SSE:大模型为什么都用它做流式
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
在模型调用 API 那篇里,你已经用 stream=true 调过大模型 API,也写过 BufferedReader 逐行读取 data: 的代码。当时的代码能跑,效果也不错——逐字输出,打字机效果。
但你有没有想过几个问题:
- 这个
data:开头的格式叫什么?是谁定义的? - 为什么大模型 API 都用这个格式,而不用 WebSocket?
- 如果网络不好,连接断了怎么办?
- 你写的那段 BufferedReader 代码,在生产环境扛得住吗?
当时那篇的定位是够用就行——能调通 API、能看到流式效果。但如果你要在生产环境用 SSE(不管是消费大模型 API 还是自己做 SSE 服务端),够用就行是不够的。你需要搞清楚 SSE 协议本身的完整规范,理解连接的生命周期,知道怎么处理异常情况。
这篇就来把 SSE 这个东西讲透。
SSE 协议:不只是 data: 开头的文本
1. SSE 是什么
SSE 全称 Server-Sent Events,直译就是服务端发送的事件。它是 HTML 标准的一部分,目前的权威规范在 WHATWG HTML Living Standard 里,定义了 text/event-stream 这套事件流格式和浏览器端的 EventSource API。
一句话总结:基于 HTTP 的单向服务端推送协议。
客户端发起一个普通的 HTTP 请求,服务端保持连接不关闭,持续向客户端推送事件。注意是单向的——只有服务端往客户端推,客户端不能通过同一个连接往服务端发数据。
和普通 HTTP 请求的区别很直观:
- 普通 HTTP:客户端发请求 → 服务端返回完整响应 → 连接关闭。一问一答。
- SSE:客户端发请�求 → 服务端持续推送事件 → 推完了或客户端主动断开 → 连接关闭。一问多答。
打个比方:普通 HTTP 像发短信,你发一条我回一条,每次都是独立的。SSE 像打电话,拨通之后对方一直在说(你只需要听),说完了再挂。
SSE 响应有一个标志性的 HTTP 头:
Content-Type: text/event-stream
浏览器和 HTTP 客户端看到这个 Content-Type,就知道这是一个 SSE 流,我要按 SSE 的规则来解析。
2. SSE 的完整字段格式
之前你只接触了 data: 字段。其实 SSE 规范一共定义了四个字段和一个注释机制,每个都有明确的用途。
一个完整的 SSE 事件流长这样:
retry: 3000
: 这是一条注释,客户端会忽略
id: 1
event: message
data: {"content": "你好"}
id: 2
event: token
data: {"content": ","}
id: 3
event: token
data: {"content": "有什么可以帮你?"}
id: 4
event: done
data: {"status": "completed", "total_tokens": 128}
逐个来看。
2.1 data: 字段——事件数据
你最熟悉的字段。每行以 data: 开头,后面跟的是事件的数据内容。
data: {"content": "你好"}
一个事件可以有多行 data:,它们会被换行符 \n 拼接起来:
data: 第一行
data: 第二行
data: 第三行
客户端收到的数据是 第一行\n第二行\n第三行。
一个事件以两个连续换行(空行)结束。这是 SSE 的事件边界标志——解析器看到空行就知道上一个事件结束了,该处理它了。
2.2 event: 字段——自定义事件类型
如果不写 event: 字段,事件的类型默认是 message。通过 event: 字段可以给事件指定自定义类型:
event: token
data: {"content": "你好"}
event: error
data: {"code": 429, "message": "rate limit exceeded"}
event: done
data: {"total_tokens": 128}
这样客户端可以根据事件类型做不同的处理——收到 token 事件就拼接内容,收到 error 事件就展示错误,收到 done 事件就结束流。
大模型 API(OpenAI、SiliconFlow 等)通常不使用 event: 字段,所有事件都是默认的 message 类型,靠 data: 里的 JSON 内容来区分。但如果你自己搭建 SSE 服务端,event: 字段就很有用了——下一篇 Spring Boot SSE 服务端实战会用到。
2.3 id: 字段——事件 ID
每个事件可以有一个 ID:
id: 42
data: {"content": "这是第 42 个事件"}
id: 字段的核心作用是支持断线重连。机制是这样的:
- 服务端给每个事件编一个
id: - 客户端内部会记住最后收到的事件 ID
- 如果连接断开,客户端重连时会在 HTTP 请求头里带上
Last-Event-ID: 42 - 服务端看到这个头,就知道客户端已经收到了 ID 42 之前的所有事件,从 ID 43 开始继续推送
这个机制让 SSE 天然支持断点续传——连接断了不用从头来,从上次断开的地方接着推。
不过大模型 API 通常不使用 id: 字段。因为大模型的流式生成是一次性的——内容是实时生成的,断了就没法从断点接着生成,只能重新请求。所以在消费大模型 API 的场景下,id: 字段基本用不到。但在自建 SSE 服务的场景下(比如推送通知、实时数据流),id: 就很有价值了。
2.4 retry: 字段——重连间隔
服务端可以通过 retry: 告诉客户端如果连接断了,等多久再重连:
retry: 5000
data: {"content": "连接已建立"}
retry: 5000 的意思是如果连接断了,等 5000 毫秒(5 秒)再尝试重连。这个字段通常只在连接建立后发送一次。
浏览器原生的 EventSource API 会自动处理重连(默认间隔约 3 秒)。但在 Java 客户端里,你需要自己实现重连逻辑——OkHttp 的 HTTP 客户端不会自动按 retry: 的值重连。
2.5 注释行——心跳保活
以冒号 : 开头的行是注释,客户端会直接忽略:
: this is a comment
: keepalive
注释看起来没什么用,但在生产环境有一个很重要的作用——心跳保活。
问题背景:SSE 连接在数据推送的间隙可能长时间没有数据传输(比如大模型在思考,几秒甚至十几秒没有输出)。如果中间经过了 Nginx、负载均衡器、CDN 等中间件,它们可能会认为这个连接已经死了,主动把连接断掉。
解决方案:服务端定期发送一个空注释 : keepalive\n\n 或者 :\n\n,客户端会忽略它,但中间件看到有数据在传输,就不会超时断开连接。
这就是为什么你在调试大模型流式 API 时,偶尔会在 SSE 流里看到一个空行或者
:开头的行——它不是数据,是心跳。
3. SSE 字段速查表
| 字段 | 格式 | 作用 | 大模型 API 是否使用 |
|---|---|---|---|
data: | data: 内容 | 事件数据,核心字段 | 是,每个 chunk 都有 |
event: | event: 类型名 | 自定义事件类型,默认 message | 否,通常不使用 |
id: | id: 事件ID | 事件标识,支持断线重连 | 否,通常不使用 |
retry: | retry: 毫秒数 | 指定客户端重连间隔 | 否,通常不使用 |
: | : 注释内容 | 注释行(心跳保活) | 偶尔使用 |
可以看到,大模型 API 只用了 SSE 最核心的
data:字段,其他字段基本不用。但理解完整的 SSE 规范很重要——一方面帮你排查问题(比如突然收到一个:开头的行,你知道它是注释不是数据),另一方面在自建 SSE 服务时这些字段都用得上。
SSE vs WebSocket vs 长轮询
你可能会好奇:为什么大模型 API 都用 SSE?不是还有 WebSocket 吗?WebSocket 不是更高级吗?
1. 三种方案的本质区别
先搞清楚三种实时通信方案各自是什么:
-
长轮询(Long Polling):客户端发请求,服务端如果没有新数据就 hold 住不返回(而不是立刻返回空),等有新数据了再返回。客户端收到响应后立刻再发一个新请求。本质上还是一问一答,只是每次答的等待时间变长了。
-
SSE(Server-Sent Events):客户端发一个 HTTP 请求,服务端保持连接,持续单向推送数据。基于 HTTP,只能服务端往客户端推。
-
WebSocket:客户端和服务端通过一次 HTTP 握手升级到 WebSocket 协议,之后双方可以随时互发消息。这是一个独立于 HTTP 的全双工协议。
详细比对如下所示:
| 对比维度 | 长轮询 | SSE | WebSocket |
|---|---|---|---|
| 通信方向 | 单向(模拟) | 单向(服务端→客户端) | 双向 |
| 底层协议 | HTTP | HTTP | 独立协议(ws://) |
| 连接方式 | 每次都是新连接 | 一个长连接 | 一个长连接 |
| 自动重连 | 不支持 | 规范内置 | 需自己实现 |
| 浏览器原生支持 | 需手写轮询逻辑 | EventSource API | WebSocket API |
| Nginx/CDN 兼容性 | 天然兼容 | 天然兼容(HTTP) | 需要额外配置代理 |
| 实现复杂度 | 低 | 低 | 中 |
| 适用场景 | 兼容性要求高的老系统 | 服务端单向推送 | 双向实时通信 |
2. 为什么大模型 API 选了 SSE
主要是四个原因:
-
方向匹配:大模型流式输出是典型的服务端→客户端单向推送——模型生成内容,逐块发给你。你不需要在同一个连接上往服务端发数据(你的问题在第一次 HTTP 请求里已经发过了)。SSE 刚好满足这个需求,WebSocket 的双向能力完全用不上。
-
HTTP 原生:SSE 就是一个普通的 HTTP 响应,只是 Content-Type 变成了
text/event-stream,数据格式是文本流。Nginx、CDN、负载均衡器、API 网关……所有 HTTP 基础设施都能原生支持,不需要额外配置。WebSocket 则需要专门配置代理的 WebSocket 升级支持(proxy_set_header Upgrade $http_upgrade这类配置),在某些企业网络环境下可能被防火墙拦截。 -
自动重连:SSE 规范内置了重连机制(
Last-Event-ID+retry:),浏览器的EventSourceAPI 自动处理。WebSocket 断线后需要你自己写重连逻辑。 -
实现简单:服务端只需要按格式输出文本行,客户端只需要逐行解析。WebSocket 有自己的帧协议(Frame),需要处理帧的编码解码、ping/pong 心跳、关闭帧等,实现复杂度高一个量级。
一个简单的判断标准:如果你的场景是服务端向客户端持续推送数据,优先考虑 SSE。只有当客户端也需要实时向服务端发送数据时(在线协作编辑、实时游戏、聊天室里的“对方正在输入…”),才需要 WebSocket。
大模型流式响应的数据结构
模型调用 API 那篇里已经展示过流式响应的基本格式。这里更系统地梳理一遍完整的数据结构,特别是一些之前没展开讲的细节。
1. 流式 vs 非流式的响应对比
先放一张对比表,有个全局认知:
| 对比维度 | 非流式响应 | 流式响应 |
|---|---|---|
| Content-Type | application/json | text/event-stream |
| 返回格式 | 一个完整的 JSON 对象 | 多个 data: 行,每行一个 JSON 对象 |
| 回答内容位置 | choices[0].message.content | choices[0].delta.content(增量) |
role 字段 | 在 message 里 | 只在第一个 chunk 的 delta 里 |
finish_reason | 在唯一的 choices[0] 里 | 只在最后一个 chunk 的 choices[0] 里 |
usage 统计 | 响应体里直接有 | 取决于平台(见下文) |
| 连接行为 | 返回响应后立即关闭 | 持续推送,直到 [DONE] |
2. 流式响应的逐 chunk 解析
用一个实际的例子来过一遍完整的流式响应。假设你问模型 SSE 是什么?,模型回答 SSE 是一种基于 HTTP 的服务端推送协议。
服务端推送过来的 SSE 流完整长这样:
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"SSE"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":" 是"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"一种"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"基于"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":" HTTP "},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"的"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"服务端"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"推送"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{"content":"协议。"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc","choices":[{"index":0,"delta":{},"finish_reason":"stop"}],"usage":{"prompt_tokens":15,"completion_tokens":12,"total_tokens":27}}
data: [DONE]
逐 chunk 拆解:
| 序号 | delta 内容 | finish_reason | 说明 |
|---|---|---|---|
| 1 | {"role":"assistant","content":""} | null | 开场白:模型说"我准备开始说话了",role 只出现这一次 |
| 2 | {"content":"SSE"} | null | 开始输出内容 |
| 3 | {"content":" 是"} | null | 继续输出 |
| 4~10 | {"content":"..."} | null | 逐块输出内容 |
| 11 | {} | "stop" | delta 为空,finish_reason 为 stop——说话结束 |
| - | [DONE] | - | SSE 流结束标记,不是 JSON |
客户端要做的事情:把第 1~10 个 chunk 的 delta.content 拼接起来,就是完整的回答。
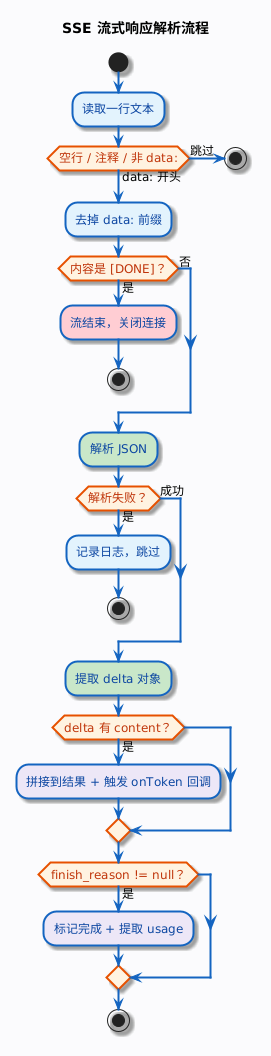
有几个需要注意的细节:
- 第一个 chunk 的
content可能是空字符串,不是所有平台都这样,但你��需要兼容。有的平台第一个 chunk 只有role,没有content字段。 - 中间可能出现空
delta:有的 chunk 的delta是空对象{},既没有content也没有role。不要因为拿不到content就报错。 finish_reason只在最后一个 chunk 有值,之前的 chunk 都是null。值不只是"stop"(正常结束),还可能是"length"(达到 max_tokens 上限被截断)、"content_filter"(被安全过滤截断)、"tool_calls"(模型转入工具调用流程)。代码里需要根据不同的值做相应处理。data: [DONE]不是 JSON,不能用 JSON 解析器去解析,要单独判断。
3. 流式模式下的 Token 统计
非流式响应里,usage 字段直接就在响应体里:
{
"choices": [...],
"usage": {
"prompt_tokens": 15,
"completion_tokens": 12,
"total_tokens": 27
}
}
流式模式下就麻烦了。不同平台的处理方式不一样:
方式一:最后一个 chunk 里附带 usage
部分平台(包括 SiliconFlow)会在 finish_reason: "stop" 那个 chunk 里附带 usage 字段。前面的示例里已经展示了这种情况。
方式二:需要额外参数 stream_options
OpenAI 的 API 需要在请求中显式加上 stream_options:
{
"model": "gpt-4",
"messages": [...],
"stream": true,
"stream_options": {
"include_usage": true
}
}
加了这个参数之后,OpenAI 会在流的最后额外发送一个只包含 usage 的 chunk(choices 为空数组)。
方式三:不返回 usage
有些平台在流式模式下压根不返回 usage。这种情况下,completion_tokens 可以在客户端自己估算(统计收到��的所有 delta.content 拼接后的字符数或 Token 数),但 prompt_tokens 只有服务端知道,拿不到就拿不到。
实测 SiliconFlow 平台的行为:在最后一个 chunk(
finish_reason: "stop")中会返回usage字段,不需要额外设置stream_options。如果你用的是其他平台,建议先测一下流式响应里有没有usage,没有的话看文档是否支持stream_options。
Java 实战:健壮的 SSE 客户端
1. 从 demo 到生产的差距
回顾一下模型调用 API 那篇里的流式调用代码。那段代码的核心逻辑是:
BufferedReader reader = new BufferedReader(new InputStreamReader(response.body().byteStream()));
String line;
while ((line = reader.readLine()) != null) {
if (line.startsWith("data: ")) {
String data = line.substring(6);
if ("[DONE]".equals(data)) break;
// 解析 JSON,提取 delta.content,拼接...
}
}
作为入门 demo 完全没问题,但在生产环境有几个隐患:
- 没有超时控制——如果服务端卡住不发数据(模型推理异常、网络拥塞),客户端的
readLine()会一直阻塞 - 没有错误处理——连接中断直接抛
IOException,调用方拿不到已经接收到的部分内容 - 没有回调机制——所有内容都是
System.out.print直接打印,没法集成到业务逻辑里(比如实时推送给前端) - 没有 Token 统计——流式模式下
usage的提取逻辑缺失 - 边界情况没处理——空
delta、缺失content字段、JSON 解析失败都没有容错
接下来封装一个相对偏向于生产可用的 SSE 流式客户端。
注意:下面的代码实现的是大模型流式 API 常见的 data-only SSE 消费逻辑,针对 OpenAI 兼容接口的主流场景做了优化。它不是一个完整的通用 SSE 协议解析器——标准 SSE 还有多行
data:拼接、未完成事件不派发等规则,在大模型 API 的场景下用不到,这里不做处理。
2. SSE 流式客户端的实现
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import okhttp3.*;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.TimeUnit;
public class SseStreamClient {
private static final String API_URL = "https://api.siliconflow.cn/v1/chat/completions";
private static final String API_KEY = "sk-xxx"; // 替换为你的 API Key
// ========== 回调接口 ==========
/**
* SSE 流式响应的事件回调
*/
interface StreamCallback {
/** 收到一个 content 增量(每个 token 调用一次) */
void onToken(String token);
/** 流正常结束,返回完整内容和 Token 统计 */
void onComplete(String fullContent, Usage usage);
/** 发生错误,partialContent 是错误发生前已接收到的内容 */
void onError(Exception e, String partialContent);
}
/**
* Token 用量统计
*/
static class Usage {
int promptTokens;
int completionTokens;
int totalTokens;
@Override
public String toString() {
return String.format("prompt=%d, completion=%d, total=%d",
promptTokens, completionTokens, totalTokens);
}
}
// ========== 核心方法 ==========
/**
* ��发起流式请求
*
* @param model 模型 ID
* @param systemPrompt System 消息内容
* @param userMessage 用户消息内容
* @param callback 事件回调
*/
public static void streamChat(String model, String systemPrompt,
String userMessage, StreamCallback callback) {
// 1. 构建请求体
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", model);
requestBody.addProperty("temperature", 0.7);
requestBody.addProperty("max_tokens", 2048);
requestBody.addProperty("stream", true);
JsonArray messages = new JsonArray();
if (systemPrompt != null && !systemPrompt.isEmpty()) {
JsonObject sysMsg = new JsonObject();
sysMsg.addProperty("role", "system");
sysMsg.addProperty("content", systemPrompt);
messages.add(sysMsg);
}
JsonObject userMsg = new JsonObject();
userMsg.addProperty("role", "user");
userMsg.addProperty("content", userMessage);
messages.add(userMsg);
requestBody.add("messages", messages);
// 2. 创建 HTTP 客户端
// 关键:readTimeout 是"两个数据块之间的最大等待时间",不是整个响应的超时
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(15, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS) // 流式场景需要更长
.writeTimeout(15, TimeUnit.SECONDS)
.build();
Request request = new Request.Builder()
.url(API_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "text/event-stream") // 明确告诉服务端我要 SSE
.post(RequestBody.create(requestBody.toString(),
MediaType.parse("application/json")))
.build();
// 3. 发起请求并解析 SSE 流
StringBuilder fullContent = new StringBuilder();
Usage usage = null;
try (Response response = client.newCall(request).execute()) {
// 检查 HTTP 状态码
if (!response.isSuccessful()) {
String errorBody = response.body() != null ? response.body().string() : "无响应体";
callback.onError(
new RuntimeException("HTTP " + response.code() + ": " + errorBody),
fullContent.toString()
);
return;
}
// 逐行读取 SSE 流(显式指定 UTF-8,SSE 规范要求 UTF-8 编码)
BufferedReader reader = new BufferedReader(
new InputStreamReader(response.body().byteStream(), StandardCharsets.UTF_8));
String line;
boolean streamDone = false; // 是否收到了 [DONE] 标记
while ((line = reader.readLine()) != null) {
// 跳过空行(SSE 事件分隔符)
if (line.isEmpty()) {
continue;
}
// 跳过注释行(心跳保活)
if (line.startsWith(":")) {
continue;
}
// 只处理 data: 开头的行(兼容 "data: xxx" 和 "data:xxx" 两种格式)
if (!line.startsWith("data:")) {
continue;
}
// 去掉 "data:" 前缀,SSE 标准规定冒号后最多去掉一个可选空格
String data = line.substring(5);
if (data.startsWith(" ")) {
data = data.substring(1);
}
// 检查流结束标记
if ("[DONE]".equals(data)) {
streamDone = true;
break;
}
// 解析 JSON(加容错)
JsonObject chunk;
try {
chunk = JsonParser.parseString(data).getAsJsonObject();
} catch (Exception e) {
// JSON 解析失败,跳过这个 chunk,不要中断整个流
System.err.println("JSON 解析失败,跳过: " + data);
continue;
}
// 提取 choices 数组
JsonArray choices = chunk.getAsJsonArray("choices");
if (choices == null || choices.isEmpty()) {
// 有些平台在最后一个 chunk(stream_options 模式)choices 为空数组
// 但可能有 usage 字段
usage = extractUsage(chunk, usage);
continue;
}
JsonObject choice = choices.get(0).getAsJsonObject();
// 提取 delta 中的 content
JsonObject delta = choice.getAsJsonObject("delta");
if (delta != null && delta.has("content")) {
JsonElement contentElement = delta.get("content");
if (!contentElement.isJsonNull()) {
String token = contentElement.getAsString();
if (!token.isEmpty()) {
fullContent.append(token);
callback.onToken(token);
}
}
}
// 提取 finish_reason
JsonElement finishElement = choice.get("finish_reason");
if (finishElement != null && !finishElement.isJsonNull()) {
String finishReason = finishElement.getAsString();
// finish_reason 不只是 "stop",还可能是:
// - "length":达到 max_tokens 上限,内容被截断
// - "content_filter":被安全过滤截断
// - "tool_calls":模型转入工具调用流程
// 这里统一标记为流结束,调用方可根据 finishReason 做更细的处理
usage = extractUsage(chunk, usage);
}
}
// 判断流是否正常结束
if (streamDone) {
callback.onComplete(fullContent.toString(), usage);
} else {
// readLine() 返回 null 但没收到 [DONE]——连接异常关闭
callback.onError(
new RuntimeException("SSE 流异常结束:未收到 [DONE] 标记"),
fullContent.toString()
);
}
} catch (Exception e) {
// 连接异常(超时、网络中断等),把已接收到的内容传给调用方
callback.onError(e, fullContent.toString());
}
}
/**
* 从 chunk 中提取 usage 信息
*/
private static Usage extractUsage(JsonObject chunk, Usage existing) {
if (!chunk.has("usage") || chunk.get("usage").isJsonNull()) {
return existing;
}
JsonObject usageJson = chunk.getAsJsonObject("usage");
Usage usage = new Usage();
usage.promptTokens = usageJson.has("prompt_tokens")
? usageJson.get("prompt_tokens").getAsInt() : 0;
usage.completionTokens = usageJson.has("completion_tokens")
? usageJson.get("completion_tokens").getAsInt() : 0;
usage.totalTokens = usageJson.has("total_tokens")
? usageJson.get("total_tokens").getAsInt() : 0;
return usage;
}
// ========== 运行示例 ==========
public static void main(String[] args) {
System.out.println("=== SSE 流式调用演示 ===\n");
streamChat(
"Qwen/Qwen3-32B",
"你是一个技术专家,回答简洁清晰。",
"用两三句话解释一下什么是 SSE 协议?",
new StreamCallback() {
@Override
public void onToken(String token) {
// 每收到一个 token 就实时输出(不换行)
System.out.print(token);
}
@Override
public void onComplete(String fullContent, Usage usage) {
System.out.println("\n");
System.out.println("--- 流式输出完毕 ---");
System.out.println("完整内容长度:" + fullContent.length() + " 字符");
if (usage != null) {
System.out.println("Token 统计:" + usage);
} else {
System.out.println("Token 统计:未返回");
}
}
@Override
public void onError(Exception e, String partialContent) {
System.err.println("\n\n--- 发生错误 ---");
System.err.println("错误信息:" + e.getMessage());
if (!partialContent.isEmpty()) {
System.err.println("已接收到的内容:" + partialContent);
}
}
}
);
}
}
运行输出:
=== SSE 流式调用演示 ===
SSE(Server-Sent Events)是基于 HTTP 的**服务器向客户端单向实时通信协议**,通过持久连接持续发送文本事件流(如 `data: message\n\n`)。
不同于 WebSocket,SSE**无需客户端主动发送消息**,适用于如实时通知、股票报价等需服务器主动推送的场景。
其优势包括**自动重连、兼容性好(HTML5 原生支持)**,但仅支持单向传输(服务器→客户端)。
--- 流式输出完毕 ---
完整内容长度:208 字符
Token 统计:prompt=33, completion=503, total=536
代码的几个关键设计点:
-
回调接口:
StreamCallback定义了三个回调方法——onToken(每个增量 token)、onComplete(流正常结束)、onError(出错)。调用方实现这个接口就能把流式内容集成到自己的业务逻辑里,比如实时推送给前端(下一篇会讲)、写入日志、或者显示进度。 -
错误时不丢内容:
onError方法带了一个partialContent参数。如果流传输到一半连接断了,调用方至少能拿到已经收到的部分内容,而不是什么都没有。 -
JSON 解析容错:解析失败不中断整个流——跳过这个有问题的 chunk,继续处理后面的。在生产环境中,偶尔会遇到格式不规范的 chunk(服务端 bug 或网络传输问题),直接崩掉是不合适的。
-
Usage 提取兼容:先尝试从
finish_reason: stop的 chunk 里提取usage,也兼容choices为空数组但有usage字段的情况(OpenAIstream_options模式)。
3. 常见坑与处理
3.1 流式超时怎么设
OkHttp 的 readTimeout 在非流式和流式场景下含义不同:
- 非流式:
readTimeout是从发出请求到收到完整响应的最大等待时间。设 30 秒意味着如果 30 秒内拿不到完整回答,就超时。 - 流式:
readTimeout是两次数据读取之间的最大等待时间。设 30 秒意味着如果 30 秒内没有收到任何新的 chunk,就超时。
这个区别很重要。流式场景下,整个响应可能持续几十秒甚至几分钟(长文本生成),但只要两个 chunk 之间的间隔不超过 readTimeout,就不会超时。
那设多少合适?
- 设太短(比如 5 秒):模型在思考比较复杂的问题时,两个 token 之间的间隔可能超过 5 秒(特别是用了深度思考模式的模型),会误判为超时。
- 设太长(比如 300 秒):如果服务端真的卡死了,你要等 5 分钟才能发现。
建议值:30~60 秒。对于大部分大模型 API,两个 chunk 之间的间隔通常在毫秒到几秒之间。30 秒的容忍度足够覆盖模型思考的场景,又不至于让真正的故障等太久。
connectTimeout和writeTimeout不受流式影响,正常设置即可(10~15 秒)。
3.2 空 delta 和缺失字段
不同平台、不同模型返回的 delta 结构不完全一致。你可能遇到这些情况:
// 情况 1:delta 有 role 但没有 content
{"delta": {"role": "assistant"}}
// 情况 2:delta 有 content 但是空字符串
{"delta": {"content": ""}}
// 情况 3:delta 是空对象
{"delta": {}}
// 情况 4:delta 的 content 是 null
{"delta": {"content": null}}
前面的代码里已经做了处理——检查 delta 是否为 null、是否有 content 字段、content 是否为 null 或空字符串。这些检查看着啰嗦,但少一个就可能在某个平台上翻车。
3.3 粘包问题
SSE 的数据是通过 HTTP 的 chunked transfer encoding 传输的。在网络层面,一次 TCP 传输可能包含多个 data: 行,也可能一个 data: 行被截断成两次传输。
如果你用 BufferedReader.readLine() 来读取,不用担心这个问题——readLine() 会帮你按换行符分割,保证每次返回一个完整的行。
但如果你用原始的 InputStream.read(byte[]) 来读取(比如为了更高的性能),就需要自己处理行边界。对于大部分场景,BufferedReader 的性能完全够用,没必要用原始 InputStream 去找麻烦。
3.4 连接中断的处理
网络不稳定时,SSE 连接可能中途断开。表现为 readLine() 抛出 IOException(通常是 SocketTimeoutException 或 SocketException)。
对于大模型 API 的场景,断了通常不��能从断点续传——因为 LLM 的生成是有状态的,内部的注意力缓存(KV Cache)在服务端,连接断了这些状态就丢了。要继续的话只能重新发请求。
代码里的处理策略:
- 在
catch块里调用onError,把已接收到的部分内容传给调用方 - 调用方根据业务需求决定是否重试——如果已经收到了大部分内容,可能展示部分结果比重试更好
- 如果决定重试,把之前的问题重新发一次(不是续传,是全新的请求)
// 调用方的重试逻辑示例
public void chatWithRetry(String question, int maxRetries) {
for (int i = 0; i <= maxRetries; i++) {
final int attempt = i;
final boolean[] success = {false};
SseStreamClient.streamChat("Qwen/Qwen3-32B", null, question,
new SseStreamClient.StreamCallback() {
@Override
public void onToken(String token) {
System.out.print(token);
}
@Override
public void onComplete(String fullContent, SseStreamClient.Usage usage) {
success[0] = true;
}
@Override
public void onError(Exception e, String partialContent) {
System.err.printf("第 %d 次请求失败: %s%n", attempt + 1, e.getMessage());
if (!partialContent.isEmpty()) {
System.err.println("已接收: " + partialContent.length() + " 字符");
}
}
}
);
if (success[0]) break;
if (i < maxRetries) {
System.err.println("等待 2 秒后重试...");
try { Thread.sleep(2000); } catch (InterruptedException ignored) {}
}
}
}
重试要注意幂等性——大模型 Chat API 的请求天然是幂等的(同样的输入不一定得到同样的输出,但不会产生副作用),可以放心重试。但如果你的请求里包含了 Function Call 调用外部系统的操作,重试就要小心了。
小结
这篇把 SSE 从能用提升到了懂原理的程度:
- SSE 协议完整规范:四个字段(
data:、event:、id:、retry:)加注释心跳机制。大模型 API 主要用data:字段,但理解完整规范能帮你排查问题和自建服务 - SSE vs WebSocket:大模型 API 选 SSE 的原因——方向匹配(单向推送)、HTTP 原生(基础设施天然支持)、实现简单
- 流式响应数据结构:
delta增量内容的逐 chunk 解析、finish_reason只在最后一个 chunk、Token 统计的三种获取方式(平台差异) - 生产级 SSE 客户端:回调接口、超时控制(30~60 秒)、JSON 解析容错、空 delta 兼容、错误处理不丢内容、区分正常结束与异常 EOF
这篇讲的是客户端消费——你作为调用方,怎么消费大模型推送过来的流式数据。但在实际项目中,你的 Java 后端不只是消费者,还是生产者——你需要把大模型的流式输出转发给你的前端用户。你的 Spring Boot 服务既是大模型 API 的 SSE 客户端,又是前端浏览器的 SSE 服务端。
有一个提前预警:即使你的客户端代码写得完全正确,如果中间的反向代理(Nginx、负载均衡器)开启了响应缓冲,前端看到的也可能不是逐 token 输出,而是憋一会儿一坨一起出来。这是线上很多人第一次踩的坑。
下一篇来讲 Spring Boot SSE 服务端实战——怎么用 SseEmitter 构建 SSE 推送接口,实现前端请求 → 后端调大模型 → 逐 Token 转发给前端的完整链路,以及生产环境的连接管理、Nginx 反向代理配置、超时处理这些工程细节。