向量检索策略与召回优化
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇讲完向量数据库,咱们已经能用 Milvus 做向量检索了——把用户的问题转成向量,在 Milvus 里找最相似的 chunk,看起来很完美。但实际跑起来,你会发现有些场景下纯向量检索会翻车。
假设你在维护一个电商客服知识库,用户问:订单号 2026012345 的物流状态是什么?你把这句话向量化后去 Milvus 里检索,返回的 Top-5 结果可能是:
- 物流配送时效说明
- 如何查询订单物流
- 物流异常处理流程
- 快递公司合作列表
- 订单状态说明
��看起来都和物流以及订单相关,但没有一个包含具体的订单号 2026012345。向量检索把 订单号 2026012345 理解成了物流相关的语义,匹配到一堆通用规则,但丢掉了最关键的精确信息——那个具体的订单号。
这就是纯向量检索的短板:它擅长理解语义,但对精确关键词不敏感。这一篇咱们就来聊聊怎么解决这个问题——通过关键词检索、混合检索、重排序,把检索质量提上去。
纯向量检索的短板:语义很强,但关键词很弱
1. 场景一:精确关键词丢失
再看一个例子。用户问:iPhone 16 Pro Max 的退货政策是什么?
向量检索会把这句话理解成"退货政策"的语义,返回所有和退货相关的 chunk:
- 七天无理由退货说明
- 退货流程和注意事项
- 不支持退货的商品类型
- 退货运费承担规则
- 退货审核时效
这些 chunk 确实都和退货有关,但用户要的是 iPhone 16 Pro Max 这个具体型号的退货政策。如果知识库里有一条专门针对这个型号的规则(比如 iPhone 16 Pro Max 因屏幕定制不支持七天无理由退货),向量检索不一定能把它排到前面,因为它更关注退货这个语义,而不是 iPhone 16 Pro Max 这�个精确关键词。
2. 场景二:专有名词和缩写
用户问:RMA 流程是什么?
RMA(Return Merchandise Authorization,退货授权)是一个专有缩写。向量检索可能把它理解成退货流程的语义,返回一堆通用的退货说明,但如果知识库里有一条专门讲 RMA 流程的文档,关键词匹配能直接命中,而向量检索可能把它排到很后面。
3. 场景三:数字和编号
用户问:2026 年春节发货安排是什么?
向量检索会把 2026 年春节理解成春节发货的语义,可能返回历年的春节发货安排(2024 年、2025 年、2026 年都有),但不一定优先返回 2026 年的那条。关键词检索能精确匹配 2026 这个数字,直接命中最相关的结果。
4. 向量检索和关键词检索的互补关系
看完这几个例子,你会发现向量检索和关键词检索各有擅长的地方:
| 维度 | 向量检索 | 关键词检索 |
|---|---|---|
| 擅长场景 | 语义理解、同义词、跨语言、意图匹配 | 精确关键词、专有名词、数字编号、缩写 |
| 典型 query | 买了一周的东西还能退吗(同义词) | 订单号 2026012345(精确匹配) |
| 短板 | 对精确关键词不敏感,容易丢失具体信息 | 无法理解语义,同义词匹配不上 |
| 底层原理 | 把文本转成向量,计算语义相似度 | 统计词频和文档频率,计算关键词重要性 |
它们不是谁替代谁的关系,而是互补的。理想的检索策略是把两者结合起来——用向量检索理解语义,用关键词检索补充精确匹配,取长补短。
关键词检索:BM25 算法
1. BM25 是什么——一句话概括
BM25(Best Matching 25)是一个经典的关键词检索算法,用来衡量一个查询词在某个文档中有多重要。它是搜索引擎(如 Elasticsearch)的默认排序算法,也是混合检索中关键词检索部分的核心。
打个比方,你在图书馆找书,关键词检索就像是看书名和目录里有没有你要找的词。如果一本书的书名里出现了你要找的词,而且这个词在其他书里很少出现(说明它很有区分度),那这本书大概率就是你要的。
2. BM25 的核心思想
BM25 不需要理解语义,它只看三个核心因素:
2.1 词频(TF):出现越多越相关,但有上限
如果一个词在文档里出现得越多,说明这个文档和这个词越相关。比如用户搜退货,一个文档里退货出现了 10 次,另一个文档里只出现了 1 次,前者大概率更相关。
但这里有个问题:如果一个文档里退货出现了 100 次,是不是就比出现 10 次的文档相关 10 倍?不一定。可能只是这个文档比较啰嗦,或者是机器生成的垃圾内容。所以 BM25 对词频做了饱和处理——出现次数从 1 增加到 10,分数涨得快;从 10 增加到 100,分数涨得慢;再往上基本不涨了。
用一句话概括:出现越多越相关,但有上限,避免长文档刷词占便宜。
2.2 逆文档频率(IDF):越稀有的词越有区分度
如果一个词在所有文档里都很常见(比如:的、是、有),那它没什么区分度,出现了也不能说明文档和查询相关。反过来,如果一个词很稀有(比如:iPhone 16 Pro Max、RMA、订单号 2026012345),那它出现在哪个文档里,哪个文档就很可能是用户要找的。
BM25 用逆文档频率(Inverse Document Frequency,IDF)来衡量��一个词的稀有程度。计算方式是:看这个词在多少个文档里出现过,出现得越少,IDF 越高,权重越大。
用一句话概括:越稀有的词越有区分度,越能帮你找到目标文档。
2.3 文档长度归一化:长文档不能占便宜
如果一个文档很长(比如 5000 字),另一个文档很短(比如 500 字),长文档里出现查询词的概率天然更高。但这不代表长文档就更相关——可能只是因为它废话多。
BM25 会对文档长度做归一化:如果一个文档比平均长度长,它的分数会被打折;如果比平均长度短,分数会被提升。这样长文档和短文档就站在同一起跑线上了。
用一句话概括:长文档不能因为块头大就占便宜,要按长度归一化。
3. BM25 vs 向量检索:不是谁替代谁
把 BM25 和向量检索放在一起对比,你会发现它们的设计思路完全不同:
| 维度 | BM25 关键词检索 | 向量检索 |
|---|---|---|
| 核心思想 | 统计词频和文档频率,计算关键词重要性 | 把文本转成向量,计算语义相似度 |
| 能否理解语义 | 不能。“七天无理由退货”和”买了一周的东西还能退吗”匹配不上 | 能。两句话语义相近��,向量距离也近 |
| 能否精确匹配 | 能。“订单号 2026012345”能精确命中 | 不能。数字和编号容易被理解成语义,丢失精确信息 |
| 对同义词的处理 | 不行。“手机”和“移动电话”匹配不上 | 行。Embedding 模型能把同义词映射到相近的向量 |
| 对专有名词的处理 | 很强。“iPhone 16 Pro Max”能精确匹配 | 一般。可能被拆成“iPhone16”“Pro”“Max”分别理解 |
| 计算成本 | 低。只需要统计词频,不需要调用模型 | 高。需要调用 Embedding 模型把 query 转成向量 |
| 典型应用 | 搜索引擎(Google、Elasticsearch) | 语义搜索、推荐系统、RAG |
看完这个表,你会发现它们是互补的:BM25 擅长精确匹配,向量检索擅长语义理解。所以实际 RAG 系统中,通常会把两者结合起来,这就是“混合检索”(Hybrid Search)。
4. Milvus 中的 BM25 支持
Milvus 从 2.5 版本开始内置了全文检索能力,支持 BM25 算法。你可以在创建 Collection 时指定一个 VarChar 字段用于全文检索,Milvus 会自动对这个字段做分词和倒排索引,支持 BM25 检索。
如果你用的 Milvus 版本低于 2.5,或者对中文分词有更高要求,也可以用外部方案——比如用 Elasticsearch 做关键词检索,Milvus 做向量检索,应用层把两路结果融合起来。这种方案架构复杂一些,但全文检索能力更强。
这一篇咱们用 Milvus 2.5+ 的原生方案,降低环境搭建成本。
混合检索:向量 + 关键词,取长补短
1. 混合检索的基本思路
混合检索(Hybrid Search)的核心思路很简单:同时执行向量检索和关键词检索,把两路结果融合成一个最终排序。
用一张图来表示:
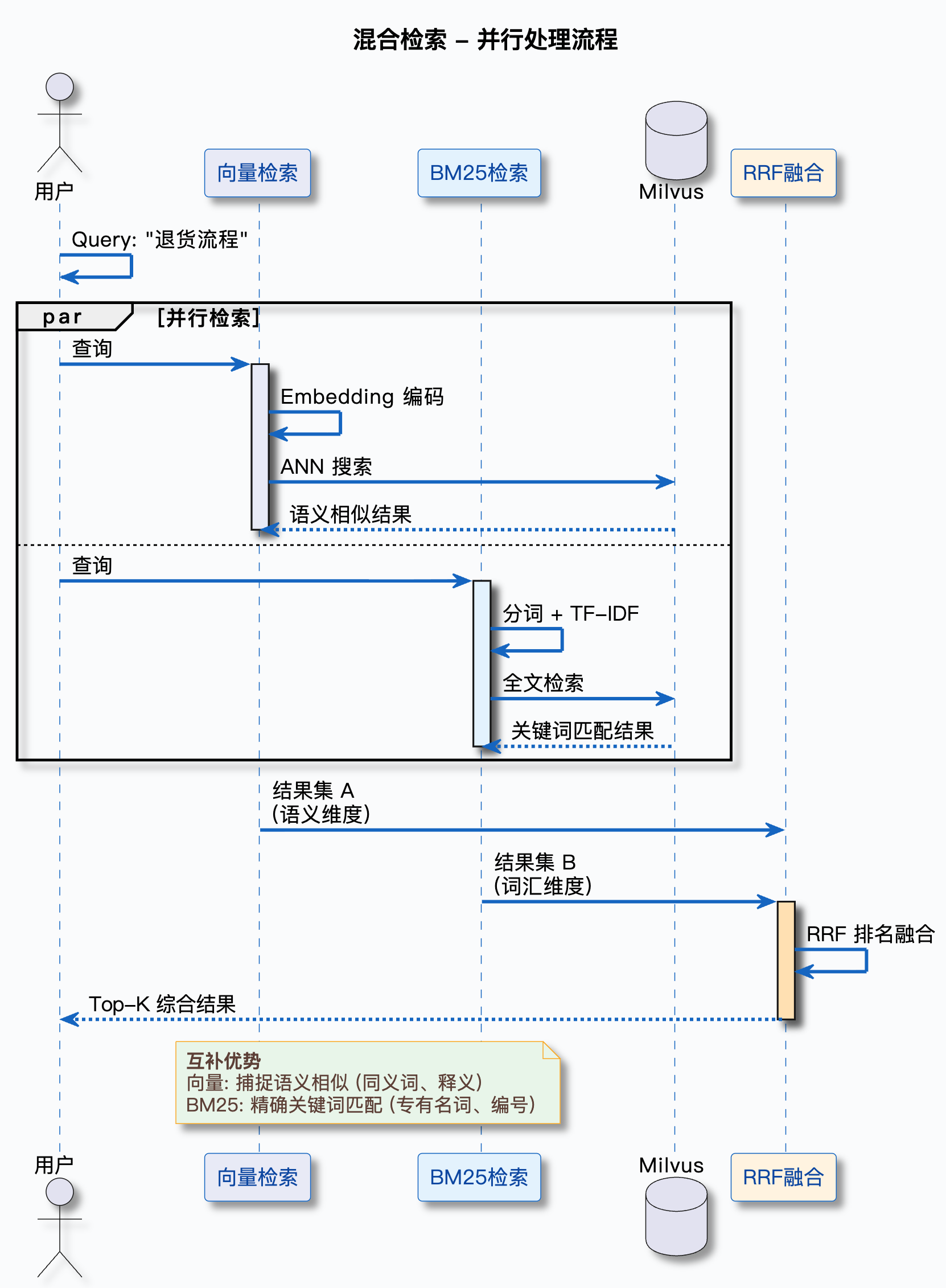
这张图展示了混合检索的基本流程:用户提问后,同时走向量检索和关键词检索两条路,最后把两路结果融合起来。
2. 两种架构方案:Milvus 原生 vs ES + Milvus
混合检索的关键词检索部分有两种实现方式,需要让读者理解各自的优劣和适用场景。
2.1 方案一:Milvus 原生混合检索(推荐)
Milvus 2.5+ 内置 BM25 全文检索能力,一个系统同时�搞定向量检索和关键词检索。
优点:
- 架构简单,不需要维护多套系统
- 数据不用双写,避免一致性问题
- Hybrid Search API 原生支持 RRF 融合
- 运维成本低,只需要管理一个 Milvus 集群
缺点:
- 全文检索能力相比 ES 偏基础
- 中文分词能力有限,不如 ES 的 IK 分词器等插件丰富
- 查询语法不如 ES 丰富(布尔查询、短语查询、聚合等)
2.2 方案二:Elasticsearch + Milvus 双系统
ES 负责关键词检索,Milvus 负责向量检索,应用层做结果融合。
优点:
- ES 的全文检索能力成熟强大
- 中文分词生态好(IK 分词器、HanLP 等)
- 查询语法丰富,支持复杂的布尔查询、短语查询、同义词扩展等
- 适合已有 ES 基础设施的团队
缺点:
- 需要维护两套系统,运维复杂度高
- 数据双写带来一致性问题(写入 Milvus 成功但写入 ES 失败怎么办?)
- 融合逻辑需要自己实现,增加开发成本
- 故障面扩大(任何一个系统挂了都会影响检索质量)
2.3 怎么选
给出一个简单的决策建议:
- 大多数 RAG 场景用 Milvus 原生方案就够了,架构简单,成本低
- 如果对中文分词有高要求(比如需要自定义词典、同义词扩展),再考虑 ES + Milvus
- 如果已有 ES 基础设施,且团队对 ES 很熟悉,可以考虑双系统方案
- 如果需要复杂的全文检索语法(布尔查询、短语查询、聚合等),ES + Milvus 更合适
本系列教程使用 Milvus 原生方案,降低环境搭建成本,让你能快速跑通整个流程。
3. 分数融合的难题:两种分数不在同一个尺度上
向量检索返回的是余弦相似度(01 之间),BM25 返回的是相关性分数(0正无穷),两者的值域不一样,不能直接相加。
打个比方,向量检索说“这个 chunk 和 query 的相似度是 0.85”,BM25 说“这个 chunk 的相关性分数是 12.3”,你怎么判断哪个更相关?直接相加(0.85 + 12.3 = 13.15)显然不合理,因为 BM25 的分数天然比余弦相似度大得多。
你可能会想到做归一化——把两种分数都映射到 01 之间,然后再相加或加权平均。但这也有问题:如果某一路检索的分数分布很集中(比如都在 0.80.9 之间),归一化后会把微小的差异放大;如果分数分布很分散(比如 0.1~0.9 都有),归一化后会把大的差异压缩。
所以实际工程中,最常用的融合策略不是基于分数,而是基于排名——这就是 RRF(Reciprocal Rank Fusion,倒数排名融合)。
4. RRF(倒数排名融合):最简单有效的融合策略
RRF 不依赖分数本身,只看排名。核心思想:一个结果在两路检索中排名都靠前,那它大概率是最相关的。
4.1 RRF 的计算方式
对于某个 chunk d,它的 RRF 分数计算公式是:
RRF(d) = Σ 1 / (k + rank_i(d))
这里:
rank_i(d)是 chunk d 在第 i 路检索中的排名(从 1 开始)k是一个平滑常数,通常取 60Σ表示对所有检索路求和
用一个具体例子走一遍。假设向量检索返回 [A, B, C, D, E],关键词检索返回 [C, A, F, B, G],怎么用 RRF 融合成最终排序?
| Chunk | 向量检索排名 | 关键词检索排名 | RRF 分数(k=60) | 计算过程 |
|---|---|---|---|---|
| A | 1 | 2 | 1/61 + 1/62 = 0.0325 | 在向量检索中排第 1,在关键词检索中排第 2 |
| B | 2 | 4 | 1/62 + 1/64 = 0.0317 | 在向量检索中排第 2,在关键词检索中排第 4 |
| C | 3 | 1 | 1/63 + 1/61 = 0.0323 | 在向量检索中排第 3��,在关键词检索中排第 1 |
| D | 4 | - | 1/64 = 0.0156 | 只在向量检索中出现,排第 4 |
| E | 5 | - | 1/65 = 0.0154 | 只在向量检索中出现,排第 5 |
| F | - | 3 | 1/63 = 0.0159 | 只在关键词检索中出现,排第 3 |
| G | - | 5 | 1/65 = 0.0154 | 只在关键词检索中出现,排第 5 |
按 RRF 分数从高到低排序,最终结果是:A、C、B、F、D、E、G。
你会发现 A 和 C 排到了最前面,因为它们在两路检索中都排名靠前。这正是混合检索想要的兼顾语义和关键词的效果。
4.2 为什么 RRF 效果好
- 不需要做复杂的分数归一化,避免了归一化带来的问题
- 对异常高分和分值尺度差异不敏感,鲁棒性强
- 在工程上稳定、好调试、好解释
- 学术界和工业界都验证过效果,是混合检索的事实标准
5. Milvus 中的混合检索实现
下面这段完整代码覆盖了 Schema 创建、数据插入、以及三种检索模式(纯向量 / 纯 BM25 / 混合 RRF)的对比。密集向量通过 SiliconFlow 的 Qwen3-Embedding-8B 模型生成,稀疏向量由 Milvus BM25 Function 自动生成。
完整代码可以查看 TinyRAG 项目 com.nageoffer.ai.tinyrag.milvus.hybrid 目录下代码。
public class MilvusHybridSchemaDemo {
private static final String COLLECTION = "customer_service_hybrid";
private static final String SILICONFLOW_API_KEY = "你的 SiliconFlow API Key";
private static final String EMBEDDING_URL = "https://api.siliconflow.cn/v1/embeddings";
private static final String EMBEDDING_MODEL = "Qwen/Qwen3-Embedding-8B";
private static final Gson GSON = new Gson();
private static final OkHttpClient HTTP_CLIENT = new OkHttpClient();
/** 三种检索模式 */
public enum SearchMode {
DENSE_ONLY, // 纯向量检索
SPARSE_ONLY, // 纯 BM25 检索
HYBRID // Dense + Sparse 混合检索
}
/** 检索参数配置 */
public static class SearchConfig {
public int denseRecallTopK = 20;
public int sparseRecallTopK = 20;
public int finalTopK = 8;
public int nprobe = 16;
public double dropRatioSearch = 0.2;
public int rrfK = 60;
public List<String> outFields = List.of("text");
public ConsistencyLevel consistencyLevel = ConsistencyLevel.BOUNDED;
public static SearchConfig defaults() {
return new SearchConfig();
}
}
public static void main(String[] args) {
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
createCollectionIfAbsentAndLoad(client);
String query = "订单号 2026012345 的物流状态";
SearchConfig cfg = SearchConfig.defaults();
// 依次跑三种模式做对比
for (SearchMode mode : SearchMode.values()) {
SearchResp resp = runSearch(client, query, mode, cfg);
printSearchResults(resp, mode);
}
}
// ==================== Collection 创建与数据加载 ====================
public static void createCollectionIfAbsentAndLoad(MilvusClientV2 client) {
Boolean exists = client.hasCollection(
HasCollectionReq.builder().collectionName(COLLECTION).build()
);
if (!Boolean.TRUE.equals(exists)) {
// 1) Schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id").dataType(DataType.Int64)
.isPrimaryKey(true).autoID(true).build());
schema.addField(AddFieldReq.builder()
.fieldName("text").dataType(DataType.VarChar)
.maxLength(8192).enableAnalyzer(true).build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense").dataType(DataType.FloatVector)
.dimension(4096).build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse").dataType(DataType.SparseFloatVector).build());
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(List.of("text"))
.outputFieldNames(List.of("text_sparse"))
.build());
// 2) Create collection
client.createCollection(CreateCollectionReq.builder()
.collectionName(COLLECTION).collectionSchema(schema).build());
// 3) Index
IndexParam denseIndex = IndexParam.builder()
.fieldName("text_dense")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.COSINE).build();
IndexParam sparseIndex = IndexParam.builder()
.fieldName("text_sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25).build();
client.createIndex(CreateIndexReq.builder()
.collectionName(COLLECTION)
.indexParams(List.of(denseIndex, sparseIndex)).build());
// 4) Insert demo data
List<JsonObject> rows = Arrays.asList(
buildRow("订单号 2026012345 的物流状态:已发货,预计 1 月 28 日送达,承运商顺丰速运。"),
buildRow("物流规则总述:标准订单 48 小时内发货,偏远地区可能延迟 1-2 天。"),
buildRow("发货时效说明:付款成功后,普通商品 24-48 小时内发货,预售商品以详情页为准。"),
buildRow("异常签收处理:如包裹显示已签收但未收到,请在 48 小时内联系客服核实。"),
buildRow("订单查询入口:登录 APP → 我的订单 → 输入订单号即可查看物流详情。"),
buildRow("退货政策:收到商品 7 天内可申请无理由退货,需保持商品完好。")
);
InsertResp insertResp = client.insert(InsertReq.builder()
.collectionName(COLLECTION).data(rows).build());
System.out.println("插入数据条数:" + insertResp.getInsertCnt());
}
client.loadCollection(LoadCollectionReq.builder()
.collectionName(COLLECTION).build());
System.out.println("Collection 已就绪并加载:" + COLLECTION);
}
// ==================== 三种检索模式 ====================
@SneakyThrows
public static SearchResp runSearch(MilvusClientV2 client,
String queryText,
SearchMode mode,
SearchConfig cfg) {
return switch (mode) {
case DENSE_ONLY -> runDenseOnly(client, queryText, cfg);
case SPARSE_ONLY -> runSparseOnly(client, queryText, cfg);
default -> runHybrid(client, queryText, cfg);
};
}
/** 纯向量检索 */
private static SearchResp runDenseOnly(MilvusClientV2 client,
String queryText,
SearchConfig cfg) throws IOException {
List<Float> queryVec = getEmbedding(queryText);
Map<String, Object> params = new HashMap<>();
params.put("metric_type", "COSINE");
params.put("nprobe", cfg.nprobe);
return client.search(SearchReq.builder()
.collectionName(COLLECTION)
.annsField("text_dense")
.data(Collections.singletonList(new FloatVec(queryVec)))
.topK(cfg.finalTopK)
.outputFields(cfg.outFields)
.searchParams(params)
.consistencyLevel(cfg.consistencyLevel)
.build());
}
/** 纯 BM25 检索 */
private static SearchResp runSparseOnly(MilvusClientV2 client,
String queryText,
SearchConfig cfg) {
Map<String, Object> params = new HashMap<>();
params.put("metric_type", "BM25");
params.put("drop_ratio_search", cfg.dropRatioSearch);
return client.search(SearchReq.builder()
.collectionName(COLLECTION)
.annsField("text_sparse")
.data(Collections.singletonList(new EmbeddedText(queryText)))
.topK(cfg.finalTopK)
.outputFields(cfg.outFields)
.searchParams(params)
.consistencyLevel(cfg.consistencyLevel)
.build());
}
/** 混合检索:Dense + Sparse,RRF 融合 */
private static SearchResp runHybrid(MilvusClientV2 client,
String queryText,
SearchConfig cfg) throws IOException {
List<Float> queryVec = getEmbedding(queryText);
AnnSearchReq denseReq = AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(Collections.singletonList(new FloatVec(queryVec)))
.params("{\"nprobe\": " + cfg.nprobe + "}")
.topK(cfg.denseRecallTopK)
.build();
AnnSearchReq sparseReq = AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(Collections.singletonList(new EmbeddedText(queryText)))
.params("{\"drop_ratio_search\": " + cfg.dropRatioSearch + "}")
.topK(cfg.sparseRecallTopK)
.build();
HybridSearchReq hybridReq = HybridSearchReq.builder()
.collectionName(COLLECTION)
.searchRequests(List.of(denseReq, sparseReq))
.ranker(new RRFRanker(cfg.rrfK))
.topK(cfg.finalTopK)
.consistencyLevel(cfg.consistencyLevel)
.outFields(cfg.outFields)
.build();
return client.hybridSearch(hybridReq);
}
private static void printSearchResults(SearchResp resp, SearchMode mode) {
System.out.println("\n===== Mode: " + mode + " =====");
List<List<SearchResp.SearchResult>> results = resp.getSearchResults();
for (List<SearchResp.SearchResult> oneQueryResults : results) {
for (int i = 0; i < oneQueryResults.size(); i++) {
SearchResp.SearchResult r = oneQueryResults.get(i);
System.out.println("Top-" + (i + 1) + " score=" + r.getScore() + ", id=" + r.getId());
Object text = r.getEntity() == null ? null : r.getEntity().get("text");
System.out.println(" " + text);
}
}
}
// ==================== 工具方法 ====================
@SneakyThrows
private static JsonObject buildRow(String text) {
JsonObject row = new JsonObject();
row.addProperty("text", text);
List<Float> denseVector = getEmbedding(text);
JsonArray arr = new JsonArray();
for (Float f : denseVector) arr.add(f);
row.add("text_dense", arr);
return row;
}
/** 调用 SiliconFlow Embedding API 生成密集向量 */
private static List<Float> getEmbedding(String text) throws IOException {
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", EMBEDDING_MODEL);
requestBody.add("input", GSON.toJsonTree(List.of(text)));
Request request = new Request.Builder()
.url(EMBEDDING_URL)
.addHeader("Authorization", "Bearer " + SILICONFLOW_API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
GSON.toJson(requestBody),
MediaType.parse("application/json")))
.build();
try (Response response = HTTP_CLIENT.newCall(request).execute()) {
String body = Objects.requireNonNull(response.body()).string();
if (!response.isSuccessful()) {
throw new IOException("Embedding API 调用失败 http=" + response.code() + ", body=" + body);
}
JsonObject json = GSON.fromJson(body, JsonObject.class);
JsonArray dataArray = json.getAsJsonArray("data");
if (CollUtil.isEmpty(dataArray)) {
throw new IOException("Embedding API 返回 data 为空,原始响应: " + body);
}
JsonArray embeddingArray = dataArray.get(0).getAsJsonObject().getAsJsonArray("embedding");
if (embeddingArray == null) {
throw new IOException("Embedding API 返回 embedding 为空,原始响应: " + body);
}
List<Float> vector = new ArrayList<>(embeddingArray.size());
for (int i = 0; i < embeddingArray.size(); i++) {
vector.add(embeddingArray.get(i).getAsFloat());
}
return vector;
}
}
}
这段代码的关键点:
SearchMode枚举支持三种模式切换,方便对比测试- 纯向量检索用
client.search()+FloatVec,纯 BM25 用client.search()+EmbeddedText,混合检索用client.hybridSearch()+RRFRanker EmbeddedText直接传原文,Milvus 会自动分词并计算 BM25 分数SearchConfig集中管理检索参数,便于调优
6. 混合检索的效果对比
用同一个 query:"订单号 2026012345 的物流状态",对比三种检索模式的实际运行结果。
纯向量检索(DENSE_ONLY)
| 排名 | score | 内容 |
|---|---|---|
| Top-1 | 0.840 | 订单号 2026012345 的物流状态:已发货,预计 1 月 28 日送达,承运商顺丰速运。 |
| Top-2 | 0.816 | 订单查询入口:登录 APP → 我的订单 → 输入订单号即可查看物流详情。 |
| Top-3 | 0.573 | 异常签收处理:如包裹显示已签收但未收到,请在 48 小时内联系客服核实。 |
| Top-4 | 0.484 | 发货时效说明:付款成功后,普通商品 24-48 小时内发货,预售商品以详情页为准。 |
| Top-5 | 0.457 | 物流规则总述:标准订单 48 小时内发货,偏远地区可能延迟 1-2 天。 |
| Top-6 | 0.389 | 退货政策:收到商品 7 天内可申请无理由退货,需保持商品完好。 |
纯 BM25 检索(SPARSE_ONLY)
| 排名 | score | 内容 |
|---|---|---|
| Top-1 | 3.837 | 订单号 2026012345 的物流状态:已发货,预计 1 月 28 日送达,承运商顺丰速运。 |
只返回了 1 条结果,其余 5 条因词汇重叠太少,BM25 打分低于
drop_ratio_search阈值被过滤。
混合检索(HYBRID,RRF k=60)
| 排名 | score | 内容 |
|---|---|---|
| Top-1 | 0.0328 | 订单号 2026012345 的物流状态:已发货,预计 1 月 28 日送达,承运商顺丰速运。 |
| Top-2 | 0.0161 | 订单查询入口:登录 APP → 我的订单 → 输入订单号即可查看物流详情。 |
| Top-3 | 0.0159 | 异常签收处理:如包裹显示已签收但未收到,请在 48 小时内联系客服核实。 |
| Top-4 | 0.0156 | 发货时效说明:付款成功后,普通商品 24-48 小时内发货,预售商品以详情页为准。 |
| Top-5 | 0.0154 | 物流规则总述:标准订单 48 小时内发货,偏远地区可能延迟 1-2 天。 |
| Top-6 | 0.0152 | 退货政策:收到商品 7 天内可申请无理由退货,需保持商品完好。 |
结果分析:
从这组对比中可以观察到几个关键现象:
-
score 量纲完全不同:BM25 的分数是 3.8,COSINE 相似度是 0.84,RRF 融合后是 0.033。三种分数不可直接比较,RRF 分数的计算公式是
1/(k+rank),k=60 时 Top-1 的理论上限约为2 × 1/61 ≈ 0.033(两路都排第一时取到最大值) -
BM25 高精度、低召回:纯 BM25 只返回了 1 条结果,因为 query 中的"订单号""2026012345""物流""状态"这些 token 只在第一条文本中大量出现,其余文本的词汇重叠太少被
drop_ratio_search=0.2过滤。这正是 BM25 的典型特征——精确匹配能力强,但对语义相近但措辞不同的文本无能为力 -
向量检索高召回、语义泛化:纯向量检索返回了全部 6 条结果,且 Top-2"订单查询入口"虽然不包含"2026012345"这个关键词,但语义上与"查订单物流"高度相关,COSINE 分数达到 0.816。这体现了向量检索的语义泛化能力
-
混合检索兼顾两者:Top-1 精确命中了包含订单号的文本(BM25 的贡献),同时 Top-2 到 Top-6 保留了向量检索的语义排序(向量检索的贡献)。在当前小数据集下,混合检索的排序与纯向量检索一致,但 Top-1 的 RRF 分数(0.0328)显著高于 Top-2(0.0161),拉开了近一倍的差距——这正是因为 Top-1 在两路检索中都排第一,获得了双倍的 RRF 加分
当前示例数据只有 6 条,三种模式的 Top-1 都是同一条,混合检索的互补优势不够明显。在实际生产环境中,当数据量达到数万甚至数百万条时,纯向量检索容易把语义相近但不相关的结果排到前面,纯 BM25 容易漏掉措辞不同但语义相关的结果,混合检索的优势会更加显著。
重排序(Reranking):对候选结果做精细化排序
1. 为什么需要重排序
混合检索已经能把相关的 chunk 召回来了,为什么还需要重排序?
因为召回阶段(向量检索 / BM25 / 混合检索)追求的是快速召回尽可能多的相关结果,但排序不一定精准。打个比方,你在图书馆找书,召回阶段是把可能相关的书都搬到桌子上,重排序是仔细翻看每本书,把最相关的几本排到最前面。
最终给 LLM 的上下文窗口很小,真正关键的是 Top-3 或 Top-5 的排序是否正确。如果 Top-1 是不相关的 chunk,LLM 很可能被误导,生成错误的答案。重排序就是解决这一步——用更强的模型对候选集重新打分,把最相关的结果排到最前面。
2. 重排序的工作原理
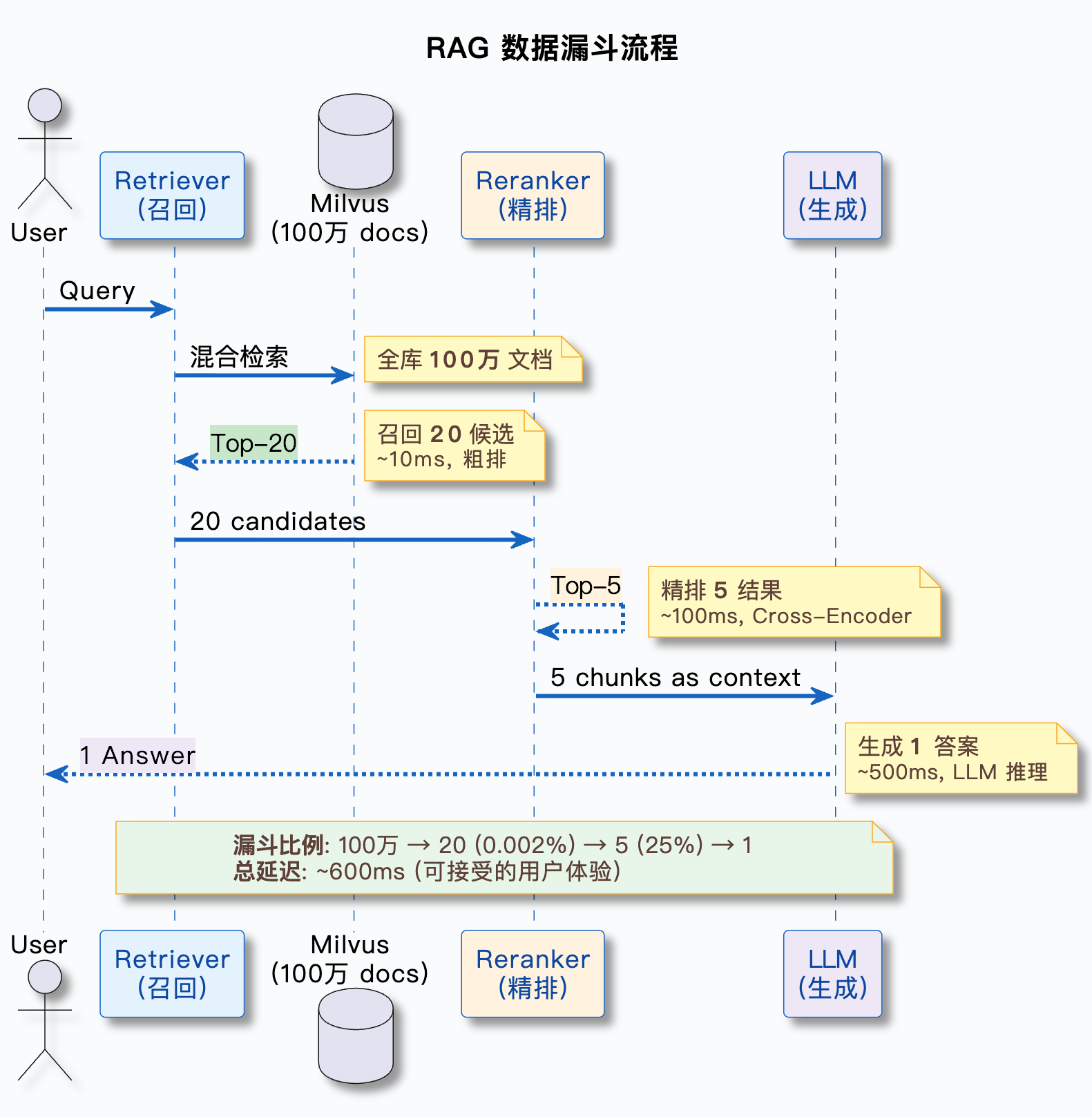
重排序的基本流程是:
- 初检阶段(向量检索 / 混合检索)快速召回候选集,比如 Top-20 或 Top-50
- 重排序模型逐个评估这个 chunk 和用户问题到底有多相关,给每个候选打分
- 按重排序分数重新排序,取 Top-K(比如 Top-5)作为最终结果
用一张图来表示:
2.1 Bi-Encoder vs Cross-Encoder
这里需要理解两种编码器的区别:
-
Bi-Encoder(双编码器):query 和 chunk 分别编码成向量,然后计算向量相似度。这就是 Embedding 模型的工作方式。优点是速度快,可以提前把所有 chunk 编码好存起来,查询时只需要编码 query;缺点是精度有限,因为 query 和 chunk 是独立编码的,无法捕捉它们之间的细粒度交互关系。
-
Cross-Encoder(交叉编码器):把 query 和 chunk 拼接在一起(比如
[CLS] query [SEP] chunk [SEP]),一起输入模型,模型能看到 query 和 chunk 的完整交互,输出一个相关性分数。优点是精度更高,能捕捉更细粒度的语义关系;缺点是速度慢,每个 (query, chunk) 对都要过一遍模型。
重排序通常用 Cross-Encoder,因为候选集已经很小了(比如 20~50 个),可以接受慢一点的速度,换取更高的精度。
2.2 为什么不直接用 Cross-Encoder 做检索
你可能会问:既然 Cross-Encoder 精度更高,为什么不直接用它做检索,还要搞两阶段?
因为太慢了。假设你的知识库有 100 万个 chunk,用户提问时,你需要把这 100 万个 chunk 逐个和 query 拼接起来过 Cross-Encoder,这需要 100 万次模型推理,延迟和成本都不可接受。
所以工程上一定是两阶段策略:
- 粗检索(Bi-Encoder):快速从 100 万个 chunk 中召回 Top-20 或 Top-50,延迟低,覆盖面广
- 精排序(Cross-Encoder):对这 20~50 个候选逐个打分,延迟可接受,精度高
这就是快召回 + 慢精排的核心思想。
3. 常用的重排序模型
对比几个主流的 Reranker 模型(截至 2026 年 2 月):
| 模型 | 特点 | 中文效果 | API 可用性 | 适用建议 |
|---|---|---|---|---|
| BAAI/bge-reranker-v2-m3 | 轻量、中文效果稳定、部署灵活 | 好 | SiliconFlow 等平台有 API | 预算敏感且要中文效果 |
| Qwen/Qwen3-Reranker-8B | 长文本能力强,支持 instruction 定制 | 很好 | SiliconFlow 等平台有 API | 行业问答、复杂意图排序 |
| Cohere rerank-v4.0 | 商业 API 成熟,集成体验好 | 一般 | Cohere 官方 API | 海外或多语言产品化场景 |
| jina-reranker-v2-base-multilingual | 多语言支持好 | 好 | Jina AI 官方 API | 跨语言场景 |
这一篇咱们用 SiliconFlow 的 Reranker API,支持 BAAI/bge-reranker-v2-m3 和 Qwen/Qwen3-Reranker-8B,中文效果都不错。
4. Java 代码实现:调用 Reranker API 做重排序
下面示例把混合检索的候选结果送到 SiliconFlow rerank 接口,再取最终 Top-K。
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import okhttp3.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class SiliconFlowRerankDemo {
private static final String API_KEY = "你的 SiliconFlow API Key";
private static final String RERANK_URL = "https://api.siliconflow.cn/v1/rerank";
private static final String MODEL = "BAAI/bge-reranker-v2-m3";
private static final Gson GSON = new Gson();
private static final OkHttpClient HTTP = new OkHttpClient();
public static class RerankItem {
public int index;
public double score;
public String text;
}
public static List<RerankItem> rerank(String query, List<String> candidates, int topN) throws IOException {
JsonObject body = new JsonObject();
body.addProperty("model", MODEL);
body.addProperty("query", query);
body.add("documents", GSON.toJsonTree(candidates));
body.addProperty("top_n", topN);
body.addProperty("return_documents", true);
Request request = new Request.Builder()
.url(RERANK_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(GSON.toJson(body), MediaType.parse("application/json")))
.build();
try (Response response = HTTP.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new RuntimeException("rerank 调用失败,HTTP=" + response.code());
}
JsonObject resp = GSON.fromJson(response.body().string(), JsonObject.class);
JsonArray results = resp.getAsJsonArray("results");
List<RerankItem> items = new ArrayList<>();
for (int i = 0; i < results.size(); i++) {
JsonObject one = results.get(i).getAsJsonObject();
RerankItem item = new RerankItem();
item.index = one.get("index").getAsInt();
item.score = one.get("relevance_score").getAsDouble();
if (one.has("document") && one.get("document").isJsonObject()) {
JsonObject doc = one.getAsJsonObject("document");
item.text = doc.has("text") ? doc.get("text").getAsString() : candidates.get(item.index);
} else {
item.text = candidates.get(item.index);
}
items.add(item);
}
items.sort(Comparator.comparingDouble((RerankItem x) -> x.score).reversed());
return items;
}
}
public static void main(String[] args) throws IOException {
String query = "订单号 2026012345 的物流状态";
List<String> candidates = List.of(
"物流配送时效说明:全国大部分地区 48 小时内发货",
"订单号 2026012345:已于 2026-02-18 14:21 从杭州仓发出,承运商顺丰,当前状态运输中",
"如何查询订单物流:登录账号后进入订单详情页,点击物流跟踪",
"物流异常处理流程:如遇物流异常,请联系客服处理",
"快递公司合作列表:顺丰、圆通、中通、韵达"
);
List<RerankItem> results = rerank(query, candidates, 3);
System.out.println("重排序后的 Top-3:");
for (int i = 0; i < results.size(); i++) {
RerankItem item = results.get(i);
System.out.println("Top-" + (i + 1) + " score=" + item.score);
System.out.println(" " + item.text);
}
}
}
如果你用 Qwen/Qwen3-Reranker-8B,可以额外传 instruction 参数(比如"优先排序包含订单号与时间状态的文档"),在业务问答里很实用:
JsonObject body = new JsonObject();
body.addProperty("model", "Qwen/Qwen3-Reranker-8B");
body.addProperty("query", query);
body.add("documents", GSON.toJsonTree(candidates));
body.addProperty("top_n", topN);
body.addProperty("return_documents", true);
body.addProperty("instruction", "优先排序包含订单号与时间状态的文档"); // 自定义指令
返回结果如下所示:
重排序后的 Top-3:
Top-1 score=0.9958966970443726
订单号 2026012345:已于 2026-02-18 14:21 从杭州仓发出,承运商顺丰,当前状态运输中
Top-2 score=0.5168612599372864
如何查询订单物流:登录账号后进入订单详情页,点击物流跟踪
Top-3 score=0.033042728900909424
物流配送时效说明:全国大部分地区 48 小时内发货
5. 重排序前后的效果对比
用同一个 query:iPhone 16 Pro Max 拆封后还能退吗,对比重排序前后的结果。
| 阶段 | Top-1 | Top-2 | Top-3 |
|---|---|---|---|
| 混合检索(未重排) | 七天无理由退货说明 | iPhone 16 Pro Max 退货政策 | 退货流程和注意事项 |
| 混合检索 + Rerank | iPhone 16 Pro Max 退货政策 | 七天无理由退货说明 | 拆封商品退货规则 |
你会发现,重排序把 iPhone 16 Pro Max 退货政策这条最相关的 chunk 从 Top-2 提升到了 Top-1,同时把拆封商品退货规则这条也提上来了(因为 query 里有拆封这个关键信息)。
重排序的价值不在多找几个,而在把真正该进上下文窗口的那几个排到最前面。
完整检索流程:从用户提问到最终结果
1. 四种检索策略的完整对比
用同一条 query:iPhone 16 Pro Max 拆封后还能退吗,分别跑四种检索策略,对比效果。
| 策略 | 召回覆盖 | Top-3 精度 | 延迟 | 成本 | 适用场景 |
|---|---|---|---|---|---|
| 纯向量检索 | 高 | 中 | 低 | 低 | 数据量小,query 以自然语言为主 |
| 纯 BM25 检索 | 中 | 中 | 低 | 低 | query 包含大量精确关键词 |
| 混合检索 | 高 | 高 | 中 | 中 | 大多数 RAG 场景的推荐方案 |
| 混合检索 + Rerank | 最高 | 最高 | 中高 | 中高 | 对答案准确率要求高的场景 |
2. 检索策略的选型建议
给出一个简单的决策表:
| 场景 | 推荐策略 | 理由 |
|---|---|---|
| 数据量小(< 1 万条),query 都是自然语言 | 纯向量检索 | 简单够用,成本低 |
| query 经常包含订单号、型号、专有名词 | 混合检索 | 关键词检索补充精确匹配能力 |
| 业务对答案准确率要求高,愿意牺牲一点延迟 | 混合检索 + 重排序 | 重排序显著提升 Top-K 质量 |
| 成本敏感,不想调用额外的 Reranker API | 混合检索(不加重排序) | RRF 融合本身已经有不错的效果 |
| 已有 ES 基础设施,对中文分词要求高 | ES + Milvus 双系统 | 利用现有基础设施,全文检索能力更强 |
3. 检索参数调优
先给一组可直接上线试跑的经验值:
| 参数 | 建议起始值 | 调优方向 |
|---|---|---|
| Dense topK | 20 | 漏召回就加大,延迟高就减小 |
| Sparse topK | 20 | query 含关键词多时可升到 40 |
| 融合 RRF k | 60 | 两路结果波动大时,优先保持 60 |
| Rerank 候选数 | 30 | 精度不够可升到 50,先盯延迟 |
| 最终返回 K | 5 | 结合 LLM 上下文窗口调整 |
3.1 一个容易忽略的调优顺序
先调召回覆盖,再调排序精度。
很多团队一上来就调 Reranker,结果其实是召回阶段已经漏掉了关键 chunk,后面怎么重排都救不回来。正确的调优顺序是:
- 先看召回覆盖率(Recall@20 或 Recall@50),确保相关的 chunk 都被召回了
- 再看排序精度(MRR、nDCG@10),优化 Top-K 的排序质量
- 最后看业务指标(人工标注准确率、用户追问率、答非所问率)
3.2 线上观测指标建议
至少盯这三类指标:
- 召回指标:Recall@20(Top-20 候选集中包含相关 chunk 的比例)
- 排序指标:MRR(Mean Reciprocal Rank,第一个相关结果的平均排名倒数)、nDCG@10(归一化折损累积增益�)
- 业务指标:人工标注准确率、用户追问率、答非所问率
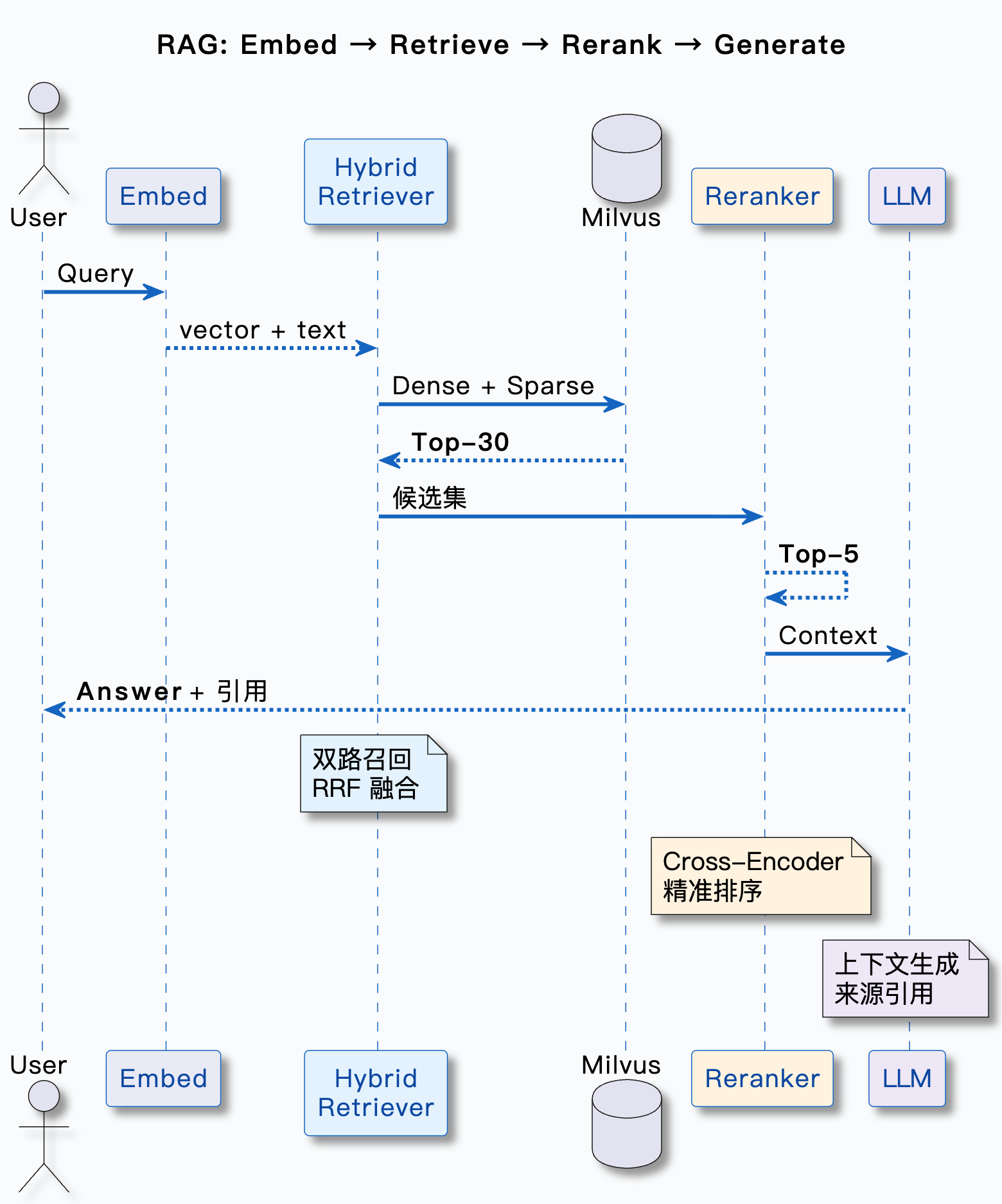
一张图看完整链路
把整个检索流程串起来,从用户提问到最终答案:
小结与下一篇预告
到这里,检索策略这块可以用一句话记住:
- 纯向量检索是基础能力,适合大多数自然语言 query
- 混合检索解决“语义强、关键词弱”的结构性短板,是生产环境的推荐方案
- 重排序决定最终给大模型的上下文质量上限,对答案准确率要求高的场景必备
如果你已经完成了分块、元数据、向量化、向量库、检索策略,下一步最值得讲的是生成阶段怎么控答案质量:
- 如何设计 Prompt 模板让模型少幻觉
- 如何做引用对齐与答案约束
- 如何把检索链路和生成链路连成完整可观测系统
下一篇咱们就进入这个环节:RAG 之生成策略与 Prompt 工程。