oneThread:
美团动态线程池项目实战
基于配置中心构建的动态可观测Java线程池框架,弥补了JDK原生线程池参数配置不灵活的不足,支持核心参数的在线动态调整、监控与阈值告警。框架兼容主流配置中心如Nacos、Apollo,实现线程池参数的热更新与统一管理。
了解详情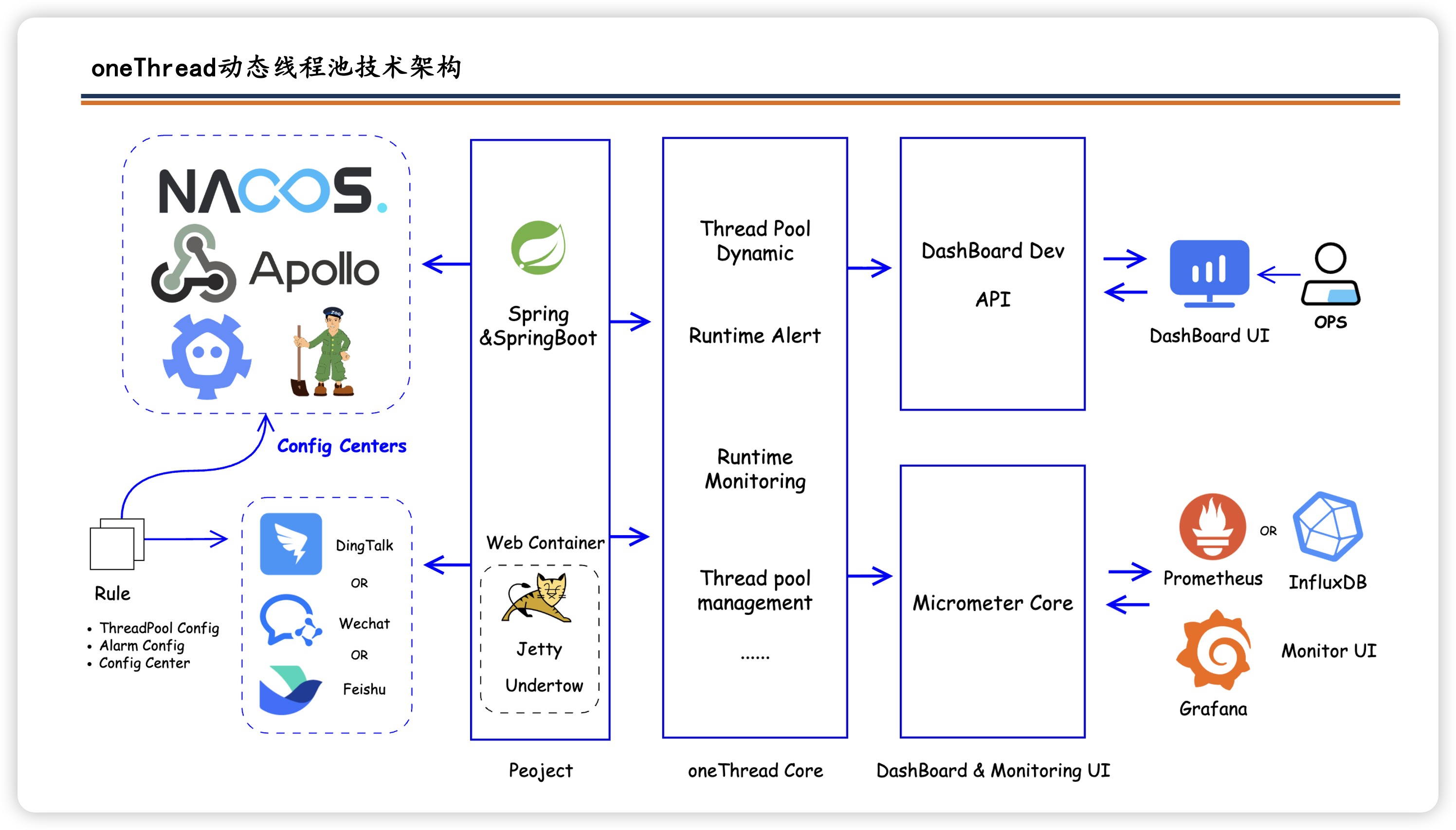
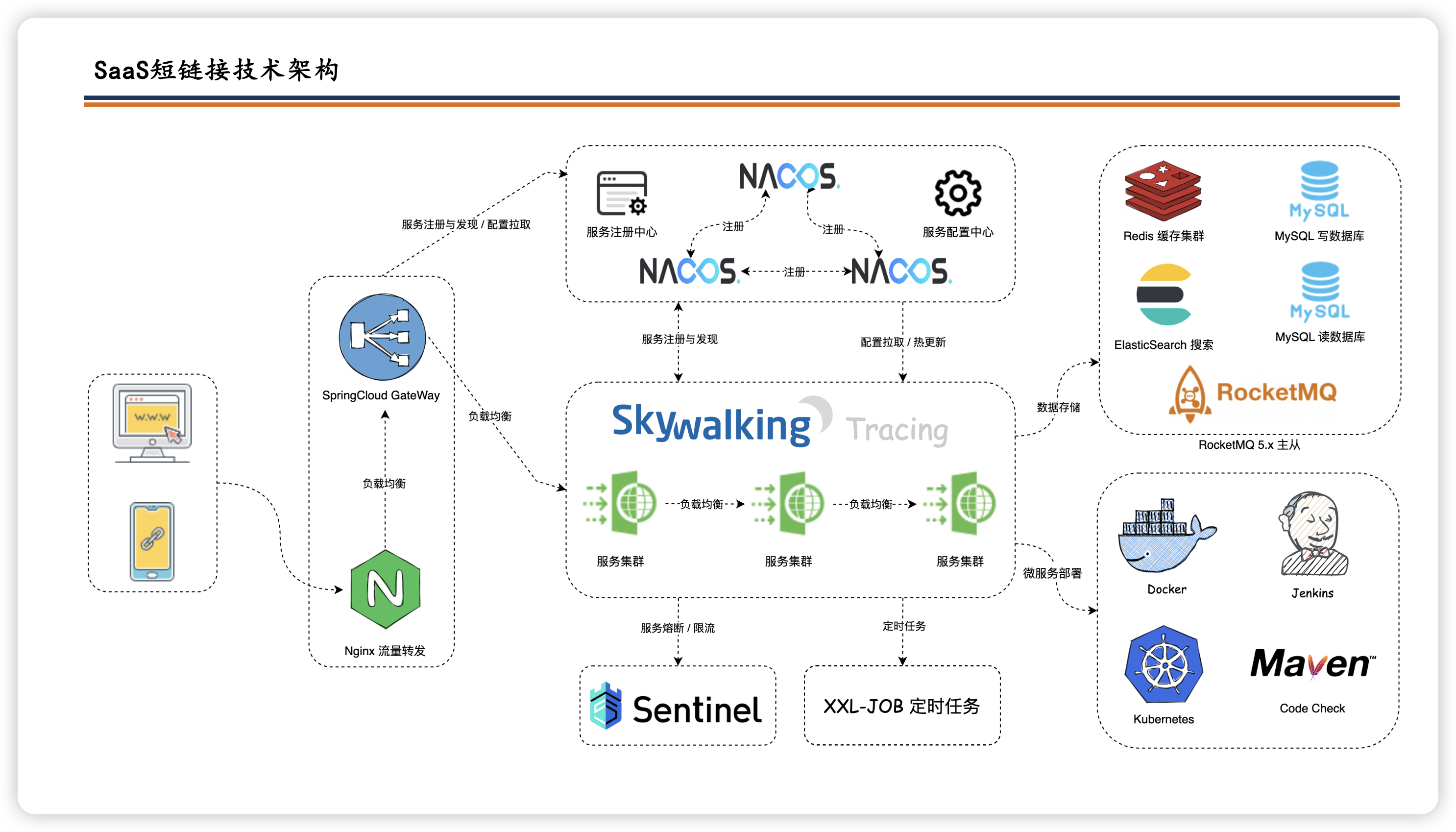
牛券:
oneCoupon优惠券平台
牛券系统,春招、秋招、应届、社招项目。SpringBoot3+SpringCloud Alibaba+RocketMQ+ElasticSearch等技术架构,完成优惠券秒杀+分发+结算+搜索等服务,帮助学生主打就业的项目。
了解详情
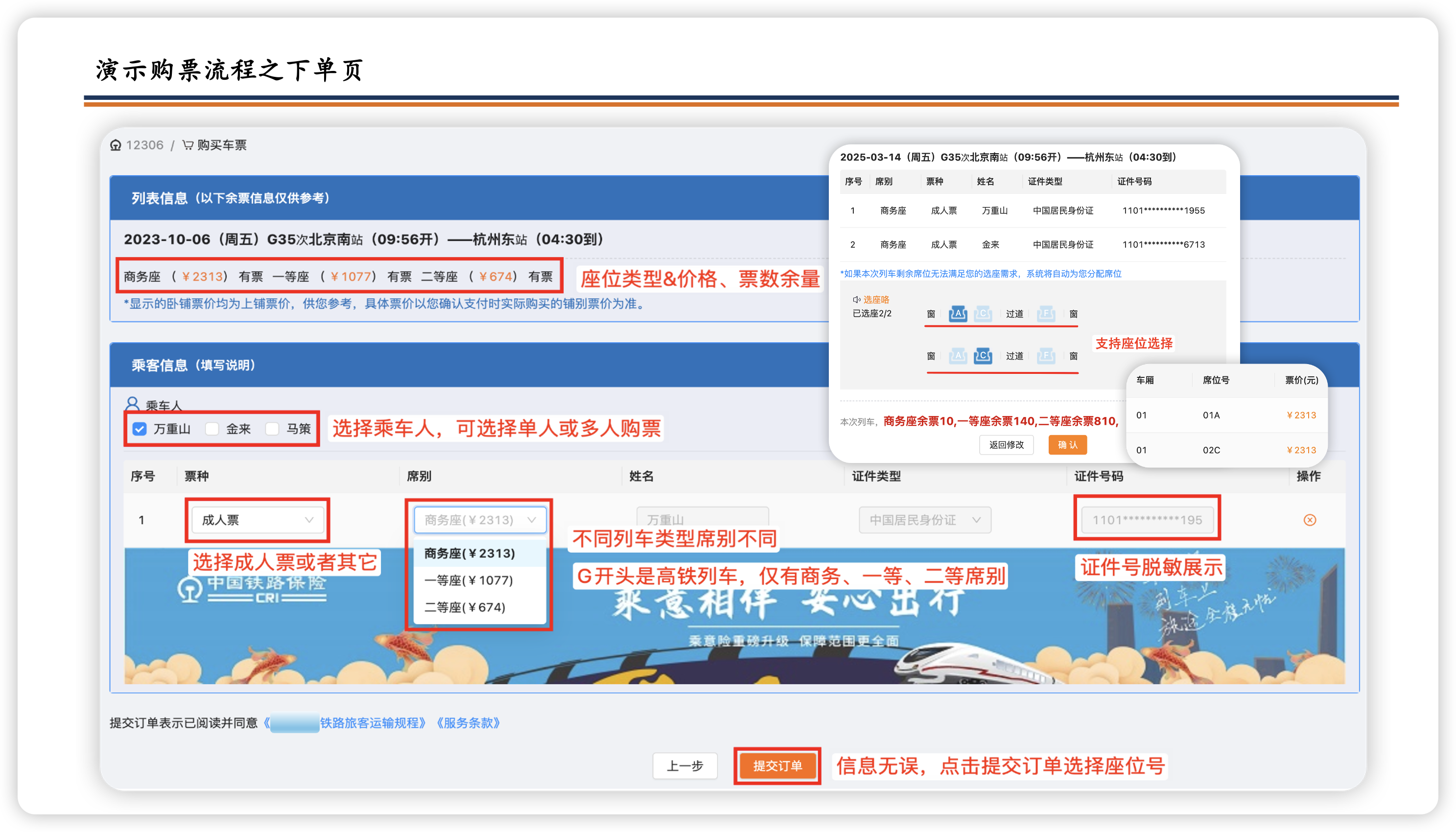
12306:
智能铁路购票平台
大学春招、秋招、应届项目,SpringBoot3+Java17+SpringCloud Alibaba+Vue3 等技术架构,完成高仿铁路12306用户+抢票+订单+支付服务,帮助学生主打就业的项目。
了解详情