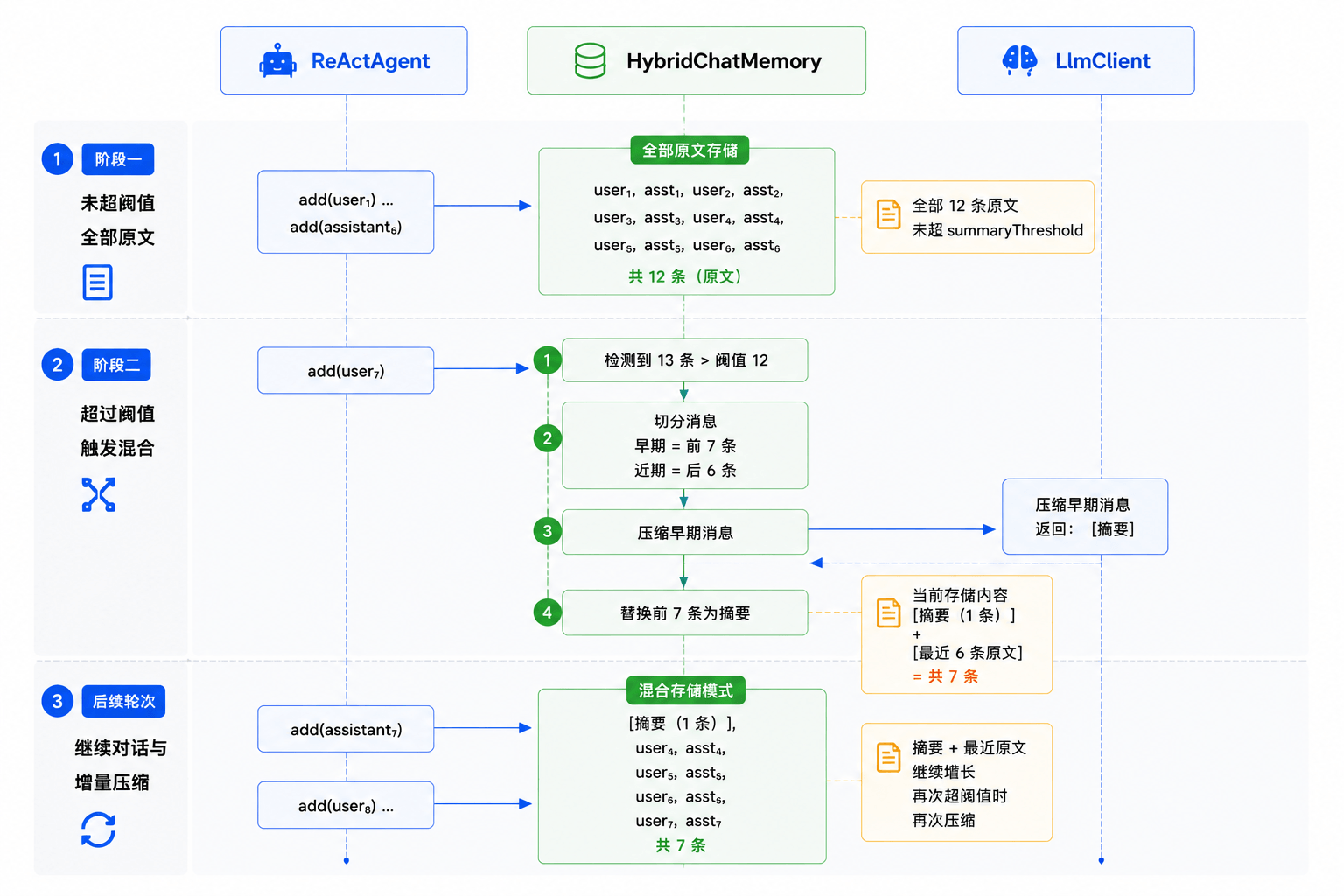
混合策略(recentSize=6, summaryThreshold=12)
第 1-3 轮(6 条消息):全部保持原文
[user₁, assistant₁, user₂, assistant₂, user₃, assistant₃]
第 4-6 轮(12 条消息):全部保持原文,未超阈值
[user₁, assistant₁, ..., user₆, assistant₆]
第 7 轮(add 第 13 条时):超过阈值,触发压缩
→ 保留最近 6 条原文(第 4-6 轮)
→ 更早的 6 条(第 1-3 轮)压缩成摘要
→ 结果:[摘要, user₄, assistant₄, user₅, assistant₅, user₆, assistant₆, user₇]
这样 Agent 在处理第 7 轮问题时,既能看到最近几轮的完整上下文(精确的指代消解),又能从摘要里找到早期的关键信息(订单号、已做过的操作)。
2. 流程图示
3. Java 实现
public class HybridChatMemory implements ChatMemory {
private final List<ChatMessage> messages = new ArrayList<>();
private final int recentSize;
private final int summaryThreshold;
private final LlmClient llmClient;
public HybridChatMemory(LlmClient llmClient, int recentSize, int summaryThreshold) {
if (recentSize < 2) {
throw new IllegalArgumentException("近期窗口至少为 2");
}
if (summaryThreshold <= recentSize) {
throw new IllegalArgumentException("摘要阈值必须大于近期窗口大小");
}
this.llmClient = llmClient;
this.recentSize = recentSize;
this.summaryThreshold = summaryThreshold;
}
@Override
public void add(ChatMessage message) {
messages.add(message);
if (messages.size() > summaryThreshold) {
compressOlderMessages();
}
}
@Override
public List<ChatMessage> messages() {
return Collections.unmodifiableList(messages);
}
@Override
public void clear() {
messages.clear();
}
private void compressOlderMessages() {
int compressEnd = messages.size() - recentSize;
if (compressEnd <= 0) {
return;
}
List<ChatMessage> olderMessages = new ArrayList<>(messages.subList(0, compressEnd));
List<ChatMessage> recentMessages = new ArrayList<>(messages.subList(compressEnd, messages.size()));
String existingSummary = extractExistingSummary(olderMessages);
String newSummary = callLlmForSummary(olderMessages, existingSummary);
messages.clear();
messages.add(ChatMessage.system("[对话摘要] " + newSummary));
messages.addAll(recentMessages);
}
private String extractExistingSummary(List<ChatMessage> olderMessages) {
for (ChatMessage msg : olderMessages) {
if (msg.role() == ChatMessage.Role.SYSTEM
&& msg.content() != null
&& msg.content().startsWith("[对话摘要]")) {
return msg.content().substring("[对话摘要] ".length());
}
}
return null;
}
private String callLlmForSummary(List<ChatMessage> toCompress, String existingSummary) {
ObjectMapper objectMapper = llmClient.getObjectMapper();
ArrayNode apiMessages = objectMapper.createArrayNode();
ObjectNode systemMsg = apiMessages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content",
"你是一个对话摘要助手。请将以下客服对话压缩为简洁的摘要,"
+ "保留关键信息(订单号、商品名、金额、操作结果、用户诉求),"
+ "去掉寒暄和重复内容。输出纯文本摘要,不要加任何格式标记。");
StringBuilder conversation = new StringBuilder();
if (existingSummary != null) {
conversation.append("之前的对话摘要:\n").append(existingSummary).append("\n\n");
conversation.append("后续新增的对话:\n");
}
for (ChatMessage msg : toCompress) {
if (msg.role() == ChatMessage.Role.SYSTEM
&& msg.content() != null
&& msg.content().startsWith("[对话摘要]")) {
continue;
}
switch (msg.role()) {
case USER -> conversation.append("用户:").append(msg.content()).append("\n");
case ASSISTANT -> conversation.append("客服:").append(msg.content()).append("\n");
default -> { }
}
}
ObjectNode userMsg = apiMessages.addObject();
userMsg.put("role", "user");
userMsg.put("content",
"请将以下内容整合成一段完整的对话摘要:\n\n" + conversation);
ChatResponse response = llmClient.chatWithTools(apiMessages, objectMapper.createArrayNode());
return response.content() != null ? response.content() : "";
}
}
跟纯摘要压缩相比,混合策略多了两个关键设计:
recentSize 和 summaryThreshold 的分工:recentSize 控制保留多少条最近的原文消息(这些消息永远不会被压缩),summaryThreshold 控制总消息条数达到多少时触发一次压缩。两者的差值就是每次被压缩的消息数量。
渐进式摘要:extractExistingSummary() 会检查旧消息里是否已经有一个摘要。如果有,就把已有摘要和新增的对话一起发给 LLM,生成一个合并后的新摘要——而不是丢弃旧摘要从头压缩。这样不管对话进行多少轮,摘要都是增量更新的,早期的关键信息不会在多次压缩中逐渐丢失。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 最近对话保持原文,指代消解准确 | 实现最复杂,参数调优有一定门槛 |
| 早期对话通过摘要保留关键信息 | 同样需要额外的 LLM 调用 |
| Token 消耗可控,兼顾近期精确和远期概览 | 渐进式摘要可能在多次压缩后信息衰减 |
| 生产环境推荐方案 | 压缩触发时有一次性延迟 |
三种策略全景对比
到这里三种策略都实现了,放在一起做一个全景对比:
| 维度 | 滑动窗口 | 摘要压缩 | 混合策略 |
|---|---|---|---|
| 实现复杂度 | 低(10 行代码) | 中(需要 LLM 调用) | 高(LLM + 双区管理) |
| Token 控制 | 精确(固定上限) | 较好(摘要长度可控) | 较好(窗口 + 摘要) |
| 信息保留 | 差(超出窗口的彻底丢失) | 较好(摘要保留关键信息) | 好(近期精确 + 远期概览) |
| 额外延迟 | 无 | 有(压缩时调 LLM) | 有(压缩时调 LLM) |
| 额外成本 | 无 | 有(每次压缩一次 LLM 调用) | 有(每次压缩一次 LLM 调用) |
| 适用场景 | 短对话、任务独立 | 中长对话、需要保留早期信息 | 长对话、生产环境推荐 |
怎么选?一个简单的决策路径:
- 对话通常不超过 5 轮 → 滑动窗口就够了,简单好用。
- 对话经常超过 5 轮,且用户会引用早期内容 → 摘要压缩或混合策略。
- 生产环境、需要稳健的记忆管理 → 混合策略。
比特严选的客服场景,大部分对话在 5 轮以内(查订单、查物流、退款),但也有少数复杂场景会超过 10 轮(故障诊断、跨品类推荐)。如果只能选一个,混合策略是最稳妥的选择——短对话时它退化成纯原文存储(因为没触发压缩阈值),长对话时自动切入压缩模式。
改造 ReActAgent:支持可插拔记忆
三种记忆策略都实现了 ChatMemory 接口,ReActAgent 不需要任何改动——这就是接口抽象的价值。
使用不同策略,只需要在构造时传入不同的实现:
// 策略一:滑动窗口(保留最近 5 轮对话)
ChatMemory memory1 = new SlidingWindowChatMemory(10);
ReActAgent agent1 = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory1);
// 策略二:摘要压缩(超过 10 条消息时压缩,保留最近 4 条原文)
ChatMemory memory2 = new SummaryChatMemory(llmClient, 10, 4);
ReActAgent agent2 = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory2);
// 策略三:混合策略(最近 6 条保持原文,超过 12 条时压缩早期消息)
ChatMemory memory3 = new HybridChatMemory(llmClient, 6, 12);
ReActAgent agent3 = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory3);
这三行代码切换记忆策略,ReActAgent 的 run() 方法一行都不用改。
这就是上一篇为什么选择把记忆放在 Agent 外部、通过接口注入的原因。如果当时把记忆逻辑直接写在
ReActAgent内部,现在要换策略就得改 Agent 的代码——而 Agent 的循环逻辑跟记忆管理是两件事,不应该耦合在一起。
Demo:用混合策略跑长对话
用混合策略跑一个稍长的对话场景,看看压缩是怎么自动触发的:
public static void main(String[] args) {
ToolRegistry toolRegistry = new ToolRegistry();
toolRegistry.register(new QueryOrderTool());
toolRegistry.register(new QueryLogisticsTool());
toolRegistry.register(new ApplyRefundTool());
toolRegistry.register(new SearchKnowledgeTool());
toolRegistry.register(new GetCurrentTimeTool());
Properties dotEnv = loadDotEnv();
LlmClient llmClient = new LlmClient(
setting(dotEnv, "TINYAGENT_API_URL", "..."),
requiredSetting(dotEnv, "TINYAGENT_API_KEY"),
setting(dotEnv, "TINYAGENT_MODEL", "deepseek-v4-pro")
);
// 混合策略:最近 6 条保持原文,超过 10 条时压缩
ChatMemory memory = new HybridChatMemory(llmClient, 6, 10);
ReActAgent agent = new ReActAgent(llmClient, toolRegistry, 10, 8000, memory);
System.out.println("========== 第 1 轮 ==========");
agent.run("帮我查一下订单 88231 的物流到哪了");
System.out.println("\n\n========== 第 2 轮 ==========");
agent.run("那我要退款呢,这个扫地机不回�充了");
System.out.println("\n\n========== 第 3 轮 ==========");
agent.run("退款多久到账?");
System.out.println("\n\n========== 第 4 轮 ==========");
agent.run("你们有没有新款扫地机推荐一下");
System.out.println("\n\n========== 第 5 轮 ==========");
agent.run("S20 Pro 多少钱");
System.out.println("\n\n========== 第 6 轮 ==========");
// 到这里已经超过 10 条消息,会触发压缩
// Agent 还能记住早期的退款信息吗?
agent.run("对了,刚才那个退款编号是多少来着");
// 打印当前记忆状态
System.out.println("\n===== 当前记忆状态 =====");
for (ChatMessage msg : memory.messages()) {
String preview = msg.content().length() > 80
? msg.content().substring(0, 80) + "..."
: msg.content();
System.out.println("[" + msg.role() + "] " + preview);
}
}
预期的行为:
- 前 5 轮正常对话,记忆不断增长。
- 第 6 轮
add(user₆)时,消息总数超过 10 条,触发压缩。 - 压缩过程:前面较早的消息(第 1-2 轮的物流查询和退款)被压缩成一段摘要,最近 6 条消息保持原文。
- 第 6 轮用户问“刚才那个退款编号是多少”,Agent 从摘要里找到退款编号 RF20260629001,正常回答。
最后打印的记忆状态类似:
===== 当前记忆状态 =====
[SYSTEM] [对话摘要] 用户查询了订单 88231(比特 S10 Pro 扫地机),物流已签收。因不回充问题申请退款...
[USER] S20 Pro 多少钱
[ASSISTANT] S20 Pro 的售价是 2499 元...
[USER] 对了,刚才那个退款编号是多少来着
[ASSISTANT] 您之前申请的退款编号是 RF20260629001...
可以看到,早期的 4 轮对话被压缩成了一条 SYSTEM 摘要消息,最近的对话保持原�文。即使压缩了,退款编号这个关键信息依然保留在摘要里。
记忆注入的注意事项
实现了记忆策略之后,还有几个工程细节值得注意:
1. 摘要消息在 messages 中的位置
上面的实现把摘要放在 messages 数组的最前面(紧跟 system 提示词之后)。这是有意为之——大模型处理消息列表时,靠前的消息会被当做背景信息,靠后的消息更像是当前正在进行的对话。摘要是历史概览,放在前面更合理。
messages 数组的最终结构:
[0] system: 系统提示词
[1] system: [对话摘要] 之前聊过什么... ← 摘要在 system 之后
[2] user: 最近的用户输入
[3] assistant: 最近的 Agent 回复
...
[N] user: 当前轮次的用户输入
但这里有一个细微的问题:ReActAgent.run() 在构建消息列表时,是先放 system 提示词,再遍历 chatMemory.messages() 注入历史。如果摘要以 SYSTEM 角色存储,它会在 system 提示词之后被注入——这是正确的位置。
2. 压缩的时机
当前实现是在 add() 时同步压缩——如果触发了压缩,add() 会阻塞等待 LLM 返回摘要。这意味着用户在等待的过程中,实际经历了两次 LLM 调用:一次压缩,一次 Agent 正常推理。
对于比特严选的客服场景,压缩通常只在长对话中偶尔触发一次,多等 1-2 秒可以接受。但如果你的场景对延迟极度敏感,可以考虑异步压缩——在后台线程执行压缩,当前轮次先用未压缩的记忆跑,下一轮开始时再用压缩后的结果。
3. 摘要也算 Token
一个容易被忽略的点:摘要本身也占 Token。虽然比原文短很多,但如果对话持续了 50 轮,经过多次渐进式压缩,摘要可能逐渐膨胀到几百甚至上千 Token。
在极端情况下,可以对摘要本身也做长度限制——比如摘要超过 500 Token 时,再调一次 LLM 做进一步压缩。但对于比特严选这种大多数会话在 10 轮以内的场景,这个问题基本不会出现。
文末总结
这一篇从记忆膨胀的实际问题出发,实现了三种记忆管理策略:
- 滑动窗口:只保留最近 N 条消息,超出的直接丢弃。实现极简(10 行代码),Token 完全可控,但早期信息彻底丢失。适合短对话、任务独立性强的场景。
- 摘要压缩:消息超过阈值时,调 LLM 把旧消息压缩成一段摘要。保留关键信息的同时大幅减少 Token 占用,但有额外的 LLM 调用成本和延迟。适合中长对话。
- 混合策略:最近 N 条保持原文 + 更早的做摘要。兼顾近期精确和远期概览,生产环境推荐方案。
三种策略都实现了 ChatMemory 接口,ReActAgent 无需任何修改,构造时传入不同实现即可切换——这是接口抽象在工程中的典型价值。
用一句话概括:记忆管理的核心不是记住所有东西,而是在有限的 Token 预算内,保留对当前任务最有价值的信息。