11小节:开发XXL-Job执行推送定时任务
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
开发XXL-Job定时任务执行分发数据,元数据信息:
- 什么是牛券oneCoupon:https://t.zsxq.com/pAWgS
- 代码仓库:https://gitcode.net/nageoffer/onecoupon —— 申请项目权限参考上述牛券项目链接
- 章节难度:★★★☆☆ - 较难
- 视频地址:文档先行视频次之
©版权所有 - 拿个offer-开源&项目实战星球专属学习项目,依据《中华人民共和国著作权法实施条例》和《知识星球产权保护》,严禁未经本项目原作者明确书面授权擅自分享至 GitHub、Gitee 等任何开放平台。违者将面临法律追究。
内容摘要:在本章节我们使用 XXL-Job 来实现定时任务的执行和分发,重点涉及到 XXL-Job 的安装、配置以及在实际业务场景中的应用。然后在 Spring Boot 项目中引入 XXL-Job 的依赖并配置相应的 Spring Bean,从而实现了定时执行优惠券分发任务的功能。
课程目录如下所示:
- 业务背景
- Git 分支
- 什么是 XXL-Job
- 安装 XXL-Job
- 配置 XXL-Job 执行器
- 开发定时执行优惠券分发任务
- SpringBoot 条件注解解耦 XXL-Job
- 文末总结
业务背景
优惠券分发任务分为两种类型:立即执行和定时执行。对于立即执行的任务,我们直接通过消息队列触发发送流程;而定时执行的任务则由定时任务监控系统扫描,找到到达执行时间的任务,然后通过 XXL-Job 分布式定时框架进行处理。
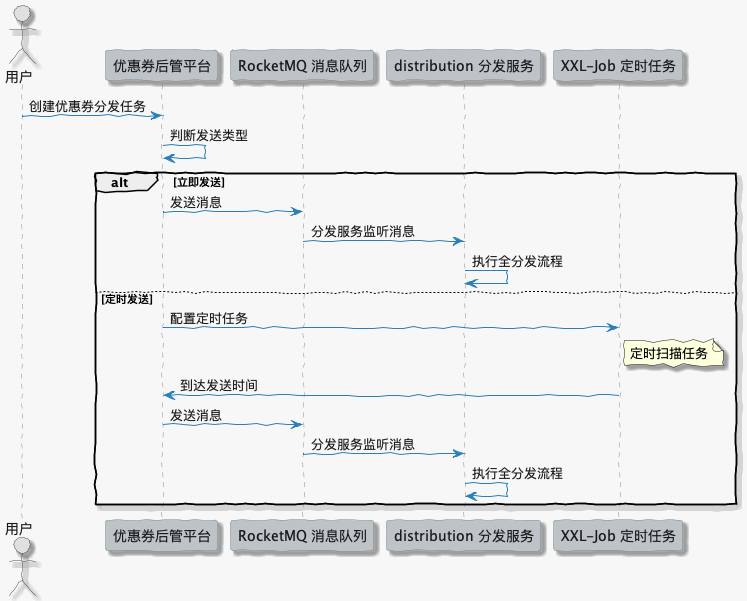
Git 分支
20240825_dev_coupon-task-timing_xxl-job_ding.ma
什么是 XXL-Job
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
- XXL-Job GitHub 地址:https://github.com/xuxueli/xxl-job
- 官方网站:https://www.xuxueli.com/xxl-job
XXL-Job 2.4.0 架构图如下所示:

安装 XXL-Job
考虑到使用 Docker 安装可能会涉及 Mac 英特尔和 ARM 芯片的区别,为了避免复杂性扩散,所以我们这里仅使用最为原始且高效的方式,拉取源代码构建的方式启动。
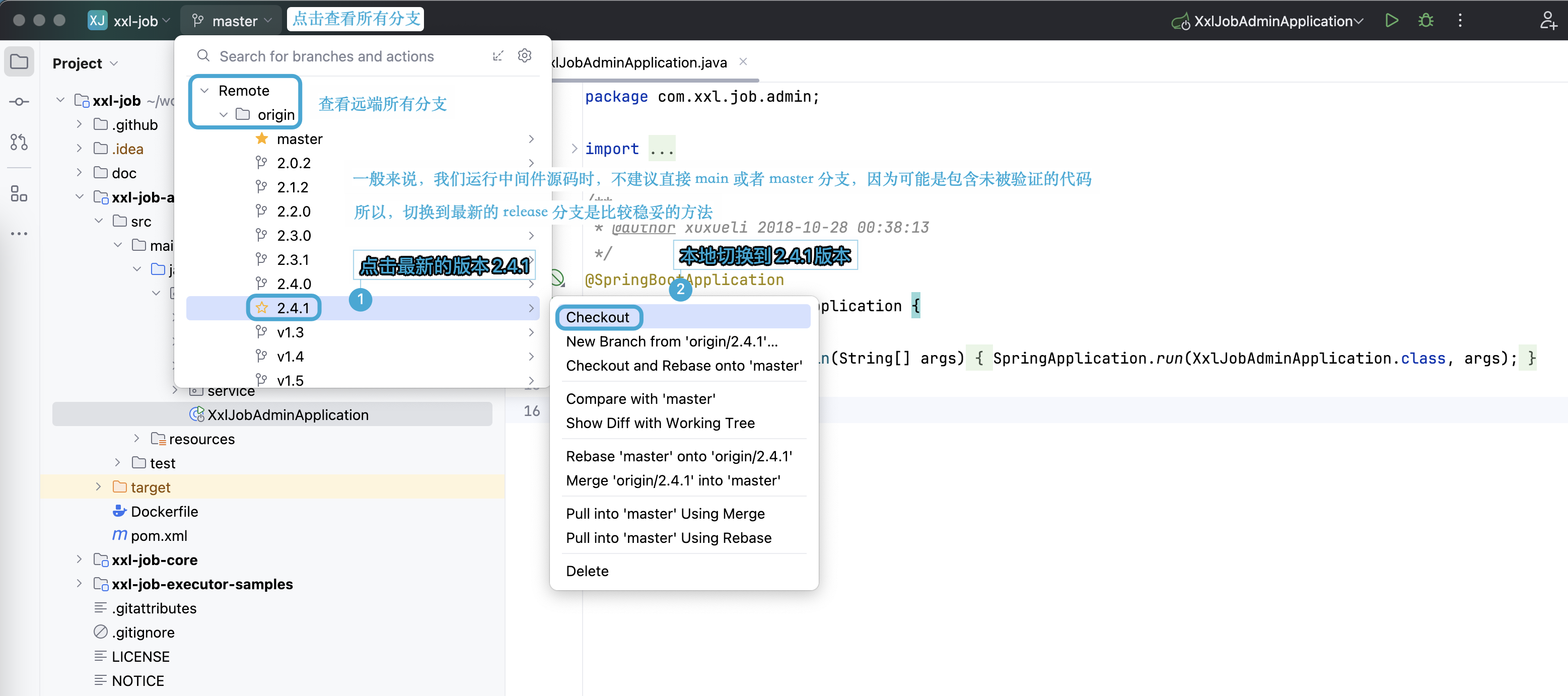
1. IDEA 下载 XXL-Job 源代码
通过 Git SSH 的方式拉取 XXL-Job 源代码仓库,SSH 地址:git@github.com:xuxueli/xxl-job.git
我们从 master 分支切换到截止目前 2024.08.25 日最新的发版分支 2.4.1 版本。
2. 初始化 XXL-Job 数据库
MySQL 中创建名称为 xxl_job 的数据库,并执行下述 SQL 语句:
#
# XXL-JOB v2.4.1
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
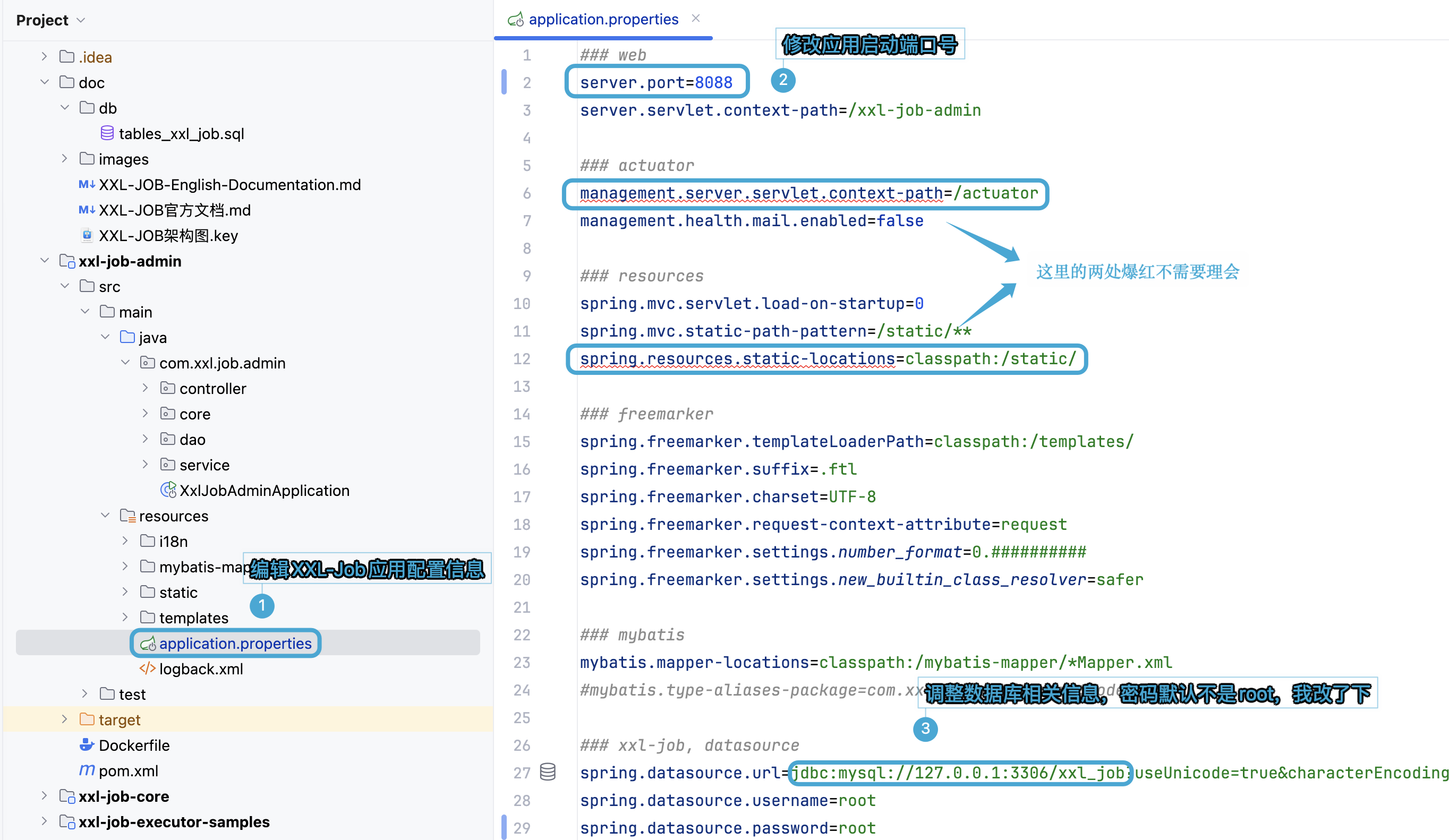
我们点击 application.properties 修改其中的 MySQL 连接配置,比如我本地默认密码是 root,就需要改动下。
因为本地 8080 端口容易被占用,那我们最好提前改下 server.port,比如改为 8088 或其他没有被�使用的端口。在这里我们修改为 8088 端口。
3. 启动 XXL- Job 服务
有一点不得不说,XXL-Job 的 JDK 适配做的真的好,我一开始以为只有 JDK8 能启动,刚拉下来的时候默认 JDK21 了,发现启动没问题,点赞 👍。
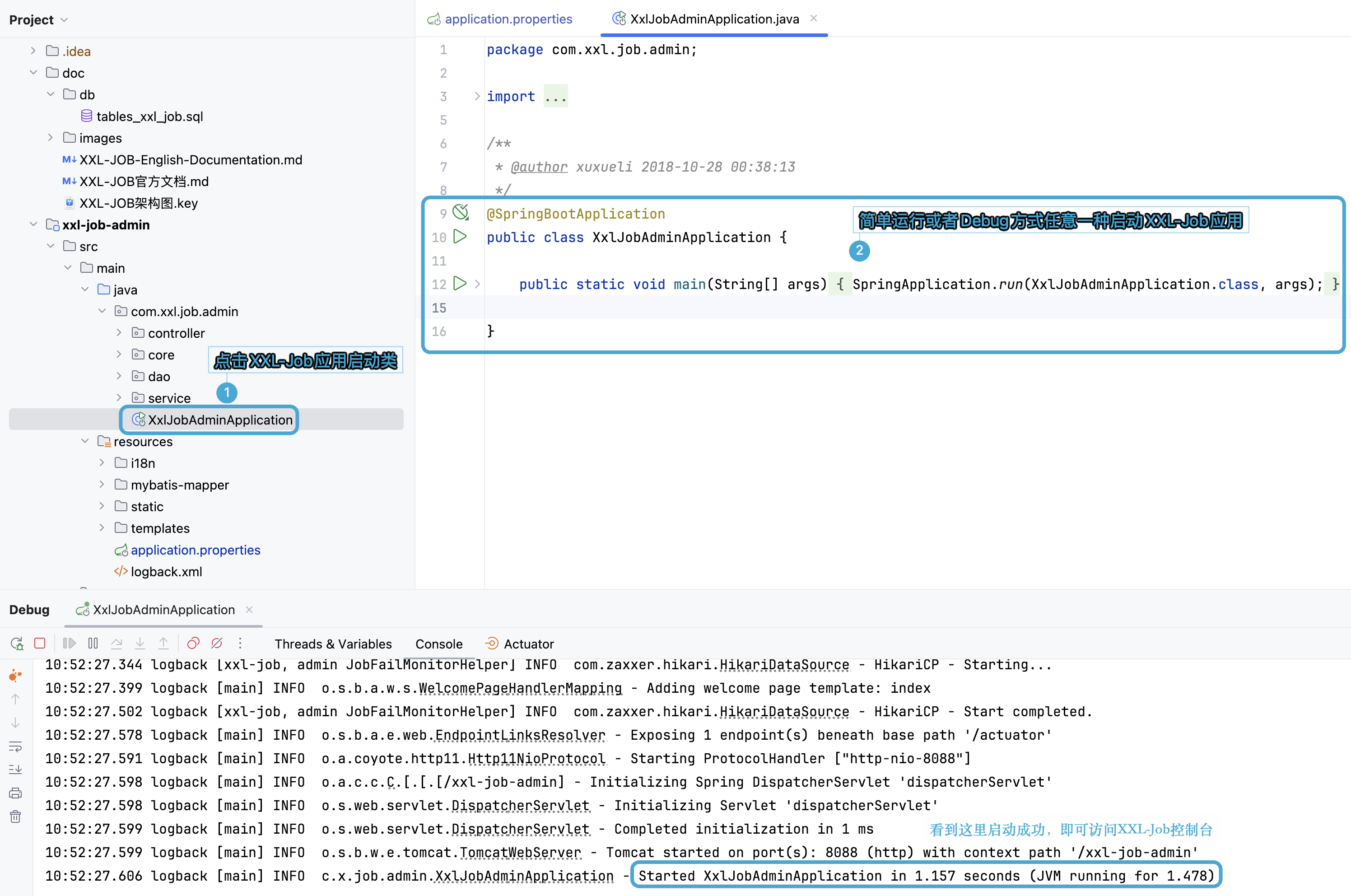
访问 XXL-Job 控制台地址 http://localhost:8088/xxl-job-admin,出现控制台页面即可。
默认用户名密码:admin/123456
配置 XXL-Job 执行器
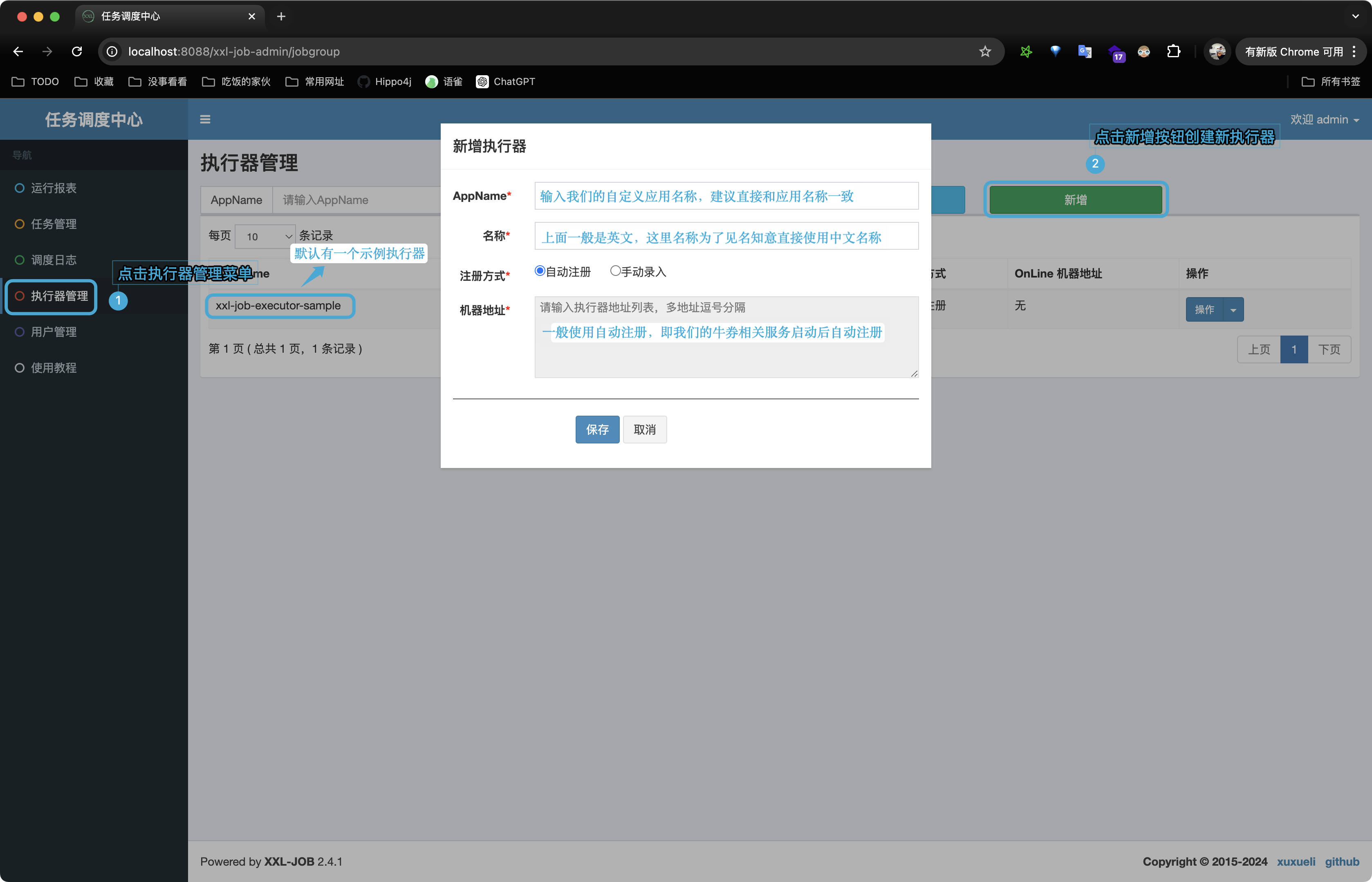
1. 创建执行器
XXL-Job 执行器是一个运行在目标服务器上的应用程序模块,用于实际执行由调度中心下发的任务。执行器可以看作是任务的“工作节点”,负责接收调度中心发送的任务调度请求并执行具体的任务逻辑。
创建执行器,配置如下:
- AppName:one-coupon-merchant-admin
- 名称:牛券后管平台
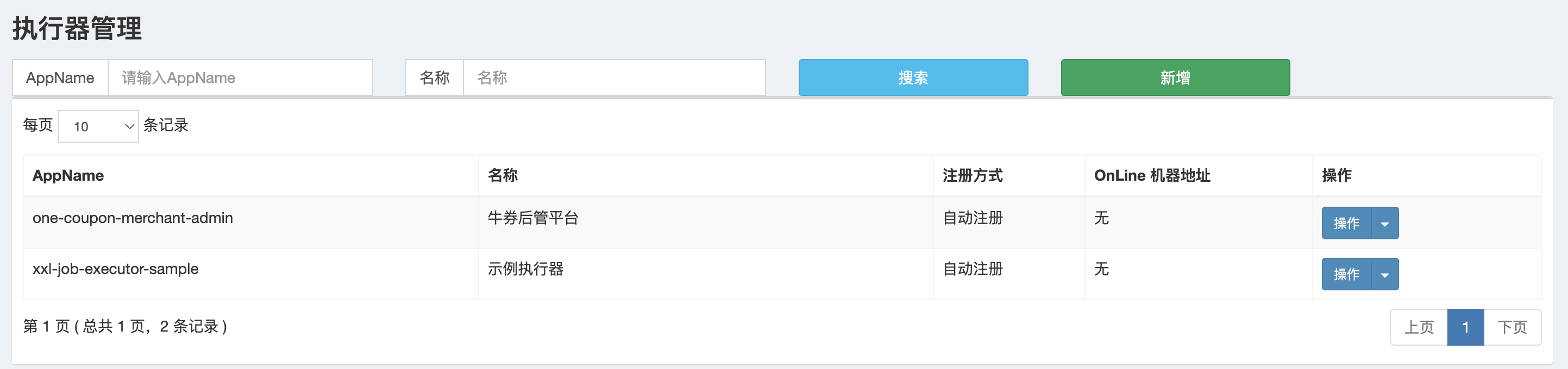
可以看到创建成功。有同学会问,为什么机器地址为空,因为我们的项目还没有引入 XXL-Job,等引入后这里就有机器地址了。
2. 创建执行器任务
执行器可以看作是和我们应用系统一一对应,那执行器任务就是应用系统里里定时任务。
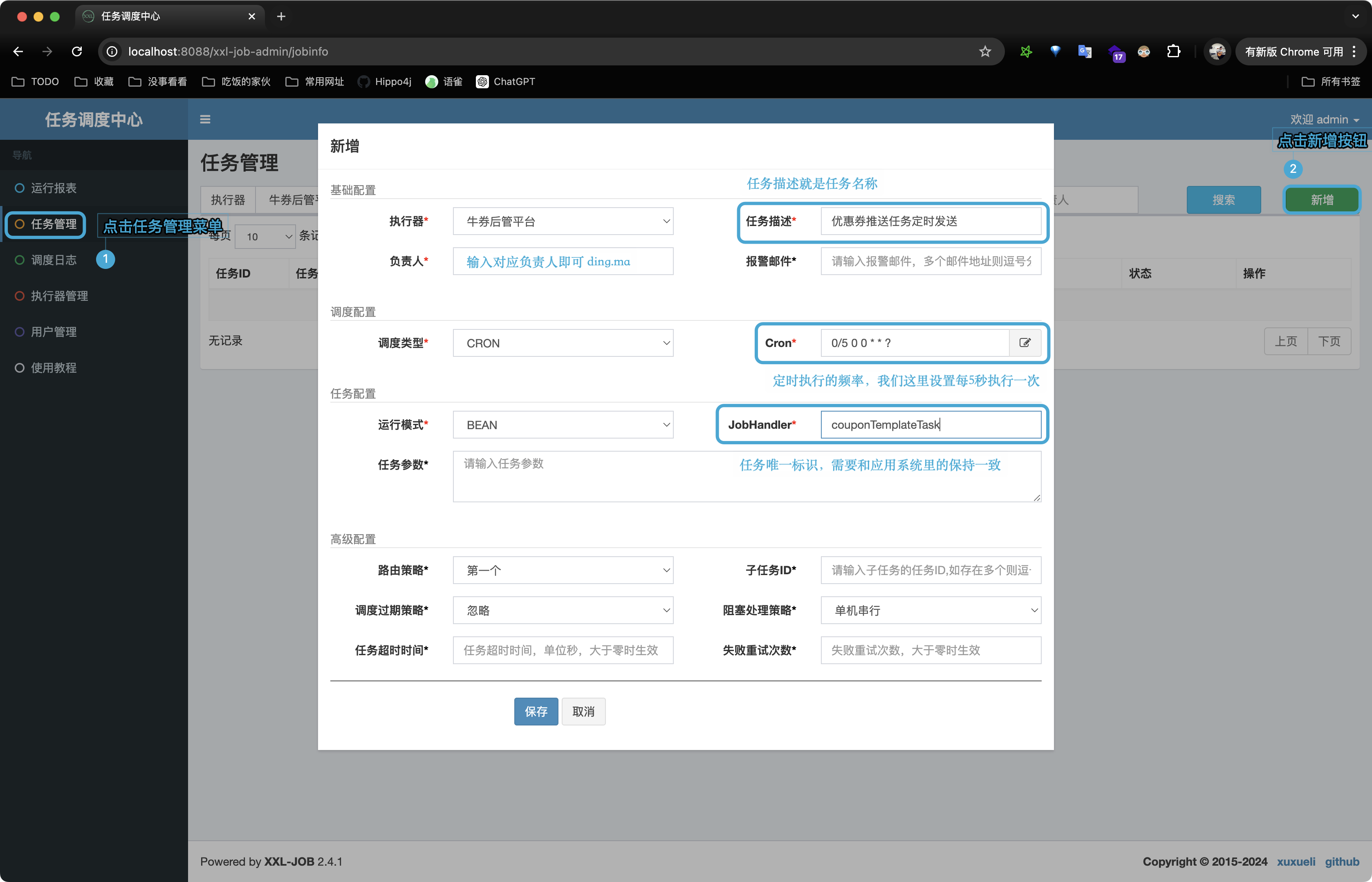
点击保存按钮,页面刷新得知任务创建成功。
3. 执行器任务参数
有些同学可能会提出疑问,关于运行模式、路由策略、调度过期策略、阻塞处理策略分别都是什么意思?我们详细来说一下。
3.1 运行模式
- BEAN 模式:通过 Spring 管理的 Bean 来执行任务。
- GLUE 模式:通过在 XXL-Job 控制台上直接编写的脚本(如 Groovy、Java 等)来执行任务。
3.2 路由策略
因为我们服务可能会启动多个应用实例,所以选择哪个执行器服务调用就需要我们选择,也就是路由策略。
- 第一个:选择执行器列表中的第一个执行器来执行任务。适用于简单场景或对负载均衡要求不高的场景。
- 最后一个:选择执行器列表中的最后一个执行器来执行任务。通常用于测试或特定需要时使用。
- 轮询:采用轮询方式依次选择执行器来执行任务,每次调度都会选择下一个执行器,依次循环。适用于需要均衡任务在所有执行器上的负载的场景,简单且有效的负载均衡策略。
- 随机:从可用的执行器列表中随机选择一个执行器来执行任务。适用于负载均衡且不在意特定执行器的场景。
- 一致性HASH:基于任务的特征(如任务参数或任务 ID)计算哈希值,然后选择对应的执行器。适用于需要确保相同特征的任务始终由同一个执行器执行的场景,如缓存命中或分布式锁的场景。
- 最不经常使用:选择执行任务次数最少的执行器来执行任务。适用于需要避免热点执行器、希望均衡执行器使用频率的场景。
- 最近最少使用:选择最近最少使用的执行器来执行任务。适用于希望在所有执行器之间均衡调度,同时避免某些执行器长时间闲置的场景。
- 故障转移:如果一个执行器执行失败,则尝试在其他执行器上执行任务,直到成功为止。适用于对任务执行可靠性要求较高的场景,需要确保任务至少执行一次。
- 忙碌转移:将任务交给当前任务队列最少的执行器。如果所有执行器都忙碌,则会选择任务队列最少的执行器执行。适用于需要尽可能均衡执行器任务负载的场景。
- 分片广播:任务被广播到所有的执行器节点上,每个执行器执行一遍。此策略主要用于分片任务的调度,配合任务分片参数可以实现分片执行。适用于大数据量任务需要在多台执行器上同时执行的场景。