多轮对话为什么会失忆?记忆设计
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
到这里,RAG 系列的核心链路已经全部打通了:数据分块 → 元数据管理 → 向量化 → 向量数据库 → 检索策略 → 生成策略 → Function Call → MCP 协议。从数据准备到检索生成,再到工具调用,一条完整的链路。
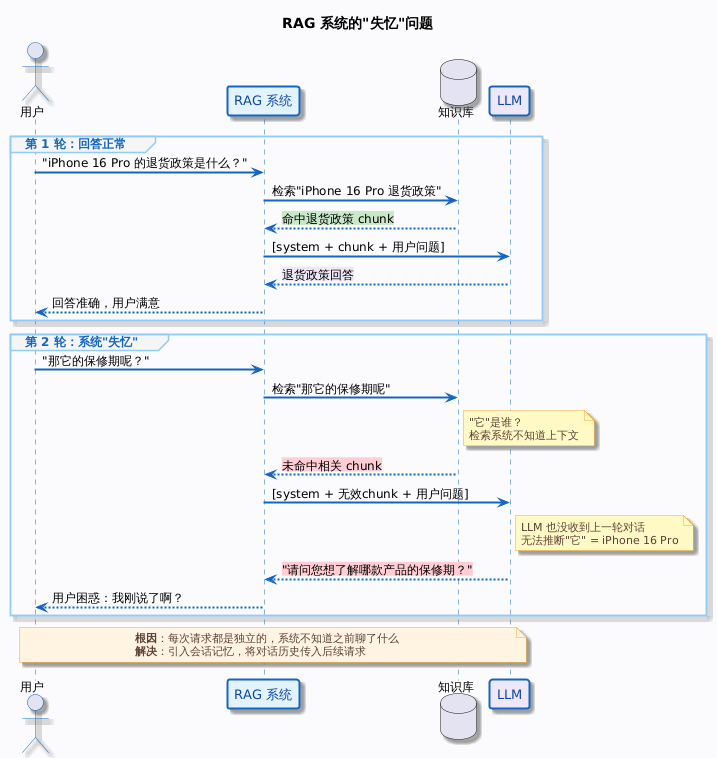
但你把这套系统上线之后,用户很快就会给你提一个 bug:你们这个 AI 是不是没有记忆?
场景是这样的:用户问“iPhone 16 Pro 的退货政策是什么”,系统检索知识库,找到退货政策的 chunk,回答得很好。用户满意了,紧接着追问“那它的保修期呢”。
然后系统的回答画风突变:
请问您想了解哪款产品的保修期呢?请提供具体的产品名称,我帮您查询。
用户心想:我刚才不是说了 iPhone 16 Pro 吗?你怎么就忘了?
这不是 bug,这是你的 RAG 系统“失忆”了。每次用户提问,系统都是从零开始——不知道之前聊了什么,不知道“它”指的是什么。对用户来说,这种体验就像跟一个每隔 30 秒就失忆的人聊天,每句话都要把前因后果重新说一遍。
这一篇咱们就来聊聊怎么给 RAG 系统装上记忆——会话记忆(Conversation Memory)。
大模型的记忆真相:每次请求都是失忆的
1. 一个常见的误解
很多人用过 ChatGPT、Kimi 这些产品,觉得大模型天生就能记住对话内容。你跟它聊了十几轮,它还记得第一轮你说了什么,感觉像是在跟一个有记忆的智能体对话。
但实际上,大模型 API 的每次请求都是完全独立的。模型不会保存任何对话状态——它没有上一轮对话的概念,没有这个用户之前问过什么的记忆,甚至不知道你是谁。
打个比方:大模型就像一个极其聪明但患有严重失忆症的专家。每次你找他,他都不记得你之前来过。你得把之前聊过的内容全部重新说一遍,他才能接着聊。
那 ChatGPT 网页上的记忆是怎么实现的?答案很简单——把你之前所有的对话历史全部塞进了 messages 数组,每次请求都重新发给 API。模型看到了完整的对话历史,所以显得有记忆,实际上每次都是从头看一遍。
2. messages 数组就是记忆的全部
回顾一下之前模型调用 API 那篇讲过的 messages 数组结构。
单轮对话——只有系统指令和用户消息:
{
"messages": [
{"role": "system", "content": "你是一个电商客服助手"},
{"role": "user", "content": "iPhone 16 Pro 的退货政策是什么?"}
]
}
多轮对话——每次请求都要带上之前所有的 user 和 assistant 消息:
{
"messages": [
{"role": "system", "content": "你是一个电商客服助手"},
{"role": "user", "content": "iPhone 16 Pro 的退货政策是什么?"},
{"role": "assistant", "content": "iPhone 16 Pro 因屏幕定制工艺,拆封后不支持七天无理由退货..."},
{"role": "user", "content": "那它的保修期呢?"}
]
}
看到区别了吗?第二轮请求的 messages 里包含了第一轮的 user 消息和 assistant 回复。模型看到了“iPhone 16 Pro 的退货政策是什么”和对应的回答,所以它知道“它”指的是 iPhone 16 Pro。
如果你第二轮请求只发了这样的 messages:
{
"messages": [
{"role": "system", "content": "你是一个电商客服助手"},
{"role": "user", "content": "那它的保修期呢?"}
]
}
模型看到的就是一个莫名其妙的问题——“它”是什么?保修期是什么产品的?所以它只能反问你“请问您想了解哪款产品的保修期”。
一句话概括:大模型没有记忆。所谓的记忆,就是你把对话历史塞进 messages 数组重新发送。记忆的管理不在模型侧,完全在你的代码侧。
3. Token 膨胀:记忆越多,成本越高
既然记忆就是把历史消息塞进 messages,那最简单的做法就是——全部塞进去呗。用户聊了 10 轮,就把 10 轮的 user + assistant 消息全带上。
听起来很合理,但实际跑起来会遇到一个严重的问题:Token 膨胀。
用一个具体的例子算一下。假设电商客服场景,每轮对话大约的 Token 消耗:
| 轮次 | 用户消息 | 助手回复 | 单轮 Token | 累计历史 Token |
|---|---|---|---|---|
| 第 1 轮 | 30 Token | 200 Token | 230 | 230 |
| 第 2 轮 | 20 Token | 150 Token | 170 | 400 |
| 第 3 轮 | 40 Token | 250 Token | 290 | 690 |
| 第 5 轮 | ... | ... | ... | ~1,200 |
| 第 10 轮 | ... | ... | ... | ~2,500 |
| 第 20 轮 | ... | ... | ... | ~5,000 |
这还只是对话历史。别忘了,RAG 系统每次请求还要带上:
- System Prompt:500~1,000 Token(角色定义、行为规则、兜底指令等)
- 检索上下文:2,000~5,000 Token(Top-K chunk 的内容)
- 预留生成空间:500~2,000 Token(模型回答需要的空间)
把这些加起来:
第 10 轮总 Token ≈ 1,000(System)+ 2,500(历史)+ 3,000(检索)+ 1,000(生成)= 7,500 Token
第 20 轮总 Token ≈ 1,000(System)+ 5,000(历史)+ 3,000(检索)+ 1,000(生成)= 10,000 Token
如果用户聊了 50 轮(比如一个复杂的售后问题来回沟通),光对话历史就可能超过 10,000 Token。加上其他部分,总 Token 轻松突破 15,000~20,000。
这会带来两个问题:
- 超出上下文窗口:有些模型的上下文窗口只有 4K 或 8K Token,塞不下这么多内容,请求直接报错
- 费用飙��升:即使模型支持 32K 或 128K 的上下文窗口,Token 越多费用越高。每轮对话都带着完整历史,相当于每次都在为重复发送旧消息付费
所以,会话记忆的核心问题不是要不要记住历史,而是怎么在有限的 Token 预算内,尽可能多地保留有用的历史信息。
会话记忆的五种策略
1. 完整历史(Full History)
最简单粗暴的策略:把所有对话历史全部塞进 messages 数组,一条不丢。
// 完整历史策略:每次请求带上所有历史消息
List<Message> messages = new ArrayList<>();
messages.add(new Message("system", systemPrompt));
messages.addAll(conversationHistory); // 全部历史消息
messages.add(new Message("user", currentQuestion));
这个策略的优点很明显——信息零丢失,模型能看到整个对话过程中的每一句话。
但缺点前面已经算过了:Token 无限膨胀。对话轮数越多,成本越高,最终要么超出上下文窗口,要么费用不可接受。
适用场景:对话轮数确定不超过 5 轮的简单场景,比如一问一答的 FAQ 查询。如果你能确保对话不会太长,用完整历史策略最省心。
2. 滑动窗口(Sliding Window)
滑动窗口是最常用的策略之一:只保留最近 N 轮对话,更早的对话直接丢弃。
打个比方:你的对话历史就像一条传送带,传送带只有 N 格长。每来一轮新对话,就放到传送带末尾;如果传送带满了,最早的那一轮就从头上掉下去。
对话历史(N=3):
第 1 轮对话结束:[第1轮]
第 2 轮对话结束:[第1轮, 第2轮]
第 3 轮对话结束:[第1轮, 第2轮, 第3轮] ← 传送带满了
第 4 轮对话结束:[第2轮, 第3轮, 第4轮] ← 第 1 轮被丢弃
第 5 轮对话结束:[第3轮, 第4轮, 第5轮] ← 第 2 轮被丢弃
优点是实现简单、Token 可控——不管聊了多少轮,历史消息的 Token 上限是固定的。
缺点也很明显:早期对话信息会永久丢失。如果用户在第 1 轮提到了一个关键信息(比如我的订单号是 #12345),到第 6 轮追问“那个订单到货了吗”,系统已经忘了订单号是什么。
那 N 取多大合适?没有标准答案,取决于几个因素:
| 场景 | 推荐 N 值 | 理由 |
|---|---|---|
| 简单 FAQ 问答 | 3~5 | 用户通常 2~3 轮就能得到答案,保留太多没意义 |
| 电商客服 | 5~8 | 退货、售后等场景可能需要来回确认细节 |
| 技术支持 | 8~10 | 排查问题需要较长的上下文,但太长的历史意义不大 |
| 复杂咨询(法律、金融) | 10~15 | 需要保留较多背景信息,但建议配合摘要压缩使用 |
经验法则:从 N=5 开始,根据实际效果调整。如果用户频繁遇到系统忘了之前说的,就增大 N;如果 Token 成本过高,就减小 N。
3. Token 截断(Token Truncation)
滑动窗口按轮数截断,但有一个问题:不同轮的消息长度差别很大。
- 用户说“好的”——2 个 Token
- 用户贴了一段商品描述——500 个 Token
- 模型详细解释退货流程——800 个 Token
如果 N=5,但其中有一轮模型回复特别长(比如 800 Token),5 轮的历史就占了 3,000~4,000 Token。而如果每轮都是简短对话,5 轮可能只占 500 Token。按轮数截断无法精确控制 Token 消耗。
Token 截断策略更精确:给对话历史设一个 Token 上限(比如 4,000 Token),从最新的消息往前算,超出上限的消息直接丢弃。
Token 上限:4,000
当前历史消息(从旧到新):
- 第 1 轮 user: 100 Token ← 超出,丢弃
- 第 1 轮 assistant:500 Token ← 超出,丢弃
- 第 2 轮 user: 50 Token ← 超出,丢弃
- 第 2 轮 assistant:300 Token ← 超出,丢弃
- 第 3 轮 user: 200 Token ✓ 保留(累计 3,800)
- 第 3 轮 assistant:800 Token ✓ 保留(累计 3,600)
- 第 4 轮 user: 100 Token ✓ 保留(累计 2,800)
- 第 4 轮 assistant:1200 Token ✓ 保留(累计 2,700)
- 第 5 轮 user: 500 Token ✓ 保留(累计 1,500)
- 第 5 轮 assistant:1000 Token ✓ 保留(累计 1,000)
注意:截断时要保证成对丢弃——一轮对话的 user 和 assistant 消息要么都保留,要么都丢弃。如果只丢了 user 留了 assistant,模型会看到一个没有问题的回答,容易混乱。
那怎么计算 Token 数呢?精确计算需要用 tokenizer(如 OpenAI 的 tiktoken),但大多数国产模型的 tokenizer 不一��样,而且 Java 生态中没有通用的 tokenizer 库。实际项目中,用字符数估算就够了:
- 中文:1 个汉字 ≈ 1~2 Token
- 英文:1 个单词 ≈ 1~1.5 Token
- 简单估算公式:Token 数 ≈ 中文字符数 × 1.5 + 英文单词数 × 1.3
/**
* 简单的 Token 估算方法
* 精度不高,但足以用于对话历史的截断控制
*/
public static int estimateTokens(String text) {
if (text == null || text.isEmpty()) {
return 0;
}
int chineseChars = 0;
int otherChars = 0;
for (char c : text.toCharArray()) {
if (Character.UnicodeScript.of(c) == Character.UnicodeScript.HAN) {
chineseChars++;
} else if (!Character.isWhitespace(c)) {
otherChars++;
}
}
// 中文:1 字 ≈ 1.5 Token,英文/数字:约 4 字符 ≈ 1 Token
return (int) (chineseChars * 1.5 + otherChars / 4.0);
}
4. 摘要压缩(Summary Compression)
前面两种策略有一个共同的缺陷:被丢弃的历史信息就永远找不回来了。如果用户在第 1 轮提到了一个关键信息,滑动窗口和 Token 截断都会在一定轮数后把它丢掉。
摘要压缩的思路不一样:不是丢掉早期对话,而是用大模型把早期对话压缩成一段简短的摘要。
打个比方:你跟同事接手一个客户工单,同事之前跟客户聊了 20 轮。你不需要看完 20 轮的完整记录,同事给你一段交接说明就行:“客户张先生,买了 iPhone 16 Pro,反映屏幕有亮点,已确认在保修期内,客户希望换新而不是维修,目前在等审批结果。”——这就是摘要。
原来 20 轮对话可能有 5,000 Token,压缩成一段摘要只需要 200~500 Token,但关键信息都保留了。
4.1 摘要 Prompt 的设计
压缩对话历史需要一个专门的 Prompt,告诉模型哪些信息要保留,哪些可以省略。
请将以下对话历史压缩为一段简洁的摘要,要求:
1. 保留用户的核心意图和关注点
2. 保留所有关键实体(产品名、订单号、日期、金额等)
3. 保留已经确认的结论和决定
4. 保留尚未解决的问题
5. 省略寒暄、重复确认、无关细节
6. 摘要以第三人称描述,控制在 200 字以内
对话历史:
{conversation_history}
压缩后的摘要会作为一条 system 或 user 消息放在 messages 的前面,让模型了解之前的对话背景。
4.2 什么时候触发摘要
摘要压缩不是每轮都做——每轮都调用大模型压缩一次,成本太高了。常见的触发策略有三种:
| 触发策略 | 做法 | 优缺点 |
|---|---|---|
| 按轮数触发 | 每隔 N 轮(如每 5 轮)压缩一次 | 简单直��接,但不够灵活,短消息也触发浪费 |
| 按 Token 阈值触发 | 对话历史超过 M Token(如 3,000 Token)时压缩 | 更精确,推荐使用 |
| 按话题切换触发 | 检测到用户换了话题时压缩上一段对话 | 效果最好,但话题切换检测本身有难度 |
推荐使用按 Token 阈值触发。比如设定阈值为 3,000 Token,当对话历史超过 3,000 Token 时,把最早的若干轮对话压缩成摘要,保留最近 2~3 轮完整对话。
需要注意的是,摘要压缩有额外的 API 调用开销:每次压缩都要调一次大模型,会增加延迟和费用。不过压缩用的 Prompt 比较短,可以考虑用小模型(如 Qwen2.5-7B-Instruct)来做,成本很低。
5. 混合策略:摘要 + 最近 N 轮(推荐)
实际生产中,最常用的是混合策略:早期对话压缩成摘要 + 最近 N 轮保留完整对话。
这个策略兼顾了两个需求:
- 长期记忆:通过摘要保留早期对话的关键信息,不会完全丢失
- 短期精度:最近几轮完整对话原封不动地保留,保证模型能准确理解当前话题的细节
混合策略下,发给模型的 messages 数组长这样:
{
"messages": [
{
"role": "system",
"content": "你是一个电商客服助手,基于提供的信息回答用户问题..."
},
{
"role": "system",
"content": "【对话背景摘要】客户咨询 iPhone 16 Pro 的售后问题。已确认:1)客户于 2025 年 1 月 15 日购买,订单号 #20250115001;2)产品屏幕出现亮点,客户已提供照片;3)确认在保修期内(1 年保修,至 2026 年 1 月 15 日);4)客户希望换新而非维修。"
},
{
"role": "user",
"content": "换新的话,是换同款还是可以换其他型号?"
},
{
"role": "assistant",
"content": "根据我们的换新政策,保修期内因质量问题换新,默认更换同款同配置的产品。如果原款已停产或缺货,可以协商更换同价位的其他型号。您的 iPhone 16 Pro 目前在售,所以会换一台全新的同款产品。"
},
{
"role": "user",
"content": "换新之后保修期怎么算?是重新开始还是接着之前的?"
}
]
}
这里有几个要点:
- 摘要放在 system 消息里,紧跟在角色定义之后,让模型优先看到对话背景
- 最近 1~2 轮的完整对话原封不动保留,保证模型理解当前话题
- 总 Token 数 = System Prompt + 摘要(约 200 Token)+ 最近几轮对�话(约 500 Token),远小于保留全部历史的方案
6. 五种策略对比
| 策略 | Token 控制 | 信息保留 | 实现复杂度 | 额外 API 调用 | 适用场景 |
|---|---|---|---|---|---|
| 完整历史 | 无控制 | 完整 | 极低 | 无 | 对话 ≤5 轮的简单场景 |
| 滑动窗口 | 按轮数控制 | 丢失早期 | 低 | 无 | 大多数客服场景 |
| Token 截断 | 按 Token 精确控制 | 丢失早期 | 中 | 无 | 消息长度差异大的场景 |
| 摘要压缩 | 大幅压缩 | 保留关键信息 | 高 | 每次压缩 1 次 | 长对话、需要长期记忆 |
| 混合策略 | 精确可控 | 长期摘要 + 短期完整 | 高 | 触发时 1 次 | 生产级系统(推荐) |
咱们在 Ragent AI 项目中,使用的就是混合策略:长期摘要 + 短期完整。
RAG + 会话记忆:Token 预算分配
1. 上下文窗口要装三样东西
在纯对话场景下,messages ��里主要是 System Prompt + 对话历史,Token 分配比较简单。但在 RAG 场景下,还要塞进检索上下文(chunks),Token 预算就紧张了。
上下文窗口需要装的内容:
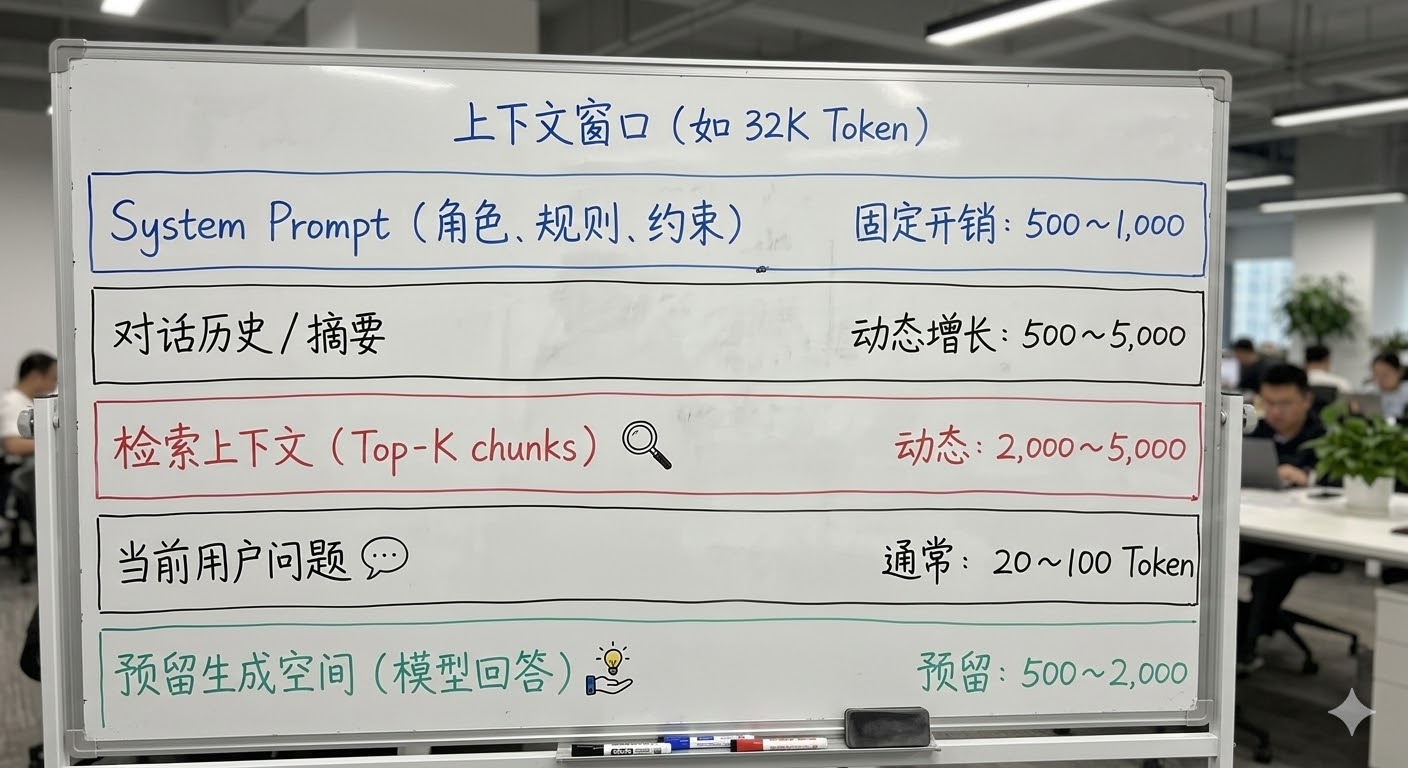
以 32K 上下文窗口为例,推荐的 Token 分配:
| 部分 | 推荐预算 | 说明 |
|---|---|---|
| System Prompt | 1,000 Token | 角色定义 + 行为规则 + 兜底指令 |
| 对话历史 / 摘要 | 4,000 Token | 摘要 + 最近 3~5 轮完整对话 |
| 检索上下文 | 5,000 Token | Top-3 到 Top-5 个 chunk |
| 当前用户问题 | 100 Token | 通常很短 |
| 预留生成空间 | 2,000 Token | 模型回答的最大长度 |
| 总计 | ~12,100 Token | 远低于 32K 上限,留有余量 |
为什么不用满 32K?因为实际使用中,Token 数越大延迟越高、费用越贵。用到总窗口的 30%~50% 通常是最佳平衡点。
很多人第一次做 RAG / Agent 系统时最容易忽略的一点,上下文窗口 = 输入 Token + 输出 Token(模型将要生成的部分)。
如果你用的是 32K 上下文模型:输入 + 输出 ≤ 32K。
2. 分配优先级
当 Token 预算紧张时(比如用了小模型只有 8K 窗口),各部分的优先级是什么?
推荐优先级(从高到低):
- System Prompt:定义模型的行为规则,不能省。没有 System Prompt,模型可能会编造答案、不标注引用、回答超出知识库范围的问题
- 预留生成空间:不够的话模型回答会被截断,用户看到半句话
- 最近 2~3 轮对话:对理解当前意图至关重要。用户说“那它呢”,如果没有最近的对话,模型不知道“它”是什么
- 检索上下文:RAG 的核心价值。没有检索上下文,模型就只能用自己的知识回答,等于 RAG 失效了
- 更早的对话历史:优先级最低,可以用摘要压缩或者直接丢弃
3. 动态调整策略
一个实用的做法是:根据当前对话历史的 Token 数,动态调整检索 chunk 或历史对话的数量。
/**
* 根据对话历史的 Token 数,动态计算可用于检索上下文的 Token 预算
*/
public int calculateChunkBudget(int historyTokens) {
int totalBudget = 12000; // 总 Token 预算
int systemPromptTokens = 1000; // System Prompt 固定开销
int reservedForGeneration = 2000; // 预留生成空间
int queryTokens = 100; // 用户问题
int availableForChunks = totalBudget - systemPromptTokens
- reservedForGeneration - queryTokens - historyTokens;
// 确保至少能放 1 个 chunk(约 500 Token)
return Math.max(500, availableForChunks);
}
这样做的效果是:
- 对话刚开始(历史 Token 少)→ 可以多放几个 chunk,检索信息更丰富
- 对话中期(历史 Token 适中)→ chunk 数量正常
- 对话后期(历史 Token 多)→ 减少 chunk 数量,或者触发摘要压缩腾出空间
会话记忆的存储方案
对话历史需要一个地方存起来。不同场景下,存储方案的选择也不一样。
1. 内存存储(HashMap / ConcurrentHashMap)
最简单的方案:用一个 Map 把每个会话的对话历史存在内存里。
// sessionId → 对话历史列表
Map<String, List<Message>> memoryStore = new ConcurrentHashMap<>();
优点是简单快速,读写都是内存操作。缺点也很明显:服务重启后数据全丢,只能单机使用,对话多了内存占用会很大。
适合开发调试和小规模部署。
2. Redis 存储
用 Redis 存储序列化后的消息列表,天然支持过期清理。
// 存储:将消息列表序列化为 JSON 存入 Redis,设置 30 分钟过期
String key = "chat:session:" + sessionId;
redisTemplate.opsForValue().set(key, gson.toJson(messages), 30, TimeUnit.MINUTES);
// 读取:从 Redis 取出并反序列化
String json = redisTemplate.opsForValue().get(key);
List<Message> messages = gson.fromJson(json, new TypeToken<List<Message>>(){}.getType());
优点:分布式(多个服务实例共享)、高性能、自带过期机制。缺点:需要序列化 / 反序列化,Redis 重启也会丢数据(除非开启持久化)。
适合生产环境。
3. 数据库存储(MySQL)
用数据库表存储每条消息,字段设计大概是这样:
CREATE TABLE conversation_message (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
session_id VARCHAR(64) NOT NULL,
role VARCHAR(16) NOT NULL COMMENT 'system/user/assistant',
content TEXT NOT NULL,
token_count INT DEFAULT 0 COMMENT '该消息的 Token 数',
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
INDEX idx_session_id (session_id)
);
优点:持久化、可审计(查看任意历史对话)、可做数据分析(统计热门问题、平均对话轮数等)。缺点:读写性能比内存和 Redis 低,需要数据库连接管理。
适合需要审计和数据分析的企业场景。
4. 选型建议
| 维度 | 内存 | Redis | 数据库(MySQL) |
|---|---|---|---|
| 读写性能 | 极快(纳秒) | 快(毫秒) | 较慢(毫秒~十毫秒) |
| 持久化 | 不支持 | 可选(AOF/RDB) | 天然支持 |
| 分布式 | 不支持 | 天然支持 | 支持 |
| 过期清理 | 需自己实现 | 原生支持(TTL) | 需定时任务 |
| 实现复杂度 | 极低 | 低 | 中 |
| 适用场景 | 开发调试 | 生产环境 | 审计 / 分析场景 |
生产环境推荐方案:Redis 做主存储 + MySQL 做归档。对话进行时,消息存 Redis(快速读写);对话结束后,异步写入 MySQL(持久化、审计)。
Java 实战:多轮对话的记忆效果
本节不串联完整的 RAG 检索流程(之前的文档已经讲过),重点展示会话记忆的核心机制——把历史消息传给大模型 API,体现"有记忆"和"无记忆"的效果差异。
1. 无记忆 vs 有记忆的效果对比
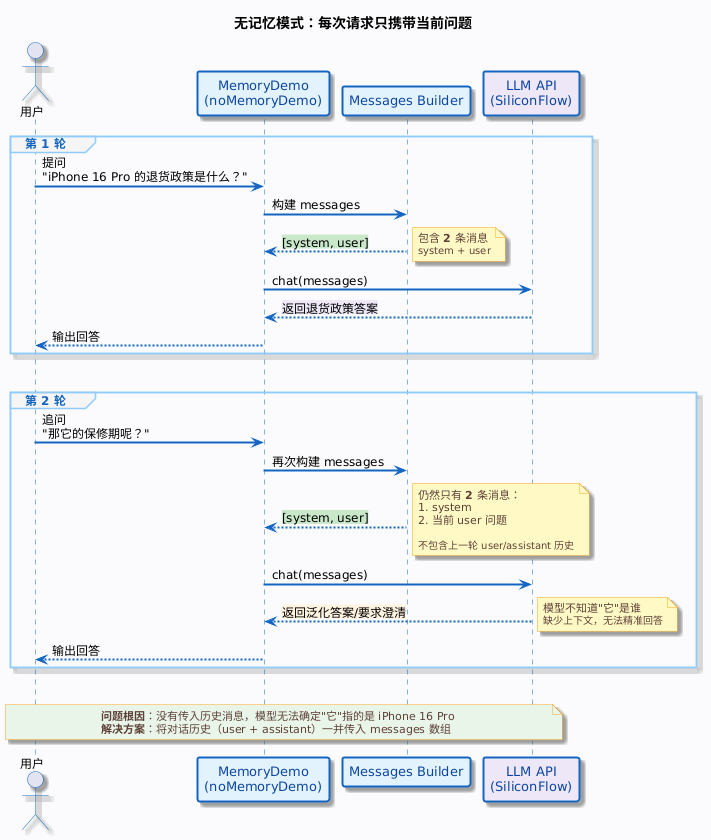
先来看最直观的对比:同样的追问,不带历史消息和带历史消息,模型的回答天差地别。
不带历史消息对话:
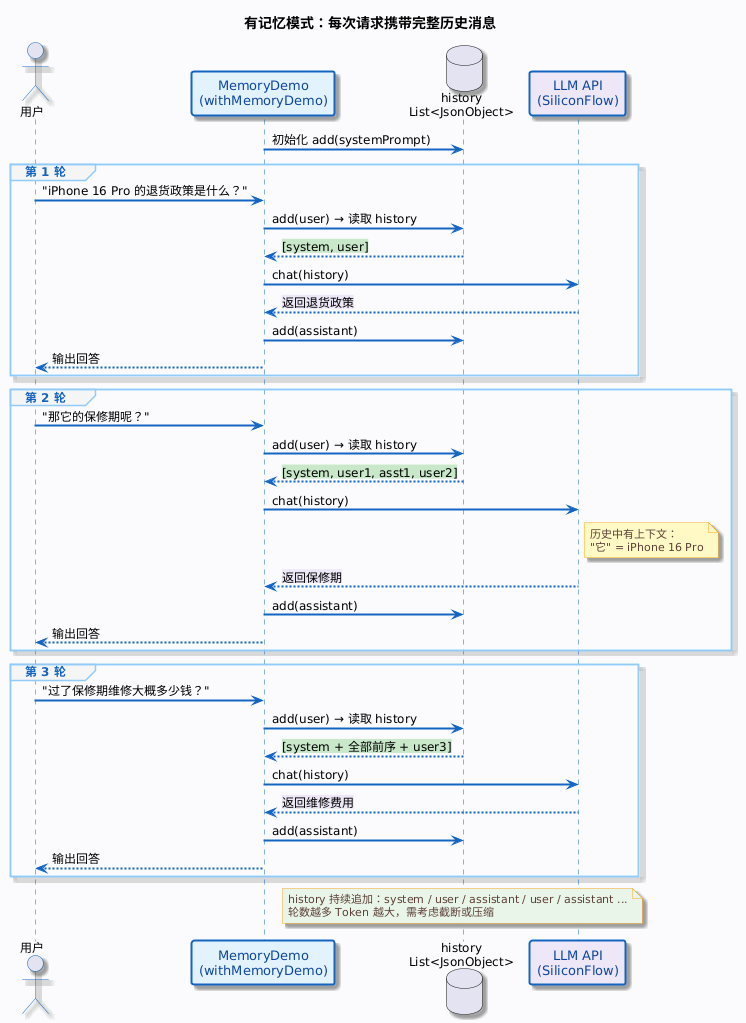
带历史消息对话:
示例代码如下所示:
import com.google.gson.*;
import okhttp3.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class MemoryDemo {
private static final String API_URL = "https://api.siliconflow.cn/v1/chat/completions";
private static final String API_KEY = "your-api-key";
private static final String MODEL = "Qwen/Qwen3-8B";
private static final OkHttpClient client = new OkHttpClient();
private static final Gson gson = new Gson();
public static void main(String[] args) throws IOException {
System.out.println("===== 无记忆模式 =====");
noMemoryDemo();
System.out.println("\n===== 有记忆模式 =====");
withMemoryDemo();
}
/**
* 无记忆模式:每次请求只带当前问题,不带历史消息
*/
static void noMemoryDemo() throws IOException {
// 第 1 轮
String answer1 = chat(List.of(
message("system", "你是一个电商客服助手,简洁回答用户问题。"),
message("user", "iPhone 16 Pro 的退货政策是什么?")
));
System.out.println("用户:iPhone 16 Pro 的退货政策是什么?");
System.out.println("助手:" + answer1);
// 第 2 轮:不带历史消息,模型不知道"它"是什么
String answer2 = chat(List.of(
message("system", "你是一个电商客服助手,简洁回答用户问题。"),
message("user", "那它的保修期呢?")
));
System.out.println("\n用户:那它的保修期呢?");
System.out.println("助手:" + answer2);
}
/**
* 有记忆模式:每次请求带上完整的历史消息
*/
static void withMemoryDemo() throws IOException {
List<JsonObject> history = new ArrayList<>();
history.add(message("system", "你是一个电商客服助手,简洁回答用户问题。"));
// 第 1 轮
history.add(message("user", "iPhone 16 Pro 的退货政策是什么?"));
String answer1 = chat(history);
history.add(message("assistant", answer1));
System.out.println("用户:iPhone 16 Pro 的退货政策是什么?");
System.out.println("助手:" + answer1);
// 第 2 轮:带上第 1 轮的历史,模型知道"它"指 iPhone 16 Pro
history.add(message("user", "那它的保修期呢?"));
String answer2 = chat(history);
history.add(message("assistant", answer2));
System.out.println("\n用户:那它的保修期呢?");
System.out.println("助手:" + answer2);
// 第 3 轮:继续追问
history.add(message("user", "过了保修期维修大概多少钱?"));
String answer3 = chat(history);
System.out.println("\n用户:过了保修期维修大概多少钱?");
System.out.println("助手:" + answer3);
}
/**
* 调用 SiliconFlow Chat API
*/
static String chat(List<JsonObject> messages) throws IOException {
JsonObject body = new JsonObject();
body.addProperty("model", MODEL);
body.addProperty("temperature", 0.1);
body.addProperty("max_tokens", 512);
JsonArray messagesArray = new JsonArray();
for (JsonObject msg : messages) {
messagesArray.add(msg);
}
body.add("messages", messagesArray);
Request request = new Request.Builder()
.url(API_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(body.toString(),
MediaType.parse("application/json")))
.build();
try (Response response = client.newCall(request).execute()) {
String responseBody = response.body().string();
JsonObject json = gson.fromJson(responseBody, JsonObject.class);
return json.getAsJsonArray("choices")
.get(0).getAsJsonObject()
.getAsJsonObject("message")
.get("content").getAsString();
}
}
static JsonObject message(String role, String content) {
JsonObject msg = new JsonObject();
msg.addProperty("role", role);
msg.addProperty("content", content);
return msg;
}
}
运行结果(示意):
===== 无记忆模式 =====
用户:iPhone 16 Pro 的退货政策是什么?
助手:iPhone 16 Pro 的退货政策通常遵循 Apple 的标准退货流程。根据 Apple 官方政策:
- **7 天无理由退货**:在收到商品后 7 天内,如无质量问题,可申请无理由退货。
- **质量问题退货**:如商品存在质量问题,可申请退换货,且不收取退货费用。
- **退货方式**:需通过 Apple 官方渠道(如 Apple 官网、Apple Store 或授权经销商)申请退货,并保留原始包装和发票。
- **退款方式**:退款将原路返回至支付账户,具��体时间视支付方式而定。
建议在退货前联系 Apple 客服确认具体政策,以确保顺利操作。
用户:那它的保修期呢?
助手:我们的产品保修期一般为1年,具体以商品详情页标注为准。如有疑问,欢迎随时咨询!
===== 有记忆模式 =====
用户:iPhone 16 Pro 的退货政策是什么?
助手:iPhone 16 Pro 的退货政策通常遵循 Apple 的标准退货规则。根据 Apple 官方政策:
1. **7 天无理由退货**:自收货之日起 7 天内,如商品未使用、包装完好,可申请无理由退货。
2. **14 天质量问题退货**:若商品存在质量问题,可申请 14 天内退货。
3. **需保留原始包装和发票**。
4. **退货需通过 Apple 官方渠道或授权零售商进行**。
建议您查看购买时的订单详情或联系 Apple 客服确认具体政策。
用户:那它的保修期呢?
助手:iPhone 16 Pro 的保修期为 **1 年**,自购买日期起算。
保修范围包括制造缺陷和硬件故障,但不包括人为损坏或意外损坏(如摔落、进水等)。
如需延长保修,可购买 AppleCare+ 服务计划。建议查看购买凭证或联系 Apple 官方客服确认具体保修信息。
用户:过了保修期维修大概多少钱?
助手:iPhone 16 Pro 过了 1 年保修期后,维修费用会根据具体问题而有所不同。一般情况下:
- **屏幕维修**:约 1200-1500 元(视型号和维修内容而定)
- **电池更换**:约 600-800 元
- **主板/其他部件维修**:费用较高,通常在 1500 元以上
建议您联系 Apple 官方售后或授权维修点,提供具体问题以获取准确报价。
效果一目了然:无记忆模式下,模型不知道“它”是什么;有记忆模式下,模型能正确理解上下文,连续追问都没问题。
2. 滑动窗口策略实现
接下来实现一个简单的(非并发模式)支持滑动窗口的会话记忆管理器。
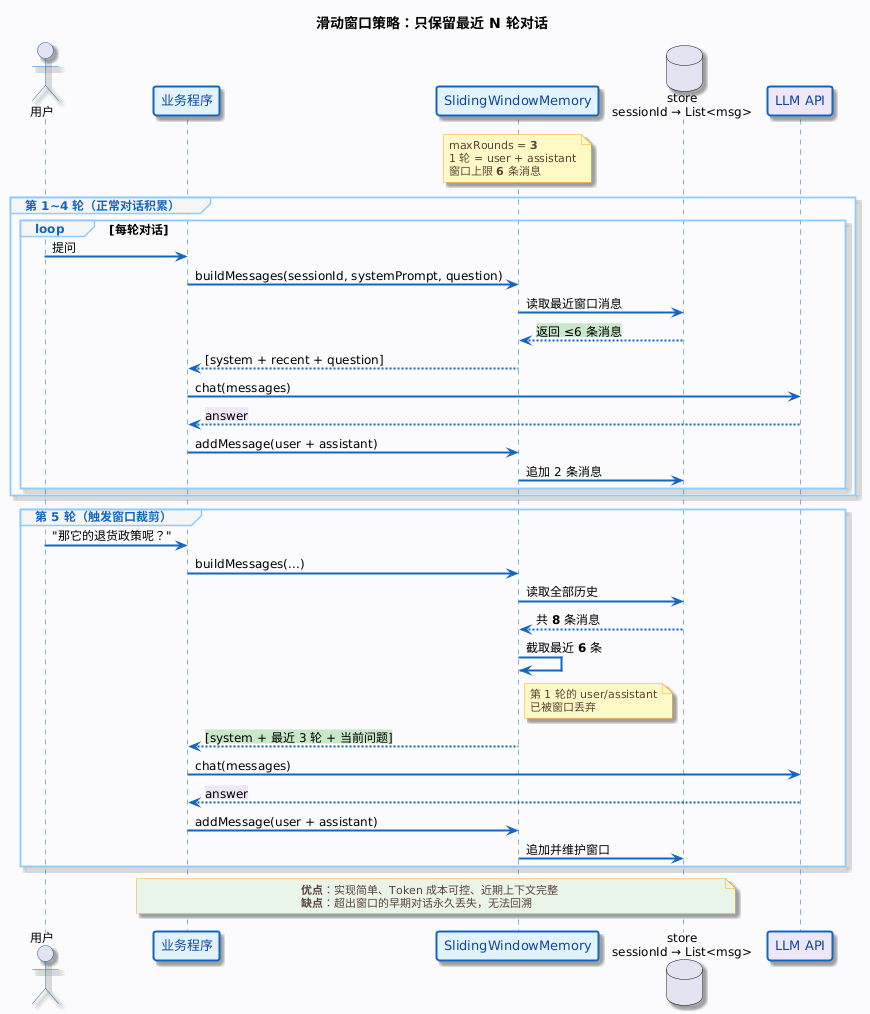
示例代码如下所示:
import com.google.gson.JsonObject;
import java.util.*;
/**
* 滑动窗口会话记忆管理器
*/
public class SlidingWindowMemory {
/** 最大保留轮数(1 轮 = 1 个 user + 1 个 assistant) */
private final int maxRounds;
/** 会话存储:sessionId → 消息列表 */
private final Map<String, List<JsonObject>> store = new HashMap<>();
public SlidingWindowMemory(int maxRounds) {
this.maxRounds = maxRounds;
}
/**
* 添加一条消息
*/
public void addMessage(String sessionId, String role, String content) {
store.computeIfAbsent(sessionId, k -> new ArrayList<>())
.add(message(role, content));
}
/**
* 获取最近 N 轮的消息(滑动窗口)
* 一轮 = user + assistant 两条消息
*/
public List<JsonObject> getRecentMessages(String sessionId) {
List<JsonObject> allMessages = store.getOrDefault(sessionId, List.of());
if (allMessages.isEmpty()) {
return List.of();
}
// 计算要保留的消息数量:maxRounds 轮 × 2 条/轮
int keepCount = maxRounds * 2;
if (allMessages.size() <= keepCount) {
return new ArrayList<>(allMessages);
}
// 只保留最近的 keepCount 条消息
return new ArrayList<>(
allMessages.subList(allMessages.size() - keepCount, allMessages.size())
);
}
/**
* 构建发��送给 API 的完整 messages 数组
*/
public List<JsonObject> buildMessages(String sessionId,
String systemPrompt,
String currentQuestion) {
List<JsonObject> messages = new ArrayList<>();
messages.add(message("system", systemPrompt));
messages.addAll(getRecentMessages(sessionId));
messages.add(message("user", currentQuestion));
return messages;
}
private JsonObject message(String role, String content) {
JsonObject msg = new JsonObject();
msg.addProperty("role", role);
msg.addProperty("content", content);
return msg;
}
}
使用示例:
public static void main(String[] args) throws IOException {
// 创建一个只保留最近 3 轮对话的记忆管理器
SlidingWindowMemory memory = new SlidingWindowMemory(3);
String sessionId = "session-001";
String systemPrompt = "你是一个电商客服助手,简洁回答用户问题。";
// 模拟 5 轮对话
String[] questions = {
"iPhone 16 Pro 多少钱?", // 第 1 轮
"有什么颜色可选?", // 第 2 轮
"白色的有现货吗?", // 第 3 轮
"支持分期吗?", // 第 4 轮(第 1 轮被丢弃)
"那它的退货政策呢?" // 第 5 轮(第 2 轮被丢弃)
};
for (String question : questions) {
// 构建消息(自动应用滑动窗口)
List<JsonObject> messages = memory.buildMessages(
sessionId, systemPrompt, question);
// 调用 API
String answer = chat(messages);
// 保存对话历史
memory.addMessage(sessionId, "user", question);
memory.addMessage(sessionId, "assistant", answer);
System.out.println("用户:" + question);
System.out.println("助手:" + answer);
System.out.println("当前记忆中的消息数:" +
memory.getRecentMessages(sessionId).size());
System.out.println();
}
}
到第 5 轮时,记忆中只保留第 3、4、5 轮的对话,第 1、2 轮已经被丢弃。如果用户在第 5 轮问"那个价格再说一下",模型已经不记得第 1 轮聊过的价格了。
3. 摘要压缩策略实现
当对话历史的 Token 超过阈值时,调用大模型把早期对话压缩成一段摘要。
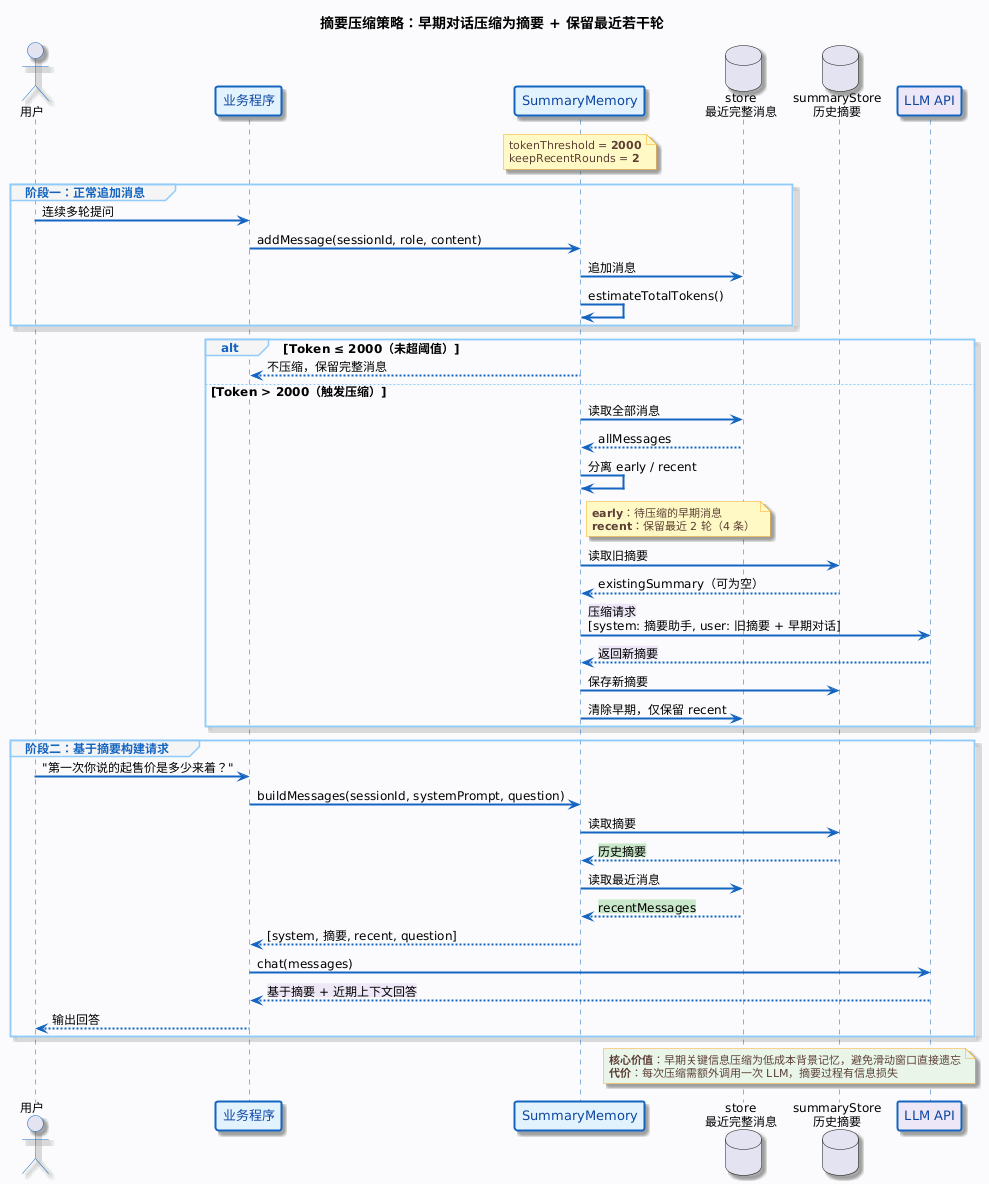
示例代码如下:
import com.google.gson.*;
import okhttp3.*;
import java.io.IOException;
import java.util.*;
/**
* 支持摘要压缩的会话记忆管理器
*/
public class SummaryMemory {
/** 触发摘要的 Token 阈值 */
private final int tokenThreshold;
/** 保留最近的完整对话轮数 */
private final int keepRecentRounds;
/** 会话存储 */
private final Map<String, List<JsonObject>> store = new HashMap<>();
/** 摘要存储 */
private final Map<String, String> summaryStore = new HashMap<>();
public SummaryMemory(int tokenThreshold, int keepRecentRounds) {
this.tokenThreshold = tokenThreshold;
this.keepRecentRounds = keepRecentRounds;
}
public void addMessage(String sessionId, String role, String content) {
store.computeIfAbsent(sessionId, k -> new ArrayList<>())
.add(message(role, content));
// 检查是否需要触发摘要压缩
int totalTokens = estimateTotalTokens(sessionId);
if (totalTokens > tokenThreshold) {
try {
compress(sessionId);
} catch (IOException e) {
System.err.println("摘要压缩失败:" + e.getMessage());
}
}
}
/**
* 压缩早期对话为摘要
*/
private void compress(String sessionId) throws IOException {
List<JsonObject> allMessages = store.get(sessionId);
if (allMessages == null || allMessages.size() <= keepRecentRounds * 2) {
return;
}
// 分离:早期消息(要压缩的)+ 最近消息(要保留的)
int keepCount = keepRecentRounds * 2;
List<JsonObject> earlyMessages = allMessages.subList(
0, allMessages.size() - keepCount);
List<JsonObject> recentMessages = new ArrayList<>(
allMessages.subList(allMessages.size() - keepCount, allMessages.size()));
// 构建要压缩的对话文本
StringBuilder conversationText = new StringBuilder();
for (JsonObject msg : earlyMessages) {
String role = msg.get("role").getAsString();
String content = msg.get("content").getAsString();
conversationText.append(role).append(":").append(content).append("\n");
}
// 获取已有的摘要
String existingSummary = summaryStore.getOrDefault(sessionId, "");
// 调用大模型生成摘要
String summaryPrompt = "请将以下对话历史压缩为一段简洁的摘要,要求:\n" +
"1. 保留用户的核心意图和关注点\n" +
"2. 保留所有关键实体(产品名、订单号、日期、金额等)\n" +
"3. 保留已经确认的结论和决定\n" +
"4. 保留尚未解决的问题\n" +
"5. 省略寒暄、重复确认、无关细节\n" +
"6. 摘要以第三人称描述,控制在 200 字以内\n";
if (!existingSummary.isEmpty()) {
summaryPrompt += "\n已有的历史摘要:\n" + existingSummary + "\n";
}
summaryPrompt += "\n需要压缩的新对话:\n" + conversationText;
String summary = chat(List.of(
message("system", "你是一个对话摘要助手,负责将对话历史压缩为简洁的摘要。"),
message("user", summaryPrompt)
));
// 更新摘要和消息列表
summaryStore.put(sessionId, summary);
store.put(sessionId, recentMessages);
System.out.println("[摘要压缩] 将 " + earlyMessages.size() +
" 条早期消息压缩为摘要");
System.out.println("[摘要内容] " + summary);
}
/**
* 构建发送给 API 的完整 messages 数组
*/
public List<JsonObject> buildMessages(String sessionId,
String systemPrompt,
String currentQuestion) {
List<JsonObject> messages = new ArrayList<>();
messages.add(message("system", systemPrompt));
// 添加摘要(如果有)
String summary = summaryStore.get(sessionId);
if (summary != null && !summary.isEmpty()) {
messages.add(message("system",
"【对话背景摘要】" + summary));
}
// 添加最近的完整对话
List<JsonObject> recentMessages = store.getOrDefault(
sessionId, List.of());
messages.addAll(recentMessages);
// 添加当前问题
messages.add(message("user", currentQuestion));
return messages;
}
private int estimateTotalTokens(String sessionId) {
List<JsonObject> messages = store.getOrDefault(sessionId, List.of());
int total = 0;
for (JsonObject msg : messages) {
total += estimateTokens(msg.get("content").getAsString());
}
return total;
}
/** 简单的 Token 估算 */
static int estimateTokens(String text) {
if (text == null || text.isEmpty()) return 0;
int chineseChars = 0, otherChars = 0;
for (char c : text.toCharArray()) {
if (Character.UnicodeScript.of(c) == Character.UnicodeScript.HAN) {
chineseChars++;
} else if (!Character.isWhitespace(c)) {
otherChars++;
}
}
return (int) (chineseChars * 1.5 + otherChars / 4.0);
}
// chat() ��和 message() 方法与前面的 MemoryDemo 相同,此处省略
}
4. 运行效果展示
用一个多轮对话示例,对比三种记忆策略的效果:
场景:用户围绕 iPhone 16 Pro 连续咨询 6 个问题。返回内容大概如下所示:
===== 无记忆模式 =====
第 1 轮 - 用户:iPhone 16 Pro 多少钱?
助手:iPhone 16 Pro 起售价 7,999 元(128GB),256GB 版本 8,999 元,512GB 版本 10,999 元,1TB 版本 12,999 元。
第 2 轮 - 用户:那它的保修期呢?
助手:请问您想了解哪款产品的保��修期?请提供具体的产品名称。
❌ 模型不知道"它"是什么
===== 滑动窗口(N=3) =====
第 1 轮 - 用户:iPhone 16 Pro 多少钱?
助手:iPhone 16 Pro 起售价 7,999 元...(正常回答)
第 2 轮 - 用户:有什么颜色?
助手:iPhone 16 Pro 有沙漠色钛金属、自然色钛金属、白色钛金属和黑色钛金属四种颜色可选。
第 3 轮 - 用户:我想要白色 256GB 的
助手:好的,白色钛金属 256GB 版本售价 8,999 元,目前有现货。
第 4 轮 - 用户:支持分期吗?
助手:支持,可以选择 3/6/12/24 期免息分期...
第 5 轮 - 用户:它多少钱来着?
助手:您看中的白色钛金属 256GB iPhone 16 Pro 售价 8,999 元。
✅ 第 3 轮的信息还在窗口内,能记住
第 6 轮 - 用户:第一次你说的起售价是多少来着?
助手:抱歉,我不太确定您之前提到的具体信息...
❌ 第 1 轮已被丢弃,价格信息丢失
===== 摘要压缩(阈值 2000 Token,保留最近 2 轮) =====
[摘要压缩] 将 4 条早期消息压缩为摘要
[摘要内容] 客户咨询 iPhone 16 Pro,了解到起售价 7,999 元(128GB),
�有四种钛金属颜色可选,客户偏好白色 256GB 版本(8,999 元),目前有现货。
第 6 轮 - 用户:第一次你说的起售价是多少来着?
助手:iPhone 16 Pro 的起售价是 7,999 元(128GB 版本)。
✅ 早期信息通过摘要保留了下来
从效果对比可以看出:
- 无记忆:第 2 轮就失忆了,用户体验极差
- 滑动窗口:近期信息记得住,但超出窗口的早期信息丢了
- 摘要压缩:关键信息都保留了,Token 也控制住了,但实现复杂度更高
生产环境的注意事项
1. 会话超时与清理
不管用哪种存储方案,都要设置会话过期时间。用户关掉页面、30 分钟没说话,对话历史就应该被清理掉。
- 内存存储:可以用定时任务扫描,或者用 Caffeine / Guava Cache 的过期机制
- Redis 存储:设置 TTL(如 30 分钟),Redis 自动过期清理
- 数据库存储:考虑到磁盘存储��成本较低,可以考虑定时任务清理已删除会话,或者标记为“已关闭”
如果不做清理,内存和 Redis 会无限增长,最终导致服务 OOM 或 Redis 内存不足。
注意,生产环境中,如果使用 Redis 存储,即使缓存被删除,但是当用户未删除对话,还可以从 MySQL 读取历史内容重新对话。
2. 敏感信息处理
对话历史中可能包含用户的敏感信息:身份证号、手机号、银行卡号、密码等。存储时需要考虑:
- 脱敏存储:对敏感字段做掩码处理(如手机号显示为 138****1234)
- 加密存储:对整个消息内容加密,读取时解密
- 访问控制:限制谁能查看对话历史,记录访问日志
在金融、医疗等合规要求严格的行业,这一点尤其重要。
3. 对话历史的可观测性
生产环境中,你需要知道每轮对话的关键指标:
- Token 消耗:每轮对话消耗了多少 Token,对话历史占了多少,检索上下文占了多少
- 是否触发摘要压缩:压缩了几次,压缩前后的 Token 变化
- 响应时间:从接收用户消息到返回答案的总耗时,其中摘要压缩、检索、生成各占多少
- 记忆命中率:用户追问时,系统是否正确理解了上下文(可以通过用户反馈��或人工抽检统计)
这些指标可以帮你发现问题(比如某些场景下摘要压缩丢了关键信息)和优化策略(比如调整窗口大小或压缩阈值)。
小结与下一篇预告
这篇讲了 RAG 系统的会话记忆,核心要点回顾:
- 大模型没有记忆:每次 API 调用都是独立的,记忆完全靠你的代码把对话历史塞进 messages 数组实现
- Token 膨胀是核心问题:对话轮数越多,历史消息占用的 Token 越多,挤压了检索上下文和生成空间的预算
- 五种记忆策略:完整历史(简单但不可持续)、滑动窗口(实用但丢早期信息)、Token 截断(更精确的滑动窗口)、摘要压缩(保留关键信息但复杂度高)、混合策略(推荐,兼顾长短期记忆)
- Token 预算分配:RAG 场景下,上下文窗口要同时装 System Prompt、对话历史、检索上下文和生成空间,需要合理分配并动态调整
- 存储选型:开发用内存,生产用 Redis,审计用数据库
会话记忆解决了让系统记住之前聊了什么的问题。但在 RAG 场景下,还有一个关键问题没解决。
回到开篇的例子:用户先问“iPhone 16 Pro 的退货政策是什么”,然后追问“那它的保修期呢”。有了会话记忆,模型能理解“它”指的是 iPhone 16 Pro,回答没问题。但别忘了,RAG 系统在回答之前要先去向量数据库检索——检索系统拿到的 query 是“那它的保修期呢”。“它”没有任何语义信息,向量化之后检索效果会很差,召回的可能是一堆不相关的内容。
也�就是说,模型记住了上下文,但检索系统没有。要让多轮对话的 RAG 检索真正靠谱,还需要一步:把“那它的保修期呢”改写成“iPhone 16 Pro 的保修期”,再拿去检索。
下一篇咱们就来聊 Query 改写——怎么结合对话历史,把用户含糊的追问自动改写成完整的检索查询,让多轮对话下的 RAG 检索不掉链子。