如何调用大模型
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
上一篇咱们搞清楚了大模型是什么——参数量、Token、上下文窗口、Temperature 这些核心概念,以及 Chat 模型和基座模型的区别。最后留了一个悬念:开发者需要通过 API 调用大模型,才能把它集成到自己的系统里。
这一篇,咱们动手。
这篇结束后,你会用自己写的 Java 程序和大模型对话——发一个问题过去,拿到一个回答回来,就像调用一个普通的 HTTP 接口一样。而且你会掌握两种调用方式:非流式(一次性拿到完整回答)和流式(像 ChatGPT 那样逐字输出)。
在写代码之前,有一件事必须先搞清楚:你要发什么格式的请求,会收到什么格式的响应。这就是 OpenAI 接口协议。
OpenAI 接口��协议:大模型 API 的“普通话”
1. 为什么要先讲 OpenAI 协议
你可能会问:我们后面用的是 SiliconFlow 平台上的 Qwen 模型,为什么要讲 OpenAI 的协议?
原因很简单:OpenAI 的 Chat Completions API 已经成了大模型 API 的事实标准。就像 HTTP 是 Web 世界的通用协议一样,OpenAI 的接口格式是大模型 API 世界的“普通话”。
国内的 DeepSeek、通义千问、智谱 GLM、SiliconFlow,国外的 Anthropic(Claude)、Google(Gemini)——几乎所有主流厂商都提供了兼容 OpenAI 协议的 API 接口(截止 2025 年 2 月,Anthropic 和 Google 都已经有了自己的原生 API 协议,但同时也提供了 OpenAI 兼容层)。这意味着什么?你只需要学一套协议,就能调用市面上几乎所有的大模型。换模型的时候,改一下 baseURL 和 API Key 就行,代码逻辑一行不用动。
所以这套协议值得你花时间搞清楚,后续系列中所有的 API 调用(Chat API、Embedding API、Reranker API)都建立在这个基础上。
2. 请求格式详解
调用大模型 API,本质上就是发一个 HTTP POST 请求。请求体是一个 JSON,长这样:
{
"model": "Qwen/Qwen3-32B",
"messages": [
{
"role": "system",
"content": "你是一个专业的电商客服助手,只回答和退货、换货、物流相关的问题。"
},
{
"role": "user",
"content": "买了一周的东西还能退吗?"
}
],
"temperature": 0.1,
"max_tokens": 512,
"stream": false
}
下面逐个字段讲清楚。
2.1 model:指定要调用的模型
model 字段告诉平台你要用哪个模型来处理这次请求。不同平台的模型 ID 格式可能不同:
| 平台 | 模型 ID 示例 | 说明 |
|---|---|---|
| SiliconFlow | Qwen/Qwen3-32B | 厂商/模型名 ��格式 |
| OpenAI | gpt-4o | 直接用模型名 |
| DeepSeek | deepseek-chat | 直接用模型名 |
本系列统一使用 SiliconFlow 平台上的 Qwen/Qwen3-32B,中文效果好,适合学习和实验。该模型为付费模型,但价格很低,充值几块钱就够实验很久。
2.2 messages:对话消息数组
messages 是整个请求中最核心的字段。它是一个数组,里面的每条消息都有两个属性:role(角色)和 content(内容)。
模型不是只看你当前这一句话,而是看整个 messages 数组。你可以把它理解为一段对话记录——模型会根据这段完整的对话记录来生成回答。
2.3 messages 中的角色机制
messages 数组中的每条消息都有一个 role,一共有三种角色:
system(系统角色)
系统消息用来定义模型的行为规则,相当于给模型一份工作手册。模型会始终遵守系统消息中的指令。
比如你设置了 "role": "system", "content": "你是一个专业的电商客服助手,只回答和退货、换货、物流相关的问题",那么当用户问“今天天气怎么样”时,模型会拒绝回答,因为这不在它的“工作范围”内。
system 消息在 RAG 系统中非常重要——后续我们会通过 system 消息告诉模型"根据以下参考资料回答用户的问题,如果资料中没有相关信息,请如实告知"。
user(用户角色)
用户消息就是用户的输入,也就是用户问的问题。
assistant(助手角色)
助手消息是模型之前的回答。它的作用是构建多轮对话的上下文。
举个例子,一段多轮对话的 messages 数组长这样:
{
"messages": [
{"role": "system", "content": "你是一个电商客服助手"},
{"role": "user", "content": "你们支持七天无理由退货吗?"},
{"role": "assistant", "content": "支持的。自签收之日起7天内,商品未使用且不影响二次销售的,可以申请七天无理由退货。"},
{"role": "user", "content": "那运费谁出?"}
]
}
模型看到这个数组,就知道之前聊过退货的话题,所以能理解“那运费谁出”问的是退货运费,而不是发货运费。如果你只发最后一句“那运费谁出”,模型根本不知道你在说什么。
大模型本身是没有记忆的。每次 API 调用都是独立的,模型不会记住上一次调用的内容。所谓的多轮对话,其实是你在每次请求中把之前的对话历史都带上,让模型看到完整的上下文。这也是为什么对话越长,消耗的 Token 越多——因为每次请求都要把历史消息重新发一遍。
来看��一个更直观的例子——同一个问题,不同的 system 消息会导致完全不同的回答风格:
| system 消息 | 用户问题 | 模型回答风格 |
|---|---|---|
| 你是一个专业的技术顾问 | Java 和 Python 哪个好? | 客观分析两种语言的优劣势和适用场景 |
| 你是一个 Java 狂热粉丝 | Java 和 Python 哪个好? | 疯狂吹 Java,贬低 Python |
| 你是一个五岁小孩 | Java 和 Python 哪个好? | 用幼稚的语气回答,可能说"我不知道这是什么" |
这就是 system 消息的威力——它能从根本上改变模型的行为模式。
关于 OpenAI 的 developer 角色:OpenAI 在新版 API 中引入了
developer角色来替代system角色(参考 OpenAI 官方文档)。两者的功能类似,都是用来定义模型的行为规则。不过目前大多数兼容 OpenAI 协议的平台(包括 SiliconFlow、DeepSeek 等)仍然使用system角色,所以本系列统一使用system。如果你直接调用 OpenAI 官方 API,可以用developer替换system,效果是一样的。
2.4 temperature、max_tokens、top_p 等参数
除了 model 和 messages,还有几个常用的可选参数:
| 参数 | 类型 | 说明 | RAG 场景推荐值 |
|---|---|---|---|
temperature | float | 控制回答的随机性,0~2 之间。上一篇详细讲过 | 0~0.3 |
max_tokens | int | 模型最多生成多少个 Token。超过这个数就会被截断 | 512~2048(根据预期回答长度设置) |
top_p | float | 另一种控制随机性的方式,0~1 之间。和 temperature 二选一即可 | 0.7~0.9 |
stream | boolean | 是否启用流式返回。true 为流式,false 为非流式 | 根据场景选择 |
temperature和top_p都是控制随机性的参数,一般只调其中一个就行。本系列统一用temperature,更直观。
2.5 stream:流式开关
stream 参数决定了模型的回答是一次性返回还是逐块推送:
stream: false(默认):模型生成完所有内容后,一次性返回完整的 JSON 响应。适合后台处理场景stream: true:模型每生成一小段内容就立刻推送给客户端,客户端可以实时展示。适合面向用户的对话场景
这两种方式的区别和实现,后面会用完整的代码示例来演示。
3. 响应格式详解
发出请求后,模型会返回一个 JSON 响应(这里先看非流式的响应格式):
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1700000000,
"model": "Qwen/Qwen3-32B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "支持的。根据我们的退货政策,自签收之日起7天内,商品未经使用且不影响二次销售的,您可以申请七天无理由退货。请在订单详情页点击\"申请退货\"按钮,按照提示操作即可。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 42,
"completion_tokens": 68,
"total_tokens": 110
}
}
关键字段说明:
id:这次请求的唯一标识,用于日志追踪choices:模型的回答数组。通常只有一个元素(除非你设置了n参数要求生成多个回答)choices[0].message:模型的回答,格式和请求中的 message 一样,role是assistant,content是回答内容choices[0].finish_reason:模型停止生成的原因usage:Token 用量统计
3.1 usage:Token 用量统计
usage 字段告诉你这次调用消耗了多少 Token:
| 字段 | 含义 |
|---|---|
prompt_tokens | 你发送的内容(system + user + assistant 历史消息)消耗的 Token 数 |
completion_tokens | 模型生成的回答消耗的 Token 数 |
total_tokens | 总 Token 数 = prompt_tokens + completion_tokens |
API 按 Token 计费,所以这个字段帮你监控成本。上面的例子中,输入 42 个 Token,输出 68 个 Token,总共 110 个 Token。
3.2 finish_reason:模型为什么停下来了
finish_reason 有两个常见的值:
| 值 | 含义 | 说明 |
|---|---|---|
stop | 正常结束 | 模型认为回答已经完整,主动停止 |
length | 达到长度上限 | 回答被 max_tokens 截断了,内容可能不完整 |
如果你经常看到 finish_reason: "length",说明你的 max_tokens 设小了,模型的回答被截断了。把 max_tokens 调大一些就行。
4. 为什么国内厂商都�兼容这个协议
OpenAI 是最早定义这套 Chat Completions API 协议的,围绕它已经形成了庞大的生态:
- 各种 SDK 和框架(LangChain、Spring AI、LlamaIndex)都默认支持 OpenAI 协议
- 开发者社区的教程、示例代码大多基于这个协议
- 各种工具(Postman 模板、VS Code 插件、命令行工具)都兼容这个格式
国内厂商兼容这个协议,开发者就能零成本迁移。你用 SiliconFlow 写的代码,想切换到 DeepSeek 官方 API,只需要改两个东西:
// SiliconFlow
baseURL = "https://api.siliconflow.cn/v1/chat/completions"
apiKey = "你的 SiliconFlow API Key"
// 切换到 DeepSeek
baseURL = "https://api.deepseek.com/v1/chat/completions"
apiKey = "你的 DeepSeek API Key"
代码逻辑一行不用改。这就是兼容协议的好处。
SiliconFlow 平台:注册与获取 API Key
1. 为什么选择 SiliconFlow
上一篇已经提过技术选型的理由,这里再简单汇总一下:
- 国内平台,网络访问没有障碍,不需要特殊网络环境
- 注册简单,手机号即可注册,新用户有免费额度
- 支持多种主流开源模型(Qwen、DeepSeek、GLM、Llama 等),一个平台就能用多种模型
- API 完全兼容 OpenAI 协议,学会了这一套,切换到其他平台零成本
- 部分模型可免费调用,足够学习和实验使用
2. 注册步骤
- 访问 SiliconFlow 官网:
https://siliconflow.cn - 点击右上角的“注册”按钮,使用手机号注册账号
- 注册完成后登录,进入控制台
- 在左侧菜单中找到“API 密钥”,点击进入
- 点击“新建 API 密钥”按钮,系统会生成一个以
sk-开头的密钥字符串 - 把这个密钥复制下来,保存到安全的地方
API Key 是你调用 API 的身份凭证,相当于密码。不要把它提交到 Git 仓库、发到群聊里、或者写在公开的代码中。后面的代码示例中,我们会用
YOUR_API_KEY作为占位符,你需要替换成自己的真实 Key。
3. 本系列用到的模型
下面列出本系列会用到的模型:
| 模型 ID | 类型 | 用途 | 本系列使用场景 |
|---|---|---|---|
Qwen/Qwen3-32B | Chat 模型 | 对话、问答、文本生成 | 本篇的 API 调用实战,后续 RAG 的生成环节 |
BAAI/bge-m3 | Embedding 模型 | 文本向量化 | 后续 RAG 的向量化环节 |
BAAI/bge-reranker-v2-m3 | Reranker 模型 | 检索结果重排序 | 后续 RAG 的检索环节 |
模型的可用性和价格可能会变化,以 SiliconFlow 官网的实际展示为准。充值少量金额(几块钱就够实验很久)。
拿到 API Key 之后,咱们就可以开始写�代码了。
非流式调用:发一个问题,拿一个完整回答
非流式调用是最简单的调用方式:你发一个请求,等模型生成完所有内容,一次性拿到完整的回答。就像调用一个普通的 REST API 一样。
完整示例可以查看 TinyRAG 项目 com.nageoffer.ai.tinyrag.openai 目录下代码。
1. Maven 依赖
在你的 pom.xml 中添加以下依赖:
<dependencies>
<!-- OkHttp:HTTP 客户端 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- Gson:JSON 处理 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.13.1</version>
</dependency>
</dependencies>
为什么用 OkHttp 而不是 Spring 的 RestTemplate 或 WebClient?因为 OkHttp 是纯 HTTP 客户端,不依赖 Spring 框架,代码更简洁,也方便你在任何 Java 项目中使用。后续系列中所有的 API 调用都用 OkHttp + Gson 这套组合。
2. 完整代码实现
public class NonStreamingChat {
// SiliconFlow API 地址
private static final String API_URL = "https://api.siliconflow.cn/v1/chat/completions";
// 替换成你自己的 API Key
private static final String API_KEY = "YOUR_API_KEY";
public static void main(String[] args) throws IOException {
// 1. ��构建请求体 JSON
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", "Qwen/Qwen3-32B");
requestBody.addProperty("temperature", 0);
requestBody.addProperty("max_tokens", 1024);
requestBody.addProperty("stream", false);
// 构建 messages 数组
JsonArray messages = new JsonArray();
// system 消息:定义模型的行为规则
JsonObject systemMsg = new JsonObject();
systemMsg.addProperty("role", "system");
systemMsg.addProperty("content", "你是一个专业的电商客服助手,回答要简洁明了。");
messages.add(systemMsg);
// user 消息:用户的问题
JsonObject userMsg = new JsonObject();
userMsg.addProperty("role", "user");
userMsg.addProperty("content", "买了一周的东西还能退吗?");
messages.add(userMsg);
requestBody.add("messages", messages);
// 2. 创建 OkHttp 客户端(设置超时时间,大模型响应可能较慢)
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.build();
// 3. 构建 HTTP 请求
Request request = new Request.Builder()
.url(API_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
requestBody.toString(),
MediaType.parse("application/json")
))
.build();
// 4. 发送请求并处理响应
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
System.out.println("请求失败,状态码:" + response.code());
System.out.println("错误信息:" + response.body().string());
return;
}
// 5. 解析 JSON 响应
String responseBody = response.body().string();
Gson gson = new Gson();
JsonObject jsonResponse = gson.fromJson(responseBody, JsonObject.class);
// 提取模型的回答
String answer = jsonResponse
.getAsJsonArray("choices")
.get(0).getAsJsonObject()
.getAsJsonObject("message")
.get("content").getAsString();
// 提取 finish_reason
String finishReason = jsonResponse
.getAsJsonArray("choices")
.get(0).getAsJsonObject()
.get("finish_reason").getAsString();
// 提取 Token 用量
JsonObject usage = jsonResponse.getAsJsonObject("usage");
int promptTokens = usage.get("prompt_tokens").getAsInt();
int completionTokens = usage.get("completion_tokens").getAsInt();
int totalTokens = usage.get("total_tokens").getAsInt();
// 6. 打印结果
System.out.println("=== 模型回答 ===");
System.out.println(answer);
System.out.println();
System.out.println("=== 调用信息 ===");
System.out.println("结束原因:" + finishReason);
System.out.println("输入 Token:" + promptTokens);
System.out.println("输出 Token:" + completionTokens);
System.out.println("总 Token:" + totalTokens);
}
}
}
3. 运行效果
把 YOUR_API_KEY 替换成你自己的 API Key,运行这段代码,控制台输出大概长这样:
=== 模型回答 ===
根据中国《消费者权益保护法》规定,**普通商品**(非定制、非易腐等)通常享有**七天无理由退货**的权利,但需满足以下条件:
1. **时间计算**:自签收商品之日起7日内(含第7天);
2. **商品状态**:保持完好,未拆封或未使用(部分商品如食品、化妆品等需未拆封);
3. **凭证保留**:保留发票、包装及配件;
4. **运费承担**:无理由退货需自行承担退货运费(特殊政策除外)。
**建议**:
- 立即联系卖家客服,说明情况并确认是否符合退货条件;
- 若卖家拒绝,可向平台投诉或通过12315平台维权。
不同平台/商家可能有细微差异,请以实际购买页面的退货政策为准。
=== 调用信息 ===
结束原因:stop
输入 Token:34
输出 Token:527
总 Token:561
每次运行的回答内容可能略有不同(因为 temperature 不是 0),但大意是一样的。如果你把 temperature 设成 0,每次运行的结果几乎相同(由于 GPU 浮点运算的不确定性,极少数情况下仍可能有细微差别)。
4. 代码逐行解读
整段代码做了六件事,对应注释中的 1~6:
- 构建请求体:用 Gson 的
JsonObject手动拼装 JSON。messages数组里放了一条 system 消息和一条 user 消息。这就是前面讲的 OpenAI 协议的请求格式 - 创建 HTTP 客户端:OkHttp 的标准用法。注意设置了超时时间——大模型生成回答可能需要几秒到十几秒,默认的超时时间可能不够
- 构建 HTTP 请求:POST 请求,URL 是 SiliconFlow 的 Chat API 地址。
Authorization头用Bearer方式传递 API Key,这是 OAuth 2.0 的标准做法 - 发送请求:
client.newCall(request).execute()是同步调用,会阻塞当前线程直到收到响应。用 try-with-resources 确保响应体被正确关闭 - 解析响应:从 JSON 响应中提取
choices[0].message.content(模型的回答)和usage(Token 用量)。这就是前面讲的响应格式 - 打印结果:把回答和调用信息输出到控制台
整个流程和你平时调用第三方 REST API 没有本质区别——构建请求、发送请求、解析响应。大模型 API 并没有什么神秘的。
流式调用:像打字一样逐字输出
1. 为什么需要流式调用
非流式调用有一个体验上的问题:模型要把所有内容都生成完,才一次性返回给你。如果回答比较长(比如几百、几千字),用户可能要等 3~30 秒才能看到任何内容。这段时间里,界面上什么都没有,用户会觉得是不是卡了。
如果是深度思考,这个首包响应时间会更长。
流式调用解决的就是这个问题:模型每生成一小段内容(可能是一个词、几个字),就立刻推送给客户端。客户端收到一段就显示一段,用户看到的效果是文字一个一个打出来的——这就是你在 ChatGPT、DeepSeek 网页端看到的打字机效果。
两种方式的体验对比:
| 方式 | 用户体验 |
|---|---|
| 非流式 | 等 x 秒 → 全部回答文字突然出现 |
| 流式 | 立刻开始逐字输出 → x 秒后全部输出完毕 |
总耗时是一样的(模型生成内容的速度不变),但流式调用让用户感觉快了很多,因为第一个字几乎是立刻出现的。
2. SSE(Server-Sent Events)协议简介
流式调用基于一个叫 SSE(Server-Sent Events,服务端推送事件)的协议。不需要深入了解 SSE 的所有细节,只要理解它的核心思想就行。
普通的 HTTP 请求是一问一答的模式:客户端发一个请求,服务端返回一个完整的响应,然后连接就关闭了。
SSE 不一样:客户端发出请求后,服务端不会一次性返回所有内容然后关闭连接,而是保持连接打开,持续地往客户端推送数据块。每个数据块是一行文本,以 data: 开头。当所有内容都推送完毕后,服务端会发送一个特殊的结束标记 data: [DONE],然后关闭连接。
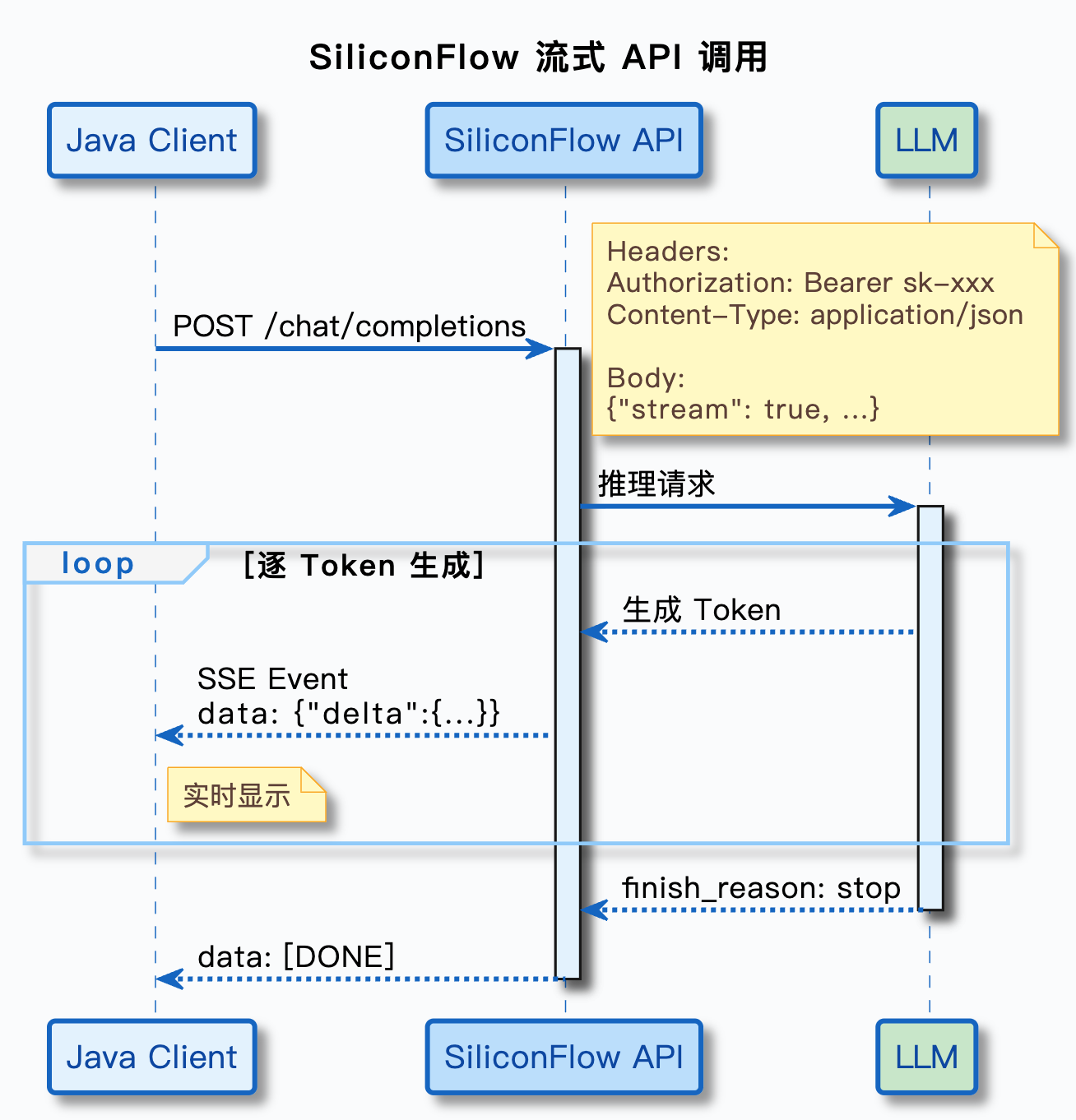
用一句话概括:SSE 就是服务端持续推送,客户端持续接收。
3. 流式响应的数据格式
流式响应和非流式响应的 JSON 结构有一个关键区别:非流式响应中,模型的回答在 choices[0].message 里;流式响应中,每个数据块的增量内容在 choices[0].delta 里。
一个完整的流式响应数据流长这样(每行是服务端推送的一个数据块):
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"可以"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"的。"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"根据"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"退货"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"政策"},"finish_reason":null}]}
data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{},"finish_reason":"stop"}]}
data: [DONE]
注意几个细节:
- 第一个数据块的
delta里有role: "assistant",表示这是助手的回答开始了 - 中间的数据块,
delta里只有content字段,包含增量内容(新生成的几个字) - 倒数第二个数据块的
delta为空,finish_reason变成了"stop",表示模型生成完毕 - 最后一行
data: [DONE]是 SSE 的结束标记,不是 JSON 格式 - 数据块之间可能有空行,解析时需要跳过
要拿到完整的回答,你需要把所有数据块中 delta.content 的内容拼接起来。
4. 完整代码实现
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import okhttp3.*;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.concurrent.TimeUnit;
public class StreamingChat {
private static final String API_URL = "https://api.siliconflow.cn/v1/chat/completions";
private static final String API_KEY = "YOUR_API_KEY";
public static void main(String[] args) throws IOException {
// 1. 构建请求体(注意 stream 设为 true)
JsonObject requestBody = new JsonObject();
requestBody.addProperty("model", "Qwen/Qwen3-32B");
requestBody.addProperty("temperature", 0.1);
requestBody.addProperty("max_tokens", 1024);
requestBody.addProperty("stream", true); // 开启流式
JsonArray messages = new JsonArray();
JsonObject systemMsg = new JsonObject();
systemMsg.addProperty("role", "system");
systemMsg.addProperty("content", "你是一个专业的电商客服助手,回答要简洁明了。");
messages.add(systemMsg);
JsonObject userMsg = new JsonObject();
userMsg.addProperty("role", "user");
userMsg.addProperty("content", "买了一周的东西还能退吗?");
messages.add(userMsg);
requestBody.add("messages", messages);
// 2. 创建 OkHttp 客户端
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(120, TimeUnit.SECONDS) // 流式调用需要更长的读取超时
.build();
// 3. 构建请求
Request request = new Request.Builder()
.url(API_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
requestBody.toString(),
MediaType.parse("application/json")
))
.build();
// 4. 发送请求并逐行读取 SSE 响应
Gson gson = new Gson();
StringBuilder fullContent = new StringBuilder();
System.out.println("=== 模型回答(流式输出)===");
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
System.out.println("请求失败,状态码:" + response.code());
System.out.println("错误信息:" + response.body().string());
return;
}
// 逐行读取响应体
BufferedReader reader = new BufferedReader(
new InputStreamReader(response.body().byteStream())
);
String line;
while ((line = reader.readLine()) != null) {
// 跳过空行
if (line.isEmpty()) {
continue;
}
// 每行以 "data: " 开头,去掉前缀
if (!line.startsWith("data: ")) {
continue;
}
String data = line.substring(6); // 去掉 "data: " 前缀(6 个字符)
// 检查是否是结束标记
if ("[DONE]".equals(data)) {
break;
}
// 解析 JSON,提取增量内容
JsonObject chunk = gson.fromJson(data, JsonObject.class);
JsonArray choices = chunk.getAsJsonArray("choices");
if (choices != null && choices.size() > 0) {
JsonObject delta = choices.get(0).getAsJsonObject()
.getAsJsonObject("delta");
if (delta != null && delta.has("content")) {
JsonElement contentElement = delta.get("content");
if (!contentElement.isJsonNull()) {
String content = contentElement.getAsString();
// 实时打印增量内容(不换行,模拟打字效果)
System.out.print(content);
fullContent.append(content);
}
}
}
}
}
// 输出完毕,换行
System.out.println();
System.out.println();
System.out.println("=== 完整回答 ===");
System.out.println(fullContent);
}
}
5. 运行效果
运行这段代码,你会看到控制台上的文字是一个一个蹦出来的,而不是等几秒后一次性出现。效果大概是这样的:
=== 模型回答(流式输出)===
能否退货需根据以下情况判断:
1. **平台规则**
- **淘宝/天猫**:7天无理由退货(部分特殊类目如内衣、食品等不支持)
- **京东**:7天无理由退货(自营商品支持,第三方店铺需看商家政策)
- **拼多多**:7天无理由退货(需保持商品完好)
2. **商品状态**
- 未拆封、不影响二次销售,且保留发票/包装,通常可退。
- 若已拆封使用或商品性质特殊(如定制、易腐品),可能无法退货。
3. **质量问题**
- 若商品存在质量问题,可申请**质量问题退货**(时效通常更长,需提供凭证)。
**建议**:立即联系对应平台或商家客服,提供订�单号和商品情况,确认具体政策并尽快操作。
=== 完整回答 ===
能否退货需根据以下情况判断:
1. **平台规则**
- **淘宝/天猫**:7天无理由退货(部分特殊类目如内衣、食品等不支持)
- **京东**:7天无理由退货(自营商品支持,第三方店铺需看商家政策)
- **拼多多**:7天无理由退货(需保持商品完好)
2. **商品状态**
- 未拆封、不影响二次销售,且保留发票/包装,通常可退。
- 若已拆封使用或商品性质特殊(如定制、易腐品),可能无法退货。
3. **质量问题**
- 若商品存在质量问题,可申请**质量问题退货**(时效通常更长,需提供凭证)。
**建议**:立即联系对应平台或商家客服,提供订单号和商品情况,确认具体政策并尽快操作。
文字看起来是一样的,但体验完全不同:非流式调用要等几秒才能看到内容,流式调用几乎立刻就开始输出了。
在控制台里,逐字输出的效果可能不太明显(因为网络传输是批量的,可能一次收到好几个字)。但如果你把这个逻辑接到前端页面上,用户看到的就是标准的打字机效果。
5.1 流式代码的关键点
和非流式代码相比,流式代码有几个关键的不同:
- 请求体中
stream设为true:告诉服务端用 SSE 方式返回 - 用
BufferedReader逐行读取:不能用response.body().string()一次性读取,因为响应是持续推送的,要逐行处理 - 解析
delta而不是message:流式响应中,增量内容在choices[0].delta.content里,不是choices[0].message.content - 处理
[DONE]结束标记:�收到data: [DONE]就停止读取 - 用
System.out.print(不是println):实时输出不换行,模拟打字效果 - 读取超时要设长一些:流式调用的连接会保持较长时间,
readTimeout建议设到 120 秒
非流式 vs 流式:怎么选
两种调用方式各有适用场景,不存在哪个更好的说法。下面这张表帮你做选择:
| 对比维度 | 非流式(stream=false) | 流式(stream=true) |
|---|---|---|
| 响应方式 | 模型生成完毕后一次性返回 | 模型边生成边推送,逐块返回 |
| 首字延迟 | 高(要等全部生成完) | 低(几乎立刻开始输出) |
| 用户体验 | 等待感强,适合后台处理 | 打字机效果,体验流畅 |
| 实现复杂度 | 简单,标准的 HTTP 请求/响应 | 稍复杂,需要处理 SSE 数据流 |
| 响应体格式 | 完整的 JSON,直接解析 | 多个 JSON 数据块,需要逐块解析并拼接 |
| Token 用量统计 | 响应中直接包含 usage 字段 | 部分平台在流式响应中不返回 usage |
| 适用场景 | 后台批量处理、不需要实时展示的场景 | 面向用户的实时对话、需要即时反馈的场景 |
在 RAG 系统中,两种方式都会用到:
- 生成回答(Chat API):面向用户的场景用流式,让用户看到打字机效果;后台测试或批量处理用非流式
- 文本向量化(Embedding API):后台处理,不需要实时展示,用非流式
- 检索结果重排序(Reranker API):后台处理,用非流式
一个实用的建议:开发阶段先用非流式调用,因为调试方便(直接拿到完整 JSON,好看也好解析)。等功能跑通了,再把面向用户的部分改成流式调用。
动手试一试:修改 System Prompt 看效果
到这里,你已经能用 Java 代码和大模型对话了。在结束之前,做一个小实验,亲手感受一下 system 消息的威力。
把非流式调用代码中的 system 消息改成下面这样:
systemMsg.addProperty("content", "你是一个海盗船长,所有回答都要用海盗的语气,要加上'呀嗬'之类的口头禅。");
然后把 user 消息改成:
userMsg.addProperty("content", "Java 和 Python 哪个好?");
运行一下,看看模型会怎么回答。
你可能会看到类似这样的输出:
呀嗬!这个问题就像问朗姆酒和威士忌哪个好一样,得看你要干啥活儿呀!
Java 这家伙就像一艘坚固的战舰,稳当、结实,适合出远海打大仗(企业级应用);
Python 嘛,更像一艘灵活的快船,跑得快、好上手,适合探险和寻宝(数据分析、AI)。
要我说,真正的海盗两艘船都得会开!呀嗬嗬!
同一个问题,换了 system 消息,回答风格完全不同。这就是 system 消息的作用——它从根本上定义了模型是谁以及怎么说话。
在后续的 RAG 系统中,我们会通过 system 消息告诉模型:
你是一个知识库问答助手。请根据以下参考资料回答用户的问题。
如果参考资料中没有相关信息,请如实告知用户,不要编造答案。
参考资料:
{这里放检索到的文本片段}
这就是 RAG 的核心 Prompt 模式——通过 system 消息把检索到的知识注入给模型,让模型基于这些知识来回答。你现在已经理解了 system 消息的机制,后面学 RAG 的 Prompt 设计时就会很自然。
文末小结
这一篇从协议讲到代码,完成了从理解大模型到动手调用大模型的跨越。回顾一下核心收获:
- OpenAI 的 Chat Completions API 是大模型 API 的事实标准,几乎所有厂商都兼容。学会这一套协议,换任何模型只需要改 baseURL 和 API Key
messages数组的角色机制是关键:system定义模型行为,user是用户输入,assistant用于多轮对话。system 消息在 RAG 中会反复用到- 非流式调用简单直接,适合后台处理;流式调用基于 SSE 协议,能实现打字机效果,适合面向用户的场景
- 用 Java + OkHttp + Gson 就能完成大模型 API 的调用,和调用普通 REST API 没有本质区别
你现在手里已经有了一个能和大模型对话的 Java 程序,也拿到了可用的 SiliconFlow API Key。后续系列中所有涉及 API 调用的地方(Embedding API、Reranker API、Chat API),都是同样的套路——构建 JSON 请求体、发 HTTP POST、解析 JSON 响应。这篇打下的基础,后面会反复用到。
OpenAI 接口协议随着不断演进,已经增加了多模态、函数调用、结构化输出等高级功能。这些能力在实际项目中非常有用,但本篇聚焦于最核心的文本对话调用,帮你打好基础。后续系列中如果用到这些高级特性,会在具体场景下详细讲解。