元数据的作用与管理
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一节我们聊了数据分块(Chunking)——怎么把一篇长文档拆成大小合适的文本块,让检索更精准、让大模型更容易理解。但拆完之后你会发现,光有文本块还不够。每个块只剩下一段裸文本,丢失了它原本的上下文:这段话来自哪份文档?属于哪�个部门?什么时候写的?谁有权限看?这些信息一旦缺失,检索质量和用户体验都会打折扣。
这就是本节要解决的问题——元数据管理(Metadata)。
为什么只有文本内容还不够?
1. 场景:企业知识库问答系统
假设你在一家中型互联网公司做开发,公司有个内部知识库系统,里面存了各个部门的文档:
- 产品部的需求文档、产品手册
- 技术部的架构设计、API 文档、故障处理手册
- 人事部的员工手册、考勤制度、薪酬政策
- 财务部的报销流程、预算审批规则
公司上了一套 RAG 系统,员工可以直接问问题,系统从知识库里检索相关内容并生成回答。听起来很美好,但实际跑起来,问题一个接一个冒出来。
2. 痛点一:用户问“这个规则的依据是什么”,系统答不上来
产品经理小王问:“新员工试用期是几个月?”
系统回答:“试用期为 3 个月。”
小王追问:“这个规定在哪份文档里?我要发给候选人看。”
系统:……(沉默)
问题出在哪?系统确实从知识库里检索到了正确的文本块,但这个块只有纯文本内容,没有记录它来自哪份文档、哪一页、哪个章节。系统知道答案,但说不出依据。
这在企业场景里是个大问题。很多时候,用户不只是要答案,还要知道答案的出处——尤其是涉及制度、流程、合规这类严肃话题时,没有出处的答案是没有公信力的。
3. 痛点二:不同部门的员工看到了不该看的敏感信息
技术部的小李问:“公司的年终奖发放标准是什么?”
系统从知识库里检索到了一段文本,回答:“根据绩效等级,年终奖为月薪的 2-6 倍,其中 S 级 6 倍,A 级 4 倍,B 级 2 倍……”
问题来了:这段内容来自人事部的内部文档,按公司规定只有人事部和管理层能看。但系统在检索时没有做任何权限判断,直接把内容返回给了普通员工。
这在企业场景里是严重的安全隐患。不同部门、不同级别的员工,能看到的知识范围是不一样的。财务部的预算数据、人事部的薪酬政策、技术部的核心架构设计,这些都不应该对所有人开放。
但如果每个文本块只有内容,没有标记它属于哪个部门、适用于哪些角色,系统就没法做权限过滤。
4. 痛点三:发现答案有误,但找不到是哪个 chunk 出了问题
运营部的小张反馈:“系统告诉我报销流程是先提交申请再贴发票,但实际上新流程已经改成线上提交了,不用贴纸质发票了。”
技术团队想修正这个错误,但问题来了:知识库里有几千个文本块,哪个块包含了这段过时的信息?
如果每个块只有文本内容,没有记录它的来源文档、在原文中的位置、创建时间,那要定位到具体的问题块就像大海捞针。就算找到了,也不知道这个块是什么时候加进来的,是不是还有其他相关的块也需要一起更新。
这三个痛点指向同一个问题:只有文本内容是不够的,每个文本块还需要携带一些附加信息,告诉系统这段文本从哪来、给谁看、怎么追溯。
这些附加信息,就是元数据(Metadata)。
元数据到底在干什么
1. 元数据在 RAG 流程中的位置
回顾一下 RAG 的数据准备流程:

元数据是在分块之后、向量化之前加入的。分块完成后,你得到的是一个个纯文本块,这时候给每个块打上标签,记录它的来源、权限、位置等信息。
这些元数据会和文本内容一起,被送到向量数据库里存储。后续检索的时候,不仅可以根据文本相似度找到相关的块,还可以根据元数据做过滤、排序、引用生成等操作。
2. 元数据的本质:给每个 chunk 贴标签
2.1 一个完整的 chunk 长什么样
在没有元数据之前,一个 chunk 就是一段文本:
"自签收之日起 7 天内,商品未经使用且不影响二次销售的,消费者可申请七天无理由退货。"
加上元数据之后,它变成了这样:
{
"content": "自签收之日起 7 天内,商品未经使用且不影响二次销售的,消费者可申请七天无理由退货。",
"metadata": {
"doc_id": "doc_20240315_001",
"source_url": "https://docs.company.com/policy/return.pdf",
"file_name": "退货政策.pdf",
"title": "一、退货政策",
"page_number": 3,
"created_at": "2024-03-15T10:30:00Z",
"updated_at": "2024-03-15T10:30:00Z",
"department": "customer_service",
"access_roles": ["employee", "customer_service", "manager"],
"start_offset": 0,
"end_offset": 58,
"chunk_index": 0
}
}
文本内容还是那段文本,但现在它带着一堆标签:来自哪份文档、在第几页、属于哪个部门、谁能看、在原文的什么位置……
这里的元数据示例写的比较全,实际过程中以能使用到的为准。
这些标签就是元数据。它们不参与语义检索(不会被向量化),但在检索前后的各个环节都能发挥作用。
2.2 元数据和文本内容的关系
可以用一个类比来理解:
文本内容就像一本书的正文,元数据就像这本书的封面、目录、版权页。读者(大模型)主要看正文,但如果你想知道这本书是谁写的、什么时候出版的、属于哪个系列,就得看封面和版权页。
在 RAG 系统里也一样:
- 检索阶段:主要靠文本内容的语义相似度来匹配
- 过滤阶段:靠元数据来判断这个块该不该返回给当前用户
- 展示阶段:靠元数据来生成引用信息(“来源:《退货政策》第 3 页”)
- 维护阶段:靠元数据来定位和修正问题块
企业场景常见的元数据字段
下面按用途把常见的元数据字段分成几类,每类都会说明为什么需要、怎么用、什么时候可以省略。
1. 文档标识类:doc_id、source_url、file_name
1.1 为什么需要文档标识
最基础的需求:知道这个 chunk 来自哪份文档。
用户问“报销流程是什么”,系统回答后,用户可能会追问“能把完整的报销文档发给我吗”。这时候如果 chunk 里记录了 source_url,系统就能直接返回文档链接。
另一个场景是去重和更新。假设你重新上传了一份更新后的《报销流程 v2.0》,系统需要把旧版本的所有 chunk 删掉。如果每个 chunk 都记录了 doc_id,就可以批量删除 doc_id = "报销流程 v1.0" 的所有块。
三个字段的分工:
doc_id:文档的唯一标识符,通常是系统生成的 ID,用于内部管理source_url:文档的访问地址,可以是 HTTP 链接、文件路径、或者内部系统的 URLfile_name:文档的原始文件名,方便人类阅读
1.2 Java 代码示例:给 chunk 添加文档标识
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class DocumentMetadataExample {
public static Document createChunkWithDocMetadata(
String content,
String docId,
String sourceUrl,
String fileName) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("doc_id", docId);
metadata.put("source_url", sourceUrl);
metadata.put("file_name", fileName);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunkContent = "自签收之日起 7 天内,商品未经使用且不影响二次销售的,"
+ "消费者可申请七天无理由退货。";
Document chunk = createChunkWithDocMetadata(
chunkContent,
"doc_20240315_001",
"https://docs.company.com/policy/return.pdf",
"退货政策.pdf"
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Metadata: " + chunk.getMetadata());
}
}
Spring AI 的 Document 类天然支持元数据,构造函数接受一个 Map<String, Object> 类型的 metadata 参数。你只需要把元数据字段放进这个 Map 里,后续存储到向量数据库时会自动带上。
1.3 适用场景与注意事项
| 维度 | 说明 |
|---|---|
| 什么时候必须有 | 几乎所有场景都需要,这是最基础的元数据 |
| 什么时候可以省略 | 如果你的知识库只有一份文档,或者文档来源不重要(比如爬虫抓的公开网页) |
| 注意事项 | doc_id 要保证唯一性;source_url 如果是内网地址,要确保用户有访问权限 |
2. 结构信息类:标题层级(H1/H2/H3)、章节编号、页码
2.1 为什么需要结构信息
很多文档是有层级结构的:一级标题、二级标题、三级标题……每个 chunk 往往属于某个章节。
记录结构信息有两个好处:
一是生成引用时更精确。比如用户问“试用期多久”,系统回答“3 个月”,如果 chunk 里记录了 title = "第二章 员工入职 > 2.1 试用期规定",就可以返回“依据:《员工手册》第二章 2.1 节”。这比只说“来源:员工手册”要清晰得多。
二是检索时可以利用结构信息做排序。比如用户问的是一个概述性问题,那一级标题下的 chunk 可能比三级标题下的更相关;如果问的是细节问题,就反过来。
2.2 如何从原始文档中提取标题层级
这取决于你的文档格式:
- Markdown 文档:标题层级是现成的(
#是 H1,##是 H2) - HTML 文档:可以解析
<h1><h2><h3>标签 - Word 文档:可以通过 Apache POI 读取样式信息,判断哪些段落是标题
- PDF 文档:比较麻烦,需要根据字体大小、加粗等特征推断标题,或者用专门的 PDF 解析库
一个简化的思路:在分块的时候,记录当前块属于哪个最近的标题。比如你按段落切块,切到第 5 段时,往前找最近的一个标题是“2.1 试用期规定”,就把这个标题记录到 chunk 的元数据里。
2.3 Java 代码示例:给 chunk 添加标题层级
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class StructureMetadataExample {
public static Document createChunkWithStructure(
String content,
String h1Title,
String h2Title,
int pageNumber) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("h1_title", h1Title);
metadata.put("h2_title", h2Title);
metadata.put("page_number", pageNumber);
// 组合成完整的标题路径
String fullTitle = h1Title + " > " + h2Title;
metadata.put("title", fullTitle);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunkContent = "新员工试用期为 3 个月,试用期内工资为正式工资的 80%。";
Document chunk = createChunkWithStructure(
chunkContent,
"第二章 员工入职",
"2.1 试用期规定",
5
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Title path: " + chunk.getMetadata().get("title"));
System.out.println("Page: " + chunk.getMetadata().get("page_number"));
}
}
这里用了一个小技巧:除了分别记录 h1_title 和 h2_title,还组合成一个 title 字段,方便后续直接使用。
2.4 适用场景与注意事项
| 维度 | 说明 |
|---|---|
| 什么时候必须有 | 文档有明确的章节结构,且用户关心“这个信息在文档的哪个部分” |
| 什么时候可以省略 | 文档本身没有结构(比如聊天记录、日志文件),或者文档很短不需要章节导航 |
| 注意事项 | 标题层级不要记录太深(H1-H3 通常够用),太深了反而不好展示 |
3. 时间版本类:创建时间、更新时间、生效时间、失效时间
3.1 为什么需要时间版本信息
企业的知识是会变化的。今年的报销政策和去年不一样,上个月的产品手册和这个月不一样。如果不记录时间信息,系统可能会把过时的内容返回给用户。
四个时间字段的含义:
created_at:这个 chunk 是什么时候创建的(通常是文档上传到系统的时间)updated_at:这个 chunk 最后一次更新是什么时候effective_date:这条规则从什么时候开始生效(比如“新版报销政策自 2024 年 4 月 1 日起执行”)expiration_date:这条规则什么时候失效(比如“本优惠活动截止到 2024 年 12 月 31 日”)
前两个(created_at、updated_at)是系统自动记录的,后两个(effective_date、expiration_date)通常需要从文档内容中提取,或者在上传文档时手动标注。
一个典型的应用场景:用户问“现在的报销额度是多少”,系统检索时可以过滤掉 expiration_date 早于当前日期的 chunk,只返回当前有效的规则。
3.2 Java 代码示例:给 chunk 添加时间版本
import org.springframework.ai.document.Document;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.HashMap;
import java.util.Map;
public class TimeMetadataExample {
public static Document createChunkWithTime(
String content,
LocalDateTime createdAt,
LocalDateTime effectiveDate,
LocalDateTime expirationDate) {
Map<String, Object> metadata = new HashMap<>();
DateTimeFormatter formatter = DateTimeFormatter.ISO_LOCAL_DATE_TIME;
metadata.put("created_at", createdAt.format(formatter));
if (effectiveDate != null) {
metadata.put("effective_date", effectiveDate.format(formatter));
}
if (expirationDate != null) {
metadata.put("expiration_date", expirationDate.format(formatter));
}
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunkContent = "员工差旅住宿费用报销上限:一线城市 500 元/晚,二线城市 300 元/晚。";
Document chunk = createChunkWithTime(
chunkContent,
LocalDateTime.now(),
LocalDateTime.of(2024, 4, 1, 0, 0),
LocalDateTime.of(2024, 12, 31, 23, 59)
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Effective from: " + chunk.getMetadata().get("effective_date"));
System.out.println("Expires at: " + chunk.getMetadata().get("expiration_date"));
}
}
时间字段建议用 ISO 8601 格式(2024-04-01T00:00:00),这是国际标准,各种编程语言和数据库都能正确解析。
3.3 适用场景与注意事项
| 维度 | 说明 |
|---|---|
| 什么时候必须有 | 知识会随时间变化的场景(政策文档、产品手册、活动规则) |
| 什么时候可以省略 | 知识相对稳定,不太会过时(比如��编程语言的基础语法、数学公式) |
| 注意事项 | effective_date 和 expiration_date 不是所有文档都有,不要强行填充;检索时要考虑时区问题 |
4. 权限控制类:部门标签、角色标签、ACL(访问控制列表)
4.1 什么是 ACL,为什么需要它
ACL 是 Access Control List(访问控制列表)的缩写。简单说,就是一个列表,记录了“谁能访问这个资源”。
在 RAG 系统里,每个 chunk 可以带一个 ACL,记录哪些角色、哪些部门、哪些用户能看到这个块。检索的时候,系统会先检查当前用户的身份,然后只返回他有权限看的 chunk。
举个例子:
{
"content": "2024 年公司整体营收目标为 10 亿元,其中...",
"metadata": {
"access_roles": ["ceo", "cfo", "finance_manager"],
"access_departments": ["finance", "executive"],
"sensitivity_level": "confidential"
}
}
这个 chunk 只有 CEO、CFO、财务经理这几个角色,或者财务部、高管部门的人能看到。普通员工检索时,即使这个 chunk 的语义相似度很高,也会被过滤掉。
权限控制有几种常见的粒度:
- 基于角色(Role-Based):比如
access_roles: ["manager", "hr"],只有经理和 HR 能看 - 基于部门(Department-Based):比如
access_departments: ["finance", "legal"],只有财务部和法务部能看 - 基于用户(User-Based):比如
access_users: ["user_001", "user_002"],只有特定用户能看 - 基于敏感级别(Sensitivity-Based):比如
sensitivity_level: "public"/"internal"/"confidential"/"secret",不同级别的用户能看不同敏感度的内容
实际项目中,通常会组合使用。比如一个 chunk 标记为 sensitivity_level: "confidential",同时指定 access_departments: ["finance"],意思是“这是机密信息,只有财务部能看”。
4.2 Java 代码示例:给 chunk 添加权限标签
import org.springframework.ai.document.Document;
import java.util.*;
public class AccessControlExample {
public static Document createChunkWithACL(
String content,
List<String> accessRoles,
List<String> accessDepartments,
String sensitivityLevel) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("access_roles", accessRoles);
metadata.put("access_departments", accessDepartments);
metadata.put("sensitivity_level", sensitivityLevel);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunkContent = "2024 年公司整体营收目标为 10 亿元,净利润目标为 2 亿元。";
Document chunk = createChunkWithACL(
chunkContent,
Arrays.asList("ceo", "cfo", "finance_manager"),
Arrays.asList("finance", "executive"),
"confidential"
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Access roles: " + chunk.getMetadata().get("access_roles"));
System.out.println("Sensitivity: " + chunk.getMetadata().get("sensitivity_level"));
}
}
4.3 检索时如何根据权限过滤
权限过滤通常发生在检索阶段。大多数向量数据库(如 Milvus、Qdrant、Weaviate)都支持元数据过滤,你可以在检索时加上过滤条件。
伪代码示例:
// 假设当前用户是财务部的普通员工
String userRole = "employee";
String userDepartment = "finance";
// 构造过滤条件:只检索用户有权限看的 chunk
Map<String, Object> filter = new HashMap<>();
filter.put("access_roles", userRole); // 或者
filter.put("access_departments", userDepartment);
// 执行检索(具体 API 取决于你用的向量数据库)
List<Document> results = vectorStore.search(
query,
topK,
filter // 传入过滤条件
);
不同向量数据库的过滤语法不太一样,但核心思路是一致的:在向量相似度检索的基础上,叠加元数据过滤条件。
4.4 适用场景与注意事项
| 维度 | 说明 |
|---|---|
| 什么时候必须有 | 企业内部知识库,不同部门/角色的知识权限不同 |
| 什么时候可以省略 | 面向公众的知识库(如产品帮助文档),所有人都能看 |
| 注意事项 | 权限设计要和公司的权限体系对齐;过滤逻辑要在检索层实现,不能只在展示层做(否则有安全风险) |
5. 位置追溯类:原文位置(start_offset、end_offset)、chunk_index
5.1 为什么需要位置信息
当你发现某个 chunk 的内容有问题,需要回到原文去修正时,位置信息就派上用场了。
start_offset 和 end_offset 记录了这个 chunk 在原文中的字符位置。比如 start_offset: 120, end_offset: 250,意思是这个 chunk 对应原文的第 120 到 250 个字符。
chunk_index 是这个 chunk 在所有 chunk 中的序号。比如一份文档被切成了 10 个 chunk,第一个 chunk 的 chunk_index 是 0,第二个是 1,以此类推。
有了这些信息,你可以:
- 快速定位到原文的具体位置,方便人工审核和修正
- 在展示答案时,高亮显示原文中的相关段落
- 分析相邻 chunk 的关系(比如检索到了 chunk 5,可以顺便看看 chunk 4 和 chunk 6 的内容)
5.2 Java 代码示例:记录 chunk 的原文位置
import org.springframework.ai.document.Document;
import java.util.*;
public class PositionMetadataExample {
/**
* 对文本进行分块,并记录每个 chunk 的位置信息
*/
public static List<Document> chunkWithPosition(
String fullText,
int chunkSize,
int overlap) {
List<Document> chunks = new ArrayList<>();
int step = chunkSize - overlap;
int start = 0;
int chunkIndex = 0;
while (start < fullText.length()) {
int end = Math.min(start + chunkSize, fullText.length());
String chunkContent = fullText.substring(start, end);
Map<String, Object> metadata = new HashMap<>();
metadata.put("start_offset", start);
metadata.put("end_offset", end);
metadata.put("chunk_index", chunkIndex);
metadata.put("total_length", fullText.length());
chunks.add(new Document(chunkContent, metadata));
start += step;
chunkIndex++;
}
return chunks;
}
public static void main(String[] args) {
String fullText = "自签收之日起 7 天内,商品未经使用且不影响二次销售的,"
+ "消费者可申请�七天无理由退货。生鲜食品、定制商品、贴身衣物等"
+ "特殊品类不适用此规则,具体以商品详情页标注为准。";
List<Document> chunks = chunkWithPosition(fullText, 40, 10);
for (Document chunk : chunks) {
System.out.println("=== Chunk " + chunk.getMetadata().get("chunk_index") + " ===");
System.out.println("Content: " + chunk.getContent());
System.out.println("Position: " + chunk.getMetadata().get("start_offset")
+ " - " + chunk.getMetadata().get("end_offset"));
System.out.println();
}
}
}
这段代码在分块的同时,记录了每个 chunk 的起止位置和序号。后续如果需要回溯,直接用 start_offset 和 end_offset 就能在原文中定位。
5.3 适用场景与注意事项
| 维度 | 说明 |
|---|---|
| 什么时候必须有 | 需要人工审核和修正 chunk 的场景;需要在原文中高亮显示检索结果的场景 |
| 什么时候可以省略 | 原文已经不可访问(比如爬虫抓的网页,原网页可能已经删除);不需要回溯到原文 |
| 注意事项 | offset 是按字符数计算的,如果原文是多字节编码(如 UTF-8),要注意字符和字节的区别 |
6. 业务自定义类:产品类型、业务线、优先级等
6.1 根据业务需求扩展元数据
前面讲的都是通用的元数据字段,但每个业务场景可能还有自己特殊的需求。
比如电商场景,你可能需要给 chunk 打上商品类目标签:
{
"content": "生鲜食品不支持七天无理由退货。",
"metadata": {
"product_category": "fresh_food",
"policy_type": "return"
}
}
这样用户问“生鲜能退货吗”,系统可以优先检索 product_category: "fresh_food" 的 chunk。
再比如技术文档场景,你可能需要标记文档的技术栈:
{
"content": "使用 @Autowired 注解可以实现依赖注��入。",
"metadata": {
"tech_stack": "spring",
"doc_type": "tutorial",
"difficulty": "beginner"
}
}
用户问“Spring 怎么做依赖注入”,系统可以过滤 tech_stack: "spring" 的 chunk。
6.2 Java 代码示例:添加自定义元数据
import org.springframework.ai.document.Document;
import java.util.*;
public class CustomMetadataExample {
public static Document createChunkWithCustomMetadata(
String content,
String productCategory,
String policyType,
int priority) {
Map<String, Object> metadata = new HashMap<>();
// 通用元数据
metadata.put("doc_id", "policy_001");
metadata.put("created_at", "2024-03-15T10:00:00Z");
// 业务自定义元数据
metadata.put("product_category", productCategory);
metadata.put("policy_type", policyType);
metadata.put("priority", priority); // 优先级,用于排序
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunkContent = "生鲜食品、定制商品、贴身衣物等特殊品类不适用七天无理由退货。";
Document chunk = createChunkWithCustomMetadata(
chunkContent,
"fresh_food",
"return",
1 // 高优先级
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Product category: " + chunk.getMetadata().get("product_category"));
System.out.println("Priority: " + chunk.getMetadata().get("priority"));
}
}
自定义元数据的设计原则:
- 只加对检索、过滤、排序有帮助的字段,不要什么都往里塞
- 字段名要有业务含义,不要用
field1、field2这种 - 如果某个字段只有少数 chunk 需要,可以设为可选字段(不是所有 chunk 都必须有)
元数据的三大核心应用场景
前面讲了元数据有哪些字段,现在看看这些字段在实际场景中怎么用。
1. 回答可引用:让 AI 的回答有据可查
1.1 场景描述
用户问:“新员工试用期多久?”
系统回答:“新员工试用期为 3 个月。”
用户追问:“这个规定在哪份文档里?”
如果 chunk 里记录了文档来源和章节信息,系统可以这样回答:
新员工试用期为 3 个月。
依据:《员工手册》第二章“员工入职” > 2.1 节“试用期规定”,第 5 页
这就是回答可引用。用户不仅得到了答案,还知道答案的出处,可以点击链接查看完整的原文。
1.2 实现思路:从 chunk 元数据生成引用信息
核心思路:检索到相关 chunk 后,从元数据中提取 file_name、title、page_number、source_url 等字段,拼接成引用信息。
流程图:
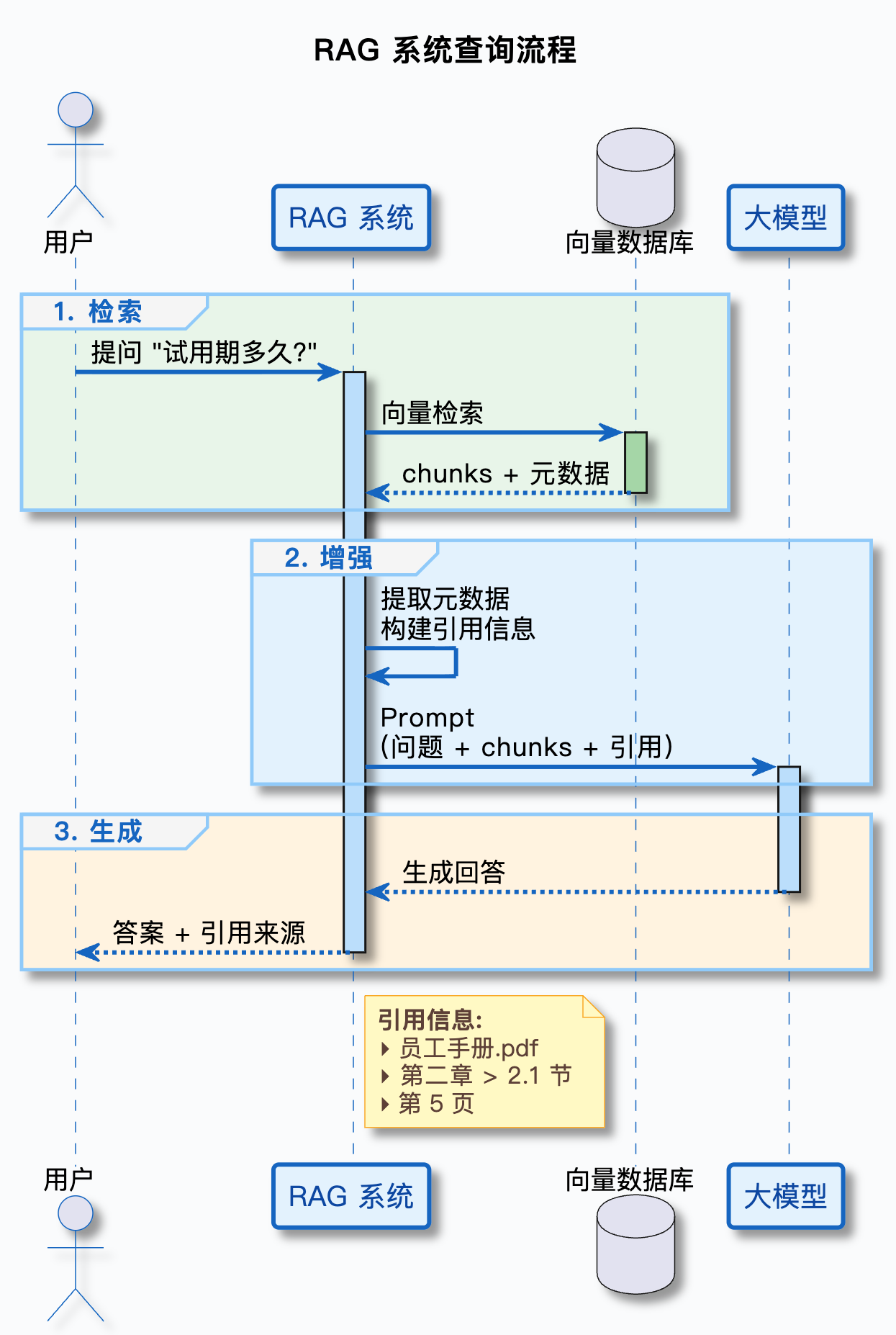
1.3 Java 代码示例:完整的引用生成流程
import org.springframework.ai.document.Document;
import java.util.*;
public class CitationExample {
/**
* 从 chunk 元数据生成引用信息
*/
public static String generateCitation(Document chunk) {
Map<String, Object> metadata = chunk.getMetadata();
String fileName = (String) metadata.get("file_name");
String title = (String) metadata.get("title");
Integer pageNumber = (Integer) metadata.get("page_number");
String sourceUrl = (String) metadata.get("source_url");
StringBuilder citation = new StringBuilder();
citation.append("**依据**: ");
if (fileName != null) {
citation.append("《").append(fileName).append("》");
}
if (title != null) {
citation.append(" ").append(title);
}
if (pageNumber != null) {
citation.append(",第 ").append(pageNumber).append(" 页");
}
if (sourceUrl != null) {
citation.append("\n\n[查看原文](").append(sourceUrl).append(")");
}
return citation.toString();
}
public static void main(String[] args) {
// 模拟一个检索到的 chunk
Map<String, Object> metadata = new HashMap<>();
metadata.put("file_name", "员工手册.pdf");
metadata.put("title", "第二章 员工入职 > 2.1 试用期规定");
metadata.put("page_number", 5);
metadata.put("source_url", "https://docs.company.com/handbook.pdf#page=5");
Document chunk = new Document(
"新员工试用期为 3 个月,试用期内工资为正式工资的 80%。",
metadata
);
String citation = generateCitation(chunk);
System.out.println("Answer: " + chunk.getContent());
System.out.println("\n" + citation);
}
}
输出:
Answer: 新员工试用期为 3 个月,试用期内工资为正式工资的 80%。
**依据**: 《员工手册.pdf》 第二章 员工入职 > 2.1 试用期规定,第 5 页
[查看原文](https://docs.company.com/handbook.pdf#page=5)
1.4 效果展示
有了引用信息,用户体验会有质的提升:
- 增强可信度:用户知道答案不是 AI 编的,而是有文档依据的
- 方便核查:用户可以点击链接查看完整原文,确认理解没有偏差
- 减少纠纷:在涉及制度、合规的场景,有明确的引用可以避免扯皮
2. 权限过滤:不同员工看不同知识
2.1 场景描述
公司的知识库里有各种文档:
- 产品部的需求文档(只有产品部和技术部能看)
- 人事部的薪酬政策(只有人事部和管理层能看)
- 财务部的预算数据(只有财务部和高管能看)
- 公共的员工手册(所有人都能看)
技术部的小李问:“公司的年终奖怎么算?”
如果不做权限过滤,系统可能会把人事部的内部文档返回给他,泄露敏感信息。
正确的做法:检索时根据小李的身份(技术部、普通员工),只返回他有权限看的 chunk。如果没有匹配的公开信息,就回答“抱歉,这个问题涉及内部信息,请咨询人事部”。
2.2 实现思路:检索前根据用户角色过滤 chunk
流程图:
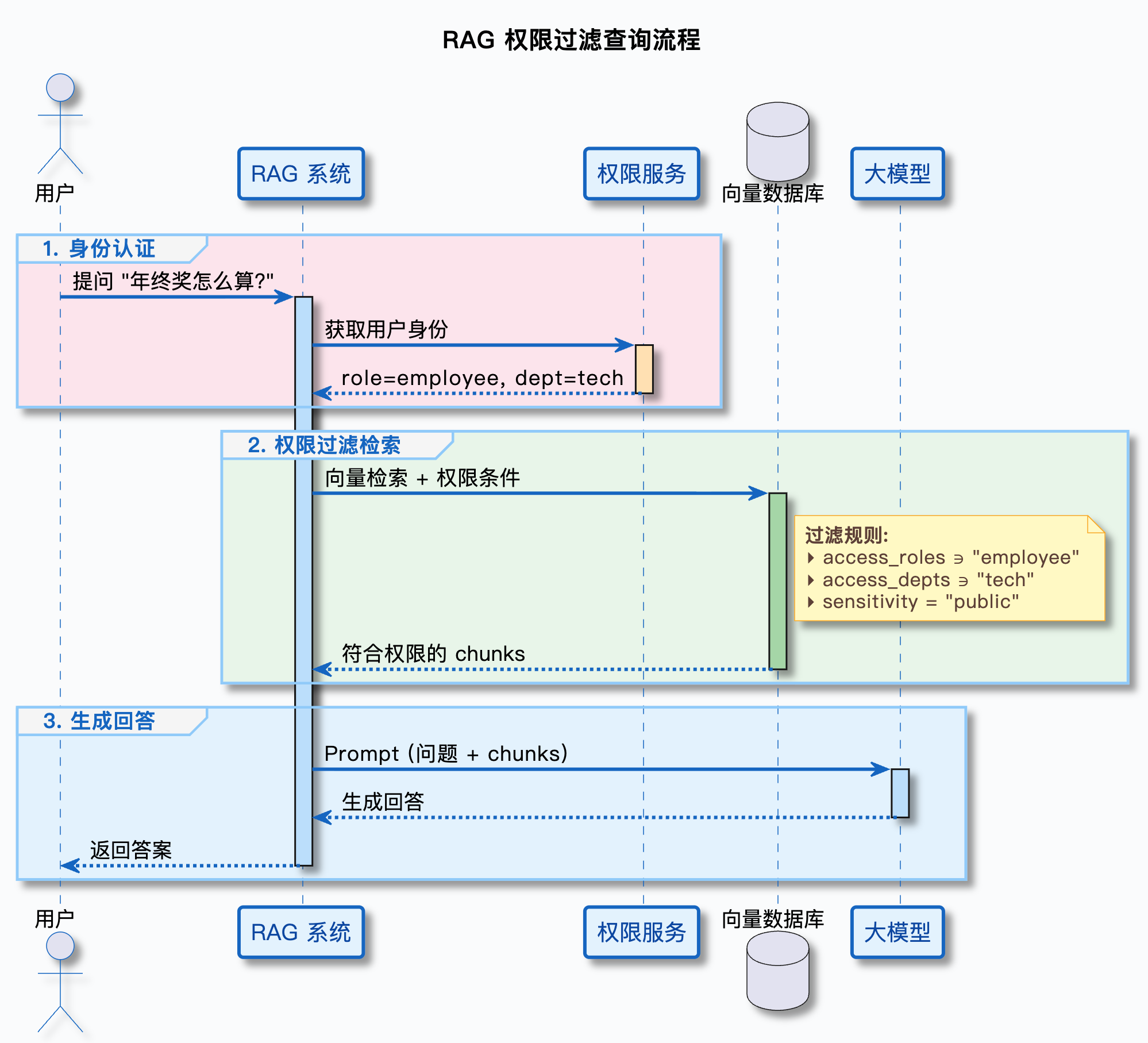
关键点:权限过滤要在向量数据库层面做,而不是检索完再过滤。这样可以避免敏感信息被加载到内存中。
2.3 Java 代码示例:基于权限的检索过滤
import org.springframework.ai.document.Document;
import java.util.*;
import java.util.stream.Collectors;
public class PermissionFilterExample {
/**
* 模拟向量数据库中的 chunks
*/
private static List<Document> mockChunks() {
List<Document> chunks = new ArrayList<>();
// Chunk 1: 公开信息
Map<String, Object> meta1 = new HashMap<>();
meta1.put("sensitivity_level", "public");
meta1.put("access_roles", Arrays.asList("employee"));
chunks.add(new Document("员工手册规定,所有员工享有带薪年假。", meta1));
// Chunk 2: 人事部内部信息
Map<String, Object> meta2 = new HashMap<>();
meta2.put("sensitivity_level", "confidential");
meta2.put("access_departments", Arrays.asList("hr", "executive"));
chunks.add(new Document("年终奖为月薪的 2-6 倍,根据绩效等级确定。", meta2));
// Chunk 3: 技术部可见信息
Map<String, Object> meta3 = new HashMap<>();
meta3.put("sensitivity_level", "internal");
meta3.put("access_departments", Arrays.asList("tech", "product"));
chunks.add(new Document("技术部员工可申请远程办公,每周最多 2 天。", meta3));
return chunks;
}
/**
* 根据用户权限过滤 chunks
*/
public static List<Document> filterByPermission(
List<Document> chunks,
String userRole,
String userDepartment) {
return chunks.stream()
.filter(chunk -> hasPermission(chunk, userRole, userDepartment))
.collect(Collectors.toList());
}
/**
* 判断用户是否有权限访问某个 chunk
*/
private static boolean hasPermission(
Document chunk,
String userRole,
String userDepartment) {
Map<String, Object> metadata = chunk.getMetadata();
// 公开信息,所有人都能看
String sensitivity = (String) metadata.get("sensitivity_level");
if ("public".equals(sensitivity)) {
return true;
}
// 检查角色权限
List<String> accessRoles = (List<String>) metadata.get("access_roles");
if (accessRoles != null && accessRoles.contains(userRole)) {
return true;
}
// 检查部门权限
List<String> accessDepts = (List<String>) metadata.get("access_departments");
if (accessDepts != null && accessDepts.contains(userDepartment)) {
return true;
}
return false;
}
public static void main(String[] args) {
List<Document> allChunks = mockChunks();
// 场景 1: 技术部普通员工
System.out.println("=== 技术部员工小李能看到的内容 ===");
List<Document> techResults = filterByPermission(allChunks, "employee", "tech");
techResults.forEach(chunk -> System.out.println("- " + chunk.getContent()));
System.out.println("\n=== 人事部经理能看到的内容 ===");
List<Document> hrResults = filterByPermission(allChunks, "manager", "hr");
hrResults.forEach(chunk -> System.out.println("- " + chunk.getContent()));
}
}
输出:
=== 技术部员工小李能看到的内容 ===
- 员工手册规定,所有员工享有带薪年假。
- 技术部员工可申请远程办公,每周最多 2 天。
=== 人事部经理能看到的内容 ===
- 员工手册规定,所有员工享有带薪年假。
- 年终奖为月薪的 2-6 倍,根据绩效等级确定。
可以看到,技术部员工看不到年终奖的具体算法(因为那是人事部的机密信息),但人事部经理可以看到。
2.4 效果展示
权限过滤的价值:
- 数据安全:敏感信息不会泄露给无权限的用户
- 合规要求:满足企业的信息安全和合规要求(如 GDPR、等保)
- 用户体验:用户只看到和自己相关的信息,不会被无关内容干扰
3. 回溯与纠错:发现错答能定位到源头
3.1 场景描述
用户反馈:“系统告诉我报销需要贴发票,但实际上新流程已经改成线上提交了,不用贴纸质发票。”
技术团队需要:
- 找到返回错误信息的那个 chunk
- 定位到原始文档的具体位置
- 修正或删除这个 chunk
- 检查是否还有其他相关的过时 chunk 需要一起更新
如果 chunk 里记录了 doc_id、chunk_index、start_offset、created_at 等信息,这个过程就会简单很多。
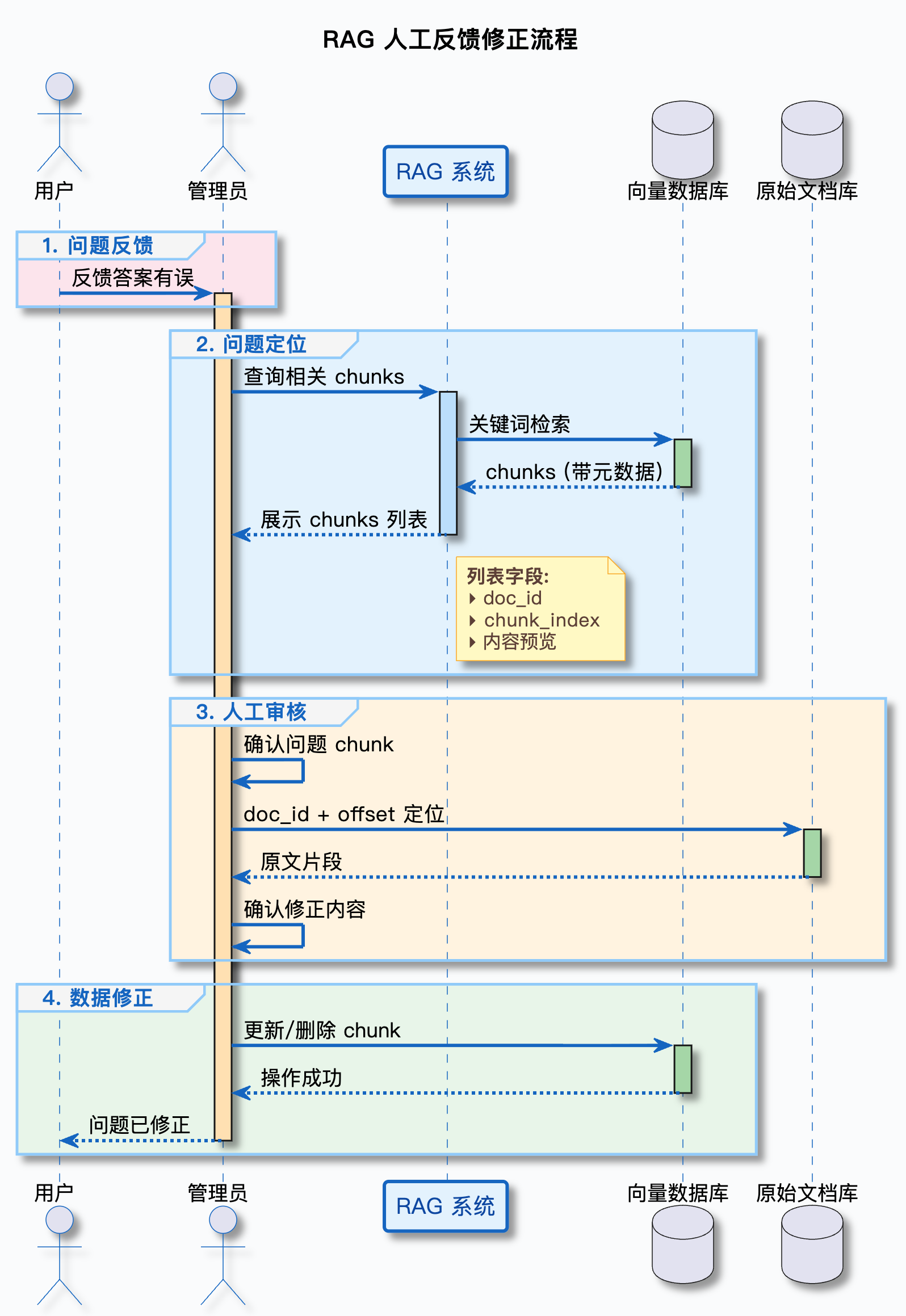
3.2 实现思路:通过元数据定位问题 chunk
流程图:
3.3 Java 代码示例:错误 chunk 的定位与修正
import org.springframework.ai.document.Document;
import java.util.*;
public class ErrorTrackingExample {
/**
* 根据关键词查找可能有问题的 chunks
*/
public static List<Document> findChunksByKeyword(
List<Document> allChunks,
String keyword) {
List<Document> results = new ArrayList<>();
for (Document chunk : allChunks) {
if (chunk.getContent().contains(keyword)) {
results.add(chunk);
}
}
return results;
}
/**
* 展示 chunk 的详细信息,方便人工审核
*/
public static void displayChunkDetails(Document chunk) {
Map<String, Object> metadata = chunk.getMetadata();
System.out.println("=== Chunk 详情 ===");
System.out.println("内容: " + chunk.getContent());
System.out.println("文档 ID: " + metadata.get("doc_id"));
System.out.println("文件名: " + metadata.get("file_name"));
System.out.println("Chunk 序号: " + metadata.get("chunk_index"));
System.out.println("原文位置: " + metadata.get("start_offset")
+ " - " + metadata.get("end_offset"));
System.out.println("创建时间: " + metadata.get("created_at"));
System.out.println("来源: " + metadata.get("source_url"));
System.out.println();
}
/**
* 模拟更新 chunk(实际项目中需要调用向量数据库的 API)
*/
public static void updateChunk(Document chunk, String newContent) {
System.out.println(">>> 更新 Chunk");
System.out.println("原内容: " + chunk.getContent());
System.out.println("新内容: " + newContent);
System.out.println("文档 ID: " + chunk.getMetadata().get("doc_id"));
System.out.println("Chunk 序号: " + chunk.getMetadata().get("chunk_index"));
System.out.println();
}
public static void main(String[] args) {
// 模拟知识库中的 chunks
List<Document> allChunks = new ArrayList<>();
Map<String, Object> meta1 = new HashMap<>();
meta1.put("doc_id", "doc_reimbursement_v1");
meta1.put("file_name", "报销流程.pdf");
meta1.put("chunk_index", 2);
meta1.put("start_offset", 150);
meta1.put("end_offset", 220);
meta1.put("created_at", "2023-06-01T10:00:00Z");
meta1.put("source_url", "https://docs.company.com/reimbursement_v1.pdf");
allChunks.add(new Document(
"报销时需打印发票并贴在报销单上,提交给财务部审核。",
meta1
));
Map<String, Object> meta2 = new HashMap<>();
meta2.put("doc_id", "doc_reimbursement_v2");
meta2.put("file_name", "报销流程_v2.pdf");
meta2.put("chunk_index", 1);
meta2.put("start_offset", 80);
meta2.put("end_offset", 140);
meta2.put("created_at", "2024-01-15T14:00:00Z");
meta2.put("source_url", "https://docs.company.com/reimbursement_v2.pdf");
allChunks.add(new Document(
"报销时在系统中上传电子发票,无需打印纸质版。",
meta2
));
// 场景:用户反馈"贴发票"的说法已经过时
System.out.println(">>> 用户反馈:系统说要贴发票,但新流程不需要了\n");
// 1. 查找包含"发票"的 chunks
List<Document> suspectedChunks = findChunksByKeyword(allChunks, "发票");
System.out.println("找到 " + suspectedChunks.size() + " 个相关 chunks:\n");
// 2. 展示详情,供人工审核
for (Document chunk : suspectedChunks) {
displayChunkDetails(chunk);
}
// 3. 人工确认第一个 chunk 是过时的,需要删除或更新
Document outdatedChunk = suspectedChunks.get(0);
System.out.println(">>> 确认 chunk_index=2 的内容已过时,准备删除\n");
// 4. 执行删除(实际项目中调用向量数据库的删除 API)
System.out.println(">>> 删除过时 chunk:");
System.out.println("文档 ID: " + outdatedChunk.getMetadata().get("doc_id"));
System.out.println("Chunk 序号: " + outdatedChunk.getMetadata().get("chunk_index"));
System.out.println("\n>>> 操作完成,问题已修正");
}
}
输出:
>>> 用户反馈:系统说要贴发票,但新流程不需要了
找到 2 个相关 chunks:
=== Chunk 详情 ===
内容: 报销时需打印发票并贴在报销单上,提交给财务部审核。
文档 ID: doc_reimbursement_v1
文件名: 报销流程.pdf
Chunk 序号: 2
原文位置: 150 - 220
创建时间: 2023-06-01T10:00:00Z
来源: https://docs.company.com/reimbursement_v1.pdf
=== Chunk 详情 ===
内容: 报销时在系统中上传电子发票,无需打印纸质版。
文档 ID: doc_reimbursement_v2
文件名: 报销流程_v2.pdf
Chunk 序号: 1
原文位置: 80 - 140
创建时间: 2024-01-15T14:00:00Z
来源: https://docs.company.com/reimbursement_v2.pdf
>>> 确认 chunk_index=2 的内容已过时,准备删除
>>> 删除过时 chunk:
文档 ID: doc_reimbursement_v1
Chunk 序号: 2
>>> 操作完成,问题已修正
3.4 效果展示
回溯与纠错的价值:
- 快速定位:通过元数据快速找到问题 chunk,不用在几千个块里大海捞针
- 精准修正:知道 chunk 的来源和位置,可以回到原文确认,避免误删
- 批量更新:如果一份文档有多个 chunk,可以根据
doc_id批量更新或删除 - 版本管理:通过
created_at和updated_at可以追踪知识的演变历史
元数据设计的最佳实践
1. 元数据字段不是越多越好
新手常犯的错误:给每个 chunk 加一堆元数据字段,恨不得把能想到的信息都塞进去。
问题在于:
- 存储成本:元数据也要占存储空间,字段太多会显著增加存储成本
- 维护成本:字段越多,维护越麻烦。每次上传文档都要填一堆字段,容易出错
- 检索性能:有些向量数据库在元数据过滤时,字段越多性能越差
一个实用的原则:只加对检索、过滤、展示有实际帮助的字段。
问自己三个问题:
- 这个字段会用于检索过滤吗?(比如权限过滤、时间过滤)
- 这个字段会展示给用户吗?(比如引用信息)
- 这个字段会用于运维管理吗?(比如定位问题 chunk)
如果三个问题的答案都是不会,那这个字段就不要加。
2. 元数据的粒度要和业务场景匹配
不同的业务场景,对元数据的粒度要求不一样。
场景 1:面向公众的产品帮助文档
- 不需要权限控制(所有人都能看)
- 不需要部门标签(没有部门概念)
- 需要文档标识和章节信息(方便引用)
推荐的元数据:
{
"doc_id": "...",
"file_name": "...",
"title": "...",
"source_url": "..."
}
场景 2:企业内部知识库
- 需要权限控制(不同部门看不同内容)
- 需要时间版本(知识会更新)
- 需要位置追溯(方便纠错)
推荐的元数据:
{
"doc_id": "...",
"file_name": "...",
"title": "...",
"source_url": "...",
"access_departments": [...],
"access_roles": [...],
"created_at": "...",
"updated_at": "...",
"start_offset": ...,
"end_offset": ...,
"chunk_index": ...
}
场景 3:电商客服知识库
- 需要商品类目标签(不同类目的规则不同)
- 需要政策类型标签(退货、换货、物流等)
- 需要优先级(某些规则优先级更高)
推荐的元数据�:
{
"doc_id": "...",
"file_name": "...",
"product_category": "...",
"policy_type": "...",
"priority": ...,
"effective_date": "...",
"expiration_date": "..."
}
3. 元数据的维护成本要考虑进去
有些元数据是系统自动生成的(如 created_at、chunk_index、start_offset),维护成本低。
有�些元数据需要人工标注(如 access_roles、product_category、effective_date),维护成本高。
如果你的知识库有几千份文档,每份文档都要人工标注十几个字段,这个工作量是不现实的。
一个折中的方案:分层标注。
- 文档级标注:在上传文档时,标注文档级的元数据(如
access_departments、doc_type),这些元数据会自动继承给文档下的所有 chunk - Chunk 级标注:系统自动生成 chunk 级的元数据(如
chunk_index、start_offset) - 按需标注:只对重要的、高频访问的文档做精细化标注(如
effective_date、priority)
这样可以在保证元数据质量的同时,把维护成本控制在可接受的范围内。
4. 元数据参考表
| 元数据字段 | 用途 | 适用场景 | 维护成本 | 优先级 |
|---|---|---|---|---|
| doc_id | 文档标识,用于批量管理 | 几乎所有场景 | 低(系统生成) | 必须 |
| file_name | 展示给用户,生成引用 | 几乎所有场景 | 低(系统生成) | 必须 |
| source_url | 提供原文链接 | 需要回溯原文的场景 | 低(系统生成) | 推荐 |
| title / h1_title / h2_title | 生成引用,展示章节信息 | 有结构的文档 | 中(需要解析) | 推荐 |
| page_number | 生成引用,定位原文 | PDF 等有页码的文档 | 中(��需要解析) | 推荐 |
| created_at / updated_at | 版本管理,追踪变更 | 知识会更新的场景 | 低(系统生成) | 推荐 |
| effective_date / expiration_date | 过滤过时内容 | 有时效性的知识(政策、活动) | 高(需要人工标注) | 可选 |
| access_roles / access_departments | 权限过滤 | 企业内部知识库 | 高(需要人工标注) | 必须(如果有权限需求) |
| sensitivity_level | 权限过滤 | 企业内部知识库 | 中(可以按文档标注) | 推荐(如果有权限需求) |
| start_offset / end_offset | 定位原文,纠错 | 需要人工审核和修正的场景 | 低(系统生成) | 推荐 |
| chunk_index | 定位 chunk,分析相邻块 | 需要管理 chunk 的场景 | 低(系统生成) | 推荐 |
| product_category / policy_type 等 | 业务过滤和排序 | 有明确业务分类的场景 | 中到高(取决于分类复杂度) | 可选 |
使用建议:
- 必须:这些字段几乎所有场景都需要,优先实现
- 推荐:这些字段能显著提升用户体验或运维效率,建议实现
- 可选:这些字段针对特定场景,根据实际需求决定是否实现
小结与下一篇预告
元数据是 RAG 系统从“能用“到“好用“的关键。只有文本内容的 chunk 只能做基础的语义检索,加上元数据之后,系统才能做权限过滤、生成引用、快速纠错。
企业场景中,三类元数据最重要:
- 文档标识类(doc_id、source_url、file_name):知道 chunk 从哪来,方便管理和引用
- 权限控制类(access_roles、access_departments、sensitivity_level):不同员工看不同知识,保证数据安全
- 位置追溯类(start_offset、end_offset、chunk_index):发现问题能快速定位和修正
其他元数据(标题层级、时间版本、业务自定义)根据实际场景选择性添加。记住一个原则:元数据不是越多越好,只加对检索、过滤、展示有实际帮助的字段。
元数据设计完成后,每个 chunk 就从“一段文本“变成了“一段带标签的文本”。但这些文本还是人类能读懂的自然语言,计算机要做相似度检索,需要把它们转成数字表示——这就是向量化(Embedding)。