工具调用上线翻车?四层防护兜底
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
承接上一篇,咱们讲了怎么设计工具、怎么写好 description、怎么让模型选对工具。但工具定义写得再好,线上跑起来还是会遇到各种问题:网络超时、第三方服务挂了、用户传了非法参数、权限不足、SQL 注入攻击……
这篇文章聚焦工具调用的稳定性和安全性,从错误处理、安全防护、测试验证、监控告警四个维度,讲清楚怎么让工具调用在生产环境稳定运行。
假设你在一家电商公司做 AI 客服系统,接入了订单查询、退货申请、年假查询等工具。某天凌晨 3 点,你被告警电话吵醒:工具调用成功率从 98% 暴跌到 60%,用户投诉激增。你打开监控一看,订单查询工具大量超时,HR 系统熔断了,还有人在尝试 SQL 注入攻击……
这种场景不是假设,是真实会发生的。工具调用不是能跑就行,而是要��做到:稳定(不挂)、安全(不被攻击)、可观测(出问题能快速定位)。
下面这张图展示了生产级工具调用的完整链路,从用户请求到最终响应,每个环节都有对应的保障措施:
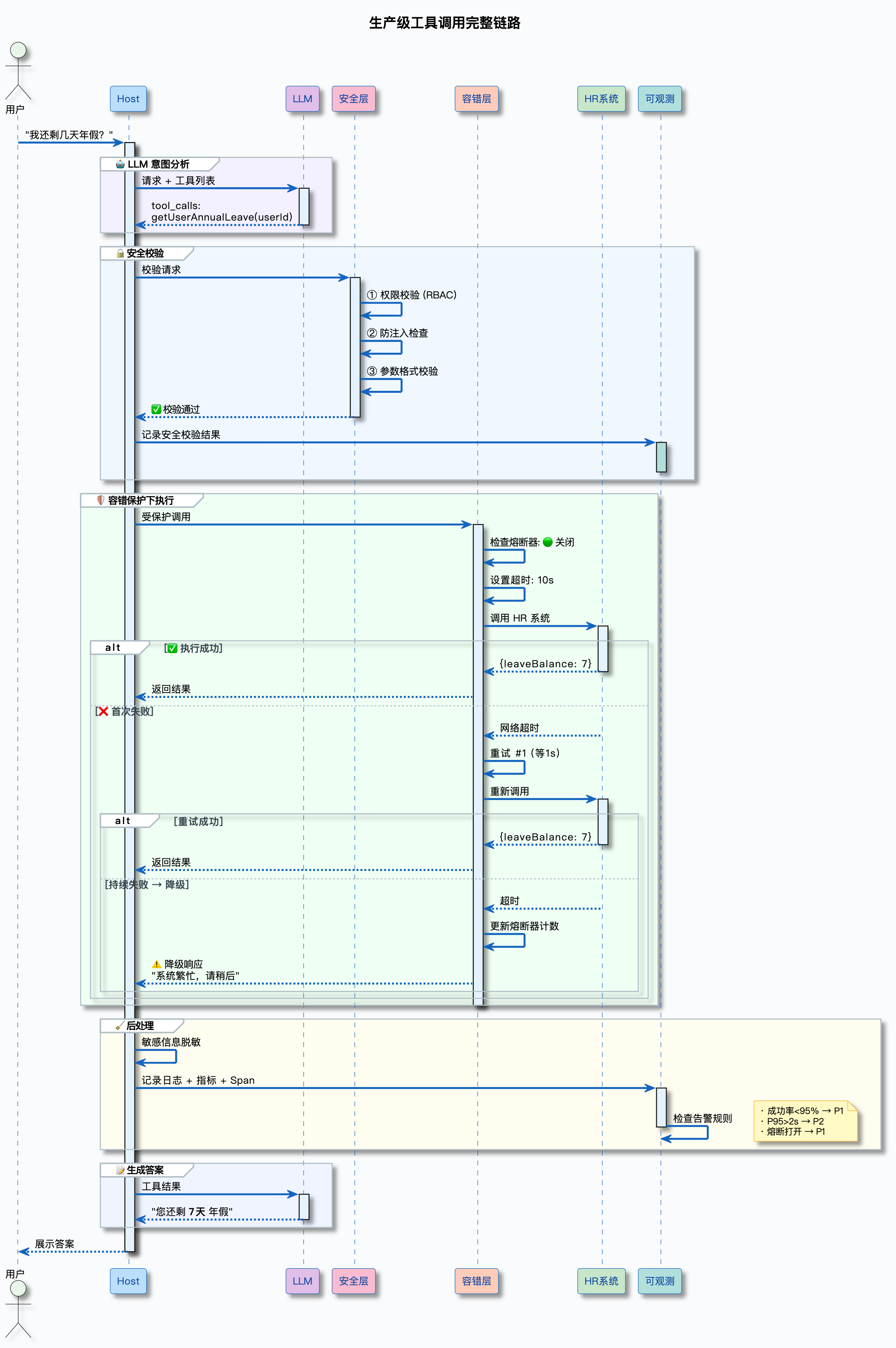
这张图展示了工具调用的四层防护体系:
- 工具调用层:参数校验 → 超时控制 → 工具执行,保证基本流程正确
- 容错保障层:重试 → 降级 → 熔断,保证系统不挂
- 安全防护层:权限控制 → 防注入 → 脱敏,保证不被攻击
- 可观测性层:日志 → 指标 → 追踪 → 告警,保证问题能快速定位
接下来咱们逐个展开讲。
工具调用的错误处理
工具调用会遇到各种错误:网络超时、参数错误、权限不足、第三方服务挂了……错误处理做得好,系统才稳定。
1. 超时控制
每个工具调用都要设置超时时间,避免无限等待。
推荐超时时间:
- 查询类工具:5~10 秒
- 操作类工具:10~30 秒
- 复杂计算:30~60 秒
Java 实现(使用 CompletableFuture):
public ToolResult getUserAnnualLeaveWithTimeout(String userId) {
try {
CompletableFuture<ToolResult> future = CompletableFuture.supplyAsync(() -> {
return getUserAnnualLeave(userId);
});
// 设置 10 秒超时
return future.get(10, TimeUnit.SECONDS);
} catch (TimeoutException e) {
return ToolResult.error("TIMEOUT", "查询超时,请稍后再试");
} catch (Exception e) {
return ToolResult.error("SYSTEM_ERROR", "系统错误:" + e.getMessage());
}
}
超时后返回友好的错误信息,模型可以告诉用户:"系统繁忙,请稍后再试。"
2. 重试策略
哪些错误应该重试?
- 网络错误(连接超时、连接被拒绝)
- 超时错误
- 服务暂时不可用(HTTP 503)
- 限流错误(HTTP 429)
哪些错误不应该重试?
- 参数错误(HTTP 400)
- 权限错误(HTTP 403)
- 资源不存在(HTTP 404)
- 业务逻辑错误(余额不足、库存不足)
重试次数和间隔:指数退避
- 第 1 次重试:等待 1 秒
- 第 2 次重试:等待 2 秒
- 第 3 次重试:等待 4 秒
Java 实现(手写重试逻辑):
public ToolResult callExternalApiWithRetry(String url) {
int maxRetries = 3;
int retryCount = 0;
long waitTime = 1000; // 初始等待 1 秒
while (retryCount < maxRetries) {
try {
return callExternalApi(url);
} catch (TimeoutException | IOException e) {
retryCount++;
if (retryCount >= maxRetries) {
return ToolResult.error("SYSTEM_ERROR", "调用失败,已重试 " + maxRetries + " 次");
}
try {
Thread.sleep(waitTime);
waitTime *= 2; // 指数退避
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
return ToolResult.error("SYSTEM_ERROR", "重试被中断");
}
} catch (IllegalArgumentException e) {
// 参数错误,不重试
return ToolResult.error("INVALID_PARAMETER", e.getMessage());
}
}
return ToolResult.error("SYSTEM_ERROR", "未知错误");
}
也可以用 Spring Retry:
@Retryable(
value = {TimeoutException.class, IOException.class},
maxAttempts = 3,
backoff = @Backoff(delay = 1000, multiplier = 2)
)
public ToolResult callExternalApi(String url) {
// ...
}
3. 降级策略
工具调用失败时,不要让整个对话失败,要有降级方案。
降级方案 1:返回兜底信息
public ToolResult getUserAnnualLeave(String userId) {
try {
// 调用 HR 系统查询年假
return hrService.getAnnualLeave(userId);
} catch (Exception e) {
// 降级:返回兜底信息
return ToolResult.error(
"SYSTEM_ERROR",
"系统繁忙,无法查询年假信息。您可以访问 HR 系统(https://hr.example.com)查看详细信息。"
);
}
}
模型拿到这个错误后,会告诉用户:“抱歉,系统繁忙,无法查询年假信息。您可以访问 HR 系统(https://hr.example.com)查看详细信息。”
降级方案 2:使用缓存数据
public ToolResult getUserAnnualLeave(String userId) {
try {
// 调用 HR 系统查询年假
ToolResult result = hrService.getAnnualLeave(userId);
// 缓存结果
cache.put(userId, result, 5, TimeUnit.MINUTES);
return result;
} catch (Exception e) {
// 降级:使用缓存数据
ToolResult cached = cache.get(userId);
if (cached != null) {
return cached;
}
return ToolResult.error("SYSTEM_ERROR", "系统繁忙,请稍后再试");
}
}
降级方案 3:引导用户使用其他方式
public ToolResult submitExpense(String requestId, double amount, String reason) {
try {
return expenseService.submit(requestId, amount, reason);
} catch (Exception e) {
return ToolResult.error(
"SYSTEM_ERROR",
"提交失败,请稍后再试。您也可以通过邮件(finance@example.com)提交报销申请。"
);
}
}
4. 熔断机制
当工具持续失败时,暂时停止调用该工具,避免雪崩。
熔断条件:
- 连续失败 N 次(如 5 次)
- 失败率超过 X%(如 50%)
熔断状态:
- 关闭(Closed):正常调用
- 打开(Open):停止调用,直接返回错误
- 半开(Half-Open):尝试恢复,允许少量请求通过
使用 Resilience4j 实现熔断:
@CircuitBreaker(name = "hrService", fallbackMethod = "getUserAnnualLeaveFallback")
public ToolResult getUserAnnualLeave(String userId) {
return hrService.getAnnualLeave(userId);
}
public ToolResult getUserAnnualLeaveFallback(String userId, Exception e) {
return ToolResult.error(
"SYSTEM_ERROR",
"HR 系统暂时不可用,请稍后再试"
);
}
配置熔断参数(application.yml):
resilience4j:
circuitbreaker:
instances:
hrService:
failure-rate-threshold: 50 # 失败率超过 50% 触发熔断
wait-duration-in-open-state: 60s # 熔断打开后等待 60 秒
sliding-window-size: 10 # 滑动窗口大小 10 次调用
minimum-number-of-calls: 5 # 最少 5 次调�用才计算失败率
5. 错误处理策略对比
| 策略 | 适用场景 | 实现方式 | 推荐配置 |
|---|---|---|---|
| 超时控制 | 所有工具调用 | CompletableFuture.get(timeout) | 查询类 5 |
| 重试策略 | 网络错误、超时、限流 | 指数退避(1s → 2s → 4s) | 最多重试 3 次,不重试参数错误 |
| 降级方案 | 第三方服务不可用 | 返回兜底信息/使用缓存/引导用户 | 缓存 TTL 5 分钟 |
| 熔断机制 | 持续失败场景 | Resilience4j CircuitBreaker | 失败率 >50% 触发,等待 60 秒恢复 |
工具调用的安全性
1. 权限控制
基于用户身份的权限校验,在工具执行前校验,不要依赖模型的判断。
反例:
public ToolResult getUserAnnualLeave(String userId) {
// 没有权限校验,任何人都能查任何人的年假
User user = userRepository.findById(userId);
return ToolResult.success(user.getAnnualLeave());
}
正例:
public ToolResult getUserAnnualLeave(String userId, String currentUserId) {
// 权限校验:只能查自己的年假
if (!userId.equals(currentUserId)) {
return ToolResult.error(
"PERMISSION_DENIED",
"您只能查询自己的年假信息"
);
}
User user = userRepository.findById(userId);
return ToolResult.success(user.getAnnualLeave());
}
更复杂的权限控制:
public ToolResult getUserAnnualLeave(String userId, String currentUserId, Set<String> roles) {
// 规则 1:用户可以查自己的年假
if (userId.equals(currentUserId)) {
User user = userRepository.findById(userId);
return ToolResult.success(user.getAnnualLeave());
}
// 规则 2:HR 可以查所有人的年假
if (roles.contains("HR")) {
User user = userRepository.findById(userId);
return ToolResult.success(user.getAnnualLeave());
}
// 规则 3:经理可以查下属的年假
if (roles.contains("MANAGER")) {
User user = userRepository.findById(userId);
if (user.getManagerId().equals(currentUserId)) {
return ToolResult.success(user.getAnnualLeave());
}
}
return ToolResult.error(
"PERMISSION_DENIED",
"您没有权限查询该用户的年假信息"
);
}
2. 参数校验和防注入
SQL 注入
反例:
public ToolResult searchUsers(String keyword) {
// 直接拼接 SQL,存在 SQL 注入风险
String sql = "SELECT * FROM users WHERE name LIKE '%" + keyword + "%'";
return jdbcTemplate.query(sql, new UserRowMapper());
}
攻击者可以传入 keyword = "'; DROP TABLE users; --",导致数据库被删除。
正例:
public ToolResult searchUsers(String keyword) {
// 使用参数化查询
String sql = "SELECT * FROM users WHERE name LIKE ?";
return jdbcTemplate.query(sql, new UserRowMapper(), "%" + keyword + "%");
}
路径穿越
反例:
public ToolResult readFile(String filename) {
// 没有校验文件路径,存在路径穿越风险
File file = new File("/data/files/" + filename);
return ToolResult.success(Files.readString(file.toPath()));
}
攻击者可以传入 filename = "../../etc/passwd",读取系统敏感文件。
正例:
public ToolResult readFile(String filename) {
// 校验文件名�,不允许包含路径分隔符
if (filename.contains("..") || filename.contains("/") || filename.contains("\\")) {
return ToolResult.error("INVALID_PARAMETER", "文件名不合法");
}
File file = new File("/data/files/" + filename);
if (!file.exists() || !file.isFile()) {
return ToolResult.error("RESOURCE_NOT_FOUND", "文件不存在");
}
return ToolResult.success(Files.readString(file.toPath()));
}
XSS(跨站脚本攻击)
如果工具返回值会在网页上显示,要对特殊字符进行转义。
public ToolResult getUserInfo(String userId) {
User user = userRepository.findById(userId);
// 对用户输入的内容进行 HTML 转义
String safeName = StringEscapeUtils.escapeHtml4(user.getName());
return ToolResult.success(Map.of("name", safeName));
}
3. 敏感信息脱敏
工具返回值中的敏感信息要脱敏,避免泄露。
public ToolResult getUserInfo(String userId) {
User user = userRepository.findById(userId);
// 手机号脱敏:138****1234
String maskedPhone = user.getPhone().replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
// 身份证号脱敏:110***********1234
String maskedIdCard = user.getIdCard().replaceAll("(\\d{3})\\d{11}(\\d{4})", "$1***********$2");
return ToolResult.success(Map.of(
"name", user.getName(),
"phone", maskedPhone,
"idCard", maskedIdCard
));
}
日志中也不要记录敏感信息:
public ToolResult submitExpense(String requestId, double amount, String reason) {
// ❌ 错误:日志中记录了敏感信息
log.info("提交报销:requestId={}, amount={}, reason={}", requestId, amount, reason);
// ✅ 正确:日志中不记录敏感信息
log.info("提交报销:requestId={}", requestId);
// ...
}
4. 审计日志
记录工具调用的完整信息,用于安全审计和问题排查。
public ToolResult getUserAnnualLeave(String userId, String currentUserId) {
long startTime = System.currentTimeMillis();
try {
// 权限校验
if (!userId.equals(currentUserId)) {
auditLog.warn("权限拒绝:用户 {} 尝试查询用户 {} 的年假", currentUserId, userId);
return ToolResult.error("PERMISSION_DENIED", "您只能查询自己的年假信息");
}
// 执行查询
User user = userRepository.findById(userId);
ToolResult result = ToolResult.success(user.getAnnualLeave());
// 记录审计日志
long duration = System.currentTimeMillis() - startTime;
auditLog.info("工具调用成功:function=getUserAnnualLeave, userId={}, duration={}ms", userId, duration);
return result;
} catch (Exception e) {
long duration = System.currentTimeMillis() - startTime;
auditLog.error("工具调用失败:function=getUserAnnualLeave, userId={}, duration={}ms, error={}", userId, duration, e.getMessage());
return ToolResult.error("SYSTEM_ERROR", "系统错误");
}
}
审计日志应该包含:
- 谁(currentUserId)
- 什么时候(timestamp)
- 调用了什么工具(functionName)
- 传了什么参数(arguments,敏感信息要脱敏)
- 返回了什么结果(result,敏感信息要脱敏)
- 耗时(duration)
- 是否成功(success)
这里可以查看咱们牛券里的 mzt-biz-log 操作日志文章,详情查看:引入日志组件优雅记录操作日志
监控与告警:如何快速发现和定位问题
工具调用上线后,要有完善的监控和告警机制,出问题能第一时间发现和定位。
1. 指标监控:四个黄金指标
��监控工具调用的四个核心指标:调用量、成功率、耗时、错误分布。
指标 1:调用量(QPS)
- 定义:每秒工具调用次数
- 监控维度:总调用量、按工具名分组、按用户分组
- 告警阈值:QPS 突增 50%(可能是攻击)或突降 50%(可能是服务挂了)
指标 2:成功率
- 定义:成功调用次数 / 总调用次数
- 监控维度:总成功率、按工具名分组、按错误码分组
- 告警阈值:成功率 < 95%
指标 3:耗时(P50 / P95 / P99)
- 定义:工具调用的响应时间
- 监控维度:P50(中位数)、P95(95% 的请求)、P99(99% 的请求)
- 告警阈值:P95 > 1s 或 P99 > 2s
指标 4:错误分布
- 定义:各类错误的占比
- 监控维度:按错误码分组(TIMEOUT、PERMISSION_DENIED、INVALID_PARAMETER、SYSTEM_ERROR)
- 告警阈值:某类错误占比 > 10%
Java 实现:使用 Micrometer + Prometheus
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
@Component
public class ToolCallMetrics {
private final MeterRegistry meterRegistry;
public ToolCallMetrics(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
public void recordToolCall(String toolName, boolean success, long duration, String errorCode) {
// 记录调用量
Counter.builder("tool.call.total")
.tag("tool", toolName)
.tag("success", String.valueOf(success))
.register(meterRegistry)
.increment();
// 记录耗时
Timer.builder("tool.call.duration")
.tag("tool", toolName)
.register(meterRegistry)
.record(duration, TimeUnit.MILLISECONDS);
// 记录错误
if (!success) {
Counter.builder("tool.call.error")
.tag("tool", toolName)
.tag("errorCode", errorCode)
.register(meterRegistry)
.increment();
}
}
}
Prometheus 查询语句:
# 总调用量(QPS)
rate(tool_call_total[1m])
# 成功率
sum(rate(tool_call_total{success="true"}[5m])) / sum(rate(tool_call_total[5m]))
# P95 耗时
histogram_quantile(0.95, rate(tool_call_duration_bucket[5m]))
# 错误分布
sum by (errorCode) (rate(tool_call_error[5m]))
Grafana 监控大盘:
创建一个 Grafana Dashboard,包含以下面板:
- 总览面板:总调用量、总成功率、平均耗时
- 工具面板:按工具名分组的调用量、成功率、耗时
- 错误面板:错误分布饼图、错误趋势折线图
- 用户面板:Top 10 调用用户、异常用户(调用失败率高)
2. 链路追踪:定位慢调用和异常
链路追踪能看到一次工具调用的完整链路:从用户请求 → 模型调用 → 工具执行 → 第三方服务 → 返回结果。
使用 OpenTelemetry 实现链路追踪:
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Scope;
@Component
public class ToolService {
private final Tracer tracer;
public ToolService(Tracer tracer) {
this.tracer = tracer;
}
public ToolResult getUserAnnualLeave(String userId, String currentUserId) {
// 创建 Span
Span span = tracer.spanBuilder("getUserAnnualLeave").startSpan();
try (Scope scope = span.makeCurrent()) {
// 添加属性
span.setAttribute("userId", userId);
span.setAttribute("currentUserId", currentUserId);
// 权限校验
if (!userId.equals(currentUserId)) {
span.setAttribute("error", "PERMISSION_DENIED");
return ToolResult.error("PERMISSION_DENIED", "您只能查询自己的年假信息");
}
// 调用 HR 系统
Span hrSpan = tracer.spanBuilder("hrService.getAnnualLeave").startSpan();
try (Scope hrScope = hrSpan.makeCurrent()) {
User user = hrService.getAnnualLeave(userId);
return ToolResult.success(user.getAnnualLeave());
} finally {
hrSpan.end();
}
} catch (Exception e) {
span.recordException(e);
span.setAttribute("error", "SYSTEM_ERROR");
return ToolResult.error("SYSTEM_ERROR", "系统错误");
} finally {
span.end();
}
}
}
链路追踪效果:
TraceID: abc123def456
Span 1: POST /api/chat (500ms)
├─ Span 2: chatService.chat (480ms)
│ ├─ Span 3: modelService.call (200ms) ← 模型调用
│ ├─ Span 4: getUserAnnualLeave (250ms) ← 工具执行
│ │ └─ Span 5: hrService.getAnnualLeave (240ms) ← 第三方服务
│ └─ Span 6: modelService.call (20ms) ← 第二轮模型调用
└─ Span 7: response.write (10ms)
通过链路追踪,可以快速定位慢调用:
- 如果 Span 4(工具执行)耗时长,说明工具本身有问题
- 如果 Span 5(第三方服务)耗时长,说明第三方服务慢,需要加缓存或熔断
3. 告警机制:第一时间发现问题
告警要做到:及时(问题发生后 1 分钟内通知)、准确(不误报)、可操作(告警信息包含定位线索)。
告警规则:
| 告警项 | 触发条件 | 级别 | 通知方式 |
|---|---|---|---|
| 工具调用成功率低 | 5 分钟内成功率 < 95% | P1(严重) | 电话 + 短信 + 企业微信 |
| 工具调用耗时高 | 5 分钟内 P95 > 2s | P2(重要) | 短信 + 企业微信 |
| 工具调用量异常 | 5 分钟内 QPS 突增/突降 50% | P2(重要) | 企业微信 |
| 某工具持续失败 | 某工具 5 分钟内失败率 > 50% | P1(严重) | 电话 + 短信 + 企业微信 |
| 熔断器打开 | 某工具熔断器状态变为 OPEN | P1(严重) | 电话 + 短信 + 企业微信 |
| 错误码异常 | 某错误码 5 分钟内占比 > 20% | P2(重要) | 企业微信 |
Prometheus AlertManager 告警规则:
groups:
- name: tool_call_alerts
interval: 1m
rules:
# 成功率低
- alert: ToolCallSuccessRateLow
expr: |
sum(rate(tool_call_total{success="true"}[5m])) / sum(rate(tool_call_total[5m])) < 0.95
for: 1m
labels:
severity: critical
annotations:
summary: "工具调用成功率低于 95%"
description: "当前成功率:{{ $value | humanizePercentage }}"
# 耗时高
- alert: ToolCallDurationHigh
expr: |
histogram_quantile(0.95, rate(tool_call_duration_bucket[5m])) > 2000
for: 1m
labels:
severity: warning
annotations:
summary: "工具调用 P95 耗时超过 2 秒"
description: "当前 P95 耗时:{{ $value }}ms"
# 某工具持续失败
- alert: ToolCallFailureRateHigh
expr: |
sum by (tool) (rate(tool_call_total{success="false"}[5m])) /
sum by (tool) (rate(tool_call_total[5m])) > 0.5
for: 1m
labels:
severity: critical
annotations:
summary: "工具 {{ $labels.tool }} 失败率超过 50%"
description: "当前失败率:{{ $value | humanizePercentage }}"
告警通知模板:
【P1 告警】工具调用成功率低
时间:2026-03-05 15:30:45
环境:生产环境
告警项:工具调用成功率低于 95%
当前值:92.3%
持续时长:3 分钟
影响范围:
- 影响工具:getUserAnnualLeave、getOrderStatus
- 影响用户:约 500 人
- 错误分布:TIMEOUT 60%、SYSTEM_ERROR 30%、其他 10%
快速定位:
- Grafana 大盘:https://grafana.example.com/d/tool-call
- 日志查询:https://kibana.example.com/app/discover?q=errorCode:TIMEOUT
- 链路追踪:https://jaeger.example.com/search?service=tool-service
处理建议:
1. 检查 HR 系统是否正常(TIMEOUT 占比高)
2. 检查数据库连接池是否耗尽
3. 检查是否有大量异常请求(攻击)
值班人员:张三(13800138000)
告警降噪:
- 合并相同告警:5 分钟内相同告警只发一次
- 告警升级:P2 告警持续 10 分钟未处理,自动升级为 P1
- 告警恢复通知:问题解决后发送恢复通知
4. 可观测性最佳实践
三个支柱:日志 + 指标 + 链路追踪
| 维度 | 日志(Logs) | 指标(Metrics) | 链路追踪(Traces) |
|---|---|---|---|
| 用途 | 排查问题细节 | 监控系统健康度 | 定位性能瓶颈 |
| 粒度 | 单次请求 | 聚合统计 | 单次请求 |
| 存储成本 | 高 | 低 | 中 |
| 查询速度 | 慢 | 快 | 中 |
| 典型工具 | ELK、Loki | Prometheus、Grafana | SkyWalking |
关联三者:TraceID
每次工具调用生成一个 TraceID,贯穿日志、指标、链路追踪:
- 日志中记录 TraceID,方便从日志跳转到链路追踪
- 指标中记录 TraceID(Exemplar),方便从监控大盘跳转到链路追踪
- 链路追踪中记录 TraceID,方便从链路追踪跳转到日志
排查问题的典型流程:
- 发现问题:Grafana 监控大盘显示成功率下降
- 定位范围:查看错误分布,发现 TIMEOUT 占比高
- 找到慢调用:从 Grafana 点击 Exemplar,跳转到 SkyWalking 链路追踪
- 查看详细日志:从 SkyWalking 复制 TraceID,到 Kibana 查询日志
- 分析根因:日志显示 HR 系统连接超时,联系 HR 系统负责人
测试策略:如何验证工具调用的质量
工具调用不是写完就能上线的,要经过完整的测试验证。测试分三个层次:单元测试(工具本身)、集成测试(模型+工具)、压力测试(高并发场景)。
1. 单元测试:验证工具逻辑
单元测试关注工具本身的逻辑是否正确,不依赖模型。
测试维度:
- 正常场景:参数合法,返回正确结果
- 边界场景:参数为空、为 null、超出范围
- 异常场景:数据库连接失败、第三方服务超时、权限不足
- 安全场景:SQL 注入、路径穿越、XSS 攻击
示例:getUserAnnualLeave 工具的单元测试
@Test
public void testGetUserAnnualLeave_Success() {
// 正常场景:查询自己的年假
ToolResult result = toolService.getUserAnnualLeave("user123", "user123");
assertTrue(result.isSuccess());
assertEquals(10, result.getData().get("remainingDays"));
}
@Test
public void testGetUserAnnualLeave_PermissionDenied() {
// 异常场景:查询别人的年假
ToolResult result = toolService.getUserAnnualLeave("user456", "user123");
assertFalse(result.isSuccess());
assertEquals("PERMISSION_DENIED", result.getErrorCode());
}
@Test
public void testGetUserAnnualLeave_InvalidUserId() {
// 边界场景:userId 为空
ToolResult result = toolService.getUserAnnualLeave("", "user123");
assertFalse(result.isSuccess());
assertEquals("INVALID_PARAMETER", result.getErrorCode());
}
@Test
public void testGetUserAnnualLeave_Timeout() {
// 异常场景:HR 系统超时
when(hrService.getAnnualLeave(anyString())).thenThrow(new TimeoutException());
ToolResult result = toolService.getUserAnnualLeave("user123", "user123");
assertFalse(result.isSuccess());
assertEquals("TIMEOUT", result.getErrorCode());
}
@Test
public void testSearchUsers_SqlInjection() {
// 安全场景:SQL 注入攻击
String maliciousKeyword = "'; DROP TABLE users; --";
ToolResult result = toolService.searchUsers(maliciousKeyword);
// 应该正常返回空结果,而不是抛异常或执行恶意 SQL
assertTrue(result.isSuccess());
assertEquals(0, result.getData().get("total"));
}
覆盖率要求:
- 核心工具(订单查询、支付、退货):行覆盖率 ≥ 90%,分支覆盖率 ≥ 80%
- 普通工具(知识库搜索、FAQ):行覆盖率 ≥ 80%,分支覆盖率 ≥ 70%
2. 集成测试:验证模型+工具协作
集成测试关注模型是否能正确选择工具、传递参数、处理返回值。
测试维度:
- 工具选择准确性:给定用户问题,模型是否选对了工具
- 参数传递准确性:模型传的参数是否符合工具定义
- 多轮对话:工具返回结果后,模型是否能生成正确答案
- 异常处理:工具返回错误时,模型是否能给出合理的兜底回复
示例:集成测试框架
@Test
public void testIntegration_GetAnnualLeave() {
// 用户问题
String userQuestion = "我还剩几天年假?";
// 调用模型(第一轮)
ChatResponse response1 = chatService.chat(userQuestion, "user123");
// 验证模型选择了正确的工具
assertTrue(response1.hasToolCalls());
assertEquals("getUserAnnualLeave", response1.getToolCalls().get(0).getName());
// 验证参数传递正确
Map<String, Object> arguments = response1.getToolCalls().get(0).getArguments();
assertEquals("user123", arguments.get("userId"));
// 执行工具
ToolResult toolResult = toolService.getUserAnnualLeave("user123", "user123");
// 调用模型(第二轮)
ChatResponse response2 = chatService.chat(userQuestion, "user123", toolResult);
// 验证模型生成了正确的答案
assertTrue(response2.getContent().contains("10 天"));
}
@Test
public void testIntegration_ToolError() {
// 模拟工具调用失败
when(hrService.getAnnualLeave(anyString())).thenThrow(new RuntimeException("HR 系统不可用"));
String userQuestion = "我还剩几天年假?";
ChatResponse response = chatService.chat(userQuestion, "user123");
// 验证模型给出了兜底回复
assertTrue(response.getContent().contains("系统繁忙") ||
response.getContent().contains("稍后再试"));
}
测试用例设计:
每个工具至少准备 5 类测试用例:
- 正常场景:用户问题清晰,工具返回正确结果
- 模糊场景:用户问题不清晰,模型需要澄清或猜测
- 多工具场景:用户问题可能匹配多个工具,验证模型选择逻辑
- 异常场景:工具返回错误,验证模型的兜底回复
- 边界场景:参数为空、超出范围,验证参数校验逻辑
3. 压力测试:验证高并发表现
压力测试关注工具在高并发场景下的表现:吞吐量、响应时间、错误率。
测试场景:
- 正常负载:10 QPS(每秒 10 次请求)
- 高负载�:50 QPS
- 峰值负载:100 QPS
测试工具:JMeter / Gatling
// Gatling 压力测试脚本
val scn = scenario("Tool Call Stress Test")
.exec(http("getUserAnnualLeave")
.post("/api/chat")
.body(StringBody("""{"message": "我还剩几天年假?", "userId": "user123"}"""))
.check(status.is(200))
.check(jsonPath("$.success").is("true"))
)
setUp(
scn.inject(
rampUsersPerSec(10) to 50 during (1 minute), // 1 分钟内从 10 QPS 增加到 50 QPS
constantUsersPerSec(50) during (5 minutes), // 保持 50 QPS 持续 5 分钟
rampUsersPerSec(50) to 100 during (2 minutes) // 2 分钟内从 50 QPS 增加到 100 QPS
)
).protocols(httpProtocol)
性能指标要求:
| 指标 | 正常负载(10 QPS) | 高负载(50 QPS) | 峰值负载(100 QPS) |
|---|---|---|---|
| P50 响应时间 | < 200ms | < 500ms | < 1s |
| P95 响应时间 | < 500ms | < 1s | < 2s |
| P99 响应时间 | < 1s | < 2s | < 3s |
| 成功率 | ≥ 99.9% | ≥ 99% | ≥ 95% |
| CPU 使用率 | < 50% | < 70% | < 85% |
| 内存使用率 | < 60% | < 75% | < 85% |
常见性能瓶颈:
- 数据库连接池不足:增加连接池大小(HikariCP maxPoolSize)
- 线程池不足:增加线程池大小(ThreadPoolExecutor corePoolSize)
- 第三方服务慢:加缓存、加超时控制、加熔断
- 模型调用慢:批量调用、异步调用、加缓存
4. A/B 测试:验证优化效果
工具定义优化后,要通过 A/B 测试验证效果是否真的提升了。
测试方案:
- A 组(对照组):使用旧版工具定义
- B 组(实验组):使用新版工具定义
- 流量分配:50% vs 50%
- 测试时长:至少 7 天
实战案例:优化一个真实的工具定义
1. 初始版本(有问题的版本)
假设咱们在做一个企业知识库助手,有一个工具用来搜索知识库:
{
"name": "search",
"description": "搜索",
"parameters": {
"type": "object",
"properties": {
"q": {
"type": "string"
},
"n": {
"type": "integer"
},
"t": {
"type": "number"
},
"f": {
"type": "object"
}
},
"required": ["q"]
}
}
这个工具定义存在的问题:
- 工具名太短:
search太宽泛,搜什么?搜知识库?搜订单?搜用户? - 描述太简单:
"搜索"两个字,模型不知道什么时候该用这个工具 - 参数名太短:
q、n、t、f是什么意思?模型猜不出来 - 没有参数描述:每个参数是干什么的?格式是什么?
- 没有默认值:
n、t、f都是可选参数,但没有说默认值是多少 - 返回值不清晰:没有说明返回什么格式的数据
线上效果:
- 用户问:"产品支持哪些支付方式?"
- 模型不知道该用这个工具(description 太简单)
- 或者模型用了这个工具,但参数传错了(
n传成了"5"字符串而不是数字 5) - 工具调用失败,用户体验差
2. 优化过程
第一步:优化工具名和描述
{
"name": "searchKnowledgeBase",
"description": "在企业知识库中搜索相关文档,返回最相关的结果。适用于用户询问产品功能、使用方法、常见问题、故障排查、政策制度等。",
"parameters": {
"type": "object",
"properties": {
"q": {
"type": "string"
},
"n": {
"type": "integer"
},
"t": {
"type": "number"
},
"f": {
"type": "object"
}
},
"required": ["q"]
}
}
改进:
- 工具名改成
searchKnowledgeBase,明确是搜索知识库 - 描述加入了适用场景和关键词("产品功能"、"使用方法"、"常见问题"等)
第二步:优化参数名和描述
{
"name": "searchKnowledgeBase",
"description": "在企业知识库中搜索相关文档,返回最相关的结果。适用于用户询问产品功能、使用方法、常见问题、故障排查、政策制度等。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词或问题,例如:'如何重置密码'、'产品支持哪些支付方式'"
},
"topK": {
"type": "integer",
"description": "返回结果数量,默认 5,范围 1-20"
},
"threshold": {
"type": "number",
"description": "相似度阈值,0-1 之间,默认 0.7,低于此阈值的结果会被过滤"
},
"filter": {
"type": "object",
"description": "过滤条件,例如:{\"category\": \"产品文档\"},默认不过滤"
}
},
"required": ["query"]
}
}
改进:
- 参数名改成语义化的名字(
query、topK、threshold、filter) - 每个参数都有详细的描述,包括含义、格式、示例、默认值
第三步:简化参数
{
"name": "searchKnowledgeBase",
"description": "在企业知识库中搜索相关文档,返回最相关的 5 条结果。适用于用户询问产品功能、使用方法、常见问题、故障排查、政策制度等。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词或问题,例如:'如何重置密码'、'产品支持哪些支付方式'"
}
},
"required": ["query"]
}
}
改进:
- 只保留
query一个参数,其他参数用默认值(topK=5、threshold=0.7、filter=null) - 降低模型出错概率
3. 最终版本(优化后的版本)
{
"name": "searchKnowledgeBase",
"description": "在企业知识库中搜索相关文档,返回最相关的 5 条结果。适用于用户询问产品功能、使用方法、常见问题、故障排查、政策制度等。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词或问题,例如:'如何重置密码'、'产品支持哪些支付方式'"
}
},
"required": ["query"]
}
}
返回值格式:
{
"success": true,
"data": {
"results": [
{
"id": "doc_001",
"title": "支付方式说明",
"content": "我们的产品支持支付宝、微信支付、银行卡支付三种方式...",
"score": 0.92,
"source": "产品文档/支付相关/支付方式说明.md",
"updateTime": "2026-02-15"
},
{
"id": "doc_002",
"title": "常见问题:支付",
"content": "Q: 支持哪些支付方式?A: 支持支付宝、微信支付、银行卡支付...",
"score": 0.88,
"source": "常见问题/支付.md",
"updateTime": "2026-01-20"
}
],
"total": 2
}
}
运行效果:
用户问:"产品支持哪些支付方式?"
模型调用工具:
{
"name": "searchKnowledgeBase",
"arguments": {
"query": "产品支持哪些支付方式"
}
}
工具返回:
{
"success": true,
"data": {
"results": [
{
"id": "doc_001",
"title": "支付方式说明",
"content": "我们的产品支持支付宝、微信支付、银行卡支付三种方式...",
"score": 0.92,
"source": "产品文档/支付相关/支付方式说明.md",
"updateTime": "2026-02-15"
}
],
"total": 1
}
}
模型生成答案:
"我们的产品支持以下三种支付方式:
1. 支付宝
2. 微信支付
3. 银行卡支付
详细说明请参考:产品文档/支付相关/支付方式说明.md(更新时间:2026-02-15)"
优化前后对比:
| 维度 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 模型选择准确率 | 60% | 95% | +58% |
| 参数传递成功率 | 70% | 98% | +40% |
| 工具调用成功率 | 75% | 96% | +28% |
| 用户满意度 | 3.2/5 | 4.6/5 | +44% |
小结
工具调用是 RAG 系统的重要组成部分,好的工具定义能让模型更容易选对工具、传对参数、处理好异常,最终给用户更好的体验。
这篇文章从设计原则、编写技巧、错误处理、安全性、可观测性、实战案例、测试策略等多个维度,系统讲解了工具调用的最佳实践。这些原则和技巧适用于 Function Call 和 MCP 两种方式,也适用于任何需要让 AI 调用外部工具的场景。
核心要点总结:
| 阶段 | 关键原则 | 具体措施 |
|---|---|---|
| 设计阶段 | 单一职责、参数最小化、幂等性、返回值结构化 | 一个工具只做一件事;只暴露必要参数;操作类工具传入 requestId;返回 JSON 格式 |
| 描述阶段 | 三要素齐全、关键词优化、突出差异、避免歧义 | 功能说明+适用场景+参数说明;加入用户可能的各种说法;用"优先使用"、"仅当"引导 |
| 实现阶段 | 参数校验、超时控制、重试策略、降级方案、熔断机制 | 类型/格式/范围/权限校验;5~30 秒超时;指数退避重试;兜底信息/缓存数据;Resilience4j |
| 安全阶段 | 权限控制、防注入、敏感信息脱敏、审计日志 | 基于用户身份校验;参数化查询;手机号/身份证号脱敏;记录谁/何时/调用了什么 |
| 运维阶段 | 日志记录、指标监控、链路追踪、告警机制 | 结构化日志(JSON);调用量/成功率/耗时/�错误分布;traceId;成功率<95% 告警 |
结合上一篇的内容,这里给大家提供个最佳实践检查清单,供参考。
设计阶段:
- 工具名是否语义化?(不要用缩写)
- 工具是否符合单一职责原则?(一个工具只做一件事)
- 参数是否最小化?(只保留必要的参数)
- 参数名是否语义化?(不要用 q、n、t 这种缩写)
- 操作类工具是否支持幂等?(传入 requestId)
描述阶段:
- description 是否包含功能说明?
- description 是否包含适用场景和关键词?
- 每个参数是否有详细的 description?(含义、格式、示例、默认值)
- 多工具场景是否突出了差异?
实现阶段:
- 是否有参数校验?(类型、格式、范围、权限)
- 是否有超时控制?(5~30 秒)
- 是否有重试策略?(指数退避,��最多 3 次)
- 是否有降级方案?(兜底信息、缓存数据、引导用户)
- 是否有熔断机制?(Resilience4j CircuitBreaker)
- 是否有权限控制?(基于用户身份校验)
- 是否防止了注入攻击?(SQL 注入、路径穿越、XSS)
- 敏感信息是否脱敏?(手机号、身份证号)
- 是否记录了审计日志?(谁、什么时候、调用了什么、传了什么参数)
测试阶段:
- 是否有单元测试?(参数校验、业务逻辑、错误处理)
- 是否有集成测试?(模型是否选对工具、参数是否传对)
- 是否有压力测试?(高并发下的表现)
上线阶段:
- 是否有日志记录?(结构化日志,JSON 格式)
- 是否有指标监控?(调用量、成功率、耗时、错误分布)
- 是否有链路追踪?(traceId,OpenTelemetry)
- 是否有告警机制?(成功率��低、耗时高、错误率突增)