向量数据库的原理与选型
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇我们把文本 chunk 变成了一组浮点数向量,还用 SiliconFlow 的 API 跑通了一个完整的向量化检索 demo。最后留了一个问题:向量生成之后存到哪里?
当时的 demo 里,我们把所有向量放在一个 List<float[]> 里,查询的时候遍历整个列表,逐个算余弦相似度,取最高的几个。demo 跑得很顺畅,因为只有几条数据。
但你想想实际场景——一个电商平�台的知识库,商品说明、退货政策、物流规则、促销活动、FAQ……分块之后轻轻松松几十万甚至上百万个 chunk,每个 chunk 对应一个 4096 维的向量。每次用户提问,你都要拿查询向量和这几十万个向量逐一比较?
这显然不现实。
这一篇,我们就来解决这个问题:向量存到哪里,怎么在海量向量中高效检索。
向量存到哪里:为什么普通数据库不够用
1. 最直觉的方案:用 MySQL 存向量
既然向量就是一组浮点数,那最直觉的想法就是——存 MySQL 呗。
方案很简单:在表里加一个 TEXT 或 JSON 字段,把向量序列化成字符串存进去。检索的时候把所有向量读出来,在应用层逐个计算余弦相似度,排序取 Top-K。
CREATE TABLE chunk_vectors (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
chunk_text TEXT NOT NULL,
vector JSON NOT NULL, -- 存储 4096 维浮点数向量
doc_id VARCHAR(64),
category VARCHAR(32),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
能跑通吗?能。demo 阶段完全没问题。
但这个方案有一个致命的问题——检索的时候,你必须把所有向量都读出来,在内存里逐个计算相似度。这就是所谓的暴力搜索(Brute-Force Search)。
2. 暴力搜索的性能瓶颈
咱们算一笔账。
假设你的知识库有 100 万个 chunk,每个 chunk 的向量是 4096 维(用的 Qwen3-Embedding-8B 模型)。每次用户提问,系统需要:
- 把用户的问题也向量化,得到一个 4096 维的查询向量
- 从数据库里读出 100 万个向量
- 逐个计算查询向量和这 100 万个向量的余弦相似度
- 排序,取相似度最高的 Top-K 个
第 3 步是瓶颈。每次余弦相似度计算需要做 4096 次乘法 + 4096 次加法 + 开方等运算。100 万个向量就是 100 万次这样的计算。
具体要多久?在一台普通服务器上(单核 CPU),100 万个 4096 维向量的暴力搜索大约需要 2~5 秒。听起来好像还行?
但别忘了:
- 这只是单次查询的耗时,如果有 100 个用户同时提问呢?
- 数据量还会增长,500 万、1000 万个 chunk 呢?
- 实际的 RAG 系统对延迟很敏感,用户问一个问题不只是向量检索,还有很多其他步骤,体验很差
- 而且每次查询都要把 100 万个向量从磁盘读到内存,I/O 开销也很大
用一张图来直观感受一下暴力搜索的过程:
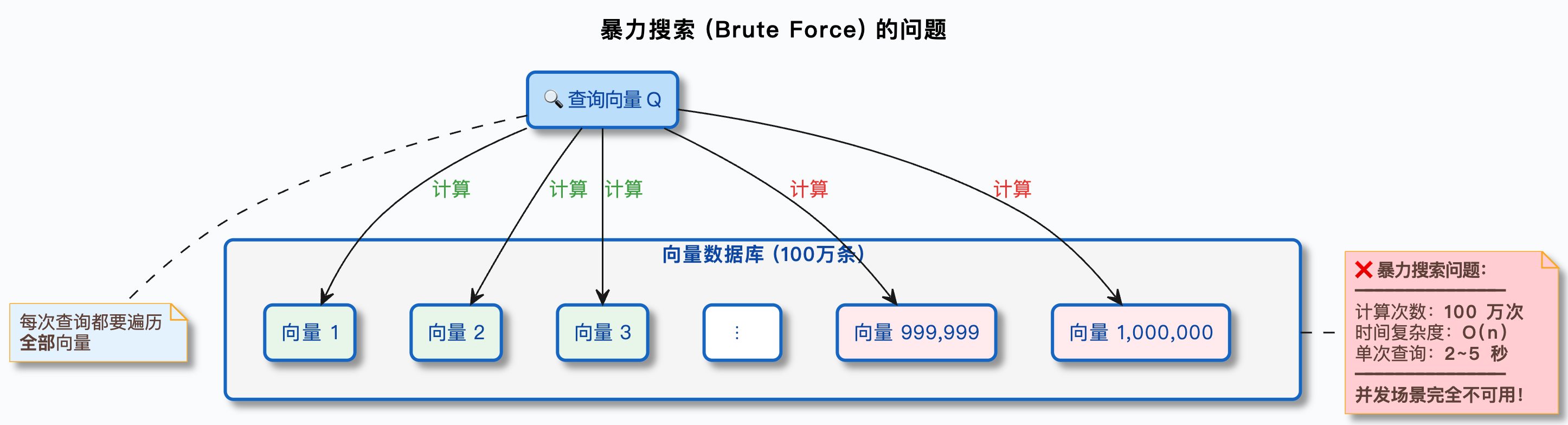
所以,暴力搜索在数据量小的时候没问题,但一旦数据量和并发量上去,就完全不可用了。
3. 近似最近邻搜索
既然逐个比较太慢,能不能不比较所有向量,只比较其中一部分,就找到大概率最相似的那几个?
答案是可以。这就是 ANN(Approximate Nearest Neighbor,近似最近邻搜索)的核心思想。
注意这里的关键词是“近似”——ANN 不保证找到的一定是全局最相似的向量,但它能在极短的时间内找到非常接近最优解的结果。
打个比方:暴力搜索就像你要在一个 100 万人的城市里找和你最像的人,挨个去比对。ANN 则是先按区域划分,再按特征缩小范围,最后只在一小撮人里精确比较。你可能会错过某个住在偏远角落的“最佳匹配”,但你找到的人已经足够像了,而且速度快了几百倍。
用数字来感受一下差距:
| 指标 | 暴力搜索 | ANN 检索 |
|---|---|---|
| 100 万向量查询耗时 | 2~5 秒 | 1~10 毫秒 |
| 召回率(Recall) | 100%(精确) | 95%~99%(近似) |
| 是否需要专门索引 | 不需要 | 需要 |
| 适用数据量 | < 10 万 | 百万~亿级 |
110 毫秒 vs 25 秒,速度差了几百到几千倍,而召回率只损失了 1%~5%。在实际的 RAG 场景中,这点精度损失几乎感知不到——你本来就是取 Top-K 个结果丢给大模型做参考,少了一个排名第 47 的 chunk 对最终回答没有影响。
这就是向量数据库存在的核心理由:它不只是存向量,更重要的是提供高效的 ANN 检索能力。普通数据库能存向量,但做不了高效的 ANN 检索。
一句话概括:向量数据库 = 向量存储 + ANN 索引 + 高效检索。它是专门为“在海量向量中快速找到最相似的那几个”这件事而设计的。
向量检索的核心算法:怎么不用逐个比较就能找到最相似的
知道了 ANN 的目标——不逐个比较,快速找到近似最优解——接下来的问题是:具体怎么做到的?
这一节我们讲两种最主流的 ANN 索引算法:IVF 和 HNSW。不涉及数学推导,重点是让你理解它们的核心思想和工程上的取舍。
1. 类比:在一本 10 万页的字典里查一个词
在讲具体算法之前,先想一个生活中的场景。
你手上有一本 10 万页的字典,要查 serendipity 这个词。你会怎么做?
肯定不会从第 1 页翻到第 100000 页。你会:
- 先看目录,确定 S 开头的词在哪个范围
- 翻到大概的位置,再根据前几个字母缩小范围
- 最后在一小段页面里精确查找
这个过程的本质是:通过某种结构(目录、索引),把搜索范围从“全部”缩小到“一小部分”,然后在小范围内精确查找。
向量索引的思路完全一样——只不过字典里的“词”变成了“向量”,字母顺序变成了空间位置。
2. IVF(倒排文件索引):先分区再搜索
IVF 的全称是 Inverted File Index(倒排文件索引)。名字听起来很学术,但思路非常直觉。
2.1 IVF 的工作原理
IVF 的核心思想就一句话:把向量空间划分成若干个区域,查询时只在最可能的几个区域里搜索。
具体怎么做?分两个阶段:
建索引阶段(离线):
- 用聚类算法(通常是 K-Means)把所有向量分成
nlist个簇(cluster) - 每个簇有一个中心点(centroid),代表这个簇里所有向量的"平均位置"
- 每个向量被分配到离它最近的那个簇
检索阶段(在线):
- 拿到查询向量后,先计算它和所有簇中心点的距离
- 找到最近的
nprobe个簇(nprobe 是一个可调参数) - 只在这
nprobe个簇里的向量中做精确搜索
打个比方:你要在一个大型图书馆里找一本关于“Java 并发编程”的书。IVF 的做法是——先看楼层指引,确定计算机类在 3 楼,编程语言在 3 楼 A 区,然后只在 3 楼 A 区的书架上找。你不需要把整个图书馆的书都翻一遍。
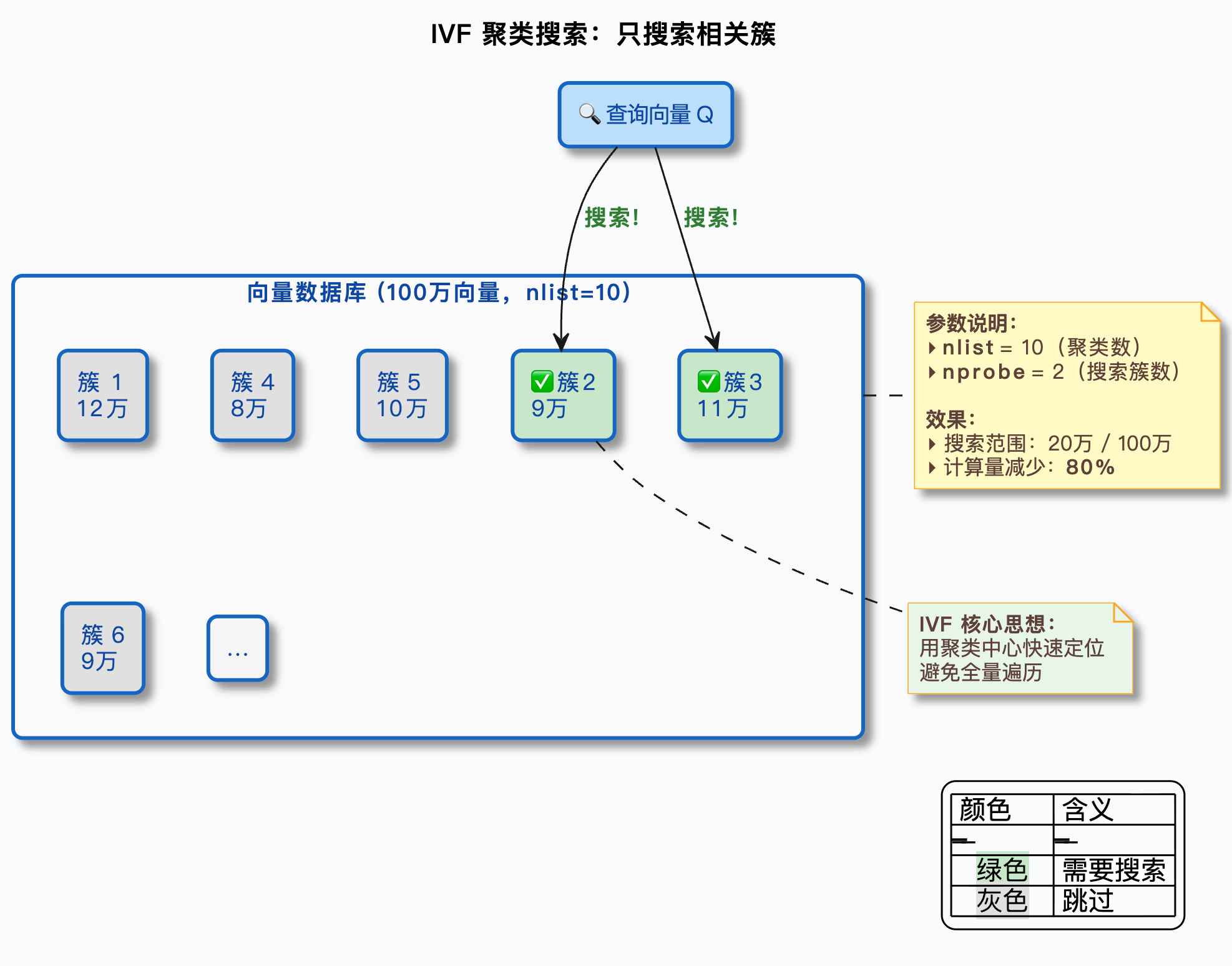
假设 nlist = 100(分成 100 个簇),nprobe = 10(查询时搜索 10 个簇),那么每次查询只需要搜索大约 10% 的向量,速度提升约 10 倍。
2.2 IVF 的优缺点
| 优点 | 缺点 |
|---|---|
| 原理简单,容易理解和调优 | 需要训练聚类模型(数据量大时训练较慢) |
| 内存占用相对较低 | 聚类边界处的向量可能被漏掉(影响召回率) |
| 适合数据量非常大的场景 | nlist 和 nprobe 的调参需要经验 |
| 支持增量插入(但可能需要定期重新聚类) | 数据分布不均匀时效果下降 |
IVF 还有几个变体:IVF_FLAT 是在簇内做精确搜索,IVF_SQ8 是对簇内向量做量化压缩以节省内存,IVF_PQ 则用乘积量化进一步压缩。后面的选型表格里会对比它们的差异。
3. HNSW(分层可导航小世界图):最主流的索引算法
HNSW 的全称是 Hierarchical Navigable Small World Graph(分层可导航小世界图)。名字很长,但它是目前最主流、效果最好的 ANN 索引算法,几乎所有向量数据库都把它作为默认或推荐的索引类型。
3.1 HNSW 的核心思想:多层图结构
要理解 HNSW,先从一个生活场景开始。
假设你要找一个"住在北京朝阳区、会写 Java、喜欢打篮球"的人,但你手上没有任何名单,只能通过社交关系去找。你会怎么做?
你不会挨个问全中国 14 亿人。你会这样:
- 先在你认识的人里找——“谁在北京?”——你的朋友老王在北京
- 问老王——“你认识朝阳区的人吗?”——老王介绍了他同事小李
- 问小李——“你认识会写 Java 的�人吗?”——小李介绍了他的大学同学张三
- 张三恰好也喜欢打篮球——找到了!
每一步你都在靠近目标,而且每一步只需要问几个人,不需要遍历所有人。
HNSW 的思路和这个完全一样,只不过把“人”换成了“向量”,把“社交关系”换成了“图中的边”。
HNSW 的核心结构是一个多层图:
- 最底层(Layer 0)包含所有向量,每个向量和它附近的若干个向量相连
- 往上每一层的向量数量越来越少(随机抽取),但连接的跨度越来越大
- 最顶层只有很少的几个向量,但它们之间的连接覆盖了整个向量空间
检索的时候,从最顶层开始,快速定位到目标的大致区域,然后逐层下降,每一层都在更精细的范围内搜索,最终在最底层找到最相似的向量。
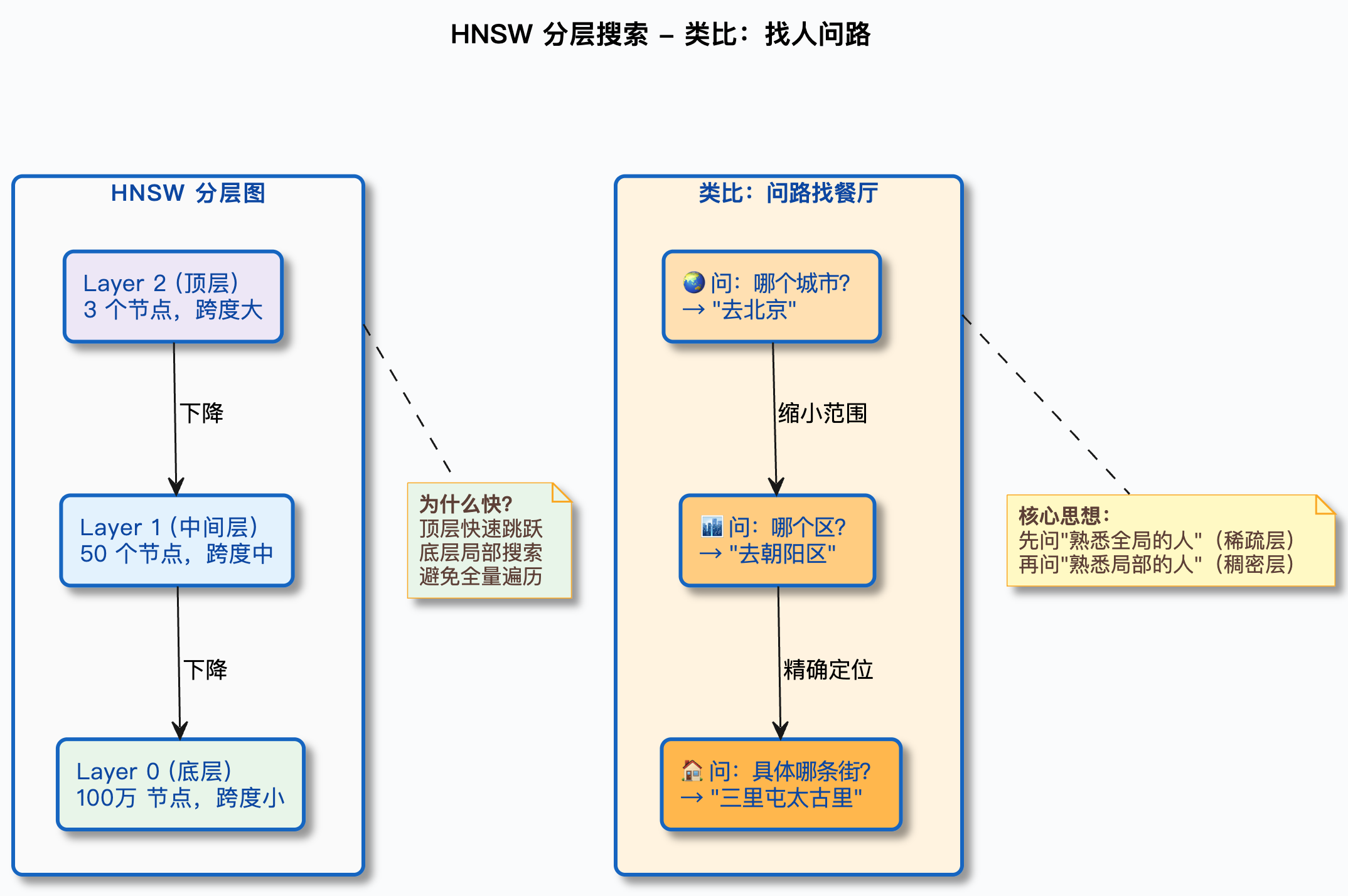
3.2 用一个具体例子走一遍 HNSW 的检索过程
为了让你更直观地理解,咱们用一个简化的例子走一遍。
假设向量数据库里有 8 个向量(A、B、C、D、E、F、G、H),HNSW 建了 3 层图。现在要查询和向量 Q 最相似的向量。
Layer 2(顶层):只有 A 和 E 两个向量
- 从 A 开始,计算 Q 和 A 的距离、Q 和 E 的距离
- 发现 E 离 Q 更近,移动到 E
Layer 1(中间层):有 A、C、E、G 四个向量
- 从 E 出发,看 E 的邻居:C 和 G
- 计算 Q 和 C、Q 和 G 的距离
- 发现 G 离 Q 更近,移动到 G
Layer 0(底层):所有 8 个向量都在
- 从 G 出发,看 G 的邻居:F 和 H
- 计算 Q 和 F、Q 和 H 的距离
- 发现 H 离 Q 最近
- 再看 H 的邻居,没有比 H 更近的了
- 结果:H 是和 Q 最相似的向量
整个过程只计算了 6 次距离(A、E、C、G、F、H),而不是 8 次。数据量小的时候差距不明显,但如果有 100 万个向量,HNSW 通常只需要计算几百到几千次距离就能找到结果。
3.3 为什么 HNSW 这么快
HNSW 快的原因可以归结为两点:
第一,多层结构实现了“粗到细”的搜索。顶层的少量向量帮你快速跳到目标附近,底层的密集连接帮你精确定位。这和跳表(Skip List)的思想很像——如果你了解 Redis 的有序集合(ZSet),它底层用的就是跳表,原理是相通的。
第二,“小世界”特性保证了图的连通性。在 HNSW 的图中,任意两个向量之间只需要经过很少的“跳转”就能到达(类似“六度分隔理论”——你和世界上任何一个人之间最多只隔 6 个人)。这意味着搜索不会陷入死角,总能快速逼近目标。
3.4 HNSW 的代价:内存占用
HNSW 的检索速度和精度都很优秀,但它有一个明显的代价:内存占用大。
因为 HNSW 需要在内存中维护整个图结构——不仅要存所有向量本身,还要存向量之间的连接关系(边)。每个向量在每一层都有若干条边,这些边的存储开销不小。
具体来说,HNSW 有两个关键参数影响内存和性能:
| 参数 | 含义 | 调大的效果 | 调小的效果 |
|---|---|---|---|
| M | 每个向量在每层的最大连接数 | 召回率更高,但内存占用更大,建索引更慢 | 内存省,但召回率可能下降 |
| efConstruction | 建索引时的搜索宽度 | 索引质量更高(连接更合理),但建索引更慢 | 建索引快,但索引质量可能下降 |
检索时还有一个参数 ef(搜索宽度),控制检索时探索的候选集大小。ef 越大,召回率越高,但检索越慢。
一个粗略的估算:100 万个 4096 维向量,用 HNSW 索引(M=16),大约需要 16~20 GB 内存。如果你的服务器内存有限,可能需要考虑 IVF 系列索引,它们的内存占用要小得多。
4. 索引算法对比:怎么选
Milvus 支持多种索引类型,下面是最常用的几种对比:
| 索引类型 | 核心思想 | 检索速度 | 召回率 | 内存占用 | 适用数据量 | 适用场景 |
|---|---|---|---|---|---|---|
| FLAT | 暴力搜索,不建索引 | 最慢 | 100%(精确) | 低(只存原始向量) | < 10 万 | 对精度要求极高,数据量小 |
| IVF_FLAT | 聚类分区 + 簇内精确搜索 | 快 | 95%~99% | 较低 | 百万~千万 | 数据量大,内存有限 |
| IVF_SQ8 | 聚类分区 + 标量量化压缩 | 快 | 93%~97% | 低(向量压缩为 1/4) | 千万~亿级 | 数据量很大,愿意牺牲一点精度换内存 |
| HNSW | 多层图结构 | 最快 | 97%~99.5% | 高(需存图结构) | 百万~千万 | 对速度和精度都有要求,内存充足 |
| DISKANN | 基于磁盘的图索引 | 较快 | 95%~98% | 低(索引在磁盘) | 亿级 | 数据量极大,内存不够放 HNSW |
怎么选?一个简单的决策路径:
- 数据量 < 10 万,直接用 FLAT,暴力搜索就够了
- 数据量 10 万~500 万,内存充足 → HNSW;内存有限 → IVF_FLAT
- 数据量 500 万~5000 万,HNSW 如果内存放得下就用 HNSW,放不下用 IVF_SQ8
- 数据量 > 5000 万,考虑 DISKANN 或 IVF_PQ
对于大多数 RAG 项目来说,数据量在百万级别,HNSW 是最优选择。这也是为什么后面的实战代码里我们用 HNSW 作为索引类型。
主流向量数据库对比与选型
理解了向量检索的算法原理之后,下一个问题是:用哪个向量数据库?
市面上的向量数据库方案大致分两类。
1. 向量数据库的分类
1.1 专用向量数据库
从零开始为向量检索设计的数据库,向量是一等公民。代表产品:Milvus、Qdrant、Weaviate、Pinecone、Chroma。
它们的特点是:原生支持多种 ANN 索引算法,针对向量检索做了大量底层优化(内存管理、并行计算、索引构建等),通常还支持标量过滤(在向量检索的同时按元数据条件过滤)。
1.2 传统数据库的向量扩展
在已有的关系型数据库上加一个向量检索插件。代表产品:pgvector(PostgreSQL 的扩展)、MySQL 8.0+ 的向量支持、Elasticsearch 的 kNN 搜索。
它们的优势是不用引入新的基础设施——如果你的项目已经在用 PostgreSQL,加一个 pgvector 扩展就能存向量、做检索,运维成本低。但在大数据量下的检索性能、索引类型的丰富度、以及向量检索的专项优化上,和专用向量数据库还是有差距。
1.3 怎么选
一个简单的判断标准:
- 如果你的向量数据量 < 50 万,且项目已经在用 PostgreSQL → pgvector 够用,省事
- 如果向量数据量 > 50 万,或者对检索性能有较高要求 → 用专用向量数据库
- 如果是学习和原型验证阶段 → Chroma(轻量,Python 生态好)或 Milvus(功能全,Java SDK 完善)
2. 主流方案对比
| 数据库 | 类型 | 部署方式 | 适用数据量 | 语言 SDK | 索引类型 | 标量过滤 | 开源 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| Milvus | 专用 | 自部署(Docker/K8s)或 Zilliz Cloud | 百万~十亿级 | Java、Python、Go、Node.js | HNSW、IVF 系列、DISKANN 等 | 支持 | 是(Apache 2.0) | 大规模生产环境,Java 技术栈 |
| Qdrant | 专用 | 自部署(Docker)或 Qdrant Cloud | 百万~亿级 | Python、Rust、Go、Java | HNSW | 支持 | 是(Apache 2.0) | Rust 生态,高性能单机场景 |
| Weaviate | 专用 | 自部署(Docker)或 Weaviate Cloud | 百万~千万级 | Python、Go、Java、JS | HNSW | 支持 | 是(BSD-3) | 内置向量化能力,全托管偏好 |
| Pinecone | 专用 | 纯云托管(无自部署) | 百万~亿级 | Python、Node.js | 自研 | 支持 | 否 | 不想运维,纯云方案 |
| Chroma | 专用 | 嵌入式 / Docker | < 百万 | Python、JS | HNSW | 支持 | 是(Apache 2.0) | 原型验证,轻量场景 |
| pgvector | 扩展 | 随 PostgreSQL 部署 | < 百万 | 所有支持 PG 的语言 | HNSW、IVF_FLAT | 支持(SQL WHERE) | 是 | 已有 PG,数据量不大 |
3. 为什么选 Milvus
本系列选择 Milvus 作为向量数据库,原因有几个:
- 开源且社区活跃:Apache 2.0 协议,截止 26.2.20 号 GitHub 上 42.8k+ star,文档和社区资源丰富
- Java SDK 完善:本系列的代码示例用 Java,Milvus 的 Java SDK(
io.milvus:milvus-sdk-java)功能完整,API 设计清晰 - 支持大规模数据:从几万到几十亿向量都能应对,单机模式适合开发和中小规模,集群模式适合大规模生产
- 索引类型丰富:HNSW、IVF_FLAT、IVF_SQ8、DISKANN 等都支持,可以根据场景灵活选择
- 标量过滤能力强:支持在向量检索的同时按元数据字段过滤(比如:只在退货政策类的 chunk 里检索),这在 RAG 场景中非常实用
- 本地部署简单:一个
docker compose up -d就能启动,开发环境零门槛
需要说明的是,选 Milvus 不代表它在所有场景下都是最优解。如果你的项目是 Python 技术栈且数据量不大,Chroma 可能更轻便;如果你不想自己运维,Pinecone 的全托管方案也值得考虑。技术选型没有银弹,适合你的场景才是最好的。
Milvus 核心概念:和传统数据库做类比
在动手写代码之前,先搞清楚 Milvus 里的几个核心概念。如果你用过 MySQL,理解起来会很快——Milvus 的概念体系和关系型数据库有很多对应关系。
1. Collection = 表
Collection 是 Milvus 中数据组织的基本单位,对应 MySQL 中的表(Table)。
一个 Collection 存储一类向量数据。比如在我们的电商客服知识库场景中,可以创建一个名为 customer_service_chunks 的 Collection,里面存所有客服知识库的 chunk 向量。
如果你有多个业务场景(比如客服知识库、商品搜索、内容推荐),通常每个场景创建一个独立的 Collection。
2. Schema = 表结构
Schema 定义了 Collection 中每条数据包含哪些字段,对应 MySQL 中的表结构(CREATE TABLE 时定义的列)。
一个典型的 RAG 场景的 Schema 包含三类字段:
| 字段类型 | 示例 | 说明 |
|---|---|---|
| 主键字段 | id(Int64 或 VarChar) | 每条数据的唯一标识,类似 MySQL 的主键 |
| 向量字段 | vector(FloatVector) | 存储 Embedding 向量,需要指定维度 |
| 标量字段 | chunk_text、doc_id、category 等 | 存储元数据,用于过滤和展示 |
2.1 向量字段和标量字段的区别
这里要特别说明一下向量字段和标量字段的区别,因为这是 Milvus 和传统数据库最大的不同。
标量字段存储的是普通数据(字符串、数字、布尔值等),和 MySQL 的列没什么区别。你可以对标��量字段建索引、做等值查询、范围查询、模糊匹配等。
向量字段存储的是高维浮点数数组(比如 4096 维的 float 数组),它不能做等值查询(两个向量完全相等的概率几乎为零),只能做相似度检索(找最近的 Top-K 个)。向量字段需要建专门的向量索引(HNSW、IVF 等),这和标量字段的 B+ 树索引是完全不同的东西。
3. Index = 索引
Milvus 中的索引分两种:
- 向量索引:为向量字段创建的 ANN 索引(HNSW、IVF_FLAT 等),用于加速向量相似度检索。这是 Milvus 的核心能力。
- 标量索引:为标量字段创建的索引,用于加速过滤条件的执行。类似 MySQL 的 B+ 树索引。
在 RAG 场景中,通常需要同时用到两种索引:向量索引用于找到语义最相似的 chunk,标量索引用于按元数据过滤(比如只搜索某个类别的 chunk)。
4. Partition = 分区
Partition 是 Collection 内部的数据分区,对应 MySQL 的分区表。
你可以按某个业务维度把数据分到不同的 Partition 里。比如按文档类别分区:退货政策放一个 Partition,物流规则放一个 Partition,促销活动放一个 Partition。
检索的时候可以指定只在某个 Partition 里搜索,这样搜索范围更小,速度更快。
不过需要注意:Partition 不是必须的。如果你的数据量不大(< 100 万),或者没有明确的分区维度,不分区也完全没问题。用标量过滤(在 WHERE 条件里加 category = 'return_policy')也能达到类似的效果,只是在数据量很大时性能不如 Partition。
5. 一张图看懂 Milvus 的数据组织
把上面的概念串起来,Milvus 的数据组织结构是这样的:
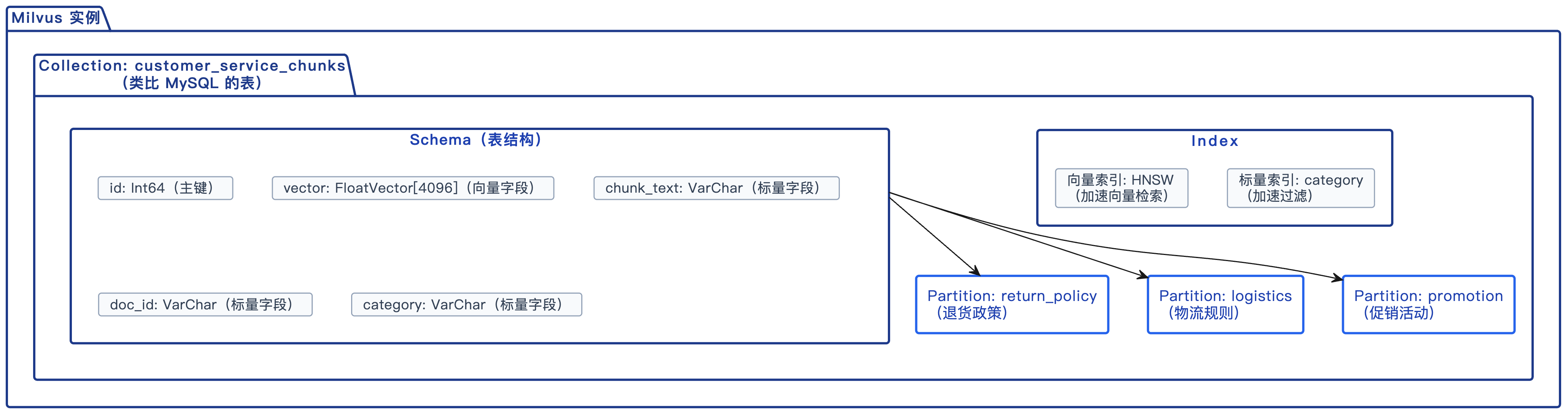
和 MySQL 做个对照:
| Milvus 概念 | MySQL 对应 | 说明 |
|---|---|---|
| Collection | Table | 数据的基本组织单位 |
| Schema | CREATE TABLE 的列定义 | 定义字段名、类型、约束 |
| Field | Column | 单个字段 |
| Partition | 分区表的 Partition | 按业务维度划分数据 |
| 向量索引(HNSW 等) | 无直接对应 | MySQL 没有向量索引 |
| 标量索引 | B+ 树索引 | 加速标量字段的查询 |
| Entity | Row | 一条数据记录 |
动手实践:用 Docker 启动 Milvus 并跑通完整流程
概念讲完了,接下来动手。这一节我们要做的事情很明确:本地启动一个 Milvus,然后用 Java 代码跑通一个完整的向量数据库操作流程—�—创建 Collection、插入向量数据、创建索引、执行向量检索、结合元数据做混合检索。
1. Docker 启动 Milvus Standalone
Milvus Standalone 是单机版,适合开发和中小规模场景。它依赖两个外部组件:一个对象存储(用来存索引文件和日志)和一个 etcd(用来存元数据)。
本系列使用 RustFS 替代默认的 MinIO 作为对象存储,另外加了一个 Attu(Milvus 的可视化管理界面),方便你直观地看到数据。
如果你已经有运行中的 Milvus 实例,可以跳过这一步,直接看后面的代码部分。
把下面的内容保存为 docker-compose.yml,然后执行 docker compose up -d 即可启动:
name: milvus-stack
services:
rustfs:
container_name: rustfs
image: rustfs/rustfs:1.0.0-alpha.72
command:
- "--address"
- ":9000"
- "--console-enable"
- "--access-key"
- "rustfsadmin"
- "--secret-key"
- "rustfsadmin"
- "/data"
environment:
- RUSTFS_ACCESS_KEY=rustfsadmin
- RUSTFS_SECRET_KEY=rustfsadmin
- RUSTFS_CONSOLE_ENABLE=true
ports:
- "9000:9000"
- "9001:9001"
volumes:
- rustfs-data:/data
healthcheck:
test: ["CMD", "sh", "-c", "wget -qO- http://localhost:9000/ || exit 1"]
interval: 30s
timeout: 10s
retries: 5
etcd:
container_name: etcd
image: quay.io/coreos/etcd:v3.5.18
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
command: >
etcd
-advertise-client-urls=http://etcd:2379
-listen-client-urls http://0.0.0.0:2379
--data-dir /etcd
volumes:
- etcd-data:/etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.6.6
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: rustfs:9000
MINIO_ACCESS_KEY_ID: rustfsadmin
MINIO_SECRET_ACCESS_KEY: rustfsadmin
volumes:
- milvus-data:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- etcd
- rustfs
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
attu:
container_name: milvus-attu
image: zilliz/attu:v2.6.3
environment:
MILVUS_URL: milvus-standalone:19530
ports:
- "8000:3000"
depends_on:
- standalone
volumes:
rustfs-data:
etcd-data:
milvus-data:
networks:
default:
name: milvus-net
各组件的作用:
| 组件 | 作用 | 端口 |
|---|---|---|
| rustfs | 对象存储,存储 Milvus 的索引文件和日志 | 9000(API)、9001(控制台) |
| etcd | 元数据存储,管理 Milvus 的集群元信息 | 2379 |
| standalone | Milvus 单机版服务 | 19530(gRPC)、9091(健康检查) |
| attu | Milvus 可视化管理界面 | 8000 |
启动后,访问 http://localhost:8000 可以打开 Attu 管理界面,直观地查看 Collection、数据和索引。
默认不需要填写用户名和密码,直接点击登录即可。
2. Maven 依赖配置
在 pom.xml 中添加 Milvus Java SDK 和 JSON 处理库的依赖:
<dependencies>
<!-- Milvus Java SDK -->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.6.6</version>
</dependency>
<!-- OkHttp,用于调用 SiliconFlow Embedding API -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON 处理 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.13.1</version>
</dependency>
</dependencies>
Milvus Java SDK 从 2.5.x 版本开始提供了 v2 API(
io.milvus.v2包),API 设计更简洁,本文的代码示例全部使用 v2 API。
3. ��创建 Collection 和 Schema
下述的示例代码,都放在了 TinyRAG 项目的 com.nageoffer.ai.tinyrag.milvus 包下,可自行测试。
先连接 Milvus,然后创建一个用于存储电商客服知识库 chunk 的 Collection。
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
public class MilvusDemo {
// 向量维度,和 Embedding 模型保持一致(Qwen3-Embedding-8B 输出 4096 维)
private static final int VECTOR_DIM = 4096;
private static final String COLLECTION_NAME = "customer_service_chunks";
public static void main(String[] args) {
// 1. 连接 Milvus
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("http://localhost:19530")
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
System.out.println("已连接到 Milvus");
// 2. 定义 Schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
// 主键字段:自增 ID
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
// 向量字段:存储 Embedding 向量
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(VECTOR_DIM)
.build());
// 标量字段:chunk 原文
schema.addField(AddFieldReq.builder()
.fieldName("chunk_text")
.dataType(DataType.VarChar)
.maxLength(8192)
.build());
// 标量字段:文档 ID(标识这个 chunk 来自哪个文档)
schema.addField(AddFieldReq.builder()
.fieldName("doc_id")
.dataType(DataType.VarChar)
.maxLength(64)
.build());
// 标量字段:分类(退货政策、物流规则、促销活动等)
schema.addField(AddFieldReq.builder()
.fieldName("category")
.dataType(DataType.VarChar)
.maxLength(32)
.build());
// 3. 创建 Collection
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.collectionSchema(schema)
.build();
client.createCollection(createCollectionReq);
System.out.println("Collection 创建成功:" + COLLECTION_NAME);
}
}
几个要点说明:
FloatVector的dimension必须和你用的 Embedding 模型输出维度一致。我们用的 Qwen3-Embedding-8B 输出 4096 维,这里就填 4096VarChar类型需要指定maxLength,这是 Milvus 的要求。chunk_text设成 8192 足够存一个 chunk 的原文autoID(true)表示主键由 Milvus 自动生成,插入数据时不需要手动指定 ID- 这里没有在创建 Collection 时同时创建索引,后面会单独创建——这样更清晰,也方便你理解每一步在做什么
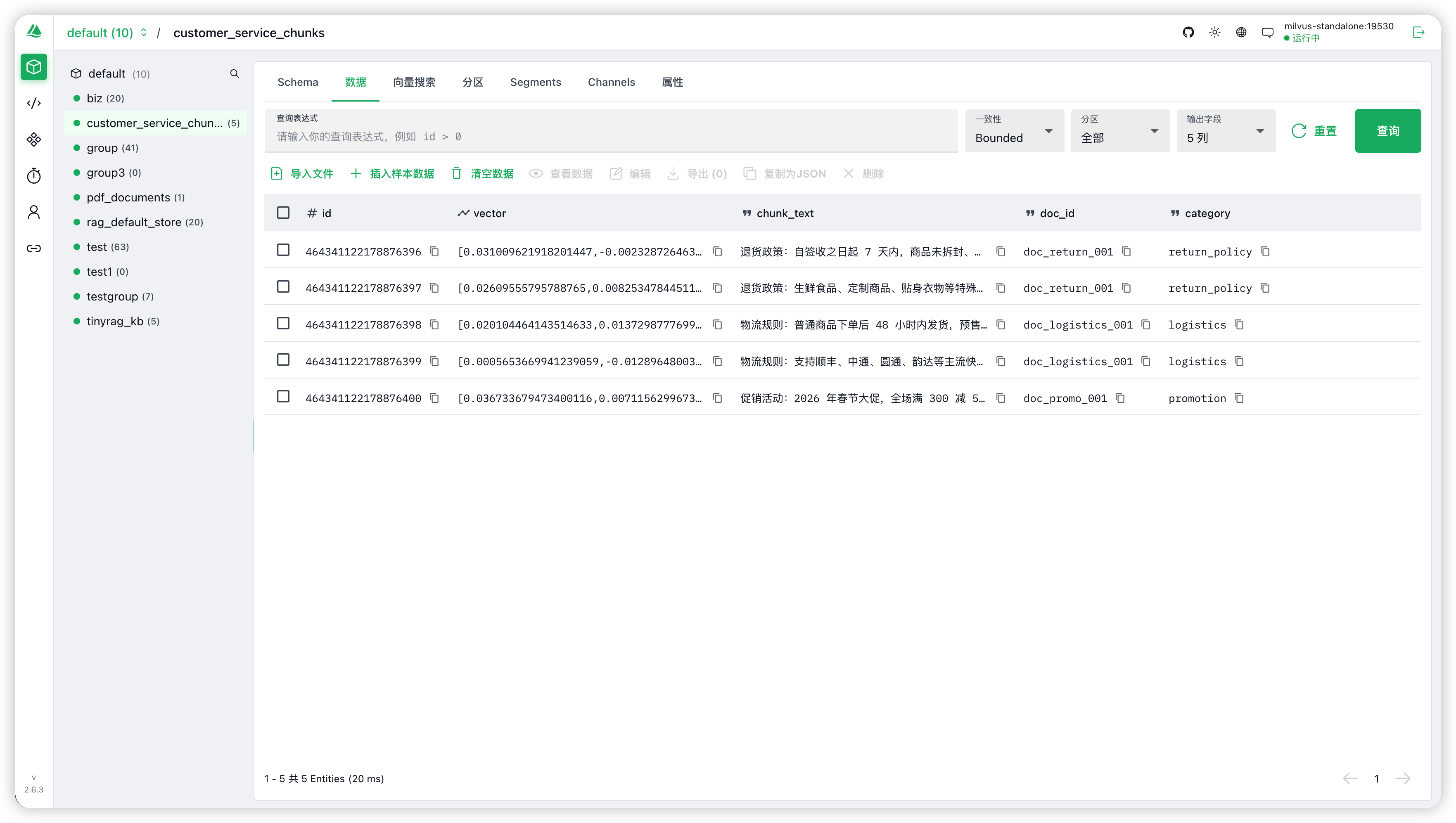
在 Attu 管理界面中可以看到刚创建的 Collection 和它的 Schema。
4. 插入向量数据
Collection 创建好了,接下来往里面插入数据。在实际的 RAG 系统中,数据来源是这样的:原始文档 → Tika 提取文本 → 分块 → 向量化 → 插入 Milvus。这里我们直接模拟几条电商客服知识库的 chunk 数据。
为了让 demo 完整可运行,我们复用上一篇的 SiliconFlow Embedding API 来生成真实的向量,而不是用随机数。
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
import okhttp3.*;
import java.io.IOException;
import java.util.*;
public class MilvusInsertDemo {
private static final String SILICONFLOW_API_KEY = "你的 SiliconFlow API Key";
private static final String EMBEDDING_URL = "https://api.siliconflow.cn/v1/embeddings";
private static final String EMBEDDING_MODEL = "Qwen/Qwen3-Embedding-8B";
private static final Gson GSON = new Gson();
private static final OkHttpClient HTTP_CLIENT = new OkHttpClient();
public static void main(String[] args) throws IOException {
// 连接 Milvus(省略,同上一节)
MilvusClientV2 client = connectMilvus();
// 模拟电商客服知识库的 chunk 数据
List<String> chunkTexts = List.of(
"退货政策:自签收之日起 7 天内,商品未拆封、不影响二次销售的情况下,支持无理由退货。退货运费由买家承担,质量问题除外。",
"退货政策:生鲜食品、定制商品、贴身衣物等特殊商品不支持无理由退货。如有质量问题,请在签收后 48 小时内联系客服并提供照片凭证。",
"物流规则:普通商品下单后 48 小时内发货,预售商品以商品详情页标注的发货时间为准。偏远地区(新疆、西藏、青海等)可能需要额外 2~3 天。",
"物流规则:支持顺丰、中通、圆通、韵达等主流快递。默认使用中通快递,如需指定快递公司,请在下单时备注,可能产生额外运费。",
"促销活动:2026 年春节大促,全场满 300 减 50,满 500 减 100。活动时间:2026 年 1 月 20 日至 2 月 5 日。优惠券�不可叠加使用。"
);
List<String> docIds = List.of("doc_return_001", "doc_return_001", "doc_logistics_001", "doc_logistics_001", "doc_promo_001");
List<String> categories = List.of("return_policy", "return_policy", "logistics", "logistics", "promotion");
// 调用 Embedding API 生成向量
List<List<Float>> vectors = getEmbeddings(chunkTexts);
// 组装插入数据
List<JsonObject> rows = new ArrayList<>();
for (int i = 0; i < chunkTexts.size(); i++) {
JsonObject row = new JsonObject();
row.addProperty("chunk_text", chunkTexts.get(i));
row.addProperty("doc_id", docIds.get(i));
row.addProperty("category", categories.get(i));
row.add("vector", GSON.toJsonTree(vectors.get(i)));
rows.add(row);
}
// 插入 Milvus
InsertReq insertReq = InsertReq.builder()
.collectionName("customer_service_chunks")
.data(rows)
.build();
InsertResp insertResp = client.insert(insertReq);
System.out.println("插入成功,数量:" + insertResp.getInsertCnt());
}
/**
* 调用 SiliconFlow Embedding API,批量生成向量
*/
private static List<List<Float>> getEmbeddings(List<String> texts) throws IOException {
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", EMBEDDING_MODEL);
requestBody.add("input", GSON.toJsonTree(texts));
Request request = new Request.Builder()
.url(EMBEDDING_URL)
.addHeader("Authorization", "Bearer " + SILICONFLOW_API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(GSON.toJson(requestBody),
MediaType.parse("application/json")))
.build();
try (Response response = HTTP_CLIENT.newCall(request).execute()) {
String body = response.body().string();
JsonObject json = GSON.fromJson(body, JsonObject.class);
JsonArray dataArray = json.getAsJsonArray("data");
List<List<Float>> vectors = new ArrayList<>();
for (int i = 0; i < dataArray.size(); i++) {
JsonArray embeddingArray = dataArray.get(i).getAsJsonObject()
.getAsJsonArray("embedding");
List<Float> vector = new ArrayList<>();
for (int j = 0; j < embeddingArray.size(); j++) {
vector.add(embeddingArray.get(j).getAsFloat());
}
vectors.add(vector);
}
return vectors;
}
}
}
插入数据时有几个细节值得注意:
- Milvus v2 API 使用
JsonObject的 List 作为插入数据的格式,每个JsonObject代表一行数据 - 因为我们设置了
autoID(true),所以插入时不需要传id字段,Milvus 会自动生成 - 向量字段的值是一个
Float的 List,维度必须和 Schema 定义的一致(4096),否则插入会报错 - 实际项目中,通常会批量插入(比如每次 1000 条),而不是一条一条插。Milvus 对批量插入做了优化,效率更高
注意,在没有创建索引前,虽然该单元测试显示插入成功,但是 Milvus 控制台查看依然是 0 条数据。只有在创建索引且加载 Collection 到内存才会正常展示。
5. 创建索引
数据插入之后,还不能直接检索——需要先为向量字段创建索引。没有索引的话,Milvus 只能做暴力搜索,和我们开头说的 MySQL 方案没区别。
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.index.request.CreateIndexReq;
// 为向量字段创建 HNSW 索引
IndexParam vectorIndex = IndexParam.builder()
.fieldName("vector")
.indexType(IndexParam.IndexType.HNSW)
.metricType(IndexParam.MetricType.COSINE) // 余弦相似度
.extraParams(Map.of(
"M", 16, // 每个向量的最大连接数
"efConstruction", 256 // 建索引时的搜索宽度
))
.build();
// 为 category 标量字段创建索引(加速过滤查询)
IndexParam categoryIndex = IndexParam.builder()
.fieldName("category")
.indexType(IndexParam.IndexType.TRIE) // 字符串类型用 Trie 索引
.build();
CreateIndexReq createIndexReq = CreateIndexReq.builder()
.collectionName("customer_service_chunks")
.indexParams(List.of(vectorIndex, categoryIndex))
.build();
client.createIndex(createIndexReq);
System.out.println("索引创建成功");
几个关键参数��解释一下:
IndexType.HNSW:我们选 HNSW 作为向量索引,前面分析过,百万级数据量下它是最优选择MetricType.COSINE:相似度度量用余弦相似度,和上一篇 Embedding 里用的一致。Milvus 还支持L2(欧氏距离)和IP(内积),后面"实际项目中的关键决策"部分会详细对比M = 16:每个向量在图中的最大连接数。16 是一个比较通用的值,兼顾了召回率和内存占用efConstruction = 256:建索引时的搜索宽度,越大索引质量越高但建索引越慢。256 是一个偏高的值,适合对召回率要求较高的场景- 标量字段
category用TRIE索引,适合字符串的等值匹配查询
索引创建完成后,需要加载 Collection 到内存才能执行检索:
import io.milvus.v2.service.collection.request.LoadCollectionReq;
client.loadCollection(LoadCollectionReq.builder()
.collectionName("customer_service_chunks")
.build());
System.out.println("Collection 已加载到内存");
loadCollection会把向量数据和索引加载到内存中。这是 Milvus 的设计——检索是在内存中进行的,所以检索前必须先加载。如果数据量很大,加载过程可能需要一些时间。
6. 执行向量检索
索引建好了,Collection 也加载了,现在可以检索了。模拟一个用户提问:“买了东西不想要了怎么退货?”
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
// 用户的问题
String query = "买了东西不想要了怎么退货?";
// 把问题向量化(复用前面的 getEmbeddings 方法)
List<List<Float>> queryVectors = getEmbeddings(List.of(query));
List<BaseVector> milvusQueryVectors = queryVectors.stream()
.map(FloatVec::new) // FloatVec(List<Float>)
.collect(java.util.stream.Collectors.toList());
// 执行向量检索
SearchReq searchReq = SearchReq.builder()
.collectionName("customer_service_chunks")
.data(milvusQueryVectors) // 查询向量
.topK(3) // 返回最相似的 3 个结果
.outputFields(List.of("chunk_text", "doc_id", "category")) // 需要返回的字段
.annsField("vector") // 指定在哪个向量字段上检索
.searchParams(Map.of("ef", 128)) // HNSW 检索时的搜索宽度
.build();
SearchResp searchResp = client.search(searchReq);
// 输出检索结果
List<List<SearchResp.SearchResult>> results = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> resultList : results) {
System.out.println("=== 检索结果 ===");
for (int i = 0; i < resultList.size(); i++) {
SearchResp.SearchResult result = resultList.get(i);
System.out.println("Top-" + (i + 1) + ":");
System.out.println(" 相似度分数:" + result.getScore());
System.out.println(" 分类:" + result.getEntity().get("category"));
System.out.println(" 文档ID:" + result.getEntity().get("doc_id"));
System.out.println(" 内容:" + result.getEntity().get("chunk_text"));
System.out.println();
}
}
检索参数说明:
topK(3):返回相似度最高的 3 个结果。在 RAG 场景中,通常取 3~10 个,具体取多少取决于你给大模型的上下文窗口有多大outputFields:指定返回哪些标量字段。不指定的话只返回主键和相似度分数searchParams中的ef = 128:HNSW 检索时的搜索宽度。ef越大,召回率越高但检索越慢。一般设置为topK的 4~16 倍annsField("vector"):指定在哪个向量字段上做检索。如果 Collection 只有一个向量字段,可以省略
检索返回结果如下所示:
=== 检索结果 ===
Top-1:
相似度分数:0.6188747
分类:return_policy
文档ID:doc_return_001
内容:退货政策:自签收之日起 7 天内,商品未拆封、不影响二次销售的情况下,支持无理由退货。退货运费由买家承担,质量问题除外。
Top-2:
相似度分数:0.61833143
分类:return_policy
文档ID:doc_return_001
内容:退货政策:生鲜食品、定制商品、贴身衣物等特殊商品不支持无理由退货。如有质量问题,请在签收后 48 小时内联系客服并提供照片凭证。
Top-3:
相似度分数:0.54991865
分类:logistics
文档ID:doc_logistics_001
内容:物流规则:支持顺丰、中通、圆通、韵达等主流快递。默认使用中通快递,如需指定快递公司,请在下单时备注,可能产生额外运费。
7. 结合元数据过滤的混合检索
纯向量检索有时候不够精确。比如用户问“退货运费谁出?”,你希望只在退货政策类的 chunk 里检索,而不是在物流规则或促销活动里找。这时候就需要在向量检索的基础上加一个标量过滤条件。
Milvus 支持在检索时通过 filter 参数指定过滤表达式,语法类似 SQL 的 Where 子句:
// 用户的问题
String query = "买了东西不想要了怎么退货?";
// 把问题向量化(复用前面的 getEmbeddings 方法)
List<List<Float>> queryVectors = getEmbeddings(List.of(query));
List<BaseVector> milvusQueryVectors = queryVectors.stream()
.map(FloatVec::new) // FloatVec(List<Float>)
.collect(java.util.stream.Collectors.toList());
// 执行向量检索
// 混合检索:向量相似度 + 标量过滤
// 只在退货政策类的 chunk 里检索
SearchReq filteredSearchReq = SearchReq.builder()
.collectionName("customer_service_chunks")
.data(milvusQueryVectors)
.topK(3)
.outputFields(List.of("chunk_text", "doc_id", "category"))
.annsField("vector")
.filter("category == \"return_policy\"") // 只搜索退货政策类
.searchParams(Map.of("ef", 128))
.build();
SearchResp filteredResp = client.search(filteredSearchReq);
// 输出过滤后的结果
List<List<SearchResp.SearchResult>> filteredResults = filteredResp.getSearchResults();
for (List<SearchResp.SearchResult> resultList : filteredResults) {
System.out.println("=== 过滤检索结果(仅退货政策) ===");
for (int i = 0; i < resultList.size(); i++) {
SearchResp.SearchResult result = resultList.get(i);
System.out.println("Top-" + (i + 1) + ":");
System.out.println(" 相似度分数:" + result.getScore());
System.out.println(" 内容:" + result.getEntity().get("chunk_text"));
System.out.println();
}
}
检索输出结果如下:
=== 过滤检索结果(仅退货政策) ===
Top-1:
相似度分数:0.6188747
内容:退货政策:自签收之日起 7 天内,商品未拆封、不影响二次销售的情况下,支持无理由退货。退货运费由买家承担,质量问题除外。
Top-2:
相似度分数:0.61833143
内容:退货政策:生鲜食品、定制商品、贴身衣物等特殊商品不支持无理由退货。如有质量问题,请在签收后 48 小时内联系客服并提供照片凭证。
filter 表达式支持的语法很丰富,常用的有:
| 表达式 | 含义 |
|---|---|
category == "return_policy" | 等值匹配 |
category in ["return_policy", "logistics"] | 多值匹配 |
doc_id != "doc_promo_001" | 不等于 |
category == "return_policy" and doc_id == "doc_return_001" | 组合条件 |
这种"向量检索 + 标量过滤"的混合检索在 RAG 场景中非常常见。比如:
- 多租户场景:每个租户只能检索自己的数据,用
tenant_id == "xxx"过滤 - 权限控制:不同角色能看到的文档不同,用
access_level <= 3过滤 - 时效性:只检索最近更新的文档,用
updated_at > "2026-01-01"过滤 - 分类检索:用户明确了问题类别时,缩小检索范围提高精度
8. 运行结果分析
把上面的代码串起来跑一遍,看看实际的检索效果。用户问的是“买了东西不想要了怎么退货?”
注意:上面的分数是示意值,实际运行时的分数会因 Embedding 模型和数据不同而有差异。
分析一下这个结果:
- Top-1 和 Top-2 都是退货政策相关的 chunk,语义上和用户的问题高度相关,这正是我们期望的
- Top-3 是物流规则,和退货没什么关系,但因为我们只取了 Top-3 且没有加过滤条件,它被“凑数”选了进来
- 相似度分数从 0.75 到 0.41 有明显的梯度下降,说明 Embedding 模型确实能区分语义相关性的强弱
如果加上 category == "return_policy" 的过滤条件,Top-3 的物流规则就不会出现了,检索结果会更精准。
这就是一个完整的向量数据库操作流程:创建 Collection → 定义 Schema → 插入数据 → 创建索引 → 加载 Collection → 执行检索。在实际的 RAG 系统中,前面几步(创建到插入)是离线的数据准备阶段,最后的检索是在线的查询阶段。
实际项目中的关键决策
跑通了 demo,接下来聊聊实际项目中你会遇到的几个关键决策。这些决策没有标准答案,取决于你的数据量、性能要求和资源限制。
1. 索引类型怎么选
前面的“索引算法对比”表格已经给了一个大致的方向,这里再给一个更实操的决策流程:
-
先问自己:数据量有多大?
- < 10 万条:直接用
FLAT,暴力搜索就够了,省去调参的麻烦 - 10 万 ~ 500 万条:优先选
HNSW,速度快、召回率高 - 500 万 ~ 5000 万条:看内存够不够。够就
HNSW,不够就IVF_SQ8(向量压缩到原来的 1/4) - 5000 万条:考虑
DISKANN(索引放磁盘)或IVF_PQ(更激进的压缩)
- < 10 万条:直接用
-
再问自己:对召回率的要求有多高?
- RAG 场景通常取 Top-5 到 Top-10,对召回率的容忍度较高,
HNSW和IVF_FLAT都能满足 - 如果是人脸识别、指纹匹配等对精度要求极高的场景,可能需要
FLAT或者把 HNSW 的参数调得很大
- RAG 场景通常取 Top-5 到 Top-10,对召回率的容忍度较高,
对于大多数 RAG 项目,HNSW 是默认选择,不需要纠结。
2. 相似度度量怎么选
Milvus 支持三种相似度度量方式:
| 度量方式 | 公式直觉 | 值域 | 越大越相似? | 适用场景 |
|---|---|---|---|---|
| COSINE(余弦相似度) | 衡量两个向量方向的夹角 | [-1, 1] | 是 | 文本语义检索(最常用) |
| IP(内积) | 衡量两个向量的方向和大小 | (-∞, +∞) | 是 | 向量已归一化时等价于余弦 |
| L2(欧氏距离) | 衡量两个向量在空间中的直线距离 | [0, +∞) | 否(越小越相似) | 图像检索、推荐系统 |
怎么选?一个简单的原则:看你用的 Embedding 模型推荐哪种。
- 大多数文本 Embedding 模型(包括 Qwen3-Embedding-8B、OpenAI text-embedding-3 等)输出的向量已经做了归一化处理,用
COSINE或IP效果一样 - 如果不确定模型是否做了归一化,用
COSINE最安全——它会自动处理向量长度的差异 L2在文本检索场景中用得较少,更多用在图像、音频等领域
本系列统一使用 COSINE。
3. 分区策略设计
Milvus 的 Partition 可以按业务维度把数据分开存储,检索时指定 Partition 可以缩小搜索范围。
常见的分区策略:
| 分区维度 | 示例 | 适用场景 |
|---|---|---|
| 按文档类别 | return_policy、logistics、promotion | 知识库有明确的分类体系 |
| 按租户 | tenant_001、tenant_002 | 多租户 SaaS 系统 |
| 按时间 | 2026_Q1、2026_Q2 | 数据有明显的时效性 |
不过,分区不是必须的。在以下情况下,用标量过滤(filter)替代分区更简单:
- 分类维度的值很多(比如上百个类别),创建太多 Partition 会增加管理复杂度
- 查询时经常需要跨多个分类检索
- 数据量不大(< 100 万),标量过滤的性能开销可以忽略
一个经验法则:如果某个过滤条件在 90% 以上的查询中都会用到,且值的种类不超过几十个,可以考虑用 Partition;否则用标量过滤就够了。
4. 数据更新策略
知识库不是一成不变的——文档会更新、会删除、会新增。向量数据库里的数据需要和源文档保持同步。
Milvus 目前不支持原地更新(update)单条数据的向量字段,所以更新的标准做法是删旧插新:
import io.milvus.v2.service.vector.request.DeleteReq;
// 1. 删除旧数据(通过 doc_id 定位)
DeleteReq deleteReq = DeleteReq.builder()
.collectionName("customer_service_chunks")
.filter("doc_id == \"doc_return_001\"")
.build();
client.delete(deleteReq);
// 2. 对更新后的文档重新分块、向量化
// 3. 插入新数据(同前面的插入流程)
这里 doc_id 的作用就体现出来了——它是连接源文档和向量数据库的纽带。当一个文档更新时,通过 doc_id 找到这个文档对应的所有 chunk,全部删除,然后重新分块、向量化、插入。
实际项目中的更新策略通常是这样的:
- 源文档变更时,触发一个异步任务
- 任务根据
doc_id删除 Milvus 中该文档的所有旧 chunk - 对新文档重新执行 Tika 提取 → 分块 → 向量化 → 插入 Milvus 的完整流程
- 整个过程对用户无感知,检索服务不中断
5. 性能调优的几个关键参数
最后汇总一下影响性能的关键参数,方便你在实际项目中调优:
5.1 HNSW 索引参数
| 参数 | 作用 | 推荐值 | 调大 | 调小 |
|---|---|---|---|---|
| M | 每个向量的最大连接数 | 8~32,通常 16 | 召回率↑,内存↑,建索引速度↓ | 内存↓,召回率可能↓ |
| efConstruction | 建索引时的搜索宽度 | 128~512,通常 256 | 索引质量↑,建索引速度↓ | 建索引速度↑,索引质量↓ |
| ef | 检索时的搜索宽度 | topK 的 4~16 倍 | 召回率↑,检索速度↓ | 检索速度↑,召回率↓ |
一个实用的调参思路:先用默认值(M=16,efConstruction=256,ef=topK×8)跑起来,然后根据实际的召回率和延迟表现微调。大多数情况下默认值就够用了。
5.2 IVF 索引参数
| 参数 | 作用 | 推荐值 | 调大 | 调小 |
|---|---|---|---|---|
| nlist | 聚类的簇数量 | 数据量的平方根(如 100 万数据用 1024) | 每个簇更小,检索更快,但训练更慢 | 每个簇更大,检索更慢 |
| nprobe | 检索时搜索的簇数量 | nlist 的 5%~10% | 召回率↑,检索速度↓ | 检索速度↑,召回率↓ |
5.3 通用建议
- 向量维度越高,检索越慢、内存占用越大。如果你的 Embedding 模型支持多种维度输出(比如 Qwen3-Embedding-8B 支持 512~4096),在精度够用的前提下可以选较低的维度
- 批量插入比逐条插入快得多,建议每批 1000~5000 条
- 如果数据量很大但查询 QPS 不高,可以考虑用
DISKANN把索引放磁盘,节省内存 - 定期监控检索延迟和召回率,Milvus 的 Attu 管理界面可以看到基本的性能指标
小结与下一篇预告
这一篇我们解决了向量存到哪里的问题。从暴力搜索的性能瓶颈出发,理解了为什么需要专门的向量数据库;学习了 IVF 和 HNSW 两种主流的 ANN 索引算法;对比了市面上的向量数据库方案,选定了 Milvus;最后用 Java 代码跑通了从建表到检索的完整流程。
到这里,RAG 的离线数据准备链路已经打通了:原始文档 → Tika 提取文本 → 分块 → 元数据管理 → 向量化 → 存入 Milvus。
但数据准备好只是第一步。当用户真正提问的时候,怎么从 Milvus 里检索出最相关的 chunk?只靠向量相似度够吗?
答案是:不够。
纯向量检索有一个天然的短板——它擅长语义匹配,但对关键词匹配不敏感。比如用户问:订单号 2026012345 的物流状态,这里面最关键的信息是订单号,但向量检索可能会忽略这个精确的数字,转而匹配一些语义上“像是在问物流”的 chunk。
下一篇我们就来解决这个问题:检索策略。会讲到关键词检索(BM25)、混合检索(向量 + 关键词)、以及重排序(Reranking)——这些策略组合起来,才能让 RAG 系统的检索质量真正达到生产可用的水平。