用 Milvus 构建向量检索实战
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
向量:让计算机理解语义
1. 什么是向量
别被向量这个词吓到,它其实很简单:向量就是一组有序的数字。
举个例子,如果我们想用数字来描述一个人:
张三 = [身高175cm, 体重70kg, 年龄25岁]
= [175, 70, 25]
这个 [175, 70, 25] 就是张三的"向量",它是一个 3 维向量(因为有 3 个数字)。
同样的道理,我们也可以用一组数字来描述一段文字的"语义":
"今天天气真好" = [0.12, -0.34, 0.78, ..., 0.56] // 假设有 1024 个数字
"今天阳光明媚" = [0.11, -0.32, 0.80, ..., 0.55] // 数字很接近!
"明天股票大跌" = [-0.67, 0.89, -0.12, ..., -0.45] // 数字差很远
关键点来了:
语义相近的文字,转成向量后,这些数字也会很接近。
2. Embedding:把文字变成向量
那谁来负责把文字转成这一串数字呢?答案是 Embedding 模型(也叫"嵌入模型")。
你可以把 Embedding 模型理解成一个"翻译官":
- 输入:一段文字
- 输出:一组数字(向量)
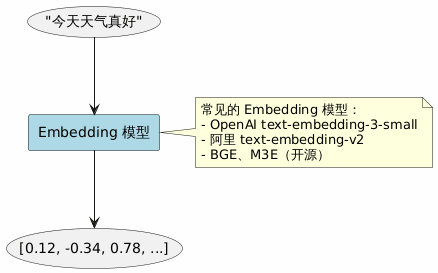
作为工程师,你不需要关心模型内部怎么计算的,只需要知道:
- 调用 API 或者本地模型
- 传入文字,拿到向量
- 向量维度是固定的(比如 1024 维或 4096 维等)
3. 向量相似度搜索
有了向量,我们就可以用数学方法计算"两段文字的语义有多接近"。
这就是向量相似度搜索的核心思路:
- 建库阶段:把所有文档都转成向量,存起来
- 查询阶段:把用户问题也转成向量,找出最相似的文档向量
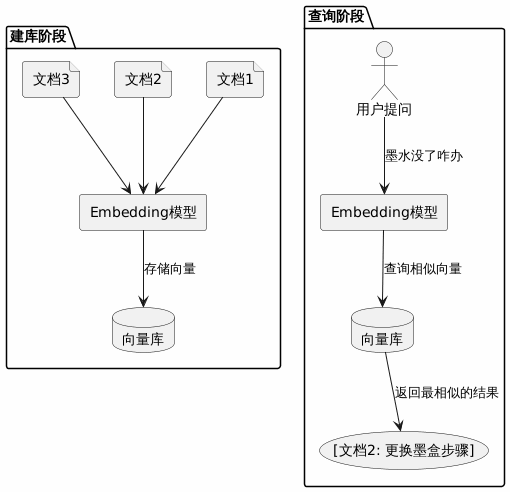
三种相似度度量方式
计算两个向量"有多接近",有几种不同的方法。你不需要记住公式,只要知道什么场景用什么方法就行。
1. L2(欧氏距离)
一句话理解:两点之间的直线距离。
向量A = [1, 2]
向量B = [4, 6]
L2距离 = √[(4-1)² + (6-2)²] = 5
特点:
- 数值越小,表示越相似
- 对向量的"长度"敏感
��适用场景:
- 图像相似度搜索
- 需要考虑数值大小的场景
2. COSINE(余弦相似度)
一句话理解:两个向量的夹角有多小。
B
/
/ 夹角小 = 方向相近 = 语义相似
/
A ———————
特点:
- 数值范围是 -1 到 1,越接近 1 越相似
- 只看"方向",不看"长度"
- 一段话写得长或短,不影响相似度判断
适用场景:
- 文本语义搜索(最常用)
- 文档长短不一的场景
3. IP(内积,Inner Product)
一句话理解:方向和长度都考虑。
特点:
- 数值越大越相似
- 如果向量已经做过归一化(长度都是 1),效果等同于余弦相似度
适用场景:
- 推荐系统
- 向量已归一化的场景
4. 怎么选?
对于 RAG 场景,90% 的情况选 COSINE 就对了:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 文本语义搜索 | COSINE | 只关心语义方向,不关心文档长短 |
| 图像搜索 | L2 | 像素特征对绝对数值敏感 |
| 推荐系统 | IP | 通常向量已归一化 |
为什么需要专门的向量数据库
1. 暴力搜索的性能灾难
假设你的知识库有 100 万条文档,每条文档的向量是 1024 维。
用户问一个问题,你需要:
- 把问题转成 1024 维向量
- 和 100 万条文档向量逐一计算相似度
- 排序,取最相似的 10 条
这意味着:100 万次向量距离计算,每次涉及 1024 个浮点数运算。
用 Java 写个 for 循�环当然能实现,但是:
- 单次查询可能要好几秒
- 并发一上来,服务器直接挂掉
2. 向量数据库的解决方案
向量数据库(如 Milvus)使用一类叫 ANN(Approximate Nearest Neighbor,近似最近邻) 的算法。
核心思想是:不追求 100% 精确,用一点点准确率下降换取巨大的速度提升。
| 方式 | 100万条数据查询耗时 | 准确率 |
|---|---|---|
| 暴力搜索 | 几秒到几十秒 | 100% |
| ANN 算法 | 几毫秒到几十毫秒 | 95%+ |
对于 RAG 场景,我们要的是"最相关的几条文档",少返回一两条不太相关的问题不大。用 95% 的准确率换 1000 倍的性能提升,非常划算。
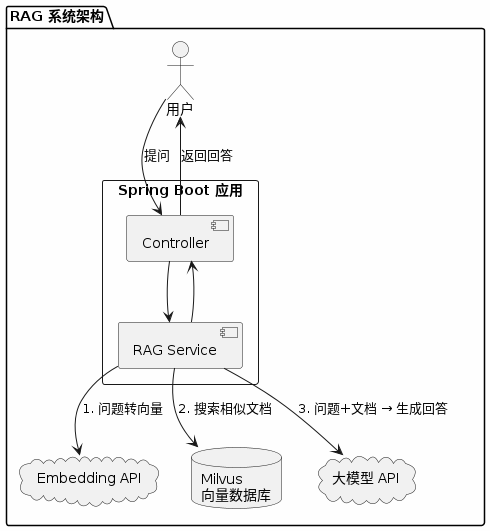
3. Milvus 是什么
Milvus 是一个开源的向量数据库,专门用来存储、索引和搜索大规模向量数据。
它的核心能力:
- 存储:高效存储数十亿级别的向量
- 索引:建立索引结构,加速搜索
- 搜索:毫秒级返回最相似的向量
在 RAG 架构中,Milvus 就是那个"知识库"的角色:
Docker 安装 Milvus
1. 环境准备
确保你的电脑已安装:
- Docker(版本 19.03 或更高)
- Docker Compose(版本 1.25.0 或更高)
验证安装:
docker --version
docker-compose --version
2. 下载 Docker Compose 配置文件
Milvus 官方提供了一个单机版的配置文件,适合学习和开发使用:
# 创建一个目录
mkdir milvus && cd milvus
# 下载 docker-compose 文件
wget https://github.com/milvus-io/milvus/releases/download/v2.4.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
如果 wget 下载很慢,你也可以手动创建 docker-compose.yml 文件:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.4.4
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
3. 启动 Milvus
# 启动服务(后台运行)
docker-compose up -d
# 查看运行状态
docker-compose ps
如果一切正常,你会看到三个容器都是 Up 状态:
NAME IMAGE STATUS
milvus-etcd quay.io/coreos/etcd:v3.5.5 Up (healthy)
milvus-minio minio/minio:... Up (healthy)
milvus-standalone milvusdb/milvus:v2.4.4 Up (healthy)
4. 验证安装
Milvus 默认监听 19530 端口,你可以用以下命令验证:
# 检查端口是否在监听
curl http://localhost:9091/healthz
返回 OK 表示安装成功。
5. 常用运维命令
# 停止服务
docker-compose down
# 停止并删除数据(慎用!)
docker-compose down -v
# 查看日志
docker-compose logs -f standalone
Spring Boot 集成 Milvus
1. 创建项目并添加依赖
在你的 Spring Boot 项目的 pom.xml 中添加 Milvus Java SDK:
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Milvus Java SDK -->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.4.1</version>
</dependency>
<!-- Lombok(可选,简化代码) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
2. 配置 Milvus 连接
创建 application.yml:
milvus:
host: localhost
port: 19530
# 如果你使用外部 Embedding API,也可以在这里配置
embedding:
api-url: https://your-embedding-api.com
api-key: your-api-key
创建配置类 MilvusConfig.java:
package com.example.demo.config;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MilvusConfig {
@Value("${milvus.host}")
private String host;
@Value("${milvus.port}")
private int port;
@Bean
public MilvusClientV2 milvusClient() {
ConnectConfig config = ConnectConfig.builder()
.uri("http://" + host + ":" + port)
.build();
return new MilvusClientV2(config);
}
}
3. 核心概念映射
在写代码之前,先理解 Milvus 的几个概念和关系型数据库的对应关系:
| Milvus 概念 | 关系型数据库 | 说明 |
|---|---|---|
| Collection | Table | 存储数据的基本单位 |
| Field | Column | 字段,包括向量字段和标量字段 |
| Entity | Row | 一条数据 |
| Index | Index | 索引,加速向量搜索 |
4. 创建 Collection(建表)
我们来创建一个存储文档的 Collection:
package com.example.demo.service;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.HasCollectionReq;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import jakarta.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Slf4j
@Service
@RequiredArgsConstructor
public class MilvusService {
private final MilvusClientV2 milvusClient;
// Collection 名称
private static final String COLLECTION_NAME = "document_vectors";
// 向量维度(根据你使用的 Embedding 模型决定)
private static final int VECTOR_DIMENSION = 1024;
/**
* 应用启动时初始化 Collection
*/
@PostConstruct
public void init() {
createCollectionIfNotExists();
}
/**
* 创建 Collection(如果不存在)
*/
public void createCollectionIfNotExists() {
// 检查是否已存在
HasCollectionReq hasReq = HasCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.build();
if (milvusClient.hasCollection(hasReq)) {
log.info("Collection {} 已存在", COLLECTION_NAME);
return;
}
// 定义字段结构
CreateCollectionReq.CollectionSchema schema =
milvusClient.createSchema();
// 主键字段
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
// 文档内容字段
schema.addField(AddFieldReq.builder()
.fieldName("content")
.dataType(DataType.VarChar)
.maxLength(65535)
.build());
// 文档标题字段
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
// 向量字段(核心!)
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(VECTOR_DIMENSION)
.build());
// 定义索引(使用 COSINE 相似度)
IndexParam indexParam = IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.IVF_FLAT)
.metricType(IndexParam.MetricType.COSINE)
.extraParams(Collections.singletonMap("nlist", 1024))
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParam);
// 创建 Collection
CreateCollectionReq createReq = CreateCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.collectionSchema(schema)
.indexParams(indexParams)
.build();
milvusClient.createCollection(createReq);
log.info("Collection {} 创建成功", COLLECTION_NAME);
}
}
5. 插入数据
接下来在 MilvusService 中添加插入数据的方法:
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import java.util.List;
/**
* 插入文档及其向量
*
* @param title 文档标题
* @param content 文档内容
* @param embedding 文档的向量表示(需要你自己调用 Embedding API 生成)
*/
public void insertDocument(String title, String content, List<Float> embedding) {
// 构建数据
JsonObject data = new JsonObject();
data.addProperty("title", title);
data.addProperty("content", content);
data.add("embedding", new Gson().toJsonTree(embedding));
List<JsonObject> dataList = Collections.singletonList(data);
// 执行插入
InsertReq insertReq = InsertReq.builder()
.collectionName(COLLECTION_NAME)
.data(dataList)
.build();
InsertResp response = milvusClient.insert(insertReq);
log.info("插入成功,影响行数: {}", response.getInsertCnt());
}
/**
* 批量插入文档
*/
public void insertDocuments(List<DocumentDTO> documents) {
List<JsonObject> dataList = new ArrayList<>();
Gson gson = new Gson();
for (DocumentDTO doc : documents) {
JsonObject data = new JsonObject();
data.addProperty("title", doc.getTitle());
data.addProperty("content", doc.getContent());
data.add("embedding", gson.toJsonTree(doc.getEmbedding()));
dataList.add(data);
}
InsertReq insertReq = InsertReq.builder()
.collectionName(COLLECTION_NAME)
.data(dataList)
.build();
InsertResp response = milvusClient.insert(insertReq);
log.info("批量插入成功,影响行数: {}", response.getInsertCnt());
}
对应的 DTO 类:
package com.example.demo.dto;
import lombok.Data;
import java.util.List;
@Data
public class DocumentDTO {
private String title;
private String content;
private List<Float> embedding;
}
6. 向量相似度搜索
这是最核心的功能——根据用户问题搜索相关文档:
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import java.util.Arrays;
import java.util.Map;
/**
* 搜索相似文档
*
* @param queryEmbedding 查询文本的向量(用户问题转成的向量)
* @param topK 返回最相似的 K 条结果
* @return 相似文档列表
*/
public List<SearchResultDTO> searchSimilarDocuments(List<Float> queryEmbedding, int topK) {
// 构建搜索请求
SearchReq searchReq = SearchReq.builder()
.collectionName(COLLECTION_NAME)
.data(Collections.singletonList(queryEmbedding))
.topK(topK)
.outputFields(Arrays.asList("id", "title", "content"))
.build();
// 执行搜索
SearchResp searchResp = milvusClient.search(searchReq);
// 解析结果
List<SearchResultDTO> results = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
if (searchResults != null && !searchResults.isEmpty()) {
for (SearchResp.SearchResult result : searchResults.get(0)) {
SearchResultDTO dto = new SearchResultDTO();
dto.setId((Long) result.getEntity().get("id"));
dto.setTitle((String) result.getEntity().get("title"));
dto.setContent((String) result.getEntity().get("content"));
dto.setScore(result.getScore()); // 相似度分数
results.add(dto);
}
}
return results;
}
搜索结果 DTO:
package com.example.demo.dto;
import lombok.Data;
@Data
public class SearchResultDTO {
private Long id;
private String title;
private String content;
private Float score; // 相似度分数,COSINE 下越接近 1 越相似
}
7. 完整的 Controller 示例
最后写一个 Controller 把这些功能暴露出去:
package com.example.demo.controller;
import com.example.demo.dto.DocumentDTO;
import com.example.demo.dto.SearchResultDTO;
import com.example.demo.service.EmbeddingService;
import com.example.demo.service.MilvusService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api/documents")
@RequiredArgsConstructor
public class DocumentController {
private final MilvusService milvusService;
private final EmbeddingService embeddingService; // 需要你自己实现
/**
* 添加文档到知识库
*/
@PostMapping
public String addDocument(@RequestBody AddDocumentRequest request) {
// 1. 调用 Embedding API 把文档内容转成向量
List<Float> embedding = embeddingService.getEmbedding(request.getContent());
// 2. 存入 Milvus
milvusService.insertDocument(
request.getTitle(),
request.getContent(),
embedding
);
return "文档添加成功";
}
/**
* 搜索相关文档
*/
@GetMapping("/search")
public List<SearchResultDTO> searchDocuments(
@RequestParam String query,
@RequestParam(defaultValue = "5") int topK) {
// 1. 把查询文本转成向量
List<Float> queryEmbedding = embeddingService.getEmbedding(query);
// 2. 在 Milvus 中搜索
return milvusService.searchSimilarDocuments(queryEmbedding, topK);
}
}
@Data
class AddDocumentRequest {
private String title;
private String content;
}
8. Embedding Service 示例(模拟实现)
为了让代码能跑起来,这里提供一个模拟的 Embedding 服务。实际项目中,你需要替换成真实的 Embedding API 调用:
package com.example.demo.service;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* Embedding 服务
*
* 注意:这只是一个模拟实现!
* 实际项目中,你需要调用真实的 Embedding API,比如:
* - OpenAI text-embedding-3-small
* - 阿里云 text-embedding-v2
* - 本地部署的 BGE 模型
*/
@Service
public class EmbeddingService {
private static final int DIMENSION = 1024;
private final Random random = new Random();
/**
* 把文本转成向量
*
* 实际实现示例(以 OpenAI 为例):
*
* public List<Float> getEmbedding(String text) {
* OpenAIClient client = new OpenAIClient(apiKey);
* EmbeddingResponse response = client.createEmbedding(
* EmbeddingRequest.builder()
* .model("text-embedding-3-small")
* .input(text)
* .build()
* );
* return response.getData().get(0).getEmbedding();
* }
*/
public List<Float> getEmbedding(String text) {
// 模拟:生成随机向量
// 真实场景请替换为 API 调用
List<Float> embedding = new ArrayList<>(DIMENSION);
for (int i = 0; i < DIMENSION; i++) {
embedding.add(random.nextFloat() * 2 - 1); // -1 到 1 之间的随机数
}
return embedding;
}
}
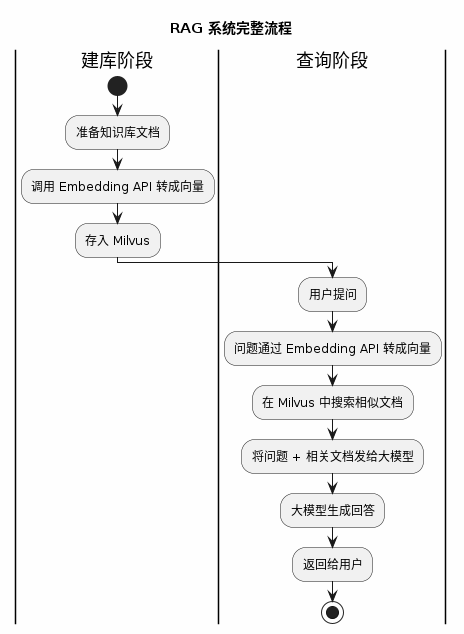
整体流程回顾
学完上面的内容,让我们回顾一下完整的 RAG 流程:
常见问题
1. 向量维度不匹配怎么办?
确保你在创建 Collection 时设置的维度,和 Embedding 模型输出的维度一致。常见的维度:
| Embedding 模型 | 维度 |
|---|---|
| OpenAI text-embedding-3-small | 1536 |
| OpenAI text-embedding-3-large | 3072 |
| 阿里云 text-embedding-v2 | 1536 |
| BGE-large-zh | 1024 |
2. 搜索结果不准怎么调优?
- 尝试不同的索引类型(IVF_FLAT、HNSW 等)
- 调整
nlist、nprobe等参数 - 检查 Embedding 模型是否适合你的场景
3. 生产环境部署建议
- 使用 Milvus 集群版而非单机版
- 配置持久化存储
- 做好数据备份
- 监控内存和 CPU 使用率
下一步学习建议
- 动手实践:按照本文步骤,把 Demo 跑起来
- 接入真实 Embedding API:替换模拟的
EmbeddingService - 完善 RAG 流程:接入大模型 API,实现完整的问答功能
- 深入学习:了解不同的索引类型(IVF_FLAT、HNSW、DiskANN)和它们的适用场景
总结
| 概念 | 一句话解释 |
|---|---|
| 向量 | 一组数字,表示文本的语义特征 |
| Embedding | 把文字转成向量的过程/模型 |
| 向量相似度 | 用数学方法衡量两个向量(语义)有多接近 |
| COSINE | 只看方向不看长度,文本搜索首选 |
| Milvus | 专门存储和搜索向量的数据库,支持毫秒级查询 |
| RAG | 先检索相关内容,再让大模型基于内容回答 |
现在大家已经理解了 Milvus 在 RAG 架构中的作用,以及如何在 Spring Boot 中使用它。可以根据上面代码去动手试试运行效果。