Ollama安装与模型调用实战
概念讲完了,这篇动手
上一篇把 Ollama 的架构、API、环境变量、硬件调度这些概念全部拆开讲了一遍。这一篇只做一件事:装 Ollama,拉模型,改 Ragent 配置,让整条 RAG 链路跑在本地。
读完本篇之后的状态是:Ragent 的 Chat 和 Embedding 都打到 localhost:11434,断网也能问答,在活动监视器里能看到 Ollama 进程在吃显存。全程不写一行 Java 代码——Ragent 的 provider 可插拔架构帮你扛了,你只需要改两行 YAML。
装 Ollama:三平台快速起步
1. macOS
两种方式选一种:
Homebrew 安装:
brew install ollama
官网安装:
去 ollama.com 下载 macOS 安装包(dmg),双击安装。
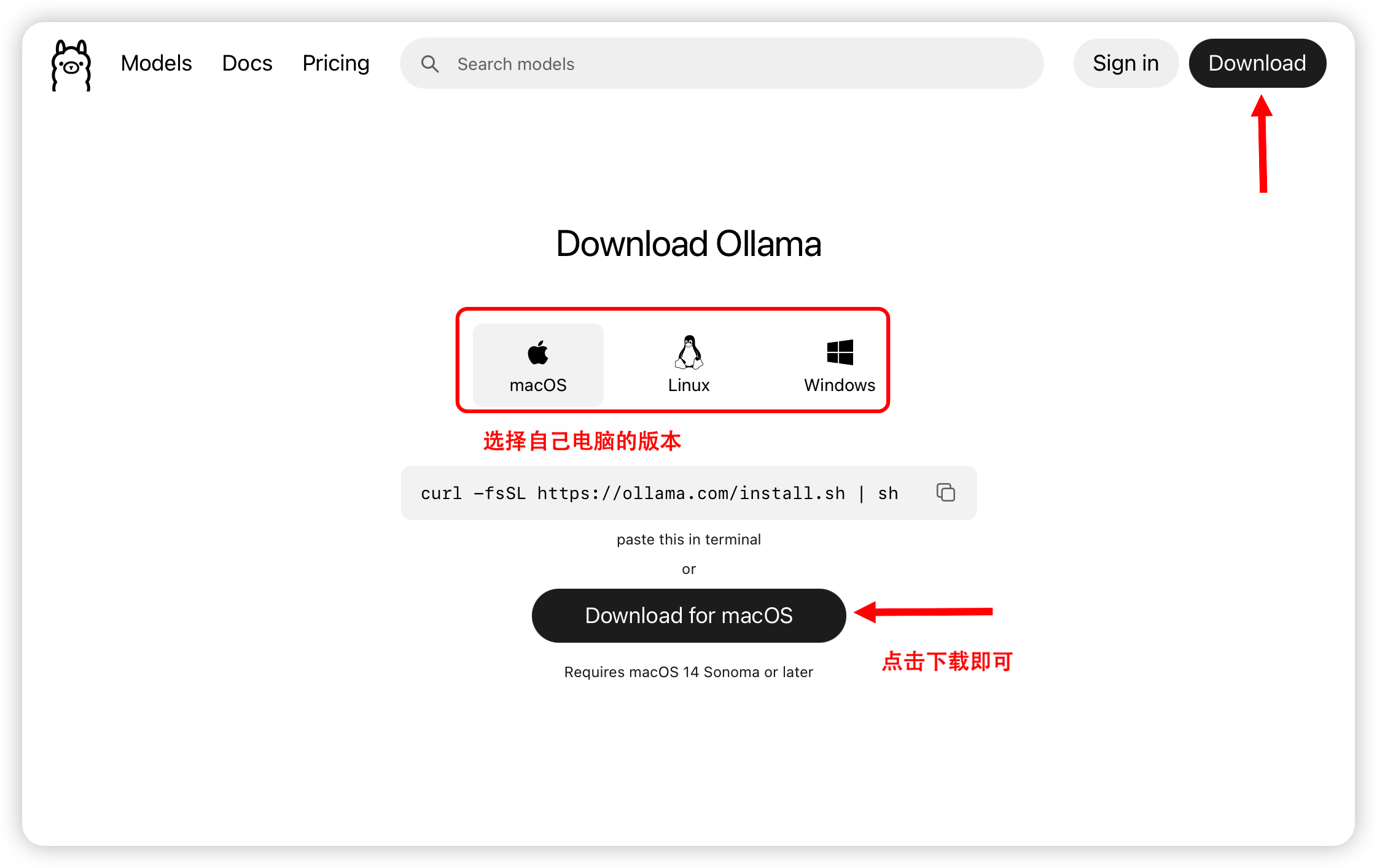
装完之后,Ollama 桌面应用会自动启动,状态栏会出现一个羊驼图标,ollama serve 已经在后台跑了。
2. Windows
同上,官网下载安装包双击安装就行。装完 Ollama 会以后台服务形式运行,后续命令在 PowerShell 里都能用。
3. Linux
官方提供了一键安装脚本:
curl -fsSL https://ollama.com/install.sh | sh
这个脚本会做三件事:下载 Ollama 二进制文件、创建 ollama 系统用户、自动注册 systemd 服务并启动。
装完用 systemctl 查看状态:
sudo systemctl status ollama
看到 active (running) 就说明服务已经在跑了。
环境变量怎么改?
Linux 上 Ollama 作为 systemd 服务运行,环境变量不能直接 export,要通过 systemctl edit 来覆盖:
sudo systemctl edit ollama
在打开的编辑器里添加:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
保存后重启服务:
sudo systemctl daemon-reload
sudo systemctl restart ollama
上面这个例子把监听地址从默认的 127.0.0.1 改成了 0.0.0.0,允许局域网内其他机器访问。这是一个很典型的场景:团队里一台 GPU 服务器装了 Ollama,其他同事的开发机通过内网 IP ��调用。
4. 验证装好了
三个平台通用的验证步骤:
# 看版本
ollama --version
应该输出类似 ollama version 0.18.x 的版本号。
# 看服务是否在跑
curl http://localhost:11434
返回 Ollama is running 就说明 ollama serve 正常启动了。
# 看本地模型列表
ollama list
刚装完应该是空的,后面拉了模型就会有记录。
Ollama Models 介绍
装好 Ollama 之后,下一步是挑模型。Ollama 官方维护了一个模型库(ollama.com/search),收录了主流的开源模型,可以直接 ollama pull 拉取。在拉模型之前,先了解一下模型库里的信息怎么看,后面挑 tag 的时候心里才有数。
1. 模型概览页
以 qwen3.5 为例,打开它的模型页面能看到这些关键信息:
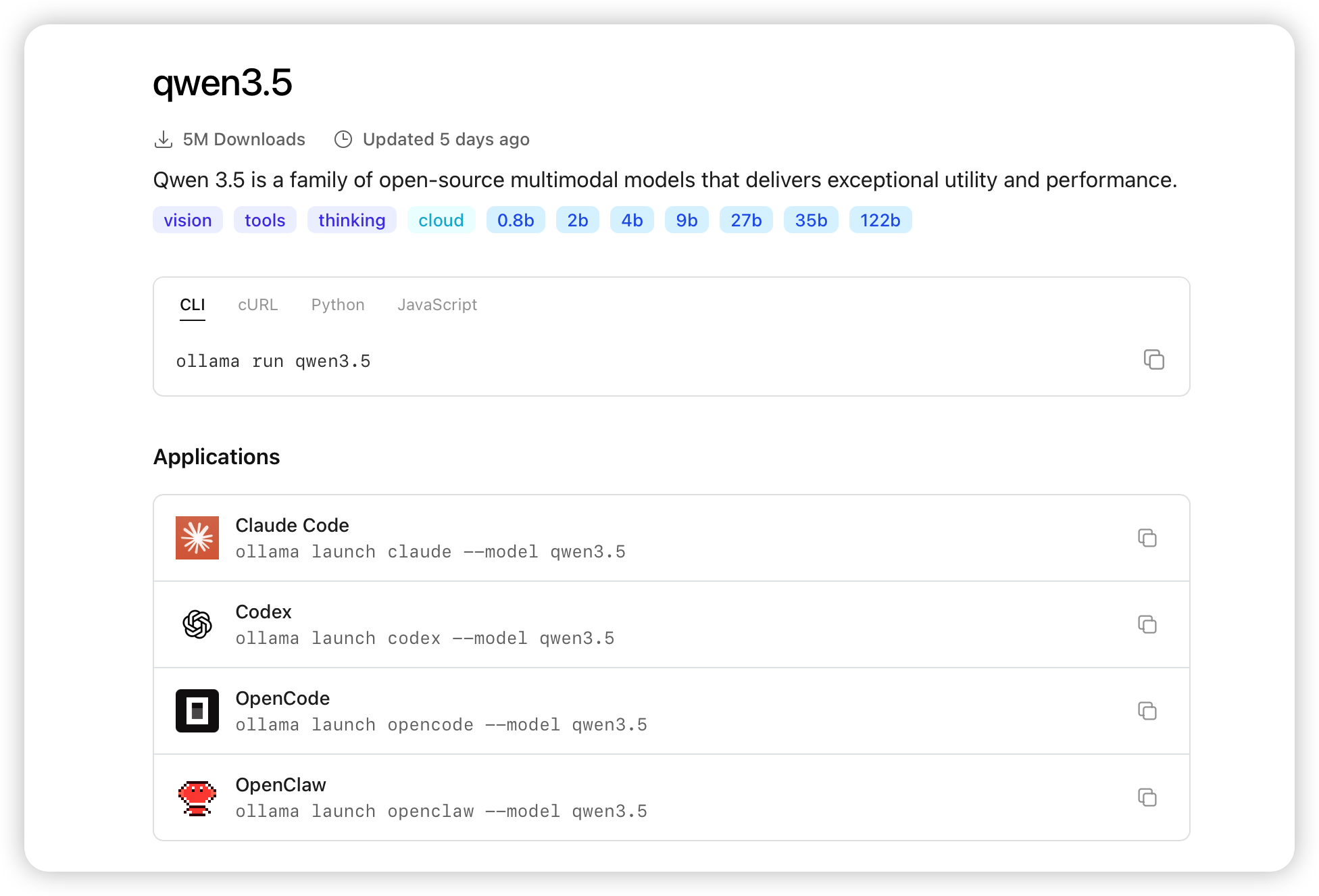
几个值得关注的点:
- 下载量:5M Downloads,说明这个模型系列在 Ollama 社区的使用量很大,稳定性和兼容性有保障。
- 能力标签:
vision(图像理解)、tools(工具调用 / Function Call)、thinking(深度思考 / CoT)、cloud(云端版本)。这些标签直接告诉你模型支持哪些能力,不用去翻论文。 - 规格标签:
0.8b、2b、4b、9b、27b、35b、122b——同一个模型系列提供了从不到 10 亿到 1220 亿参数的多种规格,按你的显存大小挑。 - 调用方式:页面上直接给出了 CLI、cURL、Python、JavaScript 四种调用方式的命令。CLI 方式就是
ollama run qwen3.5,一行命令直接跑。 - Applications:列出了兼容的应用,比如 Claude Code、Codex、OpenCode、OpenClaw 等,可以通过
ollama launch命令直接启动这些应用并指定模型。
2. 模型规格列表
往下翻到 Models 区域,能看到这个模型系列所有可用的 tag:
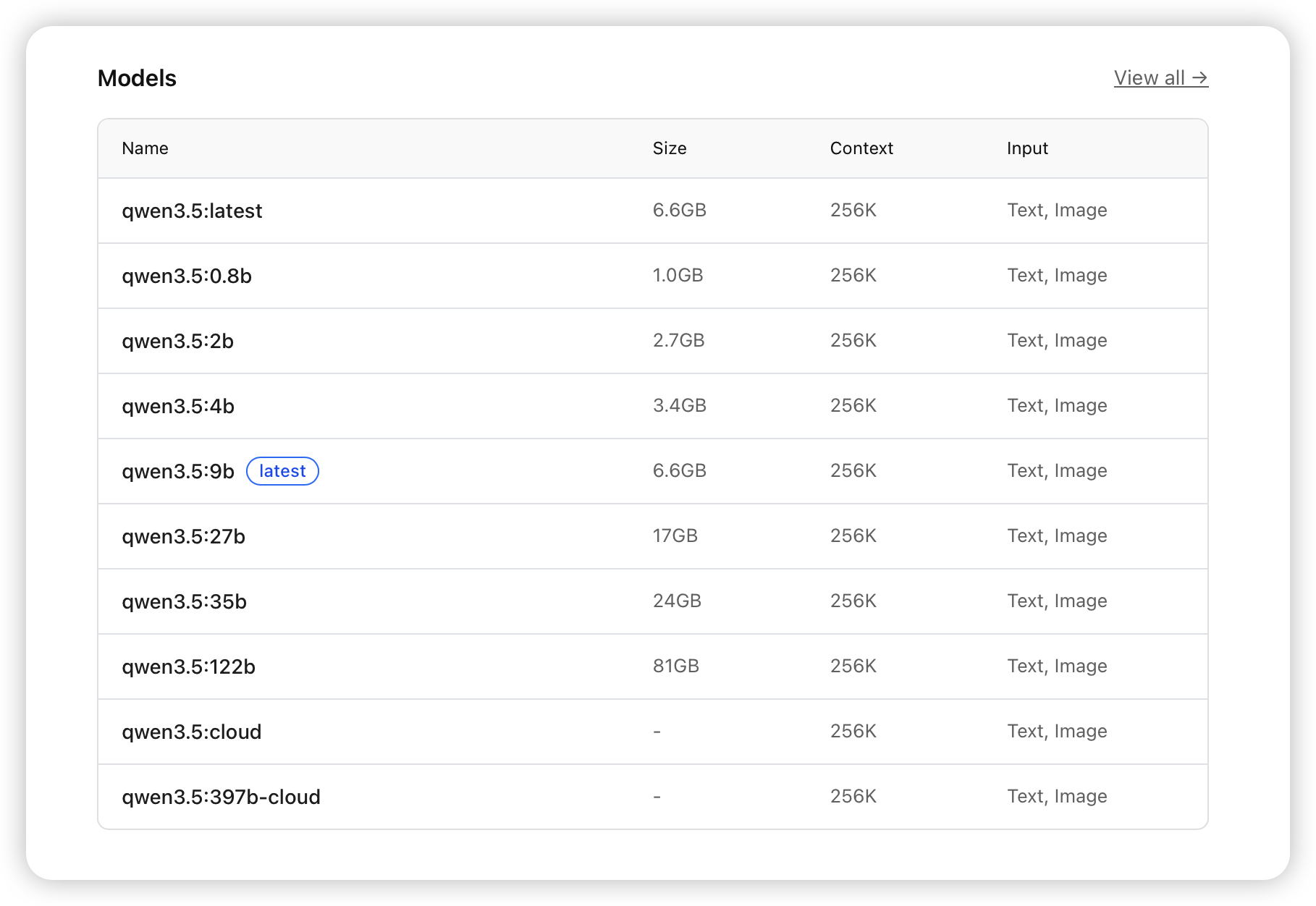
这张表是挑模型 tag 的核心参考:
| 名称 | 大小 | 上下文窗口 | 输入类型 |
|---|---|---|---|
| qwen3.5:latest | 6.6GB | 256K | Text, Image |
| qwen3.5:0.8b | 1.0GB | 256K | Text, Image |
| qwen3.5:2b | 2.7GB | 256K | Text, Image |
| qwen3.5:4b | 3.4GB | 256K | Text, Image |
| qwen3.5:9b(latest) | 6.6GB | 256K | Text, Image |
| qwen3.5:27b | 17GB | 256K | Text, Image |
| qwen3.5:35b | 24GB | 256K | Text, Image |
| qwen3.5:122b | 81GB | 256K | Text, Image |
| qwen3.5:cloud | - | 256K | Text, Image |
| qwen3.5:397b-cloud | - | 256K | Text, Image |
几个要点:
- latest 指向 9b:直接
ollama run qwen3.5拉的就是 9b 规格,6.6GB。大多数模型的 latest 都是一个中等偏小的规格,不会一上来就给你拉个几十 GB 的大家伙。 - Size 列是磁盘占用:这个大小是量化后的体积。比如 9b 只有 6.6GB 而不是 fp16 的 ~18GB,说明默认 tag 用的是量化版(通常是 Q4_K_M)。加载到显存后的实际占用会略大一些,但量级差不多。
- 全系列支持 256K 上下文:Qwen3.5 全系列都有 256K 的上下文窗口,但实际能用多长取决于你的显存——上下文越长,KV Cache 占用越大。
- 全系列支持多模态输入:Text + Image,意味着这些模型既能处理文本也能理解图片。
- cloud 版本:Size 显示
-,说明这不是本地模型,而是通过 Ollama 调用云端 API。适合显存不够但想体验大参数模型效果的场景。