什么是大模型
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
你在公司做了一套客服系统,老板突然说:现在 AI 这么火,能不能接个 AI 进去,让它自动回答用户的问题?
你打开 DeepSeek 的网页版,试着问了几个业务问题,发现效果还不错——语句通顺,逻辑清晰,甚至能根据你给的上下文做总结。你心想,这东西要是能接到系统里,客服效率直接翻倍。
但问题来了:网页版是给人用的,你的 Java 系统怎么调用它?DeepSeek、通义千问、ChatGPT 这些名字你都听过,但它们到底是什么?背后的大模型又是什么东西?为什么有的模型叫 7B,有的叫 72B?网上说的 Token、Temperature、上下文窗口又是什么意思?
别急,这个系列就是帮你搞定这些问题的。从大模型基础到 RAG 系统的完整实现,一步步来。不过在动手写代码之前,咱们先花一篇的篇幅把大模型这个东西搞清楚——它是什么,怎么分类,有哪些核心概念,以及为什么开发者需要通过 API 而不是网页来使用它。
大模型到底是什么
1. 从写死规则到让机器自己学
做业务开发的同学对 if-else 再熟悉不过了。传统编程的思路是:你把所有的规则都写死在代码里。
比如做一个简单的客服自动回复:
if (question.contains("退货")) {
return "请在订单详情页点击申请退货";
} else if (question.contains("发货")) {
return "下单后 48 小时内发货";
} else {
return "请联系人工客服";
}
这种方式的问题很明显:用户的表达方式千变万化。我想退货、东西不想要了、买错了能退吗、这个怎么退啊——这些说的都是同一件事,但你的 if-else 只能匹配到包含退货两个字的那一种。你要是想覆盖所有说法,规则会写到崩溃。
后来有了传统 NLP(自然语言处理)技术,比如关键词匹配、TF-IDF、朴素贝叶斯分类器。这些方法比 if-else 聪明一点,能做一些统计层面的文本分析,但本质上还是在“数词频”“算概率”,并不真正理解语言的含义。你说:东西不想要了,它可能把东西和不想要拆开来分析,然后匹配到商品推荐而不是退货。
大模型(Large Language Model,LLM)的出现彻底改变了这个局面。
大模型的训练方式可以简单理解为:让机器阅读互联网上海量的文本数据(书籍、网页、论坛、代码、百科……),从中学习语言的规律和知识。它不是靠人写规则,而是靠“读”了足够多的文本之后,自己“悟”出了语言是怎么运作的。
打个比方:传统编程像是给一个人一本操作手册,手册上写了遇到 A 情况就做 B,手册没写的它就不会。传统 NLP 像是让这个人去数词频、算概率,能做一些简单的判断,但理解不了复杂的语境。而大模型更像是让一个人从小读了几百万本书,虽然没人教过它具体的规则,但它通过大量阅读自然而然地学会了语言的用法、常识和推理能力。
所以当你问大模型:东西不想要了,它能理解你说的是退货,因为它在训练数据中见过无数类似的表达方式,知道这句话在购物场景下就是退货的意思。
2. 大模型的到底大在哪
大模型这个名字里的“大”,指的是模型的参数量。
你可能在各种文章里见过 7B、14B、72B 这样的数字。这里的 B 是 Billion(十亿)的缩写,7B 就是 70 亿个参数,72B 就是 720 亿个参数。
参数是什么?你可以把它理解为模型大脑里的连接数。人类大脑有大约 100 万亿个突触连接,这些连接存储了我们的记忆、知识和思维能力。大模型的参数类似——每个参数都是一个数字,所有参数组合在一起,构成了模型对语言的理解能力。
参数越多,模型能记住的知识就越多,能处理的语言现象就越复杂,回答的质量通常也越高。但代价是需要更多的计算资源(显存、算力)来运行。
下面这张表给你一个直观的感受:
| 参数量级 | 代表模型 | 大致能力 | 运行硬件需求 |
|---|---|---|---|
| 1.7B(17 亿) | Qwen3-1.7B | 简单对话、文本分类,复杂任务容易出错 | 消费级显卡(4GB 显存) |
| 8B(80 亿) | Qwen3-8B、Llama3-8B | 日常对话、简单问答、基础代码生成 | 消费级显卡(8~16GB 显存) |
| 14B(140 亿) | Qwen3-14B | 较好的对话和推理能力,中等复杂度任务 | 中端显卡(16~24GB 显存) |
| 32B(320 亿) | Qwen3-32B | 优秀的推理和代码能力,接近大参数模型 | 高端显卡(24~48GB 显存) |
| 72B(720 亿) | Qwen3-72B | 接近顶级闭源模型的能力,复杂推理和创作 | 多卡服务器(80GB+ 显存) |
| 671B(6710 亿) | DeepSeek-V3 | 顶级能力,对标 GPT-4 | 大规模集群 |
这里说的运行硬件需求是指本地部署模型时需要的资源。如果你通过 API 调用(比如调用 SiliconFlow 平台上的模型),硬件问题由平台方解决,你只需要一台能联网的电脑就行。后续系列中我们都是通过 API 调用,不涉及本地部署。
一个常见的误区是“参数越大越好”。实际上,对于很多应用场景(比如 RAG 系统中的问答),14B 或 32B 的模型就够用了。参数量大的模型虽然能力更强,但推理速度更慢、成本更高。选模型要看场景,不是越大越好。
3. 几个你必须知道的核心概念
在后续调用大模型 API 的时候,有几个概念会反复出现。现在先搞清楚,后面用到的时候就不会懵。
3.1 Token:大模型的计量单位
大模型处理文本的时候,不是�按字或词来算的,而是按 Token。
Token 是模型内部的最小处理单元。你可以把它理解为模型把文本切碎后的小片段。不同语言的切法不一样:
- 英文:大致 1 个单词 ≈ 1~1.5 个 Token。比如 "hello" 是 1 个 Token,"unbelievable" 可能被切成 "un" + "believ" + "able" 共 3 个 Token
- 中文:大致 1 个汉字 ≈ 1
2 个 Token。比如“你好”可能是 2 个 Token,“人工智能”可能是 23 个 Token
为什么要知道这个?两个原因:
- API 调用按 Token 计费。你发给模型的文本(输入)和模型返回的文本(输出)都会消耗 Token,Token 用得越多,花的钱越多
- 上下文窗口是按 Token 算的(下面马上讲)。你能塞给模型的信息量,取决于 Token 数量,而不是字数
不需要精确计算每句话有多少 Token,有个大概的感觉就行。大多数 API 平台在返回结果时会告诉你这次调用消耗了多少 Token。
3.2 上下文窗口(Context Window)
上下文窗口是模型一次对话中能看到的文本总量上限,单位是 Token。
打个比方:你和一个人聊天,这个人的记忆力有限,只能记住最近说过的 N 句话。如果你们的对话超过了 N 句,最早的那些话就被忘掉了。大模型的上下文窗口就是这个 N,只不过单位是 Token 而不是句子。
常见的上下文窗口大小:
| 上下文窗口 | 大约能容纳的中文字数 | 代表模型 |
|---|---|---|
| 4K Token | 约 2000~3000 字 | 早期模型(GPT-3.5 初版) |
| 8K Token | 约 4000~6000 字 | GPT-3.5-Turbo |
| 32K Token | 约 16000~24000 字 | GPT-4-32K |
| 128K Token | 约 64000~96000 字 | GPT-4-Turbo、Qwen2.5 系列 |
| 1M Token | 约 50 万~75 万字 | Gemini 1.5 Pro |
上下文窗口包含了你发给模型的所有内容(系统提示词 + 历史对话 + 当前问题)和模型的回答。如果总量超过了窗口大小,最早的内容会被截断,模型就看不到了。
这个概念在 RAG 中非常重要。你可能想过:既然大模型这么聪明,我把整本产品手册都塞给它,让它自己找答案不就行了?问题是,一本产品手册可能有几十万字,远远超过大多数模型的上下文窗口。就算窗口够大,塞太多内容模型也容易迷失在信息海洋里,找不到重点。这就是为什么 RAG 系统需要先检索出最相关的片段,只把这些片段塞给模型——既不超窗口,又能让模型聚焦在关键信息上。
3.3 Temperature:控制回答的创造力
Temperature(温度)是调用大模型时的一个重要参数,用来控制回答的随机性。
- Temperature = 0:模型每次都会选择概率最高的那个词,回答最确定、最稳定,但可能比较死板
- Temperature = 0.7:模型会在高概率的词里随机选择,回答更自然、更有变化
- Temperature = 1.0 或更高:模型的选择更加随机,回答更有创意,但也更容易胡说八道
用考试来类比:Temperature = 0 就像一个学霸,每道题都写标准答案,稳��定但没有惊喜;Temperature = 1.0 就像一个有创意的学生,有时候能写出精彩的答案,有时候也会跑偏。
不同场景下 Temperature 的推荐值:
| 场景 | 推荐 Temperature | 原因 |
|---|---|---|
| RAG 问答 | 0~0.3 | 需要准确回答,不要发挥 |
| 代码生成 | 0~0.2 | 代码需要精确,不能有随机性 |
| 日常对话 | 0.5~0.7 | 需要自然流畅,但不能太离谱 |
| 创意写作 | 0.7~1.0 | 需要多样性和创造力 |
在 RAG 场景下,我们通常把 Temperature 设得很低(0 或 0.1),因为答案已经在检索到的文本片段里了,模型只需要忠实地整理和表达,不需要发挥创造力。
3.4 MoE:混合专家架构
在后面的模型对比表中,你会频繁看到 MoE 这个词,比如“671B(37B 激活,MoE)”。这里先简单解释一下它是什么。
MoE 全称 Mixture of Experts(混合专家),是一种模型架构设计。传统的大模型(Dense Model,稠密模型)在处理每个输入时,所有参数都会参与计算。而 MoE 模型内部被拆分成了多个专家子网络,每次推理时只激活其中一部分专家来处理当前输入,其余专家不参与计算。
举个例子,DeepSeek-V3 的总参数量是 671B,但每次推理只激活 37B 的参数。这意味着它拥有 671B 参数量级的知识容量,但实际推理时的计算开销只相当于一个 37B 的模型。
MoE 的好处很直观:用更低的计算成本获得更强的模型能力。这也是为什么近两年很多大参数量的模型都采用了 MoE 架构——它让大模型在推理成本上变得更可控。
作为 RAG 应用开发者,你不需要深入理解 MoE 的实现细节,只需要知道:当你看到模型参数写的是“671B(37B 激活,MoE)”时,实际推理消耗的资源大致对应 37B 这个数字,而不是 671B。
当前主流大模型一览
大模型这个领域发展非常快,几乎每个月都有新模型发布。这里不追求面面俱到,只帮你建立一个基本的"模型地图",知道主流的模型有哪些、各自什么定位就够了。
1. 国际主流模型
| 模型系列(举例) | 厂商 | 特点 | 是否开源 |
|---|---|---|---|
| GPT 系列(GPT-5.2 / GPT-5.2 pro 等) | OpenAI | 综合能力与生态最成熟;推理、工具调用、Agent 工作流能力强 | 否 |
| Claude 系列(Claude Opus 4.6 / Sonnet 4.6) | Anthropic | 代码与长上下文能力突出;“computer use/代理”能力强;安全与对齐投入大 | 否 |
| Gemini 系列(Gemini 3.1 Pro / Gemini 3 Flash) | 原生多模态(文/图/音/视频);超长上下文(最高 1M);与 Google 生态结合紧密 | 否 | |
| Llama 系列(Llama 4 Scout / Maverick) | Meta | 开放权重生态最强之一;社区活跃、部署与微调方案成熟;MoE + 多模态 | 是(开放权重) |
这几个模型在国内�使用都有一定门槛:GPT 和 Claude 需要海外网络环境,Gemini 同理。Llama 虽然开源可以本地部署,但对硬件要求较高,而且中文能力不如国内模型。
2. 国内主流模型
国内大模型这两年发展很快,尤其是开源模型,在中文场景下的表现已经非常出色。
| 模型系列(最新) | 厂商 | 特点 | 是否开源 |
|---|---|---|---|
| DeepSeek 系列(V3 / R1 等) | 深度求索(DeepSeek) | 性价比高;推理能力强(R1);开放权重、可商用;社区生态活跃 | 是(MIT)(Hugging Face) |
| 通义千问 Qwen 系列(Qwen3.5) | 阿里云 / 阿里巴巴 | Agent 生态强、工具调用/多模态路线清晰;尺寸覆盖广;开源生态完善 | 是(Apache-2.0,开放权重)(Hugging Face) |
| 智谱 GLM 系列(GLM-5) | 智谱 AI / Z.ai | 面向复杂系统工程与长程 Agent 任务;推理/编码/Agentic 能力强化;GLM-5 已开源且 MIT 许可 | 是(MIT) (Hugging Face) |
| MiniMax 系列(MiniMax-M1 / abab 6.5) | MiniMax | M1 主打超长上下文 + 高效推理(百万级输入);abab 6.5 系列面向通用对话/长上下文 | 部分开源(M1 开源 Apache-2.0;abab 多为服务型) (MiniMax) |
| Kimi 系列(Kimi K2.5) | 月之暗面(Moonshot AI) | 长文档/多模态 + Agent;K2.5 开源权重,Modified MIT 许可;并提供兼容 OpenAI/Anthropic 的 API | 是(Modified MIT) (Hugging Face) |
其中 DeepSeek 和 Qwen 仍然是国内开放权重生态里最核心的两条主线:DeepSeek 更偏“推理 + Agent 训练 + 极致性价比”,Qwen 更偏“全尺寸覆盖 + agentic 能力 + 完整开源生态”。后续系列中我们会重点使用这两个系列的模型。
2.1 DeepSeek:推理能力的代表
DeepSeek 最出圈的依然是 DeepSeek-R1,在数学推理、代码生成、复杂规划等场景表现很强,并且开放权重发布,便于社区复现、微调与本地部署。
最新的 DeepSeek-V3.2 进一步面向 Agent 场景做了强化,支持把“思考”更直接地融入工具调用(Thinking in Tool-Use),同时保持较高的性价比与可用性。
另外,DeepSeek 的 API 定价长期处在行业低位,对开发者做原型、跑评测与上线都比较友好。
2.2 Qwen:中文场景的全能选手
通义千问 Qwen 系列的优势在于 模型谱系完整(从小模型到旗舰 MoE 都有)、中文能力稳定、并且围绕 Hugging Face / ModelScope / DashScope 等形成了较成熟的开源与部署生态。
最新的 Qwen3.5 更强调 "agentic" 方向,在复杂任务分解、工具使用与多模态场景上持续增强。
3. 模型对比表
下面这张表把主流模型的关键信息放在一起,方便你对比:
| 模型 | 厂商 | 参数量 | 上下文窗口 | 开源 | 主要特点 |
|---|---|---|---|---|---|
| GPT-5.2 pro | OpenAI | 未公开 | 400K | 否 | 强推理 + 工具/多轮交互;旗舰 API 能力 |
| Claude Sonnet 4.6 | Anthropic | 未公开 | 200K(默认)/ 1M(Beta) | 否 | 代码与长上下文强;computer-use/Agent 能力突出 |
| Gemini 3.1 Pro | 未公开 | 1M | 否 | 原生多模态;长上下文;适合复杂资料/代码库 | |
| Llama 4 Maverick(17Bx128E) | Meta | 400B(17B 激活,MoE) | 1M | 是(开放权重) | 多模态 + MoE;本地部署/微调生态成熟 |
| DeepSeek-V3.2(deepseek-chat) | 深度求索 | 671B(37B 激活,MoE) | 128K | 是(MIT) | 通用 + Agent 取向;支持 Thinking in Tool-Use;性价比高 |
| DeepSeek-R1(deepseek-reasoner) | 深度求索 | 671B(37B 激活,MoE) | 128K | 是(MIT) | 深度思考推理;数学/代码/规划强 |
| Qwen3.5-397B-A17B | 阿里巴巴 | 397B(17B 激活,MoE) | 262K | 是(Apache-2.0) | 旗舰开放权重;偏 agentic;长上下文更强 |
| Qwen3-32B | 阿里巴巴 | 32B | 32K(原生)/ 131K(YaRN) | 是(Apache-2.0) | 中大型开源;适合私有化、RAG、微调 |
| Qwen3-8B | 阿里巴巴 | 8B | 32K(原生)/ 131K(YaRN) | 是(Apache-2.0) | 轻量部署;成本敏感/边缘侧更友好 |
| GLM-5 | 智谱 AI(Z.ai) | 744B(40B 激活,MoE) | 200K | 是(MIT) | 面向 Coding/Agent;长上下文 + 高输出上限(128K) |
大模型领域更新极快,上面的信息以写作时为准。具体到某个模型的最新版本和能力,建议查阅各厂商的官方文档。
Chat 模型:我们真正要调用的东西
你在网页端用的 DeepSeek、通义千问,或者通过 API 调用的模型,其实都是一种特定类型的大模型——Chat 模型。但大模型并不是天生就会聊天的,它需要经过专门的训练才能变成一个合格的对话助手。
1. 基座模型(Base Model)vs Chat 模型
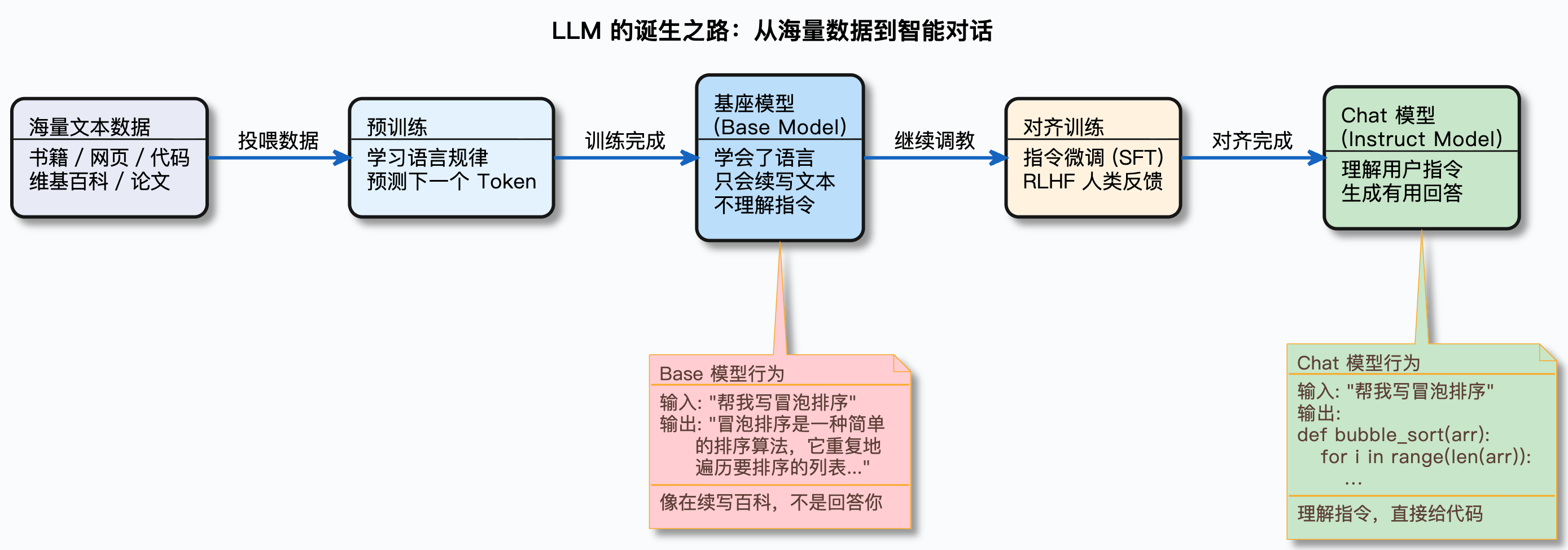
大模型的训练分两个阶段:
第一阶段是预训练(Pre-training)。模型阅读海量文本数据,学习语言的规律。训练完成后得到的就是基座模型(Base Model)。基座模型有一个特点:它只会续写。你给它一句话,它会接着往下写,但它不会回答问题。
举个例子,你给基座模型输入:中国的首都是,它可能会续写出:北京,是中华人民共和国的政治中心、文化中心……——看起来像是在回答问题,但其实它只是在做文本续写,因为训练数据里“中国的首都是北京”这种句式出现过很多次。
但如果你对它说:请根据以下用户反馈,判断用户的情绪是正面、负面还是中性,只输出情绪类别,不要输出其他内容。用户反馈:物流太慢了,等了一周才到。基座模型不会乖乖输出“负面”两个字,它更可能接着你的文本继续写下去——比如再编几条用户反馈,或者写一段关于情绪分析的介绍文章。因为它不理解“只输出情绪类别”是一个指令,它只是在预测下一个最可能出现的词。
第二阶段是对齐训练(Alignment)。在基座模型的基础上,通过指令微调(Instruction Tuning)和人类反馈强化学习(RLHF)等技术,教会模型理解人类的指令,并按照指令给出有用、安全的回答。训练完成后得到的就是 Chat 模型(也叫 Instruct 模型)。
简单说:基座模型是读了很多书的学生,Chat 模型是读了很多书,又经过面试培训,学会了怎么和人沟通的员工。
1.1 模型命名规则解读
了解了基座模型和 Chat 模型的区别,你就能看懂模型的命名了。不过要注意,命名规则并不是一成不变的,不同系列、不同代际、不同平台之间会有差异。
作为开发者,我们调用 API 或本地部署时用的几乎都是 Chat 模型。下面是一些常见的 Chat 模型命名规则:
Qwen 系列:
Qwen2.5-7B-Instruct:Instruct 后缀明确标注这是 Chat 模型Qwen3-14B:到了 Qwen3 系列,默认发布的就是 Chat 模型,不再需要 Instruct 后缀
DeepSeek 系列:
DeepSeek-V3:通用对话模型(Chat 模型),V3 表示第三代DeepSeek-R1:推理增强模型,R 代表 Reasoning(推理),专门强化了深度思考能力
平台差异:
同一个模型在不同平台上的命名可能不一样。比如 Qwen2.5-7B-Instruct 这个 Chat 模型:
- 在 Hugging Face 上叫
Qwen2.5-7B-Instruct - 在 Ollama 上可能简化为
qwen2.5:7b(省略了 Instruct 后缀) - 在 SiliconFlow API 上可能叫
Qwen/Qwen2.5-7B-Instruct(加了命名空间前缀)
Ollama、Hugging Face 这类平台为了简化用户使用,默认提供的都是 Chat 版本。如果你不确定某个模型是不是 Chat 版本,可以:
- 查看平台的模型说明页面
- 如果是 Ollama,可以通过
ollama show --modelfile <模型名>查看 modelfile,看是否包含对话模板(如<|im_start|>)、System Prompt 等 Chat 模型特征
常见后缀含义:
| 后缀 | 含义 | 示例 |
|---|---|---|
| -Instruct | 经过指令微调的 Chat 模型 | Qwen2.5-7B-Instruct |
| -Chat | 和 Instruct 类似,强调对话能力 | GLM-4-Chat |
| -GPTQ / -AWQ | 量化版本,模型体积更小,适合低资源部署 | Qwen2.5-7B-Instruct-GPTQ-Int4 |
基座��模型(Base Model)通常会明确标注
-Base后缀,主要是给做模型微调的研究人员用的。在 RAG 开发中,我们只需要关注 Chat 模型。
2. 为什么 RAG 系统只需要 Chat 模型
RAG 系统的工作流程是:用户提问 → 从知识库中检索相关文本片段 → 把问题和检索到的片段一起发给大模型 → 模型根据这些片段回答问题。
在最后一步生成回答中,模型需要做的事情是:理解用户的问题,阅读给定的文本片段,然后组织语言回答。这正是 Chat 模型擅长的——理解指令、根据上下文回答问题。
基座模型做不到这一点。你把问题和文本片段塞给基座模型,它可能会接着你的文本继续"写"下去,而不是回答你的问题。
所以在整个 RAG 系列中,我们调用的都是 Chat 模型。
3. 本地部署模型时的量化
前面的命名规则表格里提到了 -GPTQ、-AWQ 这类后缀,它们代表的是模型的量化版本。
3.1 什么是量化
大模型的参数本质上就是一堆数字(权重)。
这句话怎么理解?你可以把大��模型想象成一个巨大的打分表。当你输入一句话时,模型会把这句话拆成一个个词(token),然后通过成千上万层的计算,最终算出下一个词最可能是什么。而每一层计算里用到的那些乘法系数、加法偏移量,就是所谓的参数——它们都是具体的数字,比如 0.0012、-1.357、0.889 这样的小数。
举个简化的例子:假设模型要判断“今天天气”后面接什么词,它内部可能有这样的计算:
"晴" 的得分 = 输入向量 × 0.82 + (-0.15) = 3.7
"雨" 的得分 = 输入向量 × 0.41 + 0.23 = 1.2
这里的 0.82、-0.15、0.41、0.23 就是参数(权重)。模型在训练阶段通过海量文本不断调整这些数字,让它的打分越来越准。训练完成后,这些数字就固定下来,保存成文件——这就是你下载到的模型文件。
所谓 7B 模型有 70 亿参数,意思就是模型里有 70 亿个这样的数字。训练时这些数字通常用高精度的浮点数存储,比如 FP16(16 位浮点数)或 BF16(16 位脑浮点数),每个参数占 2 个字节。一个 7B 的模型,光是存储权重就需要约 14GB 显存。
在展开量化之前,先搞清楚这些精度格式到底是什么。
3.1.1 浮点数精度:FP32、FP16、BF16 都是什么
计算机用浮点数来表示带小数点的数字。一个浮点数由三部分组成:
- 符号位(Sign):1 位,表示正数还是负数
- 指数位(Exponent):决定数字的范围(能表示多大或多小的数)
- 尾数位(Mantissa / Fraction):决定数字的精度(小数点后能精确到第几位)
打个比方:假设你在一张小纸条上写快递地址,但纸条大小有限,总共只能写一定数量的字:
- 符号位就像写“寄/退”:只需要 1 个字,表明方向
- 指数位就像写“省市”:字数越多,能定位到的地理范围越精确(只写“广东”还是能写到“广东省深圳市”)
- 尾数位就像写“门牌号”:字数越多,地址越精确(写到“xx 小区”还是能精确到“xx 栋 xx 室”)
纸条就那么大,给“省市”多写几个字(指数位多),能覆盖的范围就更大;给“门牌号”多写几个字(尾数位多),定位就更精确。不同的浮点格式,本质上就是在“范围”和“精度”之间做不同的取舍:
| 格式 | 纸条大小(总位数) | 省市部分(指数位) | 门牌号部分(尾数位) | 能寄多远(数值范围) | 地址能写多细(精度) |
|---|---|---|---|---|---|
| FP32 | 32 格(4 字节) | 8 格 | 23 格 | 全球都能寄(±3.4×10³⁸) | 精确到xx栋xx单元xx室 |
| TF32 | 19 格(NVIDIA 专用) | 8 格 | 10 格 | 全球都能寄(同 FP32) | 精确到xx栋xx单元 |
| BF16 | 16 格(2 字节) | 8 格 | 7 格 | 全球都能寄(同 FP32) | 只能到xx栋 |
| FP16 | 16 格(2 字节) | 5 格 | 10 格 | 只能寄本省(±65504) | 精确到xx栋xx单元 |
可以看到关键的区别:
- FP32 纸条最大,省市和门牌号都写得很详细,但太占空间
- TF32 是 NVIDIA 把 FP32 的门牌号砍短了,范围不变但精度降低,GPU 内部自动使用
- BF16 省市部分和 FP32 一样详细(8 格),所以范围一样大,但门牌号只剩 7 格,精度最低
- FP16 把更多格子给了门牌号(10 格),精度比 BF16 高,但省市部分只有 5 格,能覆盖的范围小很多
用一句话总结每种格式的特点:
| 格式 | 位数 | 每参数占用 | 核心特点 |
|---|---|---|---|
| FP32 | 32 位 | 4 字节 | 传统的“全精度”,范围大、精度高,但太占显存,现在很少直接用来存模型权重 |
| TF32 | 19 位 | — | NVIDIA Ampere 架构(A100 等)引入的格式,保留 FP32 的范围但砍掉一半精度,GPU 内部自动使用,开发者一般不用管 |
| FP16 | 16 位 | 2 字节 | “半精度”,体积是 FP32 的一半,但能表示的数值范围很小(最大约 6.5 万),训练时容易溢出 |
| BF16 | 16 位 | 2 字节 | Google 提出的“脑浮点”,和 FP16 一样大,但把更多位数分给了指数(范围和 FP32 一样大),牺牲了一点精度换来了训练稳定性 |
FP16 和 BF16 同样都是 16 格的纸条,但分配方式完全不同:
- FP16:省市部分只给了 5 格,门牌号给了 10 格 → 地址写得很细,但只能寄本省,寄远了就"查无此地"(术语叫溢出)
- BF16:省市部分给了 8 格,门牌号只剩 7 格 → 全球都能寄,但地址写得比较粗,可能只到楼栋级别
打个比方:FP16 就像一个只做同城配送的快递员,他能把包裹精确送到你家门口,但出了本市就没辙;BF16 则像一个全国快递员,哪个省都能送到,但可能只送到小区门口,最后几百米得你自己走。
对于大模型训练来说,参数的数值变化范围非常大,如果“寄不到”(溢出)就直接算错了,而“地址粗一点”(精度低一点)影响没那么致命。所以 BF16 成了目前大模型训练和推理的主流选择。
你在 Hugging Face 上看到的大多数模型,默认权重格式就是 BF16。当我们说“原始精度”或“未量化”时,通常指的就是 BF16(而不是 FP32)。
3.1.2 量化:用更低的精度换更小的体积
理解了上面的精度格式之后,量化就很好理解了——它就是把模型权重从 BF16/FP16(16 位)进一步压缩到更低的位数,比如 INT8(8 位整数)或 INT4(4 位整数)。精度降低了,每个参数占用的空间也就小了:
| 精度 | 每个参数占用 | 7B 模型显存估算 | 说明 |
|---|---|---|---|
| FP32 | 4 字节 | ~28 GB | 全精度,现在基本不用来存储模型权重 |
| BF16 / FP16 | 2 字节 | ~14 GB | 当前模型的默认精度 |
| INT8 | 1 字节 | ~7 GB | 轻度量化,效果损失很小 |
| INT4 | 0.5 字节 | ~3.5 GB | 主流量化选择,效果有一定损失但通常可接受 |
上面的显存估算只是模型权重本身的大小。实际运行时还需要额外的显存用于 KV Cache(存储上下文信息)、计算中间结果等,所以真实显存占用会比表格中的数字更高。一般建议预留权重大小 1.2~1.5 倍的显存。
3.2 常见的量化格式
在 Hugging Face 上下载模型时,你会看到各种量化后缀,主要有这几种:
| 格式 | 全称 | 特点 |
|---|---|---|
| GPTQ | GPT Post-Training Quantization | 需要 GPU 推理;量化后精度较好;社区支持广泛 |
| AWQ | Activation-aware Weight Quantization | 需要 GPU 推理;比 GPTQ 更快,精度相当;较新的方案 |
| GGUF | GPT-Generated Unified Format | 支持 CPU 推理(也支持 GPU);llama.cpp 生态的标准格式;适合没有独显或显存不够的场景 |
简单来说:有 NVIDIA 显卡优先选 AWQ 或 GPTQ,显卡不够或者想用 CPU 跑就选 GGUF。
3.3 量化等级怎么选
以 GGUF 格式为例,你经常会看到 Q4_K_M、Q5_K_M、Q8_0 这样的标注,数字越大精度越高、文件越大:
- Q4_K_M:4 位量化,体积最小,适合显存紧张的场景,是性价比最高的选择
- Q5_K_M:5 位量化,效果和体积的平衡点
- Q8_0:8 位量化,接近原始精度,但体积也大得多
对于大多数本地部署场景,INT4(Q4_K_M)就够用了。除非你对输出质量有�很高的要求,否则没必要追求更高精度。
3.4 开发者需要关心吗
如果你通过 API 调用模型(比如调用 SiliconFlow、硅基流动等平台上的模型),量化这件事完全不用关心——平台方已经帮你处理好了部署和优化。
只有在本地部署模型时,你才需要根据自己的硬件条件选择合适的量化版本。关于本地部署的完整流程(包括如何选模型、选量化、配置推理框架等),后续在讲解本地部署模型时会详细说明。
深度思考:大模型的深度思考模式
如果你用过 DeepSeek 的网页版,可能注意到它有一个深度思考开关。打开之后,模型回答问题的速度会明显变慢,但回答的质量——尤其是在数学、逻辑推理这类问题上——会有明显提升。
这个深度思考背后的核心技术叫思维链(Chain of Thought,CoT)。搞清楚它是怎么回事,能帮你理解什么时候该用、什么时候没必要用。
1. 普通对话 vs 深度思考
普通对话模式下,模型看到问题后直接给出答案,像脱口而出一样。这对于简单问题完全够用,比如 Python 怎么读取 JSON 文件——答案是确定的,不需要复杂推理。
深度思考模式下,模型会先在内部进行一步步的推理(这个过程叫 thinking),把推理过程写出来,然后再给出最终答案。就像考试时,有些题你一眼就能看出答案,直接写上去;有些题你需要先在草稿纸上演算一番,再把最终结果写到答题卡上。
深度思考就是那个在草稿纸上演算的过程。
2. 思维链(Chain of Thought)是怎么回事
思维链的核心思想很简单:让模型把推理过程一步步说出来,而不是直接跳到结论。
为什么这样做效果更好?你可以这样理解:当你心算 17 × 24 的时候,直接算很容易出错。但如果你把过程写出来——17 × 24 = 17 × 20 + 17 × 4 = 340 + 68 = 408——正确率就高多了。大模型也是一样,把推理过程展开,每一步都“想清楚”再往下走,比直接蹦出一个答案要靠谱得多。
DeepSeek-R1 的深度思考就是基于这个原理。模型在回答之前,会先生成一段 thinking 内容(推理过程),这段内容对用户可见(在网页端会折叠显示),然后再输出最终答案。
3. thinking 内容长什么样
来看一个具体的例子。假设你问 DeepSeek-R1:一个水池有两个进水管,A 管单独注满需要 6 小时,B 管单独注满需要 8 小时。两管同�时开,多久能注满?
普通对话模式的回答可能直接给出:
两管同时开,注满水池需要 24/7 小时,约 3.43 小时。
深度思考模式的回答会分两部分:
thinking 部分(推理过程):
用户问的是一个经典的水池注水问题,我来分析一下。
A 管单独注满需要 6 小时,所以 A 管每小时注入水池的 1/6。 B 管单独注满需要 8 小时,所以 B 管每小时注入水池的 1/8。
两管同时开,每小时注入量 = 1/6 + 1/8。 通分:1/6 = 4/24,1/8 = 3/24。 所以每小时注入量 = 4/24 + 3/24 = 7/24。
注满整个水池需要的时间 = 1 ÷ (7/24) = 24/7 ≈ 3.43 小时。
换算一下:3 小时 + 0.43 × 60 ≈ 3 小时 26 分钟。
最终答案:
A 管每小时注入 1/6 池,B 管每小时注入 1/8 池,两管同时开每小时注入 7/24 池。注满整个水池需要 24/7 小时,约 3 小时 26 分钟。
你会发现,thinking 部分就像草稿纸上的演算过程,最终答案是整理后的结论。thinking 过程帮助模型“想清楚”了每一步,所以最终答案更准确。
4. 什么时候该用深度思考
深度思考不是万能的。它会让模型的响应速度变慢(因为要先生成 thinking 内容),Token 消耗也会增加(thinking 内容也算 Token)。所以要根据场景来选择。
| 场景 | 是否需要深度思考 | 原因 |
|---|---|---|
| 数学计算、逻辑推理 | 需要 | 需要一步步推导,直接回答容易出错 |
| 复杂代码生成 | 需要 | 需要先分析需求、设计思路,再写代码 |
| 多步骤分析(如对比多个方案的优劣) | 需要 | 需要逐个分析再综合判断 |
| 简单问答(如 Python 怎么读 JSON) | 不需要 | 答案是确定的,不需要推理 |
| 日常闲聊 | 不需要 | 没有推理需求 |
| RAG 场景下的知识检索回答 | 通常不需要 | 答案已经在检索到的文本片段里了,模型只需要整理和表达,不需要复杂推理 |
RAG 系统中,大模型的任务是根据给定的文本片段回答用户的问题。答案就在片段里,模型要做的是理解、提取和组织语言,而不是推理和计算。所以 RAG 场景下通常用普通对话模式就够了,没必要开深度思考——既省 Token,响应也更快。
网页端 vs API 调用:为什么开发者需要 API
到这里,你对大模型已经有了一个基本的认知。但还有一个关键问题没解决:你在 DeepSeek 网页版上体验到的能力,怎么搬到你的 Java 系统里?
1. 你在网页端用 DeepSeek 时,背后发生了什么
你打开 DeepSeek 的网页��,输入一个问题,等几秒钟,回答就出来了。这个过程背后其实是这样的:
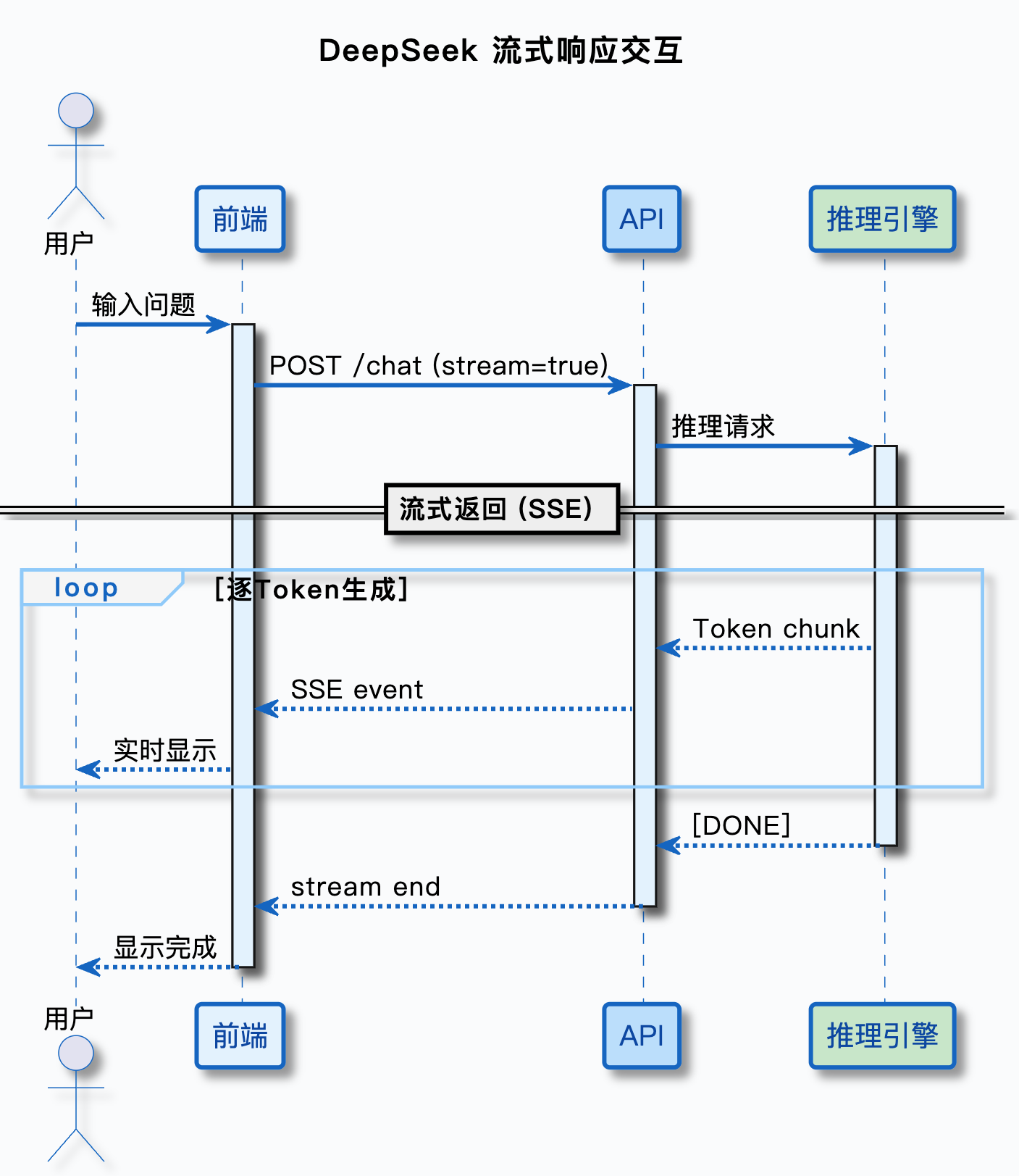
看到了吗?你在网页端用的,本质上也是 API 调用——只不过 DeepSeek 帮你做了前端界面,把 API 调用的细节藏在了背后。
2. 网页端的局限性
网页端是给个人用户设计的产品,对于开发者来说,它有几个明显的局限:
- 不能集成到你的系统里。你的客服系统是 Java 写的,你没法让它打开浏览器去 DeepSeek 网页上问问题
- 不能批量处理。你有 1000 条用户反馈要分析,总不能一条一条复制粘贴到网页上
- 不能自定义提示词模板。网页端的系统提示词是固定的,你没法告诉模型“你是一个电商客服,只回答退货相关的问题”
- 不能控制参数。Temperature、最大输出长度这些参数,网页端要么不开放,要么只有有限的选项
- 不能做 RAG。RAG 需要先检索知识库,再把检索结果和问题一起发给模型——这个流程在网页端没法实现
- 数据安全问题。你的业务数据要通过浏览器发到别人的服务器上,对于有数据安全要求的企业来说,这是不可接受的
3. API 调用能做什么
通过 API 调用大模型,本质上就是把大模型当成一个远程函数来用:你发一段文本过去,它返回一段文本回来。
这个函数的输入输出大概长这样(伪代码):
// 伪代码,展示 API 调用的基本概念
String answer = callLLM(
model: "Qwen/Qwen3-32B", // 选择模型
systemPrompt: "你是一个电商客服助手", // 系统提示词
userMessage: "买了一周的东西还能退吗?", // 用户的问题
temperature: 0.1 // 低温度,回答更准确
);
// answer = "根据我们的退货政策,自签收之日起7天内..."
或者用 curl 命令直观感受一下(这是真实的 API 调用格式,下一篇会详细讲):
curl https://api.siliconflow.cn/v1/chat/completions \
-H "Authorization: Bearer 你的API密钥" \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "system", "content": "你是一个电商客服助手"},
{"role": "user", "content": "买了一周的东西还能退吗?"}
],
"temperature": 0.1
}'
有了 API,你就可以在自己的 Java 系统里调用大模型,实现各种功能:智能客服、RAG 问答、文档摘要、内容审核、数据分析……大模型变成了你系统里的一个组件,而不是一个需要手动操作的网页工具。
4. 本系列的技术选型
在后续的系列文章中,我们会通过 API 调用大模型来构建 RAG 系统。这里先说明技术选型:
API 平台:SiliconFlow(硅基流动)
选择 SiliconFlow 的原因:
- 国内平台,网络访问没有障碍
- 注册简单,手机号即可注册
- 新用户有免费额度,足够学习和实验使用
- 支持多种主流开源模型(Qwen、DeepSeek、Llama 等)
- API 兼容 OpenAI 协议——这一点很重要,意味着你学会了调用 SiliconFlow 的 API,以后切换到 OpenAI、DeepSeek 官方 API 或其他兼容平台时,代码几乎不用改
模型选择:Qwen 系列
选择 Qwen 的原因:
- 中文效果好,适合国内业务场景
- 开源,社区活跃,文档完善
- SiliconFlow 上部分 Qwen 模型可免费调用,降低学习成本
- 模型尺寸覆盖全面,从轻量级的 7B 到高性能的 72B 都有,可以根据场景灵活选择
为什么不直接用 OpenAI(GPT 系列)?三个原因:一是网络问题,国内访问 OpenAI 的 API 需要特殊网络环境;二是成本问题,GPT-4 的 API 价格不低;三是中文效果,国内开源模型在中文场景下的表现已经非常出色,没必要舍近求远。
小结与下一篇预告
这一篇咱们从零开始,把大模型的核心认知梳理了一遍:
- 大模型通过阅读海量文本学会了语言的规律,能真正理解自然语言,这是它和传统编程、传统 NLP 的本质区别
- 参数量决定了模型的大脑容量,但不是越大越好,要根据场景选择合适的尺寸
- Token、上下文窗口、Temperature 是调用 API 时绑定出现的核心概念
- 我们调用的都是 Chat 模型(经过对齐训练的模型),不是基座模型
- 深度思考(CoT)适合推理场景,RAG 场景下通常不需要
- 开发者需要通过 API 调用大模型,才能把它集成到自己的系统中
下一篇是 RAG 之模型调用 API,会正式动手写代码。内容包括:OpenAI 接口协议的结构(为什么大家都兼容这个协议)、在 SiliconFlow 平台注册并获取 API Key、用 Java + OkHTTP 实现非流式调用和流式调用、亲手体验通过代码和大模型对话。
到时候你会发现,调用大模型 API 其实就是发一个 HTTP 请求——对于 Java 开发者来说,这再熟悉不过了。