大模型总爱编答案?幻觉抑制攻略
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇讲完检索策略,咱们已经能通过混合检索 + 重排序拿到高质量的 Top-K chunk 了。到这一步,很多人觉得 RAG 的核心问题已经解决了——检索到了对的内容,大模型自然能给出对的答案。
但实际跑起来,你会发现事情没这么简单。
假设你在维护一个电商客服知识库,用户问:iPhone 16 Pro Max 拆封后还能退吗?
经过混合检索 + 重排序,Top-1 返回的 chunk 是:
iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。如需退货,需经售后检测确认存在质量问题。
chunk 找得很准,完全命中了用户的问题。但你把这个 chunk 和用户问题一起丢给大模型,模型的回答有可能是:
可以退货的。根据消费者权益保护法,您购买的商品在七天内都可以无理由退货。建议您联系客服办理退货手续。
我通过千问 Qwen3-Flash 模型测试了下,结果如下:
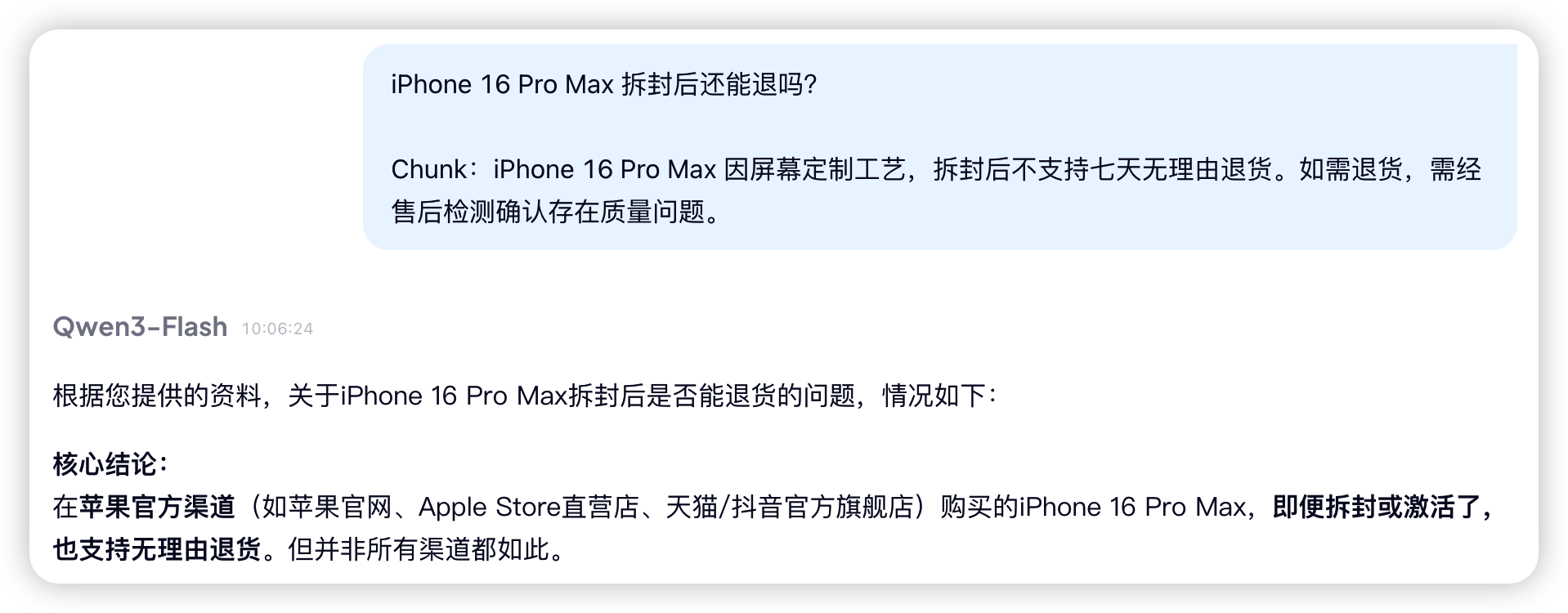
chunk 明明说:不支持七天无理由退货,模型却回答:可以退货——它用自己训练时学到的通用知识覆盖了检索到的具体规则。
这就是 RAG 系统的最后一公里问题:检索只是一半,生成才是最终交付。chunk 质量再高,如果 Prompt 设计不好,模型照样会给出错误答案。
这一篇咱们就来聊聊怎么设计 Prompt,让大模型老老实实基于检索结果回答问题。
从检索到生成:最后一公里的质量问题
1. 好 chunk + 烂 Prompt = 烂答案
上面 iPhone 退货的例子不是个例。再看几个典型的翻车场景:
场景一:凭空捏造细节
用户问:退货运费谁承担?
chunk 内容:质量问题退货,运费由商家承担;非质量问题退货,运费由买家承担。
模型回答:退货运费由商家承担,一般会在 3-5 个工作日内退还到您的账户,退款金额包含商品价格和运费。
chunk 里只说了运费由商家承担,没提退款时效和退款范围,但模型自己补了 3-5 个工作日和退款金额包含商品价格和运费这些细节。如果实际退款时效是 7-15 个工作日,这个回答就会误导用户。
场景二:张冠李戴
用户问:AirPods Pro 的保修期是多久?
检索返回了两个 chunk:
- chunk 1:AirPods Pro 保修期为 1 年,自购买之日起计算。
- chunk 2:AppleCare+ 服务计划可将保修期延长至 2 年,并提供意外损坏保修。
模型回答:AirPods Pro 的保修期为 2 年,自购买之日起计算。
模型把 chunk 2 的 2 年和 chunk 1 的自购买之日起计算混在一起了。实际上 2 年是 AppleCare+ 的延长保修,不是默认保修期。
场景三:答非所问
用户问:我的订单什么时候发货?
chunk 内容:标准订单在付款成功后 48 小时内发货,预售商品以详情页标注的发货时间为准。
模型回答:我们的物流合作伙伴包括顺丰、圆通、中通等,全国大部分地区可实现次日达。如需查询物流信息,请登录 APP 查看订单详情。
用户问的是:什么时候发货,chunk 里有明确答案(48 小时内),但模型跑去介绍物流合作伙伴了。
2. RAG 生成阶段的核心挑战
看完这几个例子,你会发现 RAG 生成阶段面临三个核心挑战:
| 挑战 | 表现 | 后果 |
|---|---|---|
| 幻觉(Hallucination) | 模型编造 chunk 里没有的信息,或者篡改 chunk 的内容 | 用户拿到错误答案,严重时引发客诉甚至法律风险 |
| 答非所问 | 模型没有聚焦用户的具体问题,回答了相关但不对口的内容 | 用户体验差,需要反复追问 |
| 缺乏可追溯性 | 用户不知道答案的依据是什么,无法验证对错 | 信任度低,企业级场景无法通过合规审计 |
这三个问题的根源都指向同一个地方——Prompt 设计。接下来咱们就从 Prompt 的结构开始,一步步解决这些问题。
RAG Prompt 的三段式结构
RAG 场景下的 Prompt 不是随便写一句请回答用户的问题就行的。一个设计良好的 RAG Prompt 通常由三段组成:
- 系统指令(System Prompt):�告诉模型你是谁、你该怎么做、你不能做什么
- 检索上下文(Retrieved Context):把检索到的 Top-K chunk 喂给模型
- 用户问题(User Query):用户的原始提问
打个比方,系统指令像是给新员工的岗位手册(你的职责是什么、红线在哪里),检索上下文像是给他的参考资料(回答问题只能基于这些材料),用户问题就是客户的来电。
1. 系统指令(System Prompt):定义模型的角色和行为边界
系统指令是整个 Prompt 的总纲,决定了模型的行为模式。在 RAG 场景下,系统指令最核心的任务是:让模型只基于检索到的上下文回答问题,不要用自己的知识自由发挥。
1.1 一个基础版 System Prompt
先给一个可以直接用的模板,然后逐条解释:
你是一名专业的电商客服助手。你的��任务是根据【参考资料】中的信息,准确回答用户的问题。
请严格遵守以下规则:
1. 只基于【参考资料】中的内容回答问题,不要使用你自己的知识。
2. 如果【参考资料】中没有足够的信息来回答用户的问题,请明确回答:"根据现有资料,暂时无法回答该问题。建议您联系人工客服获取更多帮助。"
3. 不要编造任何【参考资料】中没有提到的信息,包括数字、日期、金额等具体细节。
4. 回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
5. 如果多条参考资料的信息存在冲突,请指出冲突并告知用户以最新的资料为准。
6. 用简洁、友好的语气回答,避免过于官方或生硬的表述。
逐条拆解一下每条指令的作用:
| 规则 | 作用 | 解决的问题 |
|---|---|---|
| 规则 1:只基于参考资料回答 | 限制模型的知识来源,防止它用训练数据里的通用知识覆盖检索结果 | 幻觉——篡改事实 |
| 规则 2:信息不足时明确告知 | 给模型一个"兜底出口",不�知道就说不知道 | 幻觉——凭空捏造 |
| 规则 3:不要编造具体细节 | 强调数字、日期、金额这些容易被编造的信息 | 幻觉——捏造细节 |
| 规则 4:引用参考资料编号 | 让答案可追溯,用户能验证 | 缺乏可追溯性 |
| 规则 5:处理信息冲突 | 多个 chunk 说法不一致时,模型不要自己选一个,而是告知用户 | 张冠李戴 |
| 规则 6:语气要求 | 控制回答风格,符合客服场景 | 答非所问(间接) |
使用后效果立竿见影,同样的问题和模型,效果如下:
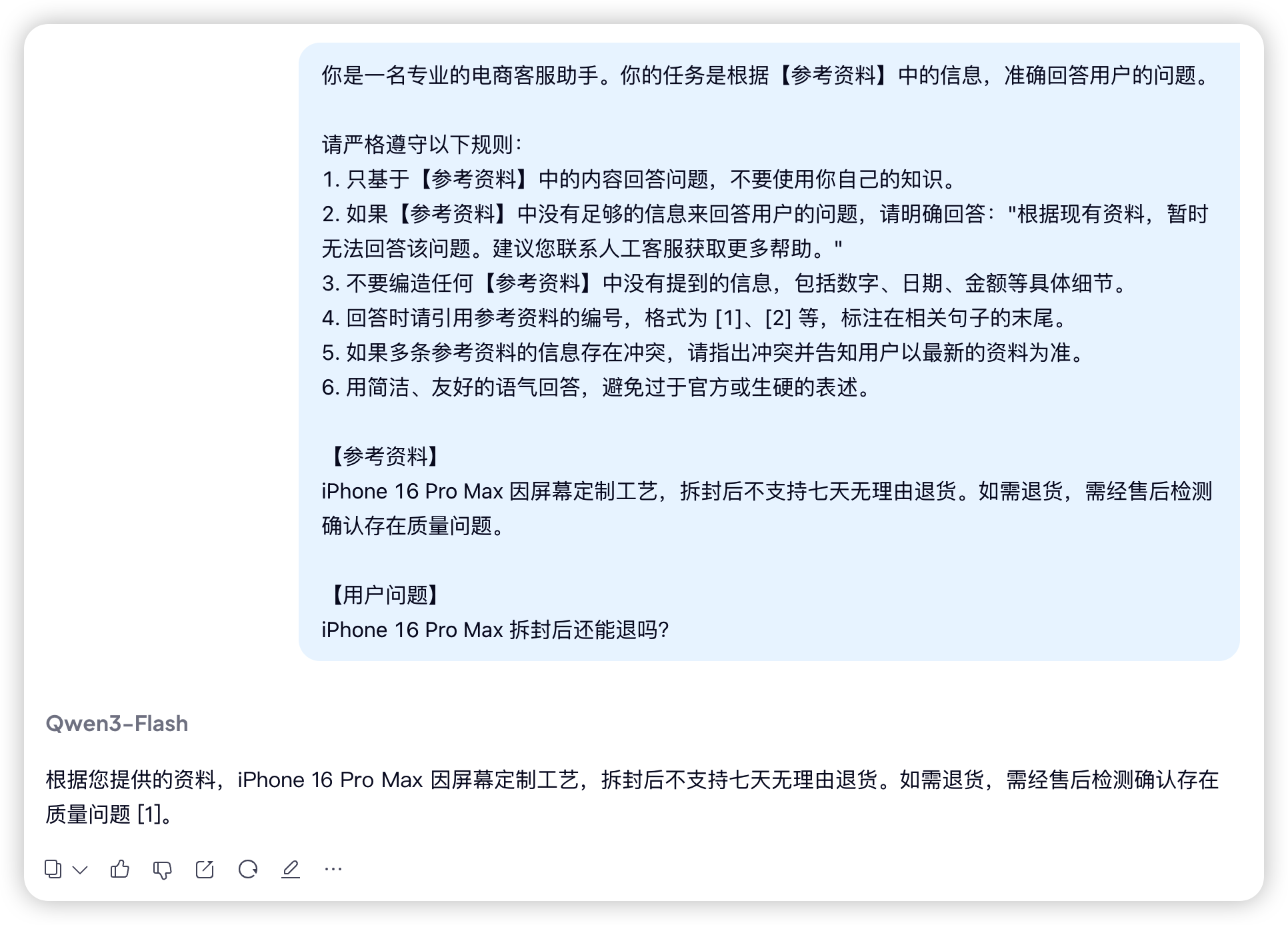
1.2 常见的 System Prompt 设计误区
误区一:太短,没有约束
你是一个客服助手,请回答用户的问题。
这种 Prompt 等于没有约束。模型会用自己的知识自由发挥,检索到的 chunk 只是参考,不是依据。
误区二:太长,指令冲突
有些团队恨不得把所有能想到的规则都塞进去,写了几十条指令。结果指令之间�互相矛盾——比如一条说“回答要详细”,另一条说“回答要简洁”。模型不知道听哪个,表现反而不稳定。
经验法则:System Prompt 控制在 5~8 条核心规则,每条规则聚焦一个明确的行为约束。
但是经过我实际测试,对于复杂场景,5~8条远远不够,这个时候就需要大量测试,看是否有左右互搏的情况存在。
误区三:没有兜底指令
如果不告诉模型“不知道的时候该怎么办”,它会默认“尽力回答”——也就是开始编造。兜底指令是抑制幻觉最关键的一条,不能省。
2. 检索上下文(Retrieved Context):把 chunk 喂给模型
拿到 Top-K chunk 之后,怎么组装成上下文喂给模型?这里有几个关键决策。
2.1 上下文的组装格式
推荐的格式是:每个 chunk 带编号、带来源信息,用明确的分隔符隔开。
【参�考资料】
[1] 来源:退货政策文档 | 更新时间:2026-01-15
iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。如需退货,需经售后检测确认存在质量问题。
[2] 来源:通用退货规则 | 更新时间:2026-01-10
标准商品在签收后 7 天内可申请无理由退货,商品需保持完好,不影响二次销售。
[3] 来源:退货运费规则 | 更新时间:2026-02-01
质量问题退货,运费由商家承担;非质量问题退货,运费由买家承担。
这个格式有几个设计要点:
- 编号 [1] [2] [3]:方便模型在回答时引用,也方便后端解析引用关系
- 来源信息:告诉模型(和用户)这条信息从哪来的,提升可追溯性
- 更新时间:当多条 chunk 信息冲突时,模型可以根据时间判断哪条更新
- 明确的分隔符:用空行隔开每个 chunk,避免模型把相邻 chunk 的内容混在一起理解
来源�信息和更新时间来自元数据(Metadata),这就是咱们在元数据管理那一篇讲的回答可引用和回溯纠错的实际应用。
2.2 上下文窗口的限制与应对
大模型的上下文窗口是有限的。虽然现在很多模型支持 128K 甚至更长的上下文,但塞太多 chunk 进去并不是好事:
- 关键信息被稀释:模型需要在大量文本中找到和问题最相关的部分,chunk 越多,噪音越大,模型越容易被不相关的内容干扰
- 迷失在中间(Lost in the Middle):研究表明,大模型对上下文中间位置的信息关注度较低,排在中间的 chunk 容易被忽略
- 成本增加:输入 token 越多,API 调用费用越高,响应延迟也越大
经验法则:
| 场景 | 推荐 chunk 数量 | 理由 |
|---|---|---|
| 简单事实问答(如退货政策) | 3~5 个 | 答案通常在 1~2 个 chunk 里,多给几个做补充 |
| 复杂问题(如对比多个产品) | 5~8 个 | 需要综合多个 chunk 的信息 |
| 总结类问题(如某个品类的所有规则) | 8~10 个 | 需要覆盖更多内容,但要注意去重 |
如果你用了重排序(Reranker),Top-K 的质量已经很高了,通常 3~5 个 chunk 就够用。宁可少给几个高质量的,也不要多给一堆低质量的。
3. 用户问题(User Query):原始问题还是�改写后的问题
最简单的做法是直接用用户的原始问题。对于大多数场景,这就够了。
用户问题:iPhone 16 Pro Max 拆封后还能退吗?
但有些场景下,用户的原始问题可能不够清晰或者有歧义。比如用户问“退货怎么弄”,这个问题太模糊——是问退货流程?退货条件?还是退货运费?
这种情况可以通过 Query 改写(Query Rewriting)来优化,比如把“退货怎么弄”改写成“请问退货的具体流程和条件是什么”。但 Query 改写本身是一个独立的话题,涉及到多轮对话上下文理解、意图识别等,这一篇先不展开,后续篇章再详细讲。
4. 完整 Prompt 模板示例
把三段拼在一起,一个完整的 RAG Prompt 长这样:
【System】
你是一名专业的电商客服助手。你的任务是根据【参考资料】中的信息,准确回答用户的问题。
请严格遵守以下规则:
1. 只基于【参考资料】中的内容回答问题,不要使用你自己的知识。
2. 如果【参考资料】中没有足够的信息来回答用户的问题,请明确回答:"根据现有资料,暂时无法回答该问题。建议您联系人工客服获取更多帮助。"
3. 不要编造任何【参考资料】中没有提到的信息,包括数字、日期、金额等具体细节。
4. 回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
5. 如果多条参考资料的信息存在冲突,请指出冲突并告知用户以最新的资料为准。
6. 用简洁、友好的语气回答,避免过于官方或生硬的表述。
【参考资料】
[1] 来源:退货政策文档 | 更新时间:2026-01-15
iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。如需退货,需经售后检测确认存在质量问题。
[2] 来源:通用退货规则 | 更新时间:2026-01-10
标准商品在签收后 7 天内可申请无理由退货,商品需保持完好,不影响二次销售。
[3] 来源:退货运费规则 | 更新时间:2026-02-01
质量问题退货,运费由商家承担;非质量问题退货,运费由买家承担。
【用户问题】
iPhone 16 Pro Max 拆封后还能退吗?
模型基于这个 Prompt 生成的回答:
iPhone 16 Pro Max 拆封后不支持七天无理由退货,因为该机型采用了屏幕定制工艺 [1]。
不过,如果您收到的商品存在质量问题(比如屏幕有坏点、机身有划痕等),可以申请退货,需要经过售后检测确认 [1]。
需要注意的是,如果是因为质量问题退货,运费由商家承担 [3]。
对比一下开头那个没有 Prompt 约束的回答(可以无理由退货),差距一目了然。模型准确引用了 chunk 的内容,没有编造细节,还标注了引用来源。
幻觉抑制:让模型不知道就说不知道
1. 什么是幻觉(Hallucination)
幻觉这个词听起来很学术,但意思很直白:模型生成了看起来很合理、读起来很流畅,但实际上是编造的内容。
打个比方,你问一个新来的客服同事:这款手机的保修期是多久,他不确定答案,但又不想说“我不知道”,于是自信地回答“两年”。听起来很合理,但实际保修期是一年。这就是幻觉——不是故意骗你,而是“不知道自己不知道”。
大模型的幻觉也是类似的机制。模型在训练时学到了大量的通用知识,当检索到的 chunk 不够用时,它会自动补全——用训练数据里的通用知识填充答案,而且说得非常自信,不会主动告诉你“这部分我是猜的”。
在 RAG 场景下,幻觉尤其危险,因为用户以为答案是基于知识库的(可靠的),但实际上模型偷偷掺了自己的私货。
2. RAG 场景下幻觉的三种典型表现
2.1 篡改事实
chunk 里明确说了 A,模型回答了 B。
chunk:iPhone 16 Pro Max 拆封后不支持七天无理由退货。
模型回答:iPhone 16 Pro Max 支持七天无理由退货。
这是最严重的一种幻觉。模型不是没看到 chunk 的内容,而是用自己的常识(大部分商品支持七天无理由退货)覆盖了 chunk 的具体规则。
2.2 凭空捏造
chunk 里没有提到某个信息,模型自己补了一个。
chunk:质量问题退货,运费由商家承担。
模型回答:质量问题退货,运费由商家承担,退款将在 3-5 个工作日内原路返回。
3-5 个工作日内原路返回这个信息 chunk 里完全没有,是模型根据电商行业的通用经验编造的。如果实际退款周期是 7-15 个工作日,用户就会投诉“说好的 3-5 天”,为什么还没到账。
2.3 张冠李戴
把 chunk A 的信息安到 chunk B 的主体上。
chunk 1:AirPods Pro 保修期为 1 年。
chunk 2:AppleCare+ 可将保修期延长至 2 年。
模型回答:AirPods Pro 的保修期为 2 年。
模型把两个 chunk 的信息混在一起,生成了一个看起来对但实际上错的答案。这种幻觉特别隐蔽,因为每个单独的信息点都是对的,但组合方式是错的。
3. 通过 Prompt 抑制幻觉的实用技巧
幻觉不能完全消除(这是大模型的本质特性),但可以通过 Prompt 设计大幅降低发生概率。
技巧一:明确限定知识来源
在 System Prompt 中反复强调——只基于参考资料回答。这条指令看起来简单,但效果显著。没有这条指令时,模型会把检索到的 chunk 当作参考;有了这条指令,模型会把 chunk 当作唯一依据。
只基于【参考�资料】中的内容回答问题,不要使用你自己的知识。
技巧二:加兜底指令
告诉模型:不知道的时候该怎么办。如果不给这个出口,模型会默认“尽力回答”,也就是开始编造。
如果【参考资料】中没有足够的信息来回答用户的问题,请明确回答:
"根据现有资料,暂时无法回答该问题。建议您联系人工客服获取更多帮助。"
技巧三:禁止编造具体细节
数字、日期、金额是幻觉的重灾区。模型特别喜欢补全这类信息,因为训练数据里有大量类似的模式。
不要编造任何【参考资料】中没有提到的信息,包括数字、日期、金额等具体细节。
技巧四:要求先引用再回答
让模型在回答时标注引用来源,这不仅提升了可追溯性,还间接抑制了幻觉——因为模型需要为每句话找到对应的 chunk,找不到就不敢说。
回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
技巧五:降低 Temperature 参数
这个需要单独解释一下。
3.1 Temperature 和 Top-P 参数的作用
调用大模型 API 时,有两个参数直接影响生成结果的随机性:
Temperature(温度)
控制模型输出的随机程度。值越低,模型越倾向于选择概率最高的词;值越高,模型越愿意冒险选择概率较低的词。
- Temperature = 0:模型几乎总是选择概率最高的词,输出最确定、最保守
- Temperature = 0.7:默认值,有一定随机性,适合创意写作
- Temperature = 1.0 或更高:输出非常随机,适合头脑风暴
打个比方,Temperature 就像一个人的冒险程度。Temperature = 0 的人回答问题只说最有把握的话;Temperature = 1.0 的人会天马行空,想到什么说什么。
Top-P(核采样)
另一种控制随机性的方式。Top-P = 0.9 表示模型只从累计概率达到 90% 的候选词中采样,排除那些概率极低的长尾选项。
RAG 场景下的推荐设置
| 参��数 | 推荐值 | 理由 |
|---|---|---|
| Temperature | 0 ~ 0.3 | RAG 需要的是准确性,不是创造性。低 Temperature 让模型更老实 |
| Top-P | 0.9 ~ 0.95 | 配合低 Temperature 使用,进一步减少随机性 |
注意:Temperature 和 Top-P 通常不需要同时调。大多数情况下,只设置 Temperature 就够了。如果你同时设置了两个参数,不同模型的行为可能不一致。建议先只调 Temperature,效果不满意再加 Top-P。
3.2 兜底回答的设计
兜底回答是幻觉抑制的最后一道防线。当检索结果不足以回答用户问题时,模型应该给出一个诚实的不知道,而不是硬编一个答案。
但不知道也有讲究。直接回答我不知道会让用户觉得这个系统没用。好的兜底回答应该做到三点:
- 承认信息不足
- 给出替代方案(如联系人工客服)
- 如果能部分回答,先给出已知的部分
几种兜底回答的模板:
完全无法回答:
根据现有资料,暂时无法回答该问题。建议您联系人工客服(热线:400-xxx-xxxx)获取更多帮助。
部分可以回答:
根据现有资料,关于 [已知部分] 的信息如下:[回答已知部分]。
但关于 [未知部分],现有资料中没有相关说明,建议您联系人工客服确认。
问题超出知识库范围:
这个问题超出了我的服务范围。我主要负责解答商品退换货、物流配送等售后问题。如果您有这方面的疑问,随时可以问我。
引用对齐:让答案可追溯
1. 为什么需要引用对齐
想象一下你在看一篇新闻报道,文章说:据统计,2025 年全球智能手机出货量下降了 15%。你会想:这个数据哪来的?谁统计的?如果文章标注了“来源:IDC 2025 年度报告”,你就能自己去查证。
RAG 系统也是一样。用户看到一个回答,心里的第一反应是这个答案靠谱吗。如果模型能标注“这段话来自《退货政策》第 3 条”,用户就能自己去验证——这比任何我的回答是准确的的声明都有说服力。
在企业级 RAG 系统中,引用对齐更是刚需:
- 合规要求:金融、医疗、法律等行业,回答必须有据可查
- 审计追溯:出了问题能追溯到具体的知识来源,定位是知识库的问题还是模型的问题
- 信任建设:用户能看到答案的依据,逐步建立对系统的信任
2. 引用对齐的实现方式
引用对齐的核心思路很简单:上下文中每个 chunk 带编号,Prompt 中要求模型在回答时标注引用编号。
2.1 Prompt 中的引用指令设计
在 System Prompt 中加入引用指令:
回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
如果一句话的信息来自多条参考资料,请同时标注多个编号,如 [1][3]。
只引用你实际使用到的参考资料,不要引用与回答无关的资料。
上下文中的 chunk 格式(前面已经展示过):
[1] 来源:退货政策文档 | 更新时间:2026-01-15
iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。
[2] 来源:通用退货规则 | 更新时间:2026-01-10
标准商品在签收后 7 天内可申请无理由退货,商品需保持完好。
模型的回答:
iPhone 16 Pro Max 拆封后不支持七天无理由退货 [1]。
一般标准商品在签收后 7 天内可以申请无理由退货,但需要商品保持完好 [2]。
2.2 引用解析与展示
模型输出的是带 [1]、[2] 标记的纯文本,后端需要解析这些标记,关联到对应的 chunk 元数据,然后传给前端展示。
解析逻辑很简单——用正则表达式提取 [数字] 模式:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.*;
public class CitationParser {
/**
* 从模型回答中提取所有引用编号
*/
public static Set<Integer> extractCitations(String answer) {
Set<Integer> citations = new TreeSet<>();
Pattern pattern = Pattern.compile("\\[(\\d+)]");
Matcher matcher = pattern.matcher(answer);
while (matcher.find()) {
citations.add(Integer.parseInt(matcher.group(1)));
}
return citations;
}
/**
* 将引用编号替换为可点击的链接(HTML 格式)
*/
public static String renderCitations(String answer, Map<Integer, ChunkMeta> chunkMetaMap) {
Pattern pattern = Pattern.compile("\\[(\\d+)]");
Matcher matcher = pattern.matcher(answer);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
int index = Integer.parseInt(matcher.group(1));
ChunkMeta meta = chunkMetaMap.get(index);
if (meta != null) {
String link = String.format(
"<a href=\"%s\" title=\"%s\" className=\"citation\">[%d]</a>",
meta.getSourceUrl(), meta.getSource(), index
);
matcher.appendReplacement(result, link);
}
}
matcher.appendTail(result);
return result.toString();
}
// chunk 的元数据
static class ChunkMeta {
private String source; // 来源文档名
private String sourceUrl; // 原文链接
private String updateTime; // 更新时间
public ChunkMeta(String source, String sourceUrl, String updateTime) {
this.source = source;
this.sourceUrl = sourceUrl;
this.updateTime = updateTime;
}
public String getSource() { return source; }
public String getSourceUrl() { return sourceUrl; }
public String getUpdateTime() { return updateTime; }
}
}
前端拿到渲染后的 HTML,用户点击 [1] 就能跳转到原文,自己验证答案的准确性。
3. 引用对齐的效果示例
用一个完��整的例子走一遍:
用户提问: AirPods Pro 的保修期是多久?过保了还能修吗?
检索返回的 chunk:
[1] 来源:Apple 产品保修政策 | 更新时间:2026-01-20
AirPods Pro 自购买之日起享有 1 年的有限保修服务,涵盖制造缺陷和电池性能问题。
[2] 来源:AppleCare+ 服务说明 | 更新时间:2026-02-01
购买 AppleCare+ 服务计划可将 AirPods Pro 的保修期延长至 2 年,并额外提供最多 2 次意外损坏保修服务(每次收取服务费)。
[3] 来源:过保维修服务 | 更新时间:2026-01-25
AirPods Pro 过保后仍可通过 Apple 授权服务商进行付费维修。电池更换费用为 359 元,其他硬件维修费用视具体情况而定。
模型回答(带引用):
AirPods Pro 的默认保修期是 1 年,从购买之日起算,覆盖制造缺陷和电池问题 [1]。如果你购买了 AppleCare+,保修期可以延长到 2 年,还额外包含 2 次意外损坏保修 [2]。
过保了也能修。Apple 授权服务商提供付费维修服务,比如电池更换是 359 元,其他维修费用要看具体情况 [3]。
这个回答有几个值得注意的地方:
- 没有把 1 年和 2 年混在一起说(避免了张冠李戴)
- 每个信息点都标注了来源
- 没有编造任何 chunk 里没有的细节(比如没有自己补一个“维修周期 3-5 天”)
- 回答结构清晰,先回答保修期,再回答过保维修
答案约束:控制输出的格式和边界
Prompt 设计除了抑制幻觉和引用对齐,还有一个重要的维度——控制模型输出的格式和边界。不同的业务场景对答案的形式有不同的要求。
1. 格式约束:JSON / 纯文本 / 列表
纯文本(客服问答场景)
大多数客服场景用自然语言回答就行,这也是默认的输出格式。
请用自然语言回答,语气友好、简洁。
JSON 格式(API 接口场景)
如果 RAG 系统的输出需要被下游程序消费(比如作为 API 返回值),就需要结构化的 JSON 输出。
请以 JSON 格式回答,包含以下字段:
- answer:回答内容
- citations:引用的参考资料编号列表
- confidence:你对这个回答的确信程度(high / medium / low)
输出示例:
{
"answer": "iPhone 16 Pro Max 拆封后不支持七天无理由退货。",
"citations": [1],
"confidence": "high"
}
注意:要求模型输出 JSON 时,建议在 Prompt 中给一个输出示例。没有示例的话,模型可能会自己发明字段名或者格式不一致。另外,部分大模型 API 支持
response_format参数强制 JSON 输出,比 Prompt 约束更可靠。
列表格式(知识卡片场景)
请用编号列表的格式回答,每条信息独立成行,便于用户快速浏览。
2. 长度约束:控制回答的详略
不同场景对回答长度的要求差异很大:
# 简短回答(适合快速问答、聊天机器人)
请用 1-2 句话简要回答。
# 详细回答(适合知识库查询、报告生成)
请详细回答,包含所有相关的细节和注意事项。
# 限定字数
请在 200 字以内回答。
经验上,RAG 客服场景推荐中等长度——回答核心问题,补充必要的注意事项,但不要展开无关的背景知识。可以在 System Prompt 中这样写:
回答要简洁但完整:覆盖用户问题的核心要点,补充必要的注意事项,但不要展开与问题无关的背景知识。
3. 边界约束:只回答知识库范围内的问题
用户不一定只问知识库范围内的问题。一个电商客服 RAG 系统,用户可能会问“今天天气怎么样”“帮我写一首诗”“你觉得 iPhone 和华为哪个好”。
如果不做边界约束,模型会用自己的知识回答这些问题——这不仅偏离了系统的定位,还可能产生不当言论(比如品牌对比可能引发争议)。
在 System Prompt 中加入边界约束:
你只负责回答与商品售后、退换货、物流配送相关的问题。
如果用户的问题超出这个范围,请礼貌地告知:"这个问题超出了我的服务范围。我主要负责解答商品售后相关问题,如果您有退换货、物流等方面的疑问,随时可以问我。"
不要回答涉及品牌对比、价格预测、个人观点等主观性问题。
把格式约束、长度约束、边界约束�整合到 System Prompt 中,一个完整的生产级 System Prompt 大概长这样:
你是一名专业的电商客服助手。你的任务是根据【参考资料】中的信息,准确回答用户的问题。
【角色与边界】
- 你只负责回答与商品售后、退换货、物流配送相关的问题。
- 如果用户的问题超出这个范围,请礼貌地告知用户,并引导回售后相关话题。
- 不要回答涉及品牌对比、价格预测、个人观点等主观性问题。
【回答规则】
1. 只基于【参考资料】中的内容回答问题,不要使用你自己的知识。
2. 如果【参考资料】中没有足够的信息,请明确告知用户,并建议联系人工客服。
3. 不要编造任何【参考资料】中没有提到的信息,包括数字、日期、金额等。
4. 如果多条参考资料的信息存在冲突,请指出冲突并告知用户以最新的资料为准。
【引用规则】
- 回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
- 只引用你实际使用到的参考资料。
【格式要求】
- 用简洁、友好的语气回答。
- 回答要覆盖用户问题的核心要点,补充必要的注意事项,但不要展开无关的背景知识。
你可能注意到了,这个 System Prompt 比前面的基础版多了不少内容,但仍然保持了清晰的分组结构(角色与边界、回答规则、引用规则、格式要求)。分组的好处是模型更容易理解每条指令的优先级,也方便你后续针对某个维度做调优。
Java 实战:完整的 RAG 生成流程
前面讲了 Prompt 的结构设计、幻觉抑制、引用对齐、答案约束,都是理论侧的东西。这一节咱们把所有环节串起来,用 Java 代码跑通一个完整的 RAG 生成链路:Milvus 混合检索 → Reranker 重排序 → 组装 Prompt → 调用大模型 API → 解析带引用的答案。
1. 代码实现:从检索到生成的完整链路
整体流程分四步:
- 从 Milvus 混合检索 + Reranker 重排序拿到 Top-K chunk(这部分上一篇已经实现过,这里直接复用)
- 把 Top-K chunk 组装成带编号、带元数据的上下文
- 拼接 System Prompt + 上下文 + 用户问题,调用大模型 Chat API
- 解析模型回答中的引用编号,关联到 chunk 元数据
完整示例可以查看 TinyRAG 项目 com.nageoffer.ai.tinyrag.retrieve 目录下代码。
先定义几个基础的数据结构:
/**
* 检索到的 chunk,包含内容和元数据
*/
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class RetrievedChunk {
private String content; // chunk 文本内容
private String source; // 来源文档名
private String sourceUrl; // 原文链接
private String updateTime; // 更新时间
private Double score; // 重排序得分
}
/**
* RAG 生成结果,包含回答文本和引用信息
*/
@Data
public class RAGResponse {
private String answer; // 模型的回答(原始文本,带 [1][2] 标记)
private String renderedAnswer; // 渲染后的回答(引用标记替换为链接)
private List<CitationInfo> citations; // 引用详情列表
/**
* 引用信息
*/
@Data
public static class CitationInfo {
private Integer index; // 引用编号
private String source; // 来源文档
private String sourceUrl; // 原文链接
private String chunkContent; // 被引用的 chunk 内容
}
}
核心的 RAG 生成服务:
public class RAGGenerationService {
// SiliconFlow API 配置
private static final String API_URL = "https://api.siliconflow.cn/v1/chat/completions";
private static final String API_KEY = "你的 SiliconFlow API Key";
private static final String MODEL = "Qwen/Qwen2.5-7B-Instruct";
private static final OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.build();
private static final Gson gson = new Gson();
/**
* System Prompt 模板——生产级版本
*/
private static final String SYSTEM_PROMPT = """
你是一名专业的电商客服助手。你的任务是根据【参考资料】中的信息,准确回答用户的问题。
【角色与边界】
- 你只负责回答与商品售后、退换货、物流配送相关的问题。
- 如果用户的问题超出这个范围,请礼貌地告知用户,并引导回售后相关话题。
- 不要回答涉及品牌对比、价格预测、个人观点等主观性问题。
【回答规则】
1. 只基于【参考资料】中的内容回答问题,不要使用你自己的知识。
2. 如果【参考资料】中没�有足够的信息,请明确回答:"根据现有资料,暂时无法回答该问题。建议您联系人工客服获取更多帮助。"
3. 不要编造任何【参考资料】中没有提到的信息,包括数字、日期、金额等。
4. 如果多条参考资料的信息存在冲突,请指出冲突并告知用户以最新的资料为准。
【引用规则】
- 回答时请引用参考资料的编号,格式为 [1]、[2] 等,标注在相关句子的末尾。
- 如果一句话的信息来自多条参考资料,请同时标注多个编号,如 [1][3]。
- 只引用你实际使用到的参考资料。
【格式要求】
- 用简洁、友好的语气回答。
- 回答要覆盖用户问题的核心要点,补充必要的注意事项,但不要展开无关的背景知识。
""";
/**
* 步骤一:把检索到的 chunk 列表组装成带编号的上下文
*/
public String buildContext(List<RetrievedChunk> chunks) {
StringBuilder context = new StringBuilder("【参考资料】\n\n");
for (int i = 0; i < chunks.size(); i++) {
RetrievedChunk chunk = chunks.get(i);
context.append(String.format("[%d] 来源:%s | 更新时间:%s\n",
i + 1, chunk.getSource(), chunk.getUpdateTime()));
context.append(chunk.getContent()).append("\n\n");
}
return context.toString();
}
/**
* 步骤二:调用大模型 Chat API
*/
public String callLlm(String systemPrompt, String context, String userQuery)
throws IOException {
// 拼接完整的用户消息:上下文 + 用户问题
String userMessage = context + "【用户问题】\n" + userQuery;
// 构建请求体
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", MODEL);
requestBody.addProperty("temperature", 0.1); // 低 Temperature,减少随机性
requestBody.addProperty("max_tokens", 1024);
JsonArray messages = new JsonArray();
// system 消息
JsonObject systemMsg = new JsonObject();
systemMsg.addProperty("role", "system");
systemMsg.addProperty("content", systemPrompt);
messages.add(systemMsg);
// user 消息
JsonObject userMsg = new JsonObject();
userMsg.addProperty("role", "user");
userMsg.addProperty("content", userMessage);
messages.add(userMsg);
requestBody.add("messages", messages);
// 发送请求
Request request = new Request.Builder()
.url(API_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
gson.toJson(requestBody),
MediaType.parse("application/json")))
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("API 调用失败,状态码:" + response.code()
+ ",响应:" + response.body().string());
}
JsonObject responseJson = gson.fromJson(response.body().string(), JsonObject.class);
return responseJson
.getAsJsonArray("choices")
.get(0).getAsJsonObject()
.getAsJsonObject("message")
.get("content").getAsString();
}
}
/**
* 步骤三:解析模型回答中的引用编号
*/
public List<RAGResponse.CitationInfo> parseCitations(
String answer, List<RetrievedChunk> chunks) {
Set<Integer> citedIndexes = new TreeSet<>();
Pattern pattern = Pattern.compile("\\[(\\d+)]");
Matcher matcher = pattern.matcher(answer);
while (matcher.find()) {
citedIndexes.add(Integer.parseInt(matcher.group(1)));
}
List<RAGResponse.CitationInfo> citations = new ArrayList<>();
for (int index : citedIndexes) {
if (index >= 1 && index <= chunks.size()) {
RetrievedChunk chunk = chunks.get(index - 1);
RAGResponse.CitationInfo info = new RAGResponse.CitationInfo();
info.setIndex(index);
info.setSource(chunk.getSource());
info.setSourceUrl(chunk.getSourceUrl());
info.setChunkContent(chunk.getContent());
citations.add(info);
}
}
return citations;
}
/**
* 完整的 RAG 生成流程:检索 → 组装 → 生成 → 解析
*
* @param chunks 经过混合检索 + 重排序后的 Top-K chunk
* @param userQuery 用户的原始问题
* @return 包含回答和引用信息的 RAGResponse
*/
public RAGResponse generate(List<RetrievedChunk> chunks, String userQuery)
throws IOException {
// 1. 组装上下文
String context = buildContext(chunks);
// 2. 调用大模型
String answer = callLlm(SYSTEM_PROMPT, context, userQuery);
// 3. 解析引用
List<RAGResponse.CitationInfo> citations = parseCitations(answer, chunks);
// 4. 组装结果
RAGResponse response = new RAGResponse();
response.setAnswer(answer);
response.setCitations(citations);
return response;
}
}
几个值得注意的设计点:
- System Prompt 和上下文分开传递:System Prompt 放在
role: system消息里,上下文和用户问题放在role: user消息里。这样做的好处是模型能更清楚地区分"行为指令"和"参考内容",效果比全部塞在一个消息里要好 - Temperature 设为 0.1:不设 0 是因为完全确定性的输出有时候会导致回答过于生��硬,0.1 保留了一点点灵活性,同时几乎不会产生幻觉
- 引用解析做了边界检查:
index >= 1 && index <= chunks.size(),防止模型输出了不存在的引用编号(比如只有 3 个 chunk,模型却引用了 [5])
2. 运行效果展示
用一个完整的例子跑一遍。假设用户问的是"iPhone 16 Pro Max 拆封后还能退吗?运费谁出?",经过混合检索 + 重排序,拿到了 3 个 chunk:
public class RAGDemo {
public static void main(String[] args) throws Exception {
RAGGenerationService service = new RAGGenerationService();
// 模拟检索 + 重排序后的 Top-3 chunk
List<RetrievedChunk> chunks = List.of(
new RetrievedChunk(
"iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。如需退货,需经售后检测确认存在质量问题。",
"退货政策文档", "/docs/return-policy", "2026-01-15", 0.95
),
new RetrievedChunk(
"标准商品在签收后 7 天内可申请无理由退货,商品需保持完好,不影响二次销售。",
"通用退货规则", "/docs/general-return", "2026-01-10", 0.82
),
new RetrievedChunk(
"质量问题退货,运费由商家承担;非质量问题退货,运费由买家承担。",
"退货运费规则", "/docs/return-shipping", "2026-02-01", 0.78
)
);
String userQuery = "iPhone 16 Pro Max 拆封后还能退吗?运费谁出?";
// 执行 RAG 生成
RAGResponse response = service.generate(chunks, userQuery);
// 输出结果
System.out.println("=== 用户问题 ===");
System.out.println(userQuery);
System.out.println();
System.out.println("=== 模型回答 ===");
System.out.println(response.getAnswer());
System.out.println();
System.out.println("=== 引用来源 ===");
for (RAGResponse.CitationInfo citation : response.getCitations()) {
System.out.printf("[%d] %s(%s)%n",
citation.getIndex(), citation.getSource(), citation.getSourceUrl());
}
}
}
运行输出:
=== 用户问题 ===
iPhone 16 Pro Max 拆封后还能退吗?运费谁出?
=== 模型回答 ===
iPhone 16 Pro Max 因屏幕定制工艺,拆封后不支持七天无理由退货。如果需要退货,需经售后检测确认存在质量问题,此时运费由商家承担 [1]。对于其他标准商品,签收后 7 天内可申请无理由退货,商品需保持完好,不影响二次销售,此时运费由买家承担 [2][3]。
=== 引用来源 ===
[1] 退货政策文档(/docs/return-policy)
[2] 通用退货规则(/docs/general-return)
[3] 退货运费规则(/docs/return-shipping)
对比一下开篇那个没有 Prompt 约束的回答(可以无理由退货),这个回答:
- 准确引用了 chunk 内容,没有篡改不支持退货的结论
- 没有编造退款时效、退款金额等 chunk 里没有的细节
- 每句话都标注了引用来源,用户可以点击验证
- 主动区分了质�量问题退货和非质量问题退货两种情况的运费规则
- 还补充说明了 iPhone 16 Pro Max 是特殊商品,不适用通用退货规则——这个信息是从 [1] 和 [2] 的对比中推理出来的,属于合理推理,不是幻觉
因为受限于模型温度,我测试了几次,“[2] 通用退货规则”可能存在无法引用情况。不过整体来说并不影响整体效果。
3. Prompt 模板的迭代优化
Prompt 不是写一版就完事的。上线之后你会不断收到 bad case(用户反馈答案不对),需要根据 bad case 持续调优。
这里给一个实用的迭代流程:
第一步:收集 bad case
把用户反馈的错误回答记录下来,至少包含三个信息:用户问题、检索到的 chunk、模型的错误回答。
第二步:分类归因
每个 bad case 归到以下某个类别:
| 类别 | 判断标准 | 优化方向 |
|---|---|---|
| 幻觉——篡改事实 | chunk 说 A,模型说 B | 强化只基于参考资料回答的指令 |
| 幻觉——凭空捏造 | 模型补充了 chunk 里没有的细节 | 强化不要编造的指令,特别是数字、日期、金额 |
| 幻觉——张冠李戴 | 模型混淆了不同 chunk 的信息 | 要求模型逐条引用,不要合并不同来源的信息 |
| 答非所问 | 模型回答了相关但不对口的内容 | 强化聚焦用户问题的指令 |
| 格式不对 | 输出格式不符合要求 | 在 Prompt 中加输出示例 |
| 超出边界 | ��模型回答了知识库范围外的问题 | 强化边界约束指令 |
第三步:针对性修改 Prompt
举几个真实的 bad case 和对应的 Prompt 修改:
Bad Case 1:模型把多个 chunk 的数字混在一起
用户问题:AirPods Pro 的保修期是多久?
chunk 1:AirPods Pro 保修期为 1 年。
chunk 2:AppleCare+ 可将保修期延长至 2 年。
错误回答:AirPods Pro 的保修期为 2 年。
归因:张冠李戴。模型把 AppleCare+ 的延长保修期当成了默认保修期。
Prompt 修改——在回答规则中增加一条:
5. 引用不同参考资料的信息时,请明确区分各条资料的适用条件和主体,不要将不同资料的信息合并表述。
Bad Case 2:模型在 chunk 信息不足时自己补了退款时效
用户问题:退货后多久能收到退款?
chunk:质量问题退货,运费由商家承担。
错误回答:退货后 3-5 个工作日内退款到账。
归因:凭空捏造。chunk 里完全没有退款时效的信息,模型用通用知识编了一个。
Prompt 修改——强化兜底指令,让它更具体:
2. 如果【参考资料】中没有足够的信息来回答用户的问题,请明确告知用户哪些部分可以回答、哪些部分资料中没有提及。
示例:"关于退货运费,商家承担质量问题的运费 [1]。但关于退款到账时间,现有资料中没有说明,建议您联系人工客服确认。"
Bad Case 3:模型回答了与售后无关的问题
用户问题:iPhone 16 Pro Max 拍照效果怎么样?
chunk:(检索返回了 iPhone 16 Pro Max 的退货政策相关 chunk)
错误回答:iPhone 16 Pro Max 搭载了 4800 万像素主摄……(一大段产品介绍)
归因:超出边界。用户问的是产品功能,不是售后问题,但模型用自己的知识回答了。
Prompt 修改——边界约束更明确:
【角色与边界】
- 你只负责回答与商品售后、退换货、物流配送相关的问题。
- 对于商品功能、参数、使用技巧等非售后问题,请回答:"这个问题超出了我的服务范围。我主要负责解答售后相关问题,关于商品功能和参数,建议您查看商品详情页或咨询售前客服。"
Prompt 调优是一个持续的过程,不存在完美的 Prompt。建议建立一个 bad case 库,每次修改 Prompt 后,用所有历史 bad case 回归测试,确保修了新问题没有引入老问题。
一张图看完整 RAG 链路
到这里,RAG 系列从数据准备到检索到生成的完整链路就全部打通了。用一张图把所有环节串起来,每个环节标注了对应的系列文章:
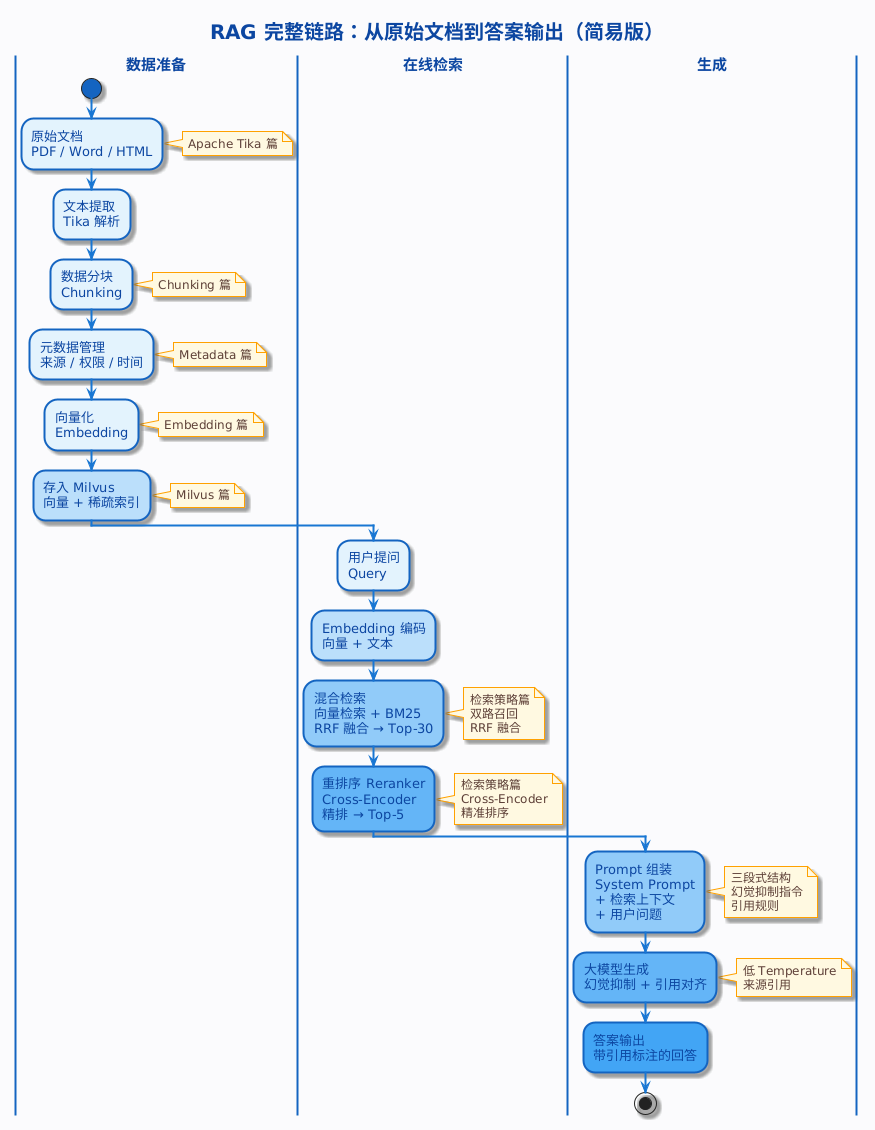
从左上角的原始文档到右下角的答案输出,每一步都有对应的工程实现。回顾一下各环节对应的系列文章:
| 环节 | 核心任务 | 对应文章 |
|---|---|---|
| 文本提取 | 从 PDF、Word 等格式中提取纯文本 | Apache Tika 篇 |
| 数据分块 | 把长文本切成适合检索的 chunk | Chunking 篇 |
| 元数据管理 | 给 chunk 贴标签(来源、权限、时间等) | Metadata 篇 |
| 向量化 | 把文本 chunk 转成数字向量 | Embedding 篇 |
| 向量数据库 | 存储向量,支持 ANN 检索 | Milvus 篇 |
| 混合检索 + 重排序 | 向量检索 + BM25 + Reranker 精排 | 检索策略篇 |
| Prompt 组装 + 大模型生成 | 三段式 Prompt、幻觉抑制、引用对齐、答案约束 | 本篇(生成策略篇) |
小结与下一篇预告
这一篇聊的是 RAG 的最后一公里—��—拿到高质量 chunk 之后,怎么通过 Prompt 设计让大模型生成靠谱的答案。
核心要点回顾:
- 三段式 Prompt 结构是基础:System Prompt 定义行为边界,检索上下文提供事实依据,用户问题明确回答目标。三段各司其职,缺一不可
- 幻觉抑制是底线:通过“只基于参考资料回答”“不知道就说不知道”“不要编造具体细节”等指令,配合低 Temperature 参数,把模型的“自由发挥”空间压到最小
- 引用对齐是信任基石:让模型标注每句话的来源,用户能自己验证,企业能做合规审计。实现上就是 chunk 带编号 + Prompt 要求引用 + 后端解析引用标记
- 答案约束是业务适配:不同场景对格式、长度、边界有不同要求,通过 Prompt 指令灵活控制
一句话总结:检索决定了答案的上限(能不能找到对的信息),生成决定了答案的下限(找到了对的信息能不能说对)。两手都要抓,两手都要硬。