长期记忆:让 Agent 跨会话认识用户
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
前面几篇咱们一路走来,先给 TinyAgent 装上了短期记忆(ChatMemory 接口 + InMemoryChatMemory),又实现了三种记忆管理策略(滑动窗口、摘要压缩、混合策略),最后用 PostgreSQL 做了持久化(JdbcChatMemory + SessionManager),让会话记忆能跨重启保留、在不同用户之间互相隔离。
到目前为止,Agent 的记忆能力已经不错了——同一个会话里能记住之前聊过什么,服务重启也不怕丢,用户和会话之间互不干扰。但还有一个问题没解决:每个会话的记忆是孤立的。
假设一个用户今天上午在比特严选的客服窗口开了一个会话,聊了 6 轮,从查物流到退款到推荐新款扫地机,Agent 表现得像个老朋友——记得订单号、知道退款编号、推荐了 S20 Pro。用户满意地关了窗口。
第二天下午,这个用户又打开客服窗口,开了一个新会话,问了一句:
昨天那个退款到账了吗?
Agent 的回复:
请问您说的是哪个退款呢?能提供一下订单号吗?
用户昨天刚聊了 6 轮,Agent 今天就完全不认识他了。
这不是 Bug——JdbcChatMemory 忠实地把昨天的对话存在了数据库里,只要用户点开昨天那个会话,所有消息都能完整还原。问题在于,用户今天开的是一个新会话,新会话的消息列表是空的,Agent 自然什么都不知道。
会话记忆解决的是单次会话内的连贯性。要让 Agent 跨会话记住用户,需要长期记忆。
本项目中具体代码已上传 GitHub TinyAgent,大家 Clone 项目后,将代码分支切换到 1.8.x,默认主分支是最新代码。运行前复制
.env.example为.env,把自己的 API Key 填进去,默认阿里云百炼平台;.env已加入.gitignore,切分支时不会丢。
会话记忆 vs 长期记忆:边界在哪
先把两者的边界理清楚。
| 维度 | 会话记忆 | 长期记忆 |
|---|---|---|
| 生命周期 | 一次会话(开始到结束) | 跨会话持久化(天、周、月) |
| 存储介质 | 内存 / PostgreSQL(JdbcChatMemory) | Key-Value / 向量库 |
| 写入时机 | 每轮对话实时追加 | 会话结束时提炼关键信息 |
| 读取时机 | 每轮对话构建 messages 时注入 | 新会话开始时按相关性检索 |
| 内容粒度 | 原始消息(用户说了什么、Agent 回了什么) | 提炼后的结构化信息(用户偏好、交互记录) |
| Token 占用 | 随对话轮次线性增长 | 通常固定在几百 Token 以内 |
用一句话概括两者的关系:会话记忆管一次会话内的连贯性,长期记忆管跨会话的个性化。
打个比方:会话�记忆就像你跟朋友的一次电话通话——挂了电话,录音还在(JdbcChatMemory 帮你存着),下次想回顾可以翻出来。但如果你接到一通新电话,你不会自动想起上次聊了什么。长期记忆就像你对这个朋友的了解——他喜欢什么、最近在忙什么、上次帮他办了什么事——这些信息在你接起电话的瞬间就自动浮现在脑海里,不需要翻任何录音。
三层记忆的完整架构
加上之前几篇实现的能力,TinyAgent 的记忆体系现在有三层,各管各的:

有一个容易混淆的地方:会话摘要和交互记录不是一回事。
| 维度 | 会话摘要 | 交互记录 |
|---|---|---|
| 归属 | 会话级(属于某个 session) | 用户级(属于某个 user) |
| 写入时机 | 会话进行中,消息超过阈值时自动压缩 | 会话结束时,调大模型提炼一次 |
| 内容 | 对话的压缩版(为了省 Token) | 关键事件的富文本叙述(为了给未来会话用) |
| 谁管 | HybridChatMemory(第 11 篇) | UserProfileExtractor(本篇) |
| 生命周期 | 随会话存在 | 跨会话持久化,保留数周到数月 |
会话摘要解决的是“当前这通电话太长了,把前面说过的内容压缩一下”;交互记录解决的是“下次来电话时,快速回忆起上次聊了什么”。两者在不同层次解决不同问题,��互不替代。
在实际代码中,两者通过 PersistentHybridChatMemory 和 LongTermMemoryRetriever 分别管理,最终在 ReActAgent 的 messages 数组里各就各位:
messages 数组的完整结构:
[0] system: 系统提示词(你是比特严选的智能客服...)
[1] system: 长期记忆上下文(用户画像 + 相关交互记录) ← 长期记忆层
[2] system: [对话摘要](HybridChatMemory 压缩的) ← 会话记忆层
[3] user: 最近的用户输入(问题) ← 会话记忆层
[4] assistant: 最近的 Agent 回复 ← 会话记忆层
...
[N] user: 当前轮次的用户输入
这一篇聚焦在最上面那一层——长期记忆。会话记忆的持久化和压缩已经在前面的篇章里实现了,这里直接复用。
长期记忆要记什么
不是所有对话内容都值得存到长期记忆里。存太多,检索时噪音大、Token 浪费;存太少,等于没记。关键是只存对未来会话有用的信息。
以比特严选的客服场景为例,长期记忆分两类:
1. 用户画像
用户在多次交互中暴露出来的偏好和特征:
用户 A 的画像:
- 偏好品类:智能家居(扫地机、智能音箱)
- 价格敏感度:中等,预算通常 2000-3000 元
- 购买习惯:喜欢等促销活动下单
- 家庭场景:有老人,关注操作简便性
这类信息不是一次对话就能收集完的。用户第一次来问扫地机,你知道他对智能家居感兴趣;第二次来问智能音箱,你确认了他在组建智能家居生态;第三次来说给爸妈用的,你知道了他的家庭场景。画像是多次会话逐步积累的。
2. 交互记录
过去几次会话的完整叙述,每条记录里嵌入了具体数据:
用户 A 的交互记录:
- [2026-06-29] 用户因订单 88231 的比特 S10 Pro 扫地机(1999 元)出现无法回充的质量问题申请退款,退款编号 RF20260629001,预计 1-3 个工作日到账
- [2026-06-30] 用户对比了 S20 Pro(2999 元)和 S20 Max(3999 元),倾向 S20 Pro 但认为价格偏高
- [2026-07-01] 用户咨询了 S20 Pro 的促销活动,被告知 7 月中旬有满减活动
跟之前的摘要相比,区别在于:每条记录里都嵌入了具体数据——订单号 88231、退款编号 RF20260629001、金额 1999 元、商品型号 S10 Pro。这些数据不是单独存放的,而是作为叙述的一部分。当向量检索命中这条记录时,Agent 同时拿到了事件的上下文和所有相关数据。
有了这些,用户第四次来的时候说“那个扫地机的促销开始了吗”,Agent 通过向量检索命中第三条记录,直接知道他问的是 S20 Pro、7 月中旬的满减活动,不需要额外查任何 Key-Value。
3. 什么不该存
| 该存 | 不该存 |
|---|---|
| 用户偏好(品类、预算、风格) | 对话原文(太长、太冗余) |
| 交互记录(每次会话的完整叙述,包含具体数据) | 中间推理过程(Thought 链) |
| 用户反馈(投诉过什么、表扬过什么) | 工具调用的原始 JSON 返回 |
| 寒暄和闲聊内容 |
原则很简单:只存未来会话中可能用到的信息,丢掉过程性和临时性的东西。
记忆条目的数据模型
长期记忆不像会话记忆那样直接存原始消息,它需要一个更结构化的数据模型。每一条长期记忆可以抽象成一个 MemoryEntry:
public record MemoryEntry(
String key,
String content,
String userId,
String type,
long timestamp,
double[] embedding
) {
public static MemoryEntry of(String key, String content, String userId, String type) {
return new MemoryEntry(key, content, userId, type, System.currentTimeMillis(), null);
}
}
几个字段的含义:
key:记忆的唯一标识,用于精确查找。比如profile:user_10086或record:user_10086:1719648000000。content:记忆的文本内容。比如用户偏好智能家居,预算 2000-3000 元。userId:关联的用户 ID,一个用户的长期记忆跟别人的隔离。type:记忆类型——USER_PROFILE(用户画像)、INTERACTION_RECORD(交互记录)。timestamp:写入时间,用于按时间排序和过期清理。embedding:内容的向量表示,向量检索时用。用户画像不需要这个字段,传null即可。
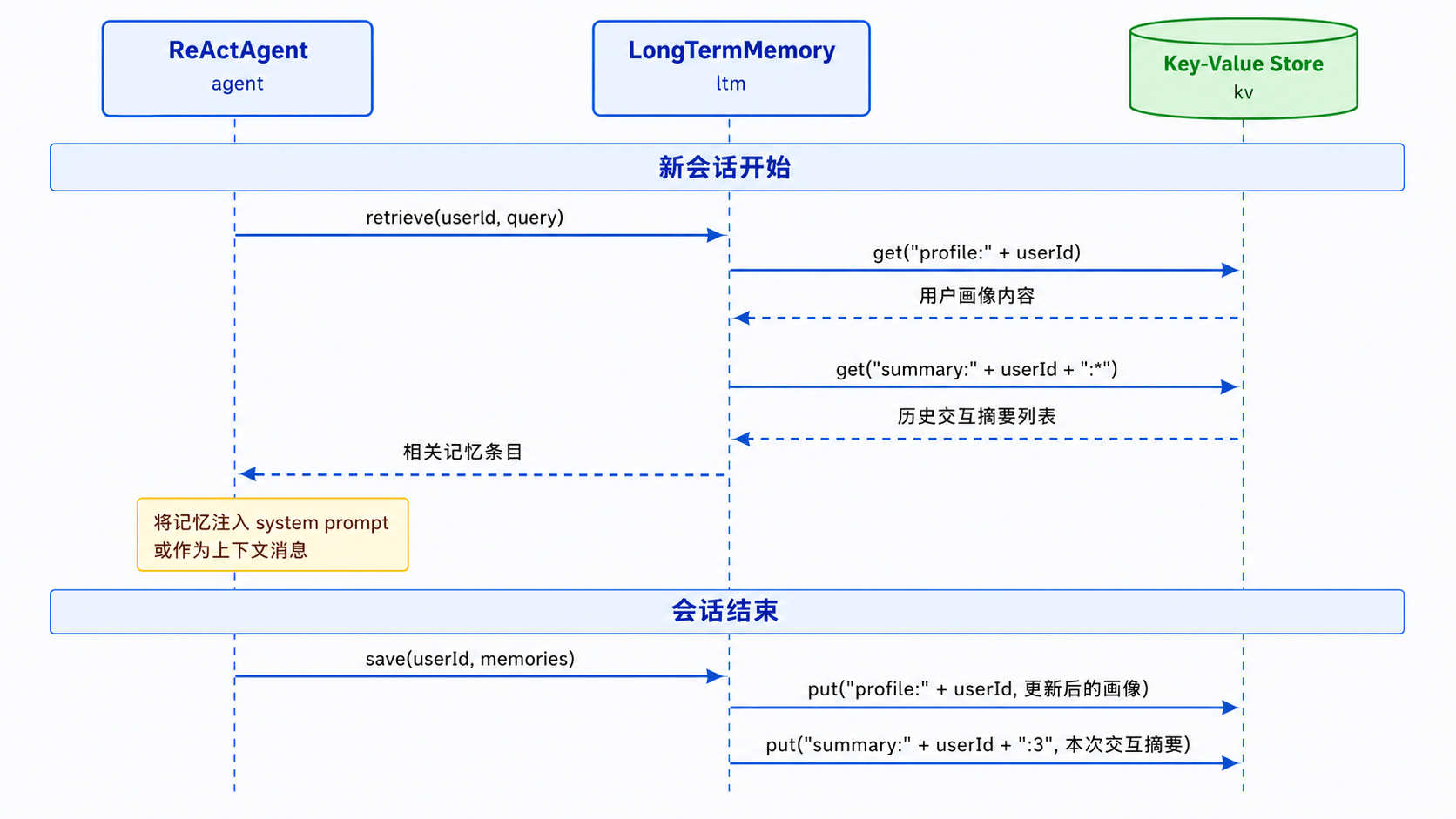
存储方案一:Key-Value 存储
1. 原理
最直观的存储方式——用一个 Map 把记忆条目存起来,按 key 精确查找。
打个比方:Key-Value 存储就像一个文件柜,每个抽屉上贴着标签(key),你知道要找什么就直接拉对应的抽屉。
Key-Value 存储结构:
profile:user_10086 → 偏好智能家居,预算 2000-3000 元,家有老人,对产品质量敏感
检索时,你需要知道要查什么 key——比如查用户画像就用 profile:{userId}。
2. 流程图示
3. Java 实现
先定义 LongTermMemory 接口:
public interface LongTermMemory {
void save(MemoryEntry entry);
List<MemoryEntry> retrieve(String userId, String query, int topK);
void delete(String key);
}
三个方法:save() 存一条记忆,retrieve() 按用户和查询条件检索最多 topK 条相关记忆,delete() 按 key 删除。
Key-Value 实现——直接复用上一篇的 memory_entry 表,存的时候不填 embedding 列,查的时候按 key 前缀匹配:
public class PgKeyValueLongTermMemory implements LongTermMemory {
private final DataSource dataSource;
public PgKeyValueLongTermMemory(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void save(MemoryEntry entry) {
String sql = "INSERT INTO memory_entry (key, content, user_id, type) "
+ "VALUES (?, ?, ?, ?) "
+ "ON CONFLICT (key) DO UPDATE SET content = EXCLUDED.content, "
+ "created_at = CURRENT_TIMESTAMP";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, entry.key());
ps.setString(2, entry.content());
ps.setString(3, entry.userId());
ps.setString(4, entry.type());
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("保存记忆失败", e);
}
}
@Override
public List<MemoryEntry> retrieve(String userId, String query, int topK) {
String sql = "SELECT key, content, user_id, type, created_at "
+ "FROM memory_entry "
+ "WHERE user_id = ? AND key LIKE ? "
+ "ORDER BY created_at DESC "
+ "LIMIT ?";
List<MemoryEntry> results = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, userId);
ps.setString(2, query + ":%");
ps.setInt(3, topK);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
results.add(new MemoryEntry(
rs.getString("key"),
rs.getString("content"),
rs.getString("user_id"),
rs.getString("type"),
rs.getTimestamp("created_at").getTime(),
null
));
}
}
} catch (SQLException e) {
throw new RuntimeException("检索记忆失败", e);
}
return results;
}
@Override
public void delete(String key) {
String sql = "DELETE FROM memory_entry WHERE key = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, key);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("删除记忆失败", e);
}
}
}
�几个关键点:
跟 PgVectorLongTermMemory 共用同一张 memory_entry 表:KV 存的记忆没有向量(embedding 列为 NULL),向量存的记忆带向量。同一张表,两种查询方式。
save() 不填 embedding:SQL 里只 INSERT 了 key、content、user_id、type 四个字段,embedding 列自动为 NULL。
retrieve() 按 key 前缀匹配:query 参数传的是前缀(如 profile),SQL 用 key LIKE 'profile:%' 来过滤。这样 retrieve(userId, “profile”, 1) 就只返回画像。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单,复用已有的 PostgreSQL | 只能精确匹配或前缀匹配,不支持语义检索 |
| 数据持久化,进程重启不丢失 | 检索依赖 key 的设计,key 设计不好就查不到 |
| 不需要 Embedding 模型,零额外成本 | 无法处理模糊查询(如”用户之前买过什么”) |
| 适合结构化的用户画像 | key 前缀查询在数据量大时需要索引优化 |
Key-Value 存储适合你明确知道要查什么的场景——查用户画像用 profile:{userId}。但如果用户说了一句”我之前问过一个智能音箱的事”,你不知道该用什么 key 去查,Key-Value 就无能为力了。
存储方案二:向量检索
1. 原理
向量检索的思路完全不同:不是按 key 精确匹配,而是把记忆内容转成向量,用语义相似度来检索。
这个套路你在 RAG 系列里已经见过了——Embedding 模型把文本转成向量,存到向量库里,查询时把 query 也转成向量,算余弦相似度找最相关的。长期记忆的向量检索,本质上就是对记忆条目做 RAG。
存储时:
记忆内容:用户偏好智能家居,预算 2000-3000 元,家有老人关注操作简便
→ Embedding → [0.12, -0.34, 0.56, ...] → 存入向量库
检索时:
用户说:“有没有适合老人用的智能音箱”
→ Embedding → [0.11, -0.31, 0.52, ...]
→ 余弦相似度 → 命中上面那条记忆(相似度 0.91)
用户没有提到预算,也没有提到智能家居,但向量检索能从语义上理解“适合老人用”跟“家有老人关注操作简便”是相关的——这是 Key-Value 做不到的。
2. 流程图示
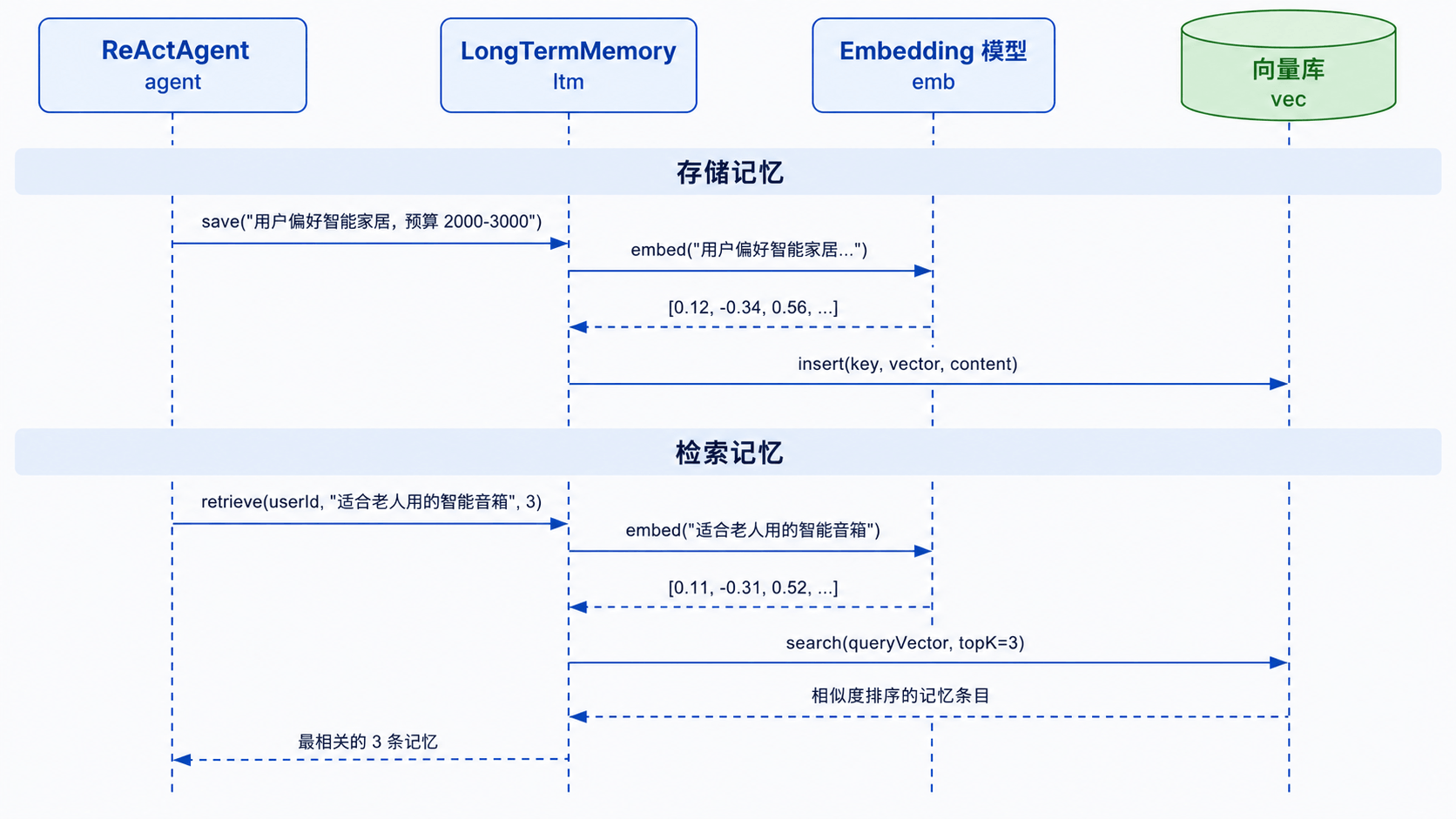
3. 表设计与 Java 实现
上一篇搭 PostgreSQL 环境时,咱们专门用了 pgvector/pgvector:pg16 镜像——现在正好用上。先启用 pgvector 扩展,再建一张 memory_entry 表存长期记忆:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS memory_entry (
key VARCHAR(256) PRIMARY KEY,
content TEXT NOT NULL,
user_id VARCHAR(64) NOT NULL,
type VARCHAR(32) NOT NULL,
embedding vector(1024),
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX IF NOT EXISTS idx_memory_entry_user_id ON memory_entry(user_id);
几个设计要点:
embedding 列用 vector(1024):这是 pgvector 提供的向量类型,1024 是向量维度,需要跟 Embedding 模型的输出维度一致。本项目用的阿里云 text-embedding-v3 默认输出 1024 维。
主键用 key:每条记忆有唯一标识,比如 profile:user_10086 或 record:user_10086:1719648000000。存储时用 ON CONFLICT DO UPDATE 实现 upsert——同 key 的记忆更新内容和向量,不会重复插入。
然后实现 EmbeddingClient,负责调 Embedding API 把文本转成向量:
public class EmbeddingClient {
private final OkHttpClient httpClient;
private final ObjectMapper objectMapper;
private final String apiUrl;
private final String apiKey;
private final String model;
public EmbeddingClient(String apiUrl, String apiKey, String model) {
this.apiUrl = apiUrl;
this.apiKey = apiKey;
this.model = model;
this.objectMapper = new ObjectMapper();
this.httpClient = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.build();
}
public double[] embed(String text) {
try {
ObjectNode requestBody = objectMapper.createObjectNode();
requestBody.put("model", model);
requestBody.put("input", text);
Request request = new Request.Builder()
.url(apiUrl)
.addHeader("Authorization", "Bearer " + apiKey)
.post(RequestBody.create(
requestBody.toString(),
MediaType.get("application/json; charset=utf-8")))
.build();
try (Response response = httpClient.newCall(request).execute()) {
String responseText = response.body() != null ? response.body().string() : "";
if (!response.isSuccessful()) {
throw new RuntimeException("Embedding API 调用失败:" + response.code());
}
JsonNode json = objectMapper.readTree(responseText);
JsonNode embeddingNode = json.at("/data/0/embedding");
double[] vector = new double[embeddingNode.size()];
for (int i = 0; i < embeddingNode.size(); i++) {
vector[i] = embeddingNode.get(i).asDouble();
}
return vector;
}
} catch (IOException e) {
throw new RuntimeException("Embedding 调用失败:" + e.getMessage(), e);
}
}
}
这跟 RAG 系列里用过的 Embedding 调用是一样的套路——POST 请求发到 Embedding API,解析返回的向量数组。
最后实现基于 pgvector 的长期记忆:
public class PgVectorLongTermMemory implements LongTermMemory {
private final DataSource dataSource;
private final EmbeddingClient embeddingClient;
public PgVectorLongTermMemory(DataSource dataSource, EmbeddingClient embeddingClient) {
this.dataSource = dataSource;
this.embeddingClient = embeddingClient;
}
@Override
public void save(MemoryEntry entry) {
double[] embedding = embeddingClient.embed(entry.content());
String vectorStr = toVectorString(embedding);
String sql = "INSERT INTO memory_entry (key, content, user_id, type, embedding) "
+ "VALUES (?, ?, ?, ?, ?::vector) "
+ "ON CONFLICT (key) DO UPDATE SET content = EXCLUDED.content, "
+ "embedding = EXCLUDED.embedding, created_at = CURRENT_TIMESTAMP";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, entry.key());
ps.setString(2, entry.content());
ps.setString(3, entry.userId());
ps.setString(4, entry.type());
ps.setString(5, vectorStr);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("保存记忆失败", e);
}
}
@Override
public List<MemoryEntry> retrieve(String userId, String query, int topK) {
double[] queryVector = embeddingClient.embed(query);
String vectorStr = toVectorString(queryVector);
String sql = "SELECT key, content, user_id, type, created_at "
+ "FROM memory_entry "
+ "WHERE user_id = ? AND embedding IS NOT NULL "
+ "ORDER BY embedding <=> ?::vector "
+ "LIMIT ?";
List<MemoryEntry> results = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, userId);
ps.setString(2, vectorStr);
ps.setInt(3, topK);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
results.add(new MemoryEntry(
rs.getString("key"),
rs.getString("content"),
rs.getString("user_id"),
rs.getString("type"),
rs.getTimestamp("created_at").getTime(),
null
));
}
}
} catch (SQLException e) {
throw new RuntimeException("检索记忆失败", e);
}
return results;
}
@Override
public void delete(String key) {
String sql = "DELETE FROM memory_entry WHERE key = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setString(1, key);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("删除记忆失败", e);
}
}
// ......
}
几个关键设计说一下:
save() 用 upsert:INSERT ... ON CONFLICT DO UPDATE 保证同 key 的记忆直接更新,不会产生重复数据。存储前先调 EmbeddingClient 把内容转成向量。
retrieve() 用余弦距离排序:<=> 是 pgvector 的余弦距离算子,值越小表示越相似。ORDER BY embedding <=> ?::vector 就是按语义相似度从高到低排列。余弦相似度的概念在 RAG 系列里已经讲过了——两个向量越相似,余弦值越接近 1,距离越接近 0。
toVectorString() 做格式转换:pgvector 接收的向量格式是 [0.12, -0.34, 0.56, ...] 这样的字符串,通过 ?::vector 转成 pgvector 的内部类型。
当记忆条数超过几万条时,可以给
embedding列加一个 HNSW 索引来加速检索:CREATE INDEX ON memory_entry USING hnsw (embedding vector_cosine_ops)。比特严选的数据量用不到,但生产环境有这个需求时加一行 SQL 就行。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 支持语义检索,不需要精确 key | 每次存储和检索都要调 Embedding API,有额外成本 |
| 能处理模糊查询和自然语言检索 | 向量相似度不等于业务相关性,可能返回语义相似但无关的结果 |
| 记忆越多,检索价值越大 | 需要 pgvector 扩展,多一层基础设施依赖 |
| 复用上一篇的 PostgreSQL,不引入新组件 | Embedding 模型的质量直接影响检索效果 |
两种方案怎么选
| 维度 | Key-Value | 向量检索 |
|---|---|---|
| 查询方式 | 精确 key 匹配 | 语义相似度排序 |
| 适合存什么 | 用户画像 | 交互记录 |
| 检索成本 | 几乎为零 | 每次检索一次 Embedding API 调用 |
| 实现复杂度 | 极低 | 中等 |
| 典型场景 | 查用户 10086 的画像 | 用户之前问过什么智能家居的问题 |
在本项目中,两种方案各管一件事:Key-Value 存用户画像(结构化、每次全量注入),向量检索存交互记录(富文本、按语义匹配)。
你可能会想:为什么不把关键事实(订单号、退款编号)也用 Key-Value 单独存?之前的版本确实这么做过,但实践中发现两个问题。第一,事实文本太短(88231、RF20260629001)�,Embedding 后语义信息极弱,做不了向量检索,只能全量加载——用户交互多了之后事实越积越多,Token 预算撑不住。第二,事实脱离了上下文——光知道 refund_id=RF20260629001,不知道是哪次交互、为什么退款、退的什么商品。
更好的做法是把事实嵌入交互记录的叙述里。向量检索命中一条记录时,事实自然跟着来了:
Key-Value 存储:
- 用户画像(偏好品类、预算范围、家庭场景)
向量检索:
- 交互记录(每次会话结束后提炼的富文本记录,包含所有关键数据)
用户画像提取:让大模型帮你总结
长期记忆的内容从哪来?不是手动填的,而是从对话中自动提取的。
最常见的做法是:会话结束时,把本次对话的内容发给大模型,让�它提取画像和交互记录,然后存到长期记忆里。
1. 提取时机
1.1 什么算会话结束
在实际业务里,会话结束没有一个天然的信号,常见的判断方式有三种:
- 用户主动关闭:点了关闭窗口或退出聊天页面,前端发一个关闭事件给后端——这是最明确的信号。
- 超时判定:用户超过 N 分钟没有新消息(比如 30 分钟),服务端认为会话结束。客服系统最常用这种方式。
- 用户显式结束:用户说了“没别的问题了”“谢谢再见”之类的话,Agent 识别到结束意图后触发。
比特严选这种客服场景,最实际的做法是前端关闭 + 超时兜底组合:前端关闭窗口立即触发提取,同时后台定时任务扫描超过 30 分钟没活跃的会话做兜底提取,防止用户直接杀进程或断网导致关闭事件没发出来。
1.2 不止结束时:三种提取策略
会话结束时提取是最基础的策略,但不是唯一的。根据业务场景不同,还有两种补充策略:
| 策略 | 触发条件 | 适用场景 | 优缺点 |
|---|---|---|---|
| 会话结束提取 | 用户关闭 / 超时 / 显式结束 | 大多数短会话(5 轮以内) | 实现最简单,但会话中途异常断开可能丢信息 |
| 轮次触发 | 每隔 N 轮(如每 5 轮)做一次增量提取 | 长会话(技术支持、故障诊断) | 即使会话中途断开,已提取的信息不会丢 |
| 定时增量 | 后台任务每隔一段时间(如每 10 分钟)扫描活跃会话 | 会话边界模糊的场景(用户断断续续聊一下午) | 不依赖会话结束事件,但增加了后台任务的复杂度 |
三种策略可以组合使用。比特严选的客服场景下,大部分会话在 5 轮以内,会话结束时提取一次就够了。只有那些超长会话(故障诊断、跨品类推荐)才需要考虑叠加轮次触发或定时增量。
1.3 为什么不每轮都提取
你可能会想:最保险的做法不是每轮都提取吗?不建议,三个原因:
- 减少 LLM 调用次数:每轮都提取太频繁了,会话可能只有 3 轮,全量提取一次就够。
- 信息更完整:会话结束时能看到完整的对话脉络,提取的信息更准确。比如用户前 2 轮在问退款,第 3 轮突然改主意说不退了——如果第 2 轮就提取了“用户要退款”,这条信息就是错的。
- 不影响响应延迟:会话结束后异步提取,不耽误用户当前的交互体验。
2. 提取提示词
提取的质量取决于提示词的设计。针对比特严选的业务场景,提示词需要明确告诉大模型要提取哪几类信息:
public class UserProfileExtractor {
private final LlmClient llmClient;
public UserProfileExtractor(LlmClient llmClient) {
this.llmClient = llmClient;
}
public ExtractedProfile extract(List<ChatMessage> conversationHistory) {
ObjectMapper objectMapper = llmClient.getObjectMapper();
ArrayNode messages = objectMapper.createArrayNode();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", """
你是一个用户画像提取助手。根据以下客服对话记录,提取用户画像和交互记录。
输出格式(严格遵守,参照示例):
[画像] 偏好和特征的描述
[记录] 包含具体数据(订单号、编号、型号、金额等)的完整交互叙述,不要用模糊指代
示例(仅供参考格式,实际内容根据对话提取):
[画像] 偏好智能家居品类(扫地机),预算 2000-3000 元,对产品质量敏感
[记录] 用户因订单 88231 的比特 S10 Pro 扫地机(1999 元)出现无法回充的质量问题申请退款,退款编号 RF20260629001,预计 1-3 个工作日到账,随后咨询新款扫地机,对比了 S20 Pro 和 S20 Max,倾向 S20 Pro 但认为价格偏高
规则:
- 交互记录是一段完整叙述,所有关键数据(订单号、退款编号、金额、型号等)嵌入叙述中
- 不要把数据拆成单独的 key=value 行,全部写进记录的叙述里
- 不要重复对话原文,不要输出不确定的推测""");
StringBuilder conversation = new StringBuilder();
for (ChatMessage msg : conversationHistory) {
switch (msg.role()) {
case USER -> conversation.append("用户:").append(msg.content()).append("\n");
case ASSISTANT -> conversation.append("客服:").append(msg.content()).append("\n");
default -> { }
}
}
ObjectNode userMsg = messages.addObject();
userMsg.put("role", "user");
userMsg.put("content", "请从以下对话中提取信息:\n\n" + conversation);
ChatResponse response = llmClient.chatWithTools(messages, objectMapper.createArrayNode());
return parseExtractedProfile(response.content());
}
// ......
}
ExtractedProfile 是一个简单的数据载体:
public record ExtractedProfile(
String userProfile,
String interactionRecord
) {}
3. 提取结果示例
假设用户本次会话聊了退款和新品推荐,大模型提取的结果可能是:
[画像] 偏好智能家居品类(扫地机),对产品质量敏感,因质量问题退货,价格预算中等(关注 2000-3000 元档)
[记录] 用户因订单 88231 的比特 S10 Pro 扫地机(1999 元)出现无法回充的质量问题申请退款,退款编号 RF20260629001,预计 1-3 个工作日到账,随后咨询新款扫地机,对比了 S20 Pro 和 S20 Max,倾向 S20 Pro 但认为价格偏高
交互记录是一段完整的叙述,所有关键数据都嵌入其中。大模型根据对话内容自主判断哪些数据值得保留,业务扩展时不需要改提示词模板。
拿到这个结果后,把画像存到 Key-Value 里(覆盖更新),把交互记录存到向量库里。只需两次存储操作。
4. 存储流程
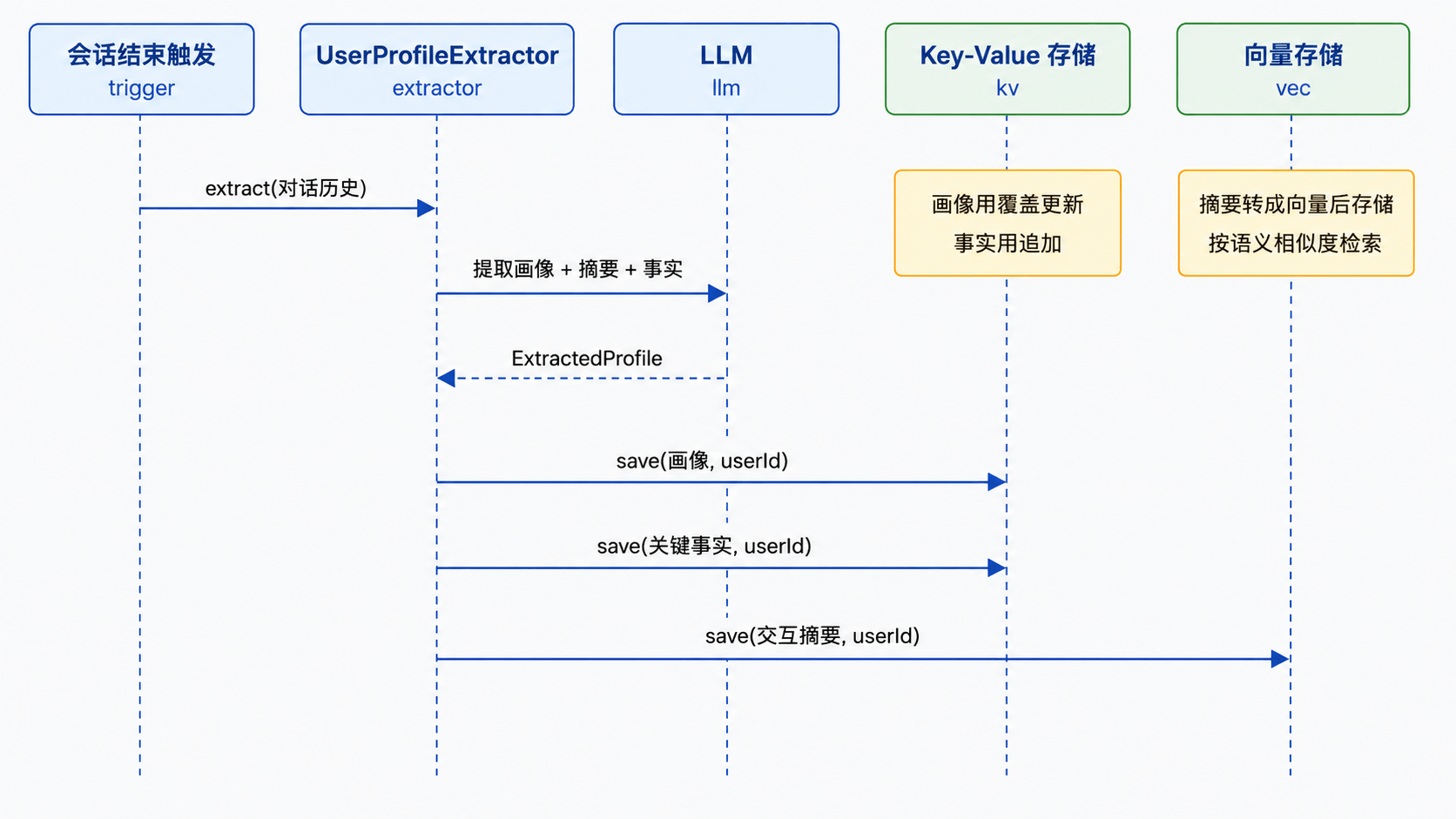
按相关性筛选注入
长期记忆存好了,下一个问题是:新会话开始时,怎么把相关的长期记忆注入到 Agent 的上下文里?
不能全部注入——一个活跃用户可能有几十条长期记忆,全塞进去会占大量 Token。需要一个筛选机制,把最有价值的记忆挑出来。
1. 筛选策略
两种记忆的检索方式不同:
- 用户画像:每次都全量注入,不需要筛选——画像就一条,提供个性��化基调。
- 交互记录:走向量检索,按语义相似度匹配当前用户输入,取最相关的 topK 条。
用户当前输入:”昨天那个退款到账了吗”
第一步:全量注入用户画像
→ [画像] 偏好智能家居,预算 2000-3000,对产品质量敏感
第二步:向量检索交互记录(topK=3)
候选记录(共 3 条):
[记录] 订单 88231 的 S10 Pro 退款,编号 RF20260629001,金额 1999 元 → 余弦距离 0.12 ✓
[记录] 对比 S20 Pro(2999 元)和 S20 Max(3999 元),倾向 Pro 但嫌贵 → 余弦距离 0.58
[记录] 咨询 S20 Pro 促销,被告知 7 月中旬有满减 → 余弦距离 0.62
→ 命中第 1 条(跟”退款到账”语义最近)
交互记录里已经包含了所有关键数据(订单号 88231、退款编号 RF20260629001、金额 1999 元),向量检索命中一条记录时,Agent 同时拿到了事件上下文和具体数据,不需要额外查 Key-Value。
2. Java 实现
public class LongTermMemoryRetriever {
private final PgKeyValueLongTermMemory kvMemory;
private final PgVectorLongTermMemory vectorMemory;
private final int maxTokens;
public LongTermMemoryRetriever(PgKeyValueLongTermMemory kvMemory,
PgVectorLongTermMemory vectorMemory,
int maxTokens) {
this.kvMemory = kvMemory;
this.vectorMemory = vectorMemory;
this.maxTokens = maxTokens;
}
public String buildMemoryContext(String userId, String userQuery) {
StringBuilder context = new StringBuilder();
int estimatedTokens = 0;
// 第一步:用户画像(固定注入)
List<MemoryEntry> profiles = kvMemory.retrieve(userId, "profile", 1);
if (!profiles.isEmpty()) {
String profileText = "用户画像:" + profiles.getFirst().content();
context.append(profileText).append("\n");
estimatedTokens += profileText.length();
}
// 第二步:向量检索相关的交互记录
List<MemoryEntry> relevant = vectorMemory.retrieve(userId, userQuery, 3);
for (MemoryEntry entry : relevant) {
String entryText = "交互记录:" + entry.content();
if (estimatedTokens + entryText.length() > maxTokens) {
break;
}
context.append(entryText).append("\n");
estimatedTokens += entryText.length();
}
return context.toString();
}
}
几个关键设计:
两步检索:画像固定注入(提供个性化基调),然后向量检索相关交互记录(跟当前问题最相关的历史)。
Token 预算控制:maxTokens 限制长期记忆总共能占多少 Token。长期记忆只是上下文的一部分,不能喧宾夺主——系统提示词、会话记忆、工具描述、当前输入都需要空间。一般给长期记忆分配 500-800 Token 就够了。
兜底截断:如果某一级的记忆加进去会超预算,直接 break 不加了。宁可少注入几条,也不能挤占其他组件的 Token 空间。
改造 ReActAgent:集成长期记忆
有了长期记忆的检索能力,接下来把它集成到 ReActAgent 里。
改动很小——新增一个 LongTermMemoryRetriever 字段和一个带 userId 参数的 run() 重载,在构建消息列表时把长期记忆注入到系统提示词之后、对话历史之前:
public class ReActAgent {
// ... 已有字段
private final LongTermMemoryRetriever memoryRetriever;
// 新增构造函数,接收 LongTermMemoryRetriever(可选)
public ReActAgent(LlmClient llmClient, ToolRegistry toolRegistry,
int maxSteps, int maxTokens, ChatMemory chatMemory,
LongTermMemoryRetriever memoryRetriever) {
// ... 已有赋值
this.memoryRetriever = memoryRetriever;
}
// 原有方法保持不变,向下兼容
public String run(String userMessage) {
return run(userMessage, null);
}
// 新增重载,支持 userId 触发长期记忆注入
public String run(String userMessage, String userId) {
ArrayNode messages = objectMapper.createArrayNode();
// 系统提示词
String systemPrompt = buildSystemPrompt();
ObjectNode systemMsg = messages.addObject();
systemMsg.put("role", "system");
systemMsg.put("content", systemPrompt);
TokenBudget tokenBudget = new TokenBudget(maxTokens);
tokenBudget.addMessage(systemPrompt);
// 注入长期记忆(在系统提示词之后、对话历史之前)
if (memoryRetriever != null && userId != null) {
String memoryContext = memoryRetriever.buildMemoryContext(userId, userMessage);
if (!memoryContext.isBlank()) {
ObjectNode memoryMsg = messages.addObject();
memoryMsg.put("role", "system");
memoryMsg.put("content",
"以下是关于当前用户的历史信息,供你参考:\n" + memoryContext);
tokenBudget.addMessage(memoryContext);
}
}
// 会话记忆注入(跟之前一样)
if (chatMemory != null) {
chatMemory.add(ChatMessage.user(userMessage));
for (ChatMessage mem : chatMemory.messages()) {
// ... 注入逻辑不变
}
}
// ... 后续循环逻辑不变
}
}
注入的位置很重要。长期记忆放在 system 提示词之后、会话记忆(对话历史)之前:
messages 数组的结构:
[0] system: 系统提示词(你是比特严选的智能客服...)
[1] system: 长期记忆上下文(用户画像 + 相关交互记录) ← 新增
[2] system: [对话摘要](如果有混合策略的摘要)
[3] user: 最近的用户输入
[4] assistant: 最近的 Agent 回复
...
[N] user: 当前轮次的用户输入
为什么放在这个位置?因为长期记忆是跨会话的背景信息,它的作用类似于提前告诉大脑这个用户是谁,而不是当前对话的一部分。放在 system 层能让大模型把它当做背景参考,而不是跟对话历史混在一起。
Demo:跨会话记住用户
把所有模块串起来,模拟同一个用户的两次独立会话。会话记忆用 PersistentHybridChatMemory——它把 JdbcChatMemory(持久化)和 HybridChatMemory(摘要压缩)组合在一起,原始消息写入数据库,Agent 看到的是压缩后的视图。长期记忆用 LongTermMemoryRetriever 在新会话开始时注入历史��信息:
public static void main(String[] args) {
// 初始化工具和 LLM
ToolRegistry toolRegistry = new ToolRegistry();
toolRegistry.register(new QueryOrderTool());
toolRegistry.register(new QueryLogisticsTool());
toolRegistry.register(new ApplyRefundTool());
toolRegistry.register(new SearchKnowledgeTool());
toolRegistry.register(new GetCurrentTimeTool());
Properties dotEnv = loadDotEnv();
LlmClient llmClient = new LlmClient(
setting(dotEnv, "TINYAGENT_API_URL", "..."),
requiredSetting(dotEnv, "TINYAGENT_API_KEY"),
setting(dotEnv, "TINYAGENT_MODEL", "deepseek-v4-pro")
);
EmbeddingClient embeddingClient = new EmbeddingClient(
setting(dotEnv, "TINYAGENT_EMBEDDING_URL", "..."),
requiredSetting(dotEnv, "TINYAGENT_API_KEY"),
setting(dotEnv, "TINYAGENT_EMBEDDING_MODEL", "text-embedding-v3")
);
// 创建数据源(复用上一篇的 PostgreSQL 环境)
DataSource dataSource = createDataSource(dotEnv);
SessionManager sessionManager = new SessionManager(dataSource);
// 长期记忆(跨会话共享,都存 PostgreSQL)
PgKeyValueLongTermMemory kvMemory = new PgKeyValueLongTermMemory(dataSource);
PgVectorLongTermMemory vectorMemory = new PgVectorLongTermMemory(dataSource, embeddingClient);
LongTermMemoryRetriever retriever = new LongTermMemoryRetriever(kvMemory, vectorMemory, 600);
UserProfileExtractor extractor = new UserProfileExtractor(llmClient);
String userId = "user_10086";
// ========== 第一次会话 ==========
System.out.println("========== 第一次会话 ==========");
String session1Id = sessionManager.createSession(userId);
ChatMemory session1Memory = new PersistentHybridChatMemory(
dataSource, session1Id, llmClient, 6, 12);
ReActAgent agent1 = new ReActAgent(
llmClient, toolRegistry, 10, 8000, session1Memory, retriever);
String firstAnswer = agent1.run("帮我查一下订单 88231 的物流", userId);
// 第一轮结束后自动生成会话标题(复用上一篇的 SessionTitleGenerator)
SessionTitleGenerator titleGen = new SessionTitleGenerator(llmClient);
String title1 = titleGen.generate("帮我查一下订单 88231 的物流", firstAnswer);
sessionManager.updateTitle(session1Id, title1);
agent1.run("那我要退款呢,这个扫地机不回充了", userId);
agent1.run("退款多久到账", userId);
// 会话结束,提取长期记忆
System.out.println("\n[会话结束] 提取用户画像和关键信息...");
ExtractedProfile profile = extractor.extract(session1Memory.messages());
System.out.println("[提取结果] 画像:" + profile.userProfile());
System.out.println("[提取结果] 记录:" + profile.interactionRecord());
if (profile.userProfile() != null) {
kvMemory.save(MemoryEntry.of(
"profile:" + userId, profile.userProfile(), userId, "USER_PROFILE"));
}
if (profile.interactionRecord() != null) {
vectorMemory.save(MemoryEntry.of(
"record:" + userId + ":" + System.currentTimeMillis(),
profile.interactionRecord(), userId, "INTERACTION_RECORD"));
}
// ========== 第二次会话(模拟第二天) ==========
System.out.println("\n\n========== 第二次会话(第二天) ==========");
String session2Id = sessionManager.createSession(userId);
ChatMemory session2Memory = new PersistentHybridChatMemory(
dataSource, session2Id, llmClient, 6, 12);
ReActAgent agent2 = new ReActAgent(
llmClient, toolRegistry, 10, 8000, session2Memory, retriever);
// 用户没有提供任何订单号,但 Agent 应该从长期记忆中找到退款信息
String firstAnswer2 = agent2.run("昨天那个退款到账了吗", userId);
sessionManager.updateTitle(session2Id,
titleGen.generate("昨天那个退款到账了吗", firstAnswer2));
agent2.run("再帮我推荐一个扫地机呗,要比之前那个好的", userId);
}
注意这里用的是 PersistentHybridChatMemory 而不是裸的 JdbcChatMemory——它把持久化和摘要压缩组合在一起:原始消息写入 PostgreSQL(不丢数据),Agent 看到的是压缩后的视图(省 Token)。同时 ReActAgent 多了一个 retriever 参数,能在新会话开始时从长期记忆里捞出历史信息。三层记忆各就各位。
预期行为:
- 第一次会话:正常的退款流程,跟之前的 Demo 一样。会话结束后,
UserProfileExtractor提取用户画像和交互记录,存入长期记忆。 - 第二次会话:用户开了一个新的 session(
session2Id),会话记忆是空的。但ReActAgent在构建消息列表时,通过retriever从长期记忆中�检索到包含退款编号 RF20260629001 的交互记录。Agent 不需要再问用户”您说的是哪个退款”,直接用退款编号 RF20260629001 去查退款状态。用户问”比之前那个好的”时,Agent 知道之前买的是 S10 Pro,自然会推荐规格更高的型号。
长期记忆的工程注意事项
1. 画像更新与冲突处理
用户画像不是只写一次就不管了。随着用户多次来访,画像应该逐步丰富和修正。
最直观的做法是让大模型帮你合并——每次会话结束后,把新提取的画像跟已有画像一起发给大模型,生成一份合并后的画像。
但合并时有一个关键问题:前后信息冲突了怎么办?
举个例子:用户前三次来都买 2000-3000 元的扫地机,画像里写着预算中高端。第四次来随口问了一句“有没有 500 以内的智能音箱”。如果合并时简单地以最新为准,画像就变成预算 500 元以内了——但实际上用户可能只是帮人随便问问,并不代表他自己的消费水平变了。
处理冲突的原则是:区分事实和偏好,区分一次提及和多次验证。
| 信息类型 | 冲突处理策略 | 举例 |
|---|---|---|
| 客观事实 | 新的覆盖旧的 | 收货地址变了,以最新为准 |
| 高频偏好 | 多次出现才更新,�一次提及只做标注 | 连续 3 次买高端→稳定偏好;1 次问便宜的→也关注性价比 |
| 场景相关偏好 | 按场景拆分,不互相覆盖 | 自用买贵的、送人买便宜的,两个偏好并存 |
| 临时意图 | 不写入画像,只存交互记录 | “今天就随便看看”→不影响长期画像 |
具体到合并提示词,关键是告诉大模型不要简单覆盖,而是综合判断:
提示词:
请将以下两段用户画像信息合并为一段完整画像。合并规则:
1. 不冲突的信息直接保留
2. 客观事实(地址、设备型号)以新信息为准
3. 偏好类信息不要因为一次提及就推翻已有判断,而是补充描述
4. 如果新旧信息看起来矛盾,保留两者并标注场景差异
已有画像(基于 3 次会话):偏好智能家居,预算 2000-3000 元,对产品质量敏感
新提取画像(本次会话):咨询了 500 元以内的智能音箱,说是给父母买的
合并结果:
偏好智能家居品类,自用预算 2000-3000 元,对产品质量敏感。
也会为家人选购性价比产品(500 元档),关注操作简便性。
对比一下如果用以最新为准的简单策略,合并结果会变成预算 500 元以内——这就把三次会话积累的稳定偏好给丢了。
偏好类信息的本质是统计特征而非最新状态。一个用户买了 10 次贵的、问了 1 次便宜的,他的偏好大概率还是中高端。合并提示词里带上已有画像基于 N 次会话这个信息,能帮大模型更准确地判断权重。
2. 记忆过期清理
不是所有长期记忆都永远有用。三个月前的交互记录,对当前会话的参考价值已经很低了。
建议设置一个过期策略:
| 记忆类型 | 建议保留时长 | 原因 |
|---|---|---|
| 用户画像 | 不过期,只更新 | 画像是累积的,越来越准 |
| 交互记录 | 90 天 | 太早的交互对当前场景参考价值低 |
3. 隐私与合规
长期记忆存储了用户的个人偏好、购买历史、投诉记录等敏感信息,必须考虑:
- 数据脱敏:收货地址、手机号等敏感信息不建议直接存明文。
- 用户可控:用户有权要求删除自己的长期记忆(GDPR、《个人信息保护法》)。
- 访问隔离:用户 A 的长期记忆不能被用户 B 的会话检索到——
retrieve()方法里的userId过滤必须严格执行。
4. 交互记录的时效性:快照而非实时状态
交互记录里的数据有一个容易被忽略的特性:它是对话发生时的快照,不是业务系统的实时状态。
举个例子:用户昨天通过客服申请了退款,记录里包含了退款编号 RF20260629001。但今天用户自己在 App 上取消了退款,或者退款已经到账了——这些变化发生在对话之外,长期记忆完全不知道。
如果 Agent 下次直接拿着交互记录里的数据告诉用户“您的退款还在处理中”,就给了错误信息。
处理这个问题的原则是:记录当线索用,不当结论用。
具体来说:
- 会变的数据(退款状态、物流进度、库存):Agent 从交互记录中拿到退款编号后,应该调工具去查最新状态,而不是直接用记录里的状态回复用户。交互记录提供的是“查什么”的线索,不是“结果是什么”的答案。
- 不会变的数据(订单号、商品型号、用户偏好):可以直接使用,不需要每次都重新查。
- 生产环境的进阶方案:如果业务系统支持,可以在关键事件发生时(退款到账、订单发货、工单关闭)主动推送到长期记忆模块,更新或删除相关记录。这就是事件驱动的记忆更新——不依赖对话,业务状态变了记忆也跟着变。但这需要和业务系统做对接,超出本篇的范围。
一个简单的判断标准:这条数据如果一周后还是同样的值,可以直接用;如果可能变,就只当检索线索,调工具查最新的。
文末总结
这一篇从会话记忆的跨会话隔离问题出发,完整实现了长期记忆模块:
- 边界划分:会话记忆管一次会话内的连贯性(内存 / PostgreSQL),长期记忆管跨会话的个性化(提炼 + 按需检索)。
- 记什么:用户画像(偏好、特征)和交互记录(每次会话的完整叙述,订单号、退款编号、金额等关键数据嵌入其中)。不记对话原文和中间推理过程。
- 怎么存:用户画像用 Key-Value 存储(每次全量注入),交互记录用向量检索存储(按语义相似度匹配)。每种记忆用最适合它的存储和检索方式。
- 怎么提取:会话结束时,调大模型从对话历史中提取画像和交互记录。交互记录是富文本叙述,关键数据嵌入其中,天然适合向量检索。
- 怎么注入:新会话开始时,�两步检索(用户画像固定注入 + 交互记录向量检索 topK 条),控制总 Token 在预算内,注入到 system 消息层。
用一句话概括:长期记忆让 Agent 从一个每次都失忆的客服,变成一个认识你、记得你、能为你提供个性化服务的客服。