控制台功能的全面剖析
Ragent 控制台功能详解
这篇文档面向有开发基础但还没深入接触过 RAG 系统的同学。每个功能模块会先讲清楚为什么需要它,再讲它具体做了什么,最后结合电商智能客服的场景帮你建立感官。
Dashboard
Dashboard 是登录控制台后看到的第一个页面。整体分为左右两栏布局——左侧是指标卡片和趋势图表,右侧是 AI 性能面板和运营洞察。页面右上角有时间窗口切换和手动刷新按钮。
1. 页面布局总览
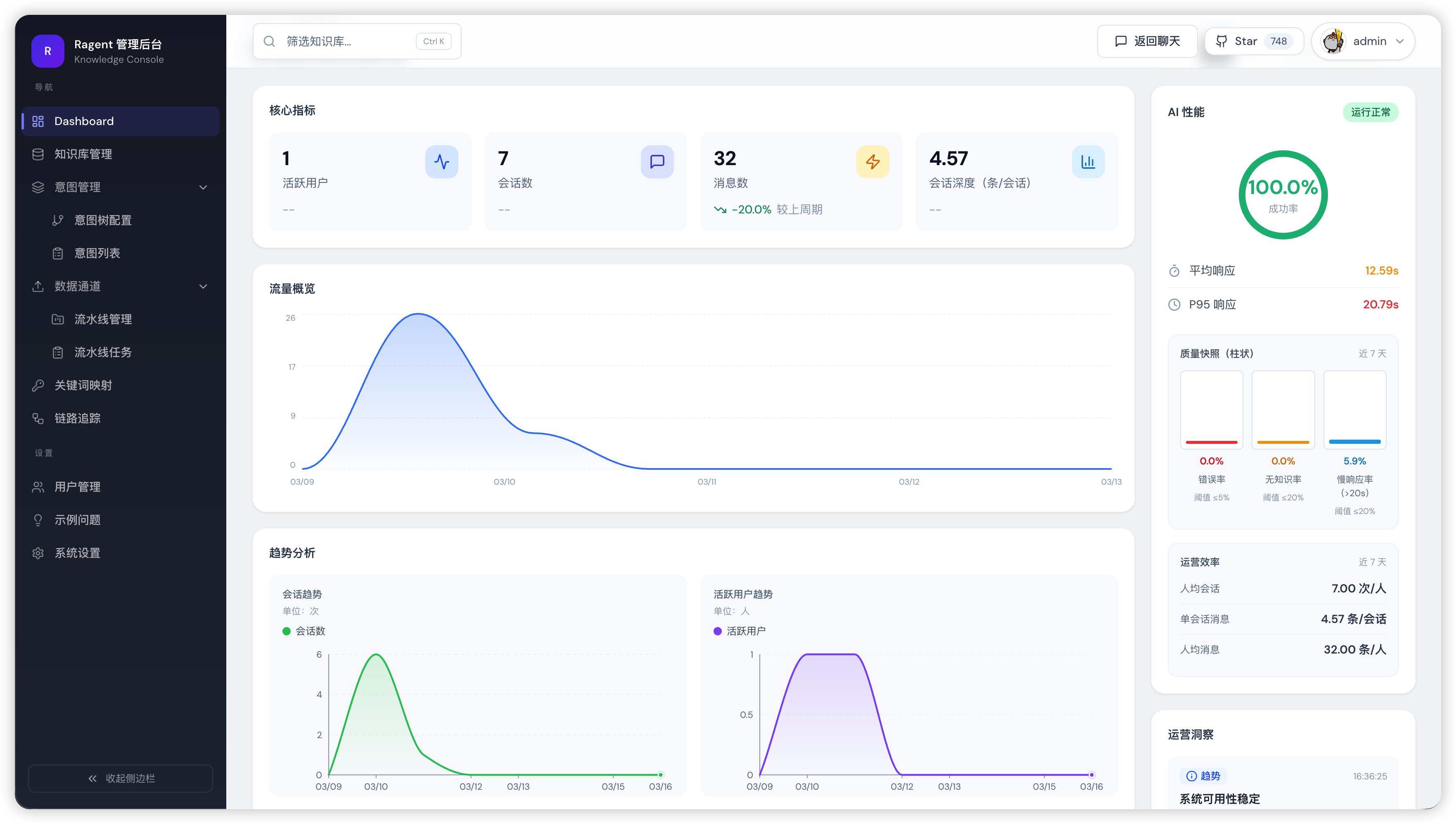
2. 核心指标卡片
页面顶部横排展示 4 个 KPI 卡片。每个卡片显示当前值和环比变化(delta 百分比),环比的对比基准是上一个等长的时间窗口。选了 24h 就和前一个 24 小时比,选了 7d 就和前 7 天比。
| 卡片 | 数据来源 | 读法 |
|---|---|---|
| 活跃用户 | 时间窗口内发送过消息的独立用户数 | 注册了但没说过话的不算,反映真实使用率 |
| 会话数 | 时间窗口内新建的对话数 | 就是有多少人来问过问题 |
| 消息�数 | 时间窗口内的消息总量(用户 + AI 都算) | 系统的实际负载量 |
| 会话深度(条/会话) | 消息数 ÷ 会话数 | 平均每轮对话要几条消息才结束,越高往往意味着一次答不到位 |
会话深度是前端拿消息数和会话数现算的,后端不直接返回这个指标。如果这个值突然飙高,值得留意——可能是知识库内容没覆盖到用户最近集中问的某类问题,导致用户反复追问。比如电商客服场景下,上了一批新品但忘了导入产品文档,用户问新品相关的问题就得不到好的回答,会话深度自然就上去了。
3. 趋势分析
核心指标下面是趋势图表区域,展示数据随时间的变化。一共 5 组趋势数据,分两种图表呈现:
流量概览——单独一张面积图,高度 300px,带渐变填充和交互式 Tooltip,展示消息数的变化曲线。这是整个页面视觉上最显眼的图表。
趋势网格——4 张折线图排成 2×2 的网格,每张 192px 高:
| 图表 | 数据 | 阈值线 |
|---|---|---|
| 会话趋势 | 会话数随时间变化 | 无 |
| 活跃用户趋势 | 活跃用户数随时间变化 | 无 |
| 响应时间趋势 | 平均响应时间随时间变化 | 良好 ≤10s,警告 >15s |
| 质量趋势 | 错误率 + 无知识率(两条线) | 错误警告 5%,无知识警告 30% |
页面头部有三个时间窗口按钮,切换后所有卡片和图表同步更新:
| 窗口 | 图表数��据粒度 | 环比基准 |
|---|---|---|
| 滚动 24h | 每小时一个点 | 前 24 小时 |
| 近 7 天 | 每天一个点 | 前 7 天 |
| 近 30 天 | 每天一个点 | 前 30 天 |
后端其实支持任意格式的时间窗口参数,比如
48h、14d,只是前端目前只放了这三个选项。
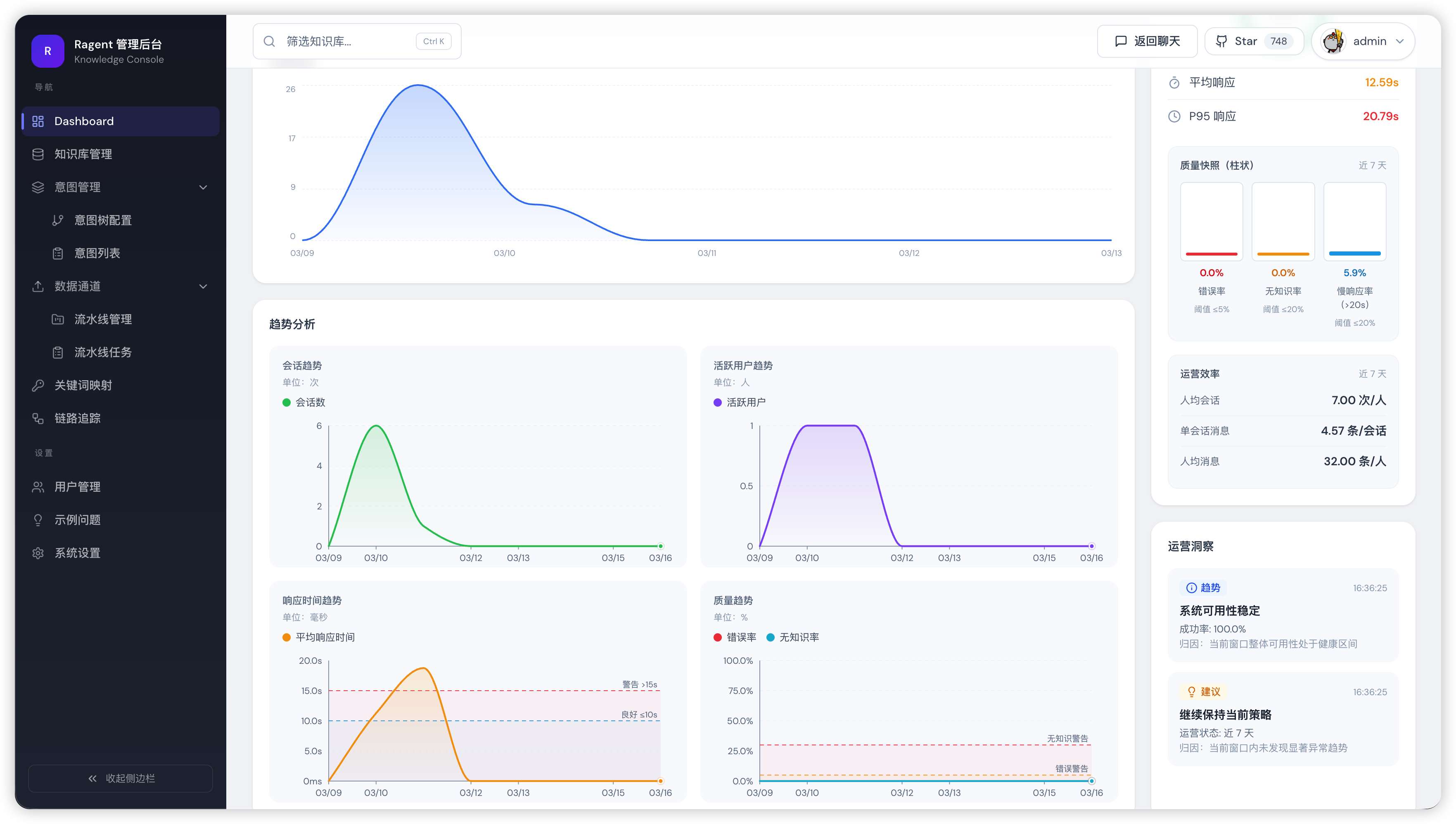
4. AI 性能面板
右侧边栏顶部是一个固定的性能卡片,信息密度比较高,从上到下分为四个区块:
4.1 成功率环形图
卡片最上方是一个环形进度条,正中间显示成功率数字。颜色编码很直观:
| 成功率范围 | 颜色 |
|---|---|
| ≥95% | 绿色 |
| ≥85% 且 < 95% | 橙色 |
| < 85% | 红色 |
旁边还有一个健康状态徽章,根据多个指标综合判定:
| 徽章文字 | 触发条件 |
|---|---|
| 运行正常(绿色) | 错误率 ≤5% 且 成功率 ≥95% 且 无知识率 ≤20% |
| 需要关注(橙色) | 无知识率 >20%(其他指标正常) |
| 风险偏高(红色) | 错误率 >5% 或 成功率 < 95% |
4.2 响应时间
两行指标,各自带颜色编码:
| 指标 | 含义 | 颜色阈值 |
|---|---|---|
| 平均响应 | 全部请求的平均耗时 | ≤10s 绿色,≤15s 橙色,>15s 红色 |
| P95 响应 | 第 95 百分位耗时 | 同上 |
P95 是什么意思?把所有请求按耗时从小到大排列,排在 95% 位置的那个值。它比平均值更能反映大部分用户的真实体验,因为平均值容易被少量极慢的请求拉高。
4.3 质量快照
三条水平进度条,直观展示质量维度的数据:
| 指标 | 含义 | 颜色阈值 |
|---|---|---|
| 错误率 | 处理过程中抛出异常的请求占比 | ≤1% 绿色,≤5% 橙色,>5% 红色 |
| 无知识率 | 回复未检索到相关文档的请求占比 | ≤10% 绿色,≤30% 橙色,>30% 红色 |
| 慢响应率 | 耗时超过 20 秒的请求占比 | 仅展示,无颜色阈值 |
4.4 无知识率是怎么算的
后端判定逻辑:如果 AI 回复的 content 精确等于 未检索到与问题相关的文档内容。 这个固定字符串,就算一次无知识。这意味着只有系统主动承认找不到答案的�情况才会计入,AI 自己编了一个不靠谱的答案不会被统计到这里。
4.5 运营效率
质量快照下面还有三个小指标:
| 指标 | 计算方式 | 单位 |
|---|---|---|
| 人均会话 | 会话数 ÷ 活跃用户 | 次/人 |
| 单会话消息 | 消息数 ÷ 会话数 | 条/会话 |
| 人均消息 | 消息数 ÷ 活跃用户 | 条/人 |
这三个指标帮你从用户维度理解使用模式——是少数重度用户在频繁使用,还是大量用户各问了一两个问题?
5. 运营洞察
右侧边栏底部最多显示 3 条自动生成的建议卡片,高度 360px 可滚动。这些卡片不是后端返回的,而是前端根据性能面板的数据自动推导的:
| 触发条件 | 卡片内容 |
|---|---|
| 错误率 >5% 或成功率 < 95% | 异常告警,提示关注系统稳定性 |
| 无知识率 >20% | 建议检查和补充知识库内容 |
| 平均响应 >15s | 建议优化模型配置或检索策略 |
| 以上都没触发 | 显示系统运行良好的占位卡片 |
如果同时触发了多条规则,最多展示 3 条。如果不足 3 条,会用一切正常的占位卡片补齐。
举个例子:你运营的电商客服机器人,某天无知识率从 8% 飙到 35%,洞察区域会自动弹出一张卡片提示你检查知识库。一查发现——昨天上架了一批新品,但产品说明文档还没导入。
6. 数据加载机制
页面打开后的数据加载分两步:
- 先加载核心指标(overview)和性能面板(performance)——这两个请求并行发出
- 再加载 5 条趋势数据——等第一步完成后,5 个趋势请求再并行发出
这样设计是因为趋势数据量比较大,拆成两步可以让用户先看到最关键的数字,趋势图随后填充进来。前端用了一个 requestIdRef 计数器来防止快速切换时间窗口时,旧请求的响应覆盖新数据。
手动点击刷新按钮会重新走一遍上面的完整流程。
知识库管理
RAG 系统的核心逻辑可以用一句话概括:把用户的问题,去一堆文档里找最相关的内容,拼到 Prompt 里让大模型回答。那堆文档存在哪?怎么组织?这就是知识库要解决的事情。
你可以把知识库理解成图书馆里的一个书架。一个书架放一类书,书架有自己的编号(Collection Name),书架上的每本书就是一篇文档,书里面一页一页的内容就是一个个分块(Chunk)。用户提问的时候,系统不是把整本书塞给大模型(那会超出 Token 限制),而是从书架上精准翻到最相关的几页。
1. 知识库的核心属性
| 字段 | 说明 | 备注 |
|---|---|---|
| 名称 | 知识库的展示名 | 可修改 |
| Embedding 模型 | 用哪个向量化模型 | 如果已有向量化文档,不可更改 |
| Collection Name | Milvus 中的集合名 | 创建后不可更改,仅支持小写字母和数字 |
Collection Name 不可变是因为它同时作为 Milvus 向量集合和 S3 存储桶的标识。改名意味着要迁移向量数据和文件存储,代价很大,所以系统直接锁死了这个字段。
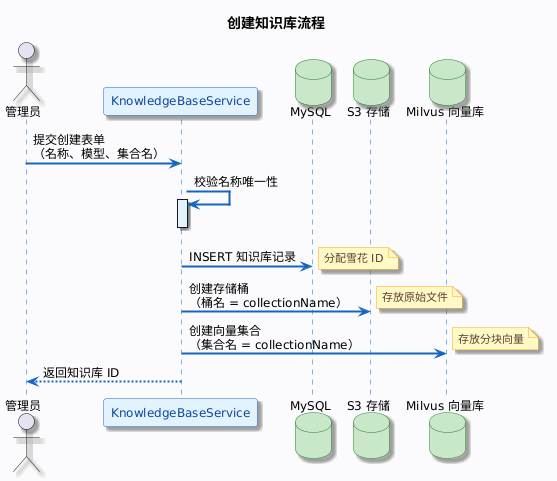
1.1 创建知识库的背后发生了什么
表面上你只是填了个表单点确认,后端其实做了三件事:
- 在 MySQL 中插入知识库记录
- 在 S3(或兼容存储)中创建一个同名的存储桶,用来放上传的文档原文件
- 在 Milvus 中创建一个向量集合,用来存文档分块的向量
1.2 删除保护
知识库下如果还有文档,删除操作会被拒绝。这是一个合理的防御——避免误删导致大量已向量化的文档数据丢失。你需要先清空文档,再删除知识库。
2. 文档管理
可以把知识库理解成架子,文档才是内容。这一层管理的是要把什么内容喂给系统,以及怎么处理它。
2.1 文档来源
| 来源类型 | 说明 | 适用场景 |
|---|---|---|
| 文件上传 | 直接上传本地文件 | 产品手册 PDF、售后政策 Word 文档 |
| URL 抓取 | 填入网页地址,系统自动拉取内容 | 在线帮助中心、API 文档 |
以电商客服为例:退换货政策写在公司内网的 Confluence 页面上,直接填 URL 让系统去抓取,比手动导出再上传方便得多。URL 来源还能配置定时调度——政策页面更新了,系统自动重新抓取。
2.2 文档处理模式
上传文档后,系统不会直接把原文塞进向量库。它需要先经过切块,把一篇长文档拆成若干小段,每段单独做向量化。这里有两种处理模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| 直接分块(chunk) | 内置分块策略,上传即可处理 | 简单场景,文档格式规范 |
| 数据通道(pipeline) | 走自定义的数据处理流水线 | 需要额外增强、富化的复杂场景 |
�直接分块的两种策略:
| 策略 | 参数 | 原理 |
|---|---|---|
| 固定大小(fixed_size) | chunkSize(默认 512),overlapSize(默认 128) | 按字符数切,每块之间重叠一段。简单粗暴但通用 |
| 结构感知(structure_aware) | targetChars(1400),maxChars(1800),minChars(600),overlapChars(0) | 识别文档结构(标题、段落),尽量在语义边界处切分 |
怎么选?如果你的文档是规整的 FAQ 列表(一问一答),固定大小就够了。如果是长篇产品使用手册、有多级标题和章节的,结构感知能切得更合理——不会把一个完整的操作步骤从中间劈开。
2.3 文档生命周期
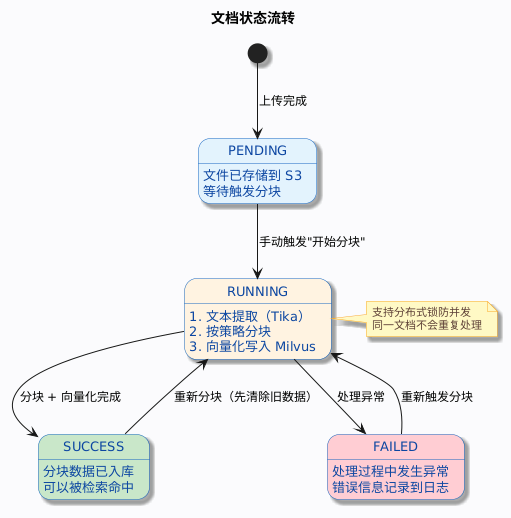
几个关键细节:
- 上传后文档状态是
PENDING,不会自动开始分块。你需要手动点击开始分块按钮触发处理。 - 重新分块时,系统会先删除该文档的所有旧分块(包括 Milvus 中的向量),然后重新处理。
- 分块过程使用 Redisson 分布式锁(5 秒等待,30 秒超时),防止重复触发。
- 每次分块会生成一条分块日志(Chunk Log),记录各阶段耗时:文本提取、分块、向量化、总耗时。
2.4 文档启用/禁用
文档支持启用和禁用切换。禁用一篇文档时,它下面所有分块的向量都会从 Milvus 中移除——也就是说,这篇文档的内容不再参与检索。重新启用时,向量会被重建。
电商场景:双 11 大促期间有特殊的退换货政策,大促结束后你不想删除这个文档(明年还要用),只需要禁用它,日常的退换货问题就不会命中大促政策了。
2.5 URL 文档的定时调度
如果文档来源是 URL,可以配置 Cron 表达式来定期重新抓取。系统会通过 ETag、Last-Modified 和内容哈希做变更检测,只在内容真正变化时才重新处理。
调度的最小间隔默认 60 秒,防止配置过于激进导致频繁请求。
3. 文档管理 - 分块管理
分块是 RAG 系统中真正被检索和送入大模型的最小单元。你可以把它理解为:知识库是书架,文档是书,分块就是书里面被高亮标记的一段段内容。用户提问时,系统从几万个分块里找出最相关的 5-10 个,拼接成 Prompt 的上下文。