Agent 架构全景:大脑、工具、记忆与规划
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们把 RAG 和 Agent 的边界讲清楚了:Agent 比 RAG 多了一个想-做-看的循环,能自主推理、调用工具、根据结果决定下一步。篇末还甩了一段 agentRun 的 while 循环骨架,让你先有个直觉。
但你盯着那段代码看,多半会冒出一连串问号:
- 那个负责想的
llmClient.chat,凭什么知道下一步该干啥? toolRegistry又�是个什么东西,工具是怎么挂上去的?trace这个 List 一路往里塞东西,它就是所谓的记忆吗?- 说好的自主规划,到底藏在哪一行?
这一篇咱们不急着写新代码,先把镜头拉远,给你一张 Agent 的架构全景图。把 LLM 大脑、工具手脚、记忆、规划这四个要素分别讲清楚,再看它们怎么协作运转起来。这张全景图装进脑子里,后面一篇篇拆解的时候,你才知道自己正站在哪一块拼图上。
为什么要先看架构
1. 别一上来就抠代码
很多人学 Agent,是直接抱着一份开源框架的源码硬啃,结果越看越懵——又是 Planner,又是 Executor,又是 Memory,又是 Toolkit,类名一大堆,绕来绕去不知道主线在哪。
问题不在代码,在于没先建立全局观。Agent 说到底就四个部件,每个部件干一件事,它们之间怎么传数据也很清晰。先把这四块和它们的协作关系印在脑子里,再去看任何框架、任何源码,你都能迅速对号入座:这个类是大脑,那个类是工具注册表,这串 List 是记忆。
2. 用一个比喻先立住四要素
打个比方。把 Agent 想�象成比特严选新来的一个客服专员,他要独立接待用户、把事办成,靠的是什么?
- 他得有个脑子会思考——用户这句话什么意思、接下来该先干啥。这就是 LLM 大脑。
- 他得有手脚能干活——查订单系统、翻物流、发起退款,光想不动手没用。这就是工具。
- 他得记得住——用户上一句说了啥、刚才查订单查出来什么,不能转头就忘。这就是记忆。
- 他得会盘算——一个模糊的诉求进来,先干哪步后干哪步,他心里得有个谱。这就是规划。
四样缺一不可。没有大脑,只会蛮干;没有工具,光说不练;没有记忆,转头就忘;没有规划,东一榔头西一棒。一个靠谱的 Agent,是这四样配齐、还能顺畅配合的整体。
下面这张图,就是把这四个要素和它们的关系摆在一起:
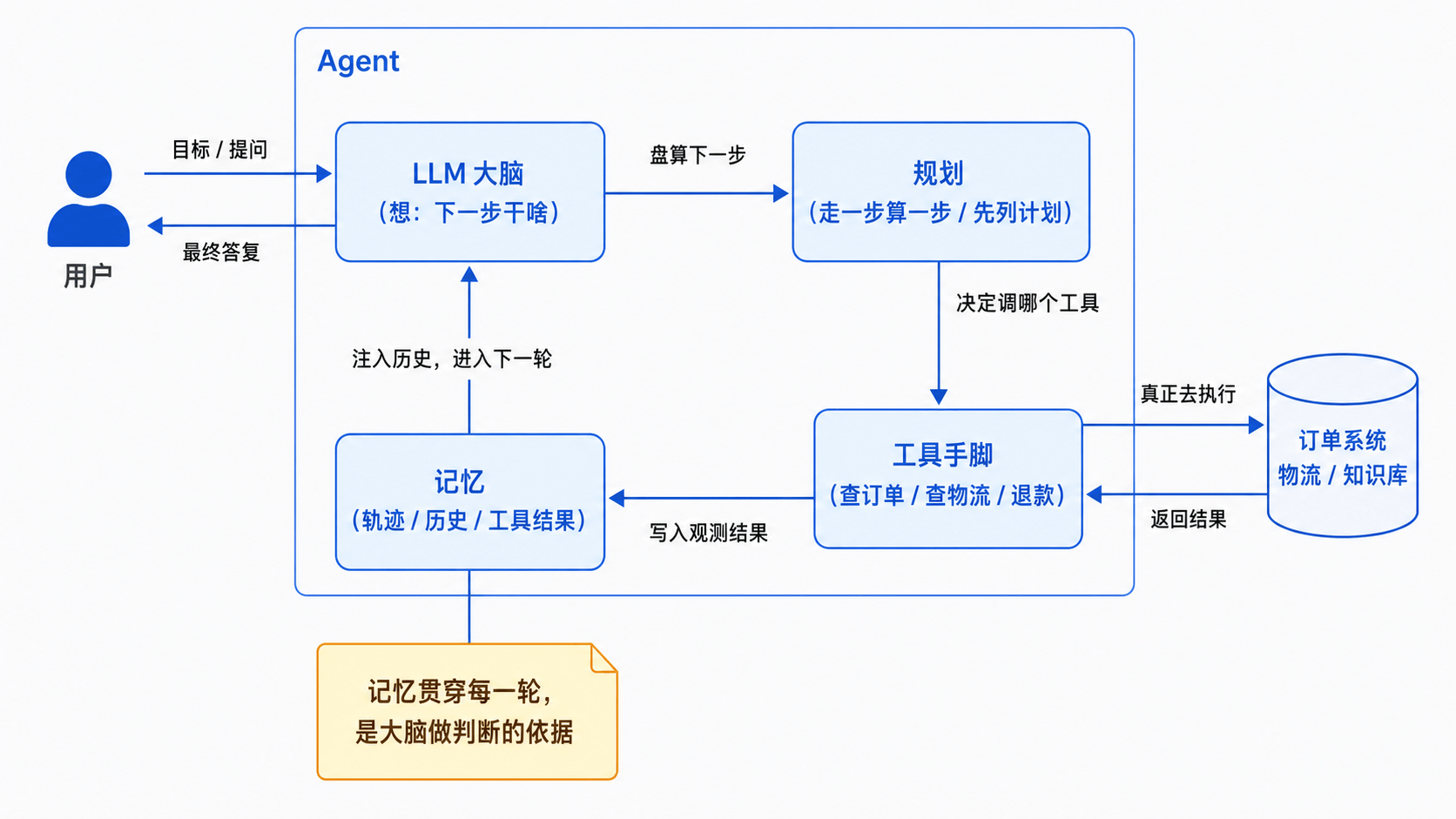
注意这张图的核心是中间那个回路:大脑想 → 规划定方向 → 工具执行 → 结果写进记忆 → 记忆再喂回大脑。这个回路转一圈又一圈,直到大脑认为目标达成,才把最终答复吐给用户。上一篇说的循环,本质就是这四个部件协作运转。
接下来咱们一个一个拆。
大脑:LLM 负责想
1. 大脑在循环里干的唯一一件事
先说最核心的部件——LLM 大脑。
它的职责其实特别单一:基于当前已知的一切,决定下一步干什么。注意,是决定下一步,不是把整件事干完。每转到一轮,大脑被唤醒一次,它看一眼记忆里的轨迹,然后输出一个判断——要么说“我还得查个订单”,要么说“信息够了,可以给最终答复了”。
这就是它和 RAG 里那次模型调用最大的不同。RAG 里模型被调用一次,任务是根据这些资料组织一段话;Agent 里模型被反复调用,每次的任务是根据现在的局面,下一步该怎么走。同样是调 LLM,前者在生成内容,后者在做决策。
2. 大脑对应的代码
回到上一篇那段骨架,大脑就是这一行:
// 大脑:基于当前轨迹,想出下一步动作
String thought = llmClient.chat(buildReActPrompt(trace));
llmClient.chat 还是你在 RAG 系列里写过的那个纯 Java + OkHttp 的模型调用,没有任何变化。变化的是喂给它的东西——buildReActPrompt(trace) 把整条轨迹包装成一段提示词,逼着模型按先想、再决定动作的格式输出。这段提示词怎么设计,是后面《ReAct 提示词设计》那篇的重头戏,这里你只要记住:大脑这个部件,物理上就是一次 LLM 调用,只是被放进了循环里反复触发。顺便提一嘴:大脑的一次输出,其实同时包含 Thought(推理过程)和 Action(要执行的动作),变量名叫 thought 只取了一半含义,具体的输出格式放到 ReAct 提示词那篇再细说。
3. 大脑的边界
| 维度 | 说明 |
|---|---|
| 擅长 | 理解模糊意图、做下一步决策、把工具结果总结成人话 |
| 不擅长 | 精确计算、访问实时数据、记住超长历史(受上下文窗口限制) |
| 工程注意 | 每轮都是一次 API 调用,循环越长 Token 和时延越高 |
| 关键认知 | 大脑只负责想和决定,真正干活要靠工具 |
最后这一条得划重点:大脑自己是不会查订单、不会发退款的。它顶多在脑子里说一句“我要查订单 88231”,至于这句话怎么变成一次真实的系统调用——那是工具的事。
手脚:工具让 Agent 能动
1. 没有工具,Agent 光说不练假把式
承接上面那句。大脑再聪明,它的输出也只是文本。它说“我要查订单 88231”,这句话本身查不出任何东西。要让这句话产生实际效果,必须有人接住它、去真正调订单系统、再把结果拿回来。这个接住并执行的部件,就是工具。
工具是 Agent 真正能干活的地方。在比特严选里,典型的工具有这么几个:
- 查订单状态(输入订单号,返回下单时间、商品、当前状态)
- 查物流轨迹(输入运单号,返回最新位置)
- 发起退款 / 换货(输入订单号和原因,触发售后流程)
- 检索知识库(输入问题,返回相关的保修、退货政策——没错,你的 RAG 在这里变成了一个工具)
每个工具本质上就是一个 Java 方法:有明确的入参、明确的出参,干一件确定的事。大脑负责决定调哪个、传什么参;工具负责按指令执行。
2. 工具对应的代码
骨架里的工具部分是这两行:
// 手脚:解析出要调哪个工具,执行它,拿回观测结果
Action action = parseAction(thought);
String observation = toolRegistry.execute(action);
parseAction 把大脑那段文本里的“我要��查订单 88231”解析成结构化的 Action(调哪个工具、参数是啥);toolRegistry 是所有工具的注册表,根据 Action 找到对应的方法并执行,返回一个 observation(观测结果)。
注册表本身很朴素,你可以先简单理解成一个 Map:
// 工具注册表的雏形:名字 -> 真正干活的方法
public class ToolRegistry {
private final Map<String, Tool> tools = new HashMap<>();
public void register(Tool tool) {
tools.put(tool.name(), tool);
}
public String execute(Action action) {
Tool tool = tools.get(action.toolName());
if (tool == null) {
return "错误:没有名为 " + action.toolName() + " 的工具";
}
return tool.invoke(action.input()); // 真正调订单系统就发生在这里
}
}
你可以先把 Tool 和 Action 想成这样:
// 一个工具:有名字,能执行
interface Tool { String name(); String invoke(String input); }
// 一个动作:调哪个工具,传什么参数
record Action(String toolName, String input) {}
工具怎么定义、怎么把入参出参描述给大脑听,是《给 Agent 装上工具》那篇的内容。这里抓住一点就够:工具是大脑意图的执行末端,是 Agent 唯一能对真实世界产生影响的部件。
3. 工具能力的取舍
| 维度 | 说明 |
|---|---|
| 价值 | 让 Agent 突破纯文本,能查实时数据、能触发真实操作 |
| 复用 | RAG 系列写的检索、Function Call、MCP(Model Context Protocol,模型上下文协议)都能直接封成工具 |
| 风险 | 退款、改单这类有副作用的工具,调错了是真出事,要加确认与权限 |
| 工程注意 | 工具的描述写得越清楚,大脑越不容易调错 |
记忆:让 Agent 记得住
1. 没有记忆,循环转不起来
接着看第三个部件——记忆。
为什么循环必须要有记忆?想想看:大脑每一轮都是一次独立的 LLM 调用,模型本身是无状态的,它不会自动记得上一轮想了啥、查到了啥。如果每轮都只把用户最初那句话喂给它,那它永远在原��地打转,第二轮还会重复第一轮的动作。
记忆就是用来打破这个困境的。它把走过的每一步——大脑的每一次思考、每一次工具调用的结果——都记下来,下一轮再把这整条轨迹喂回给大脑。这样大脑才知道“订单我已经查过了,是上周三下的单,那下一步该算保修期了”。
所以记忆不是个可有可无的组件,它是循环能不断推进、不原地踏步的前提。
2. 记忆对应的代码
骨架里那个一路往里塞东西的 trace,就是最原始的记忆:
List<String> trace = new ArrayList<>(); // 这就是记忆
trace.add("用户目标:" + userGoal);
// ...每一轮:
trace.add(thought); // 记下这轮怎么想的
trace.add("Observation:" + observation); // 记下工具返回了啥
一个 List<String> 当然简陋,但它已经抓住了记忆的本质:把轨迹累积下来,再注入到下一轮的提示词里。buildReActPrompt(trace) 那一步,干的就是把整条轨迹拼进提示词的活。
不过这里藏着一个一眼能看穿的问题:历史记录越积越长,迟早会撑爆模型的上下文窗口,Token 成本也跟着飙。所以真实的记忆模块不会这么裸奔——它要区分短期记忆和长期记忆,要在轨迹过长时做压缩和摘要。这些是第三部分《记忆与上下文》专门要解决的,这里先认识到记忆本质上就是累积的轨迹这个内核。
3. 短期与长期记忆
| 类型 | 存什么 | 生命周期 | 比特严选里的例子 |
|---|---|---|---|
| 短期记忆 | 当前任务的轨迹、工具结果 | 一次任务内有效 | 这通会话里查到的订单号、诊断走到第几步 |
| 长期记忆 | 跨会话的用户偏好、历史 | 长期持久化 | 这个用户偏爱安卓、家里已有一台比特音箱 |
短期记忆是循环转起来的刚需,长期记忆则让 Agent 越用越懂你。本系列先把短期记忆讲透,长期记忆点到为止。
规划:决定往哪走
1. 规划到底藏在哪一行
最后一个要素,也是最容易让人犯迷糊的——规划。
上一篇有读者就问:说好的自主规划,代码里怎么没看见一份计划?
答案是:在 ReAct 这条主线里,规划没有单独成块,它摊在大脑每一轮思考里头。也就是前面那行 String thought = llmClient.chat(buildReActPrompt(trace)) 里的事。模型每转一轮,基于当前轨迹盘算下一步该干啥,做完看了结果再盘算下一步——走一步算一步,而不是一上来先把 1234 步全定好。
所以在最小的 ReAct 实现里,规划和大脑是融在一起的:大脑每次思考,既是推理也是规划。这也是为什么前面那张全景图里,我把规划画在大脑和工具之间——它是大脑思考的产物,决定了这一轮去碰哪个工具。
2. 两种规划风格的对比
但走一步算一步不是唯一的规划方式。规划这件事,业界大体有两条路:
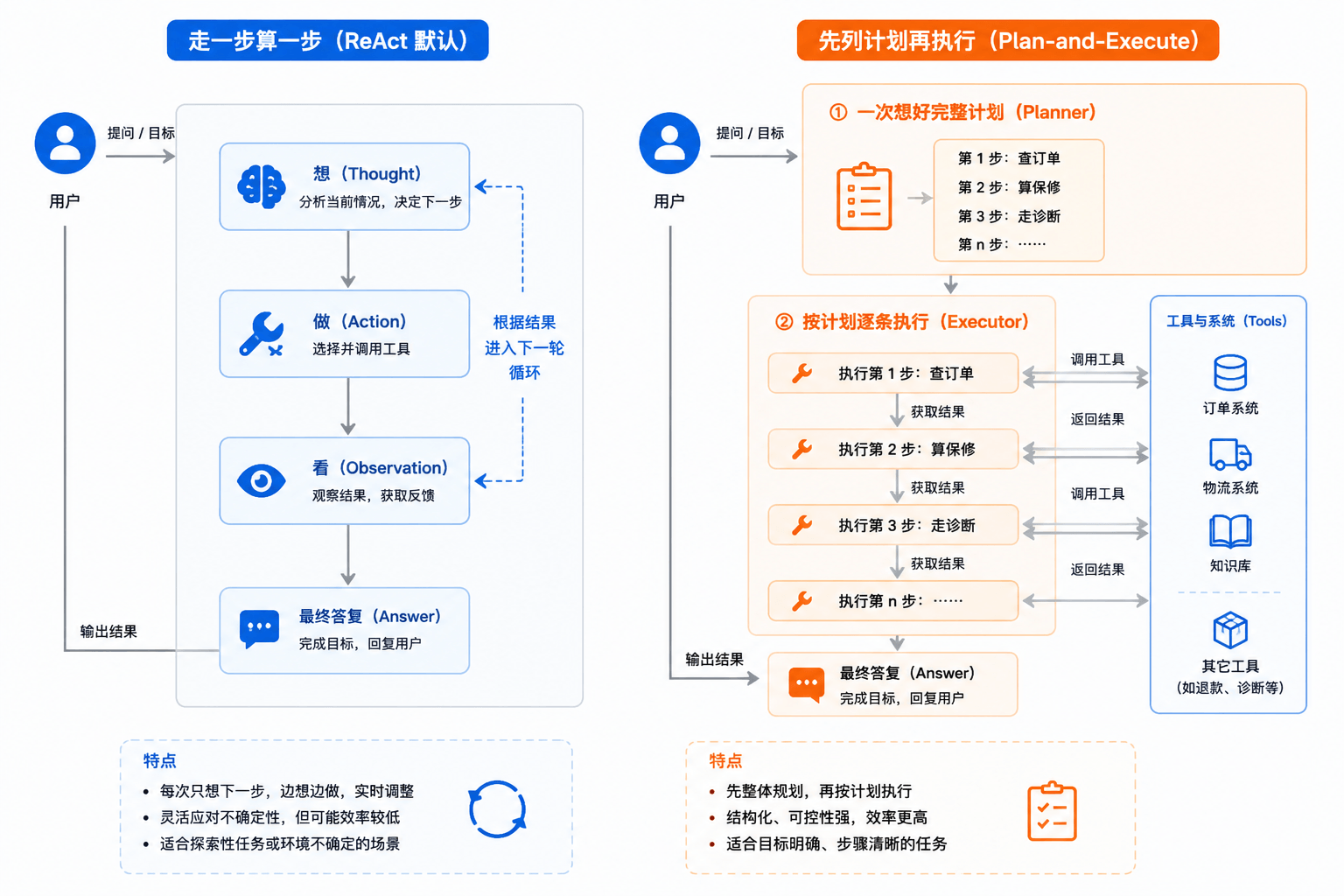
左边是 ReAct 的默认风格,规划隐含在每一轮里,灵活��、好实现,适合走向不确定的任务;右边是 Plan-and-Execute,一上来先让大脑生成一份完整计划,再逐条执行,步骤清晰、可控,适合流程相对固定的任务。
本系列以 ReAct 为主线,所以前期你看到的规划都是走一步算一步这种隐式风格。那种先生成完整计划再执行的显式规划,是第四部分《Plan-and-Execute 模式》要专门展开的。现在你只要知道:规划是一个独立的要素,但在最小 ReAct 里它融合在大脑的每轮思考中。
3. 两种规划风格的取舍
| 维度 | 走一步算一步(ReAct) | 先列计划再执行(Plan-and-Execute) |
|---|---|---|
| 灵活性 | 高,能随结果随时调整方向 | 低,计划定了再改成本高 |
| 可控性 | 低,走向不完全可预测 | 高,步骤一目了然 |
| 适合场景 | 故障诊断这类走向不定的任务 | 流程固定的批量任务 |
| 实现难度 | 低,循环里顺手就做了 | 中,要额外管理计划状态 |
四要素如何转一圈
讲完四个部件,咱们把它们串起来,看一次完整的循环到底怎么串联。还是用扫地机退货那个老例子:用户说“上周买的扫地机不回充了,修不好我想退”。
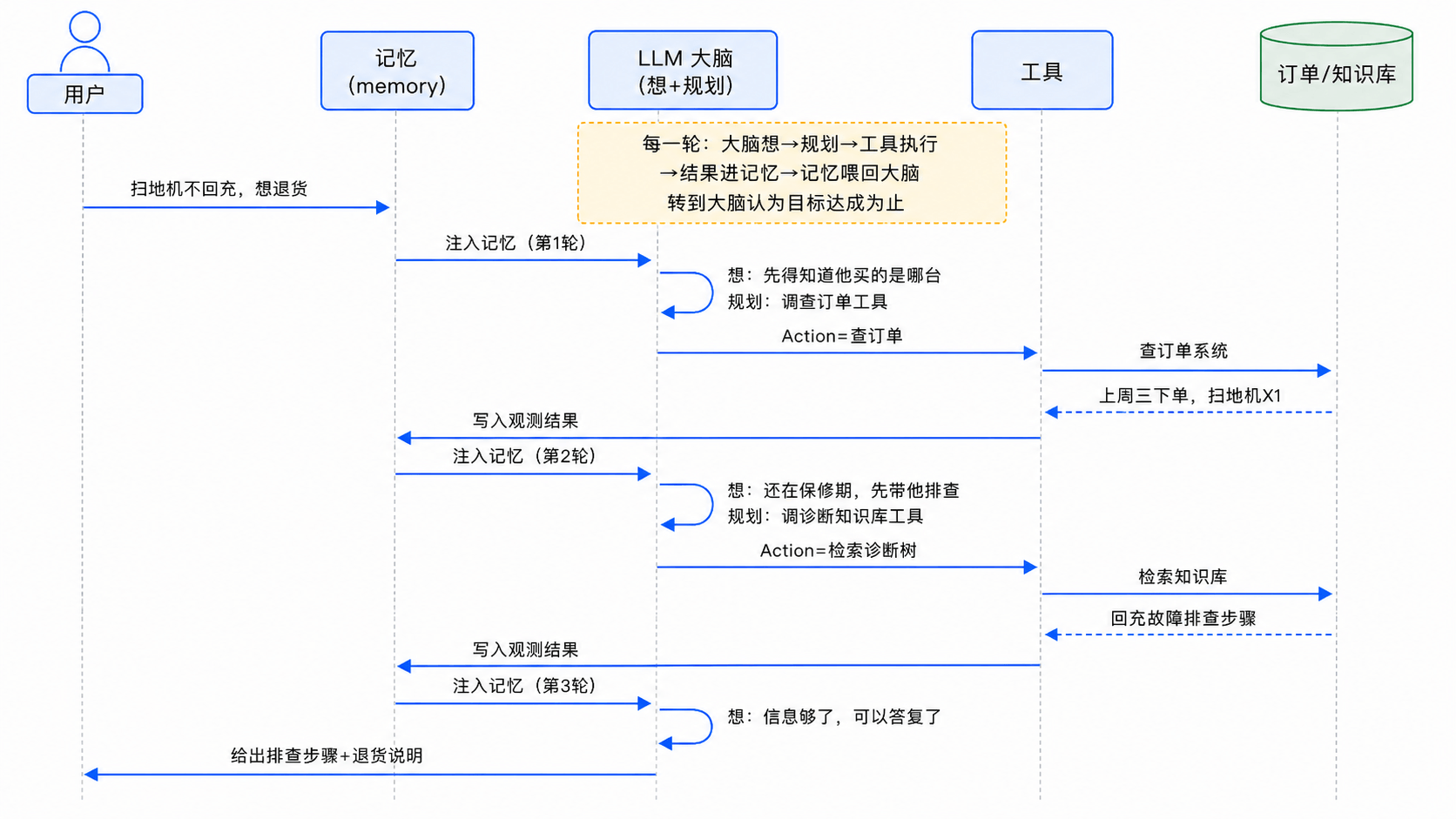
顺着这张时序图再回看一遍四要素的分工,就特别清楚了:
- 记忆像一条贯穿始终的总线,每轮都把最新轨迹喂给大脑,又把工具结果收回来。
- 大脑每轮被唤醒一次,负责思考和规划两件事,决定这轮碰哪个工具。
- 工具接住大脑的决定,去真实系统里执行,把观测结果交还给记忆。
- 规划没有独立的泳道,因为它就发生在大脑的每一次思考里。
这四样协作运转,就是上一篇说的那个想-做-看的循环的内部构造。你再回头看 agentRun 那段 while,每一行都能对号入座了:llmClient.chat 是大脑,toolRegistry.execute 是工具,trace 是记忆,而规划,就藏在 thought 里。
文末总结
这一篇咱们把镜头拉远,给 Agent 拍了张全景图,立住了四个要素:
- LLM 大脑:每轮被唤醒一次,只负责想和决定下一步,物理上就是一次 LLM 调用。
- 工具手脚:大脑意图的执行末端,是 Agent 唯一能对真实世界产生影响的部件,RAG 在这里被封装成 Agent 的一个工具。
- 记忆:逐轮累积的历史记录,是循环能不断推进、不原地踏步的前提。
- 规划:在最小 ReAct 里融合在大脑的每轮思考中,走一步算一步;后面还有先列计划再执行的另一条路。
一句话收尾:Agent = 一个会想的大脑 + 一双能动的手脚 + 一份记得住的记忆 + 一套盘算下一步的规划,四者在循环里协作运转。
把这张全景图记牢,后面每拆一个部件,你都知道自己在补哪一块拼图,不会迷路。
下一篇,咱们正式画出比特严选智能体的蓝图——它要解决哪些任务、第一版做成什么样,画完就从第二部分开始,真刀真枪手写 ReAct 循环。
我们下一篇见。