03小节:完成优惠券模板分库分表功能
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
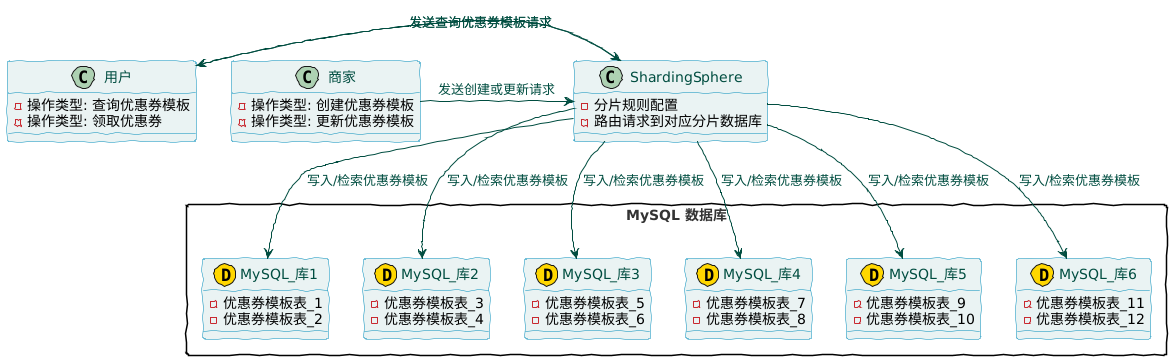
通过ShardingSphere完成优惠券分库分表,元数据信息:
- 什么是牛券oneCoupon:https://t.zsxq.com/pAWgS
- 代码仓库:https://gitcode.net/nageoffer/onecoupon —— 申请项目权限参考上述牛券项目链接
- 章节难度:★★★☆☆ - 较难
- 视频地址:文档先行视频次之
©版权所有 - 拿个offer-开源&项目实战星球专属学习项目,依据《中华人民共和国著作权法实施条例》和《知识星球产权保护》,严禁未经本项目原作者明确书面授权擅自分享至 GitHub、Gitee 等任何开放平台。违者将面临法律追究。
内容摘要:讲解分库分表背景、技术选型等方案,通过优惠券模板为切入点,说明业务代码如何完成分库分表改造。
课程目录如下所示:
- 业务说明
- 分库分表概述
- 分库分表设计
- 分库分表框架选型
- 为什么不使用分布式数据库?
- Git 分支
- 优惠券模板如何分库分表?
- ShardingSphere 项目实战
- 常见问题答疑
业务说明
创建优惠券的主力是商家用户,按照淘宝、天猫非官方数据统计,商家数量已有近 3000万。我们假设每个商家会创建 100 张优惠券,那优惠券模板表就会接近 300 亿数据量。
为什么是假设?因为优惠券创建行为隶属于每一个商家,不管是平台还是任何人,都只能以常规数据进行推测。
这个推测也是具备时效性的,随着时间的推迟,商家会更多,同时创建的优惠券也可能会更多,预估数据也会随之增加。
分库分表概述
分库是将原本的单库拆分为多个库,分表是将原来的单表拆分为多个表。
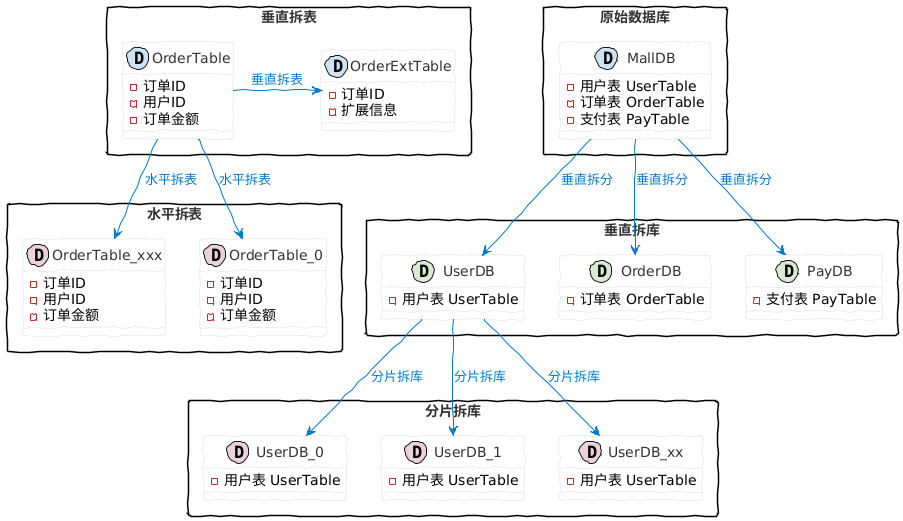
分库有两种模式:
- 垂直拆库:电商库 MallDB,业务拆分后就是 UserDB、OrderDB、PayDB 等。
- 分片拆库:用户库 UserDB,分片库后就是 UserDB_0、UserDB_1、UserDB_xx。
分表也有两种模式:
- 垂直拆分:订单表 OrderTable,拆分后就是 OrderTable 以及 OrderExtTable。
- 水平拆分:订单表 OrderTable,拆分后就是 OrderTable_0、 OrderTable_xxx。
1. 什么场景分表?
当出现以下三种情况的时候,我们需要考虑分表:
- 单表的数据量过大。
- 单表存在较高的写入场景,可能引发行锁竞争。
- 当表中包含大量的 TEXT、LONGTEXT 或 BLOB 等大字段。
2. 什么场景分库?
当出现以下两种情况时,我们需要考虑通过分库来将数据分散到多个数据库实例上,以提升整体系统的性能:
- 当单个数据库支持的连接数已经不足以满足客户端需求。
- 数据量已经超过单个数据库实例的处理能力。
3. 什么场景分库分表?
当出现以下两种场景下,需要进行分库又分表:高并发写入和海量数据:
- 高并发写入场景:当应用面临高并发的写入请求时,单一数据库可能无法满足写入压力,此时可以将数据按照一定规则拆分到多个数据库中,每个数据库处理部分数据的写入请求,从而提高写入性能。
- 海量数据场景:随着数据量的不断增加,单一数据库的存储和查询性能可能逐渐下降。此时,可以将数据按照一定的规则拆分到多个表中,每个表存储部分数据,从而分散数据的存储压力,提高查询性能。
分库分表设计
1. 如何选择分片键?
-
数据均匀性:分片键应该保证数据的均匀分布在各个分片上,避免出现热点数据集中在某个分片上的情况。
-
业务关联性:分片键应该与业务关联紧密,这样可以避免跨分片查询和跨库事务的复杂性。
-
数据不可变:一旦选择了分片键,它应该是不可变的,不能随着业务的变化而频繁修改。
2. 分库分表算法?
分库分表的算法会根据业务的不同而变化,所以并没有固定算法。在业界里用的比较多的有两种:
- HashMod:通过对分片键进行哈希取模的分片算法。
- 时间范围: 基于时间范围分片算法。
分片算法讲解一个数据均匀,时间范围并不适合优惠券模板业务,因为商家用户前期比较少,后面会越来越多,所以有比较明显的不均匀问题。
分库分表框架选型
选择 MyCat 还是 ShardingSphere 取决于项目的具体需求、架构设计、团队技术栈和个人偏好。
- MyCat:https://gitee.com/MycatOne/Mycat2
- ShardingSphere:https://shardingsphere.apache.org
如果项目对功能需求较高,希望在一个较为活跃的社区中获取支持,且对数据库的支持要求较高,那么 ShardingSphere 可能是一个更好的选择。如果项目相对简单,对生态和社区支持要求不高,那么 Mycat 也是一个稳定的选择。
我们可以从下面几个维度做一下评估:
1. 生态和社区支持
Mycat:MyCat 的社区相对较小,更新和支持相对有限。
ShardingSphere:ShardingSphere 是 Apache 旗下的项目,有较大的社区支持,得到了广泛的认可和使用。
2. 社区活跃度
Mycat:社区相对较小,更新和新功能开发可能相对缓慢。
ShardingSphere:由于是 Apache 顶级项目,社区活跃度较高,更新和新功能的开发较为迅速。
3. 分库分表策略
Mycat:Mycat 主要支持水平分表和垂直分库,提供相对基础的分片策略。
ShardingSphere:ShardingSphere 提供了更为灵活和丰富的分库分表策略,支持广泛的分片规则,包括范围、哈希、复合分片等。
为什么不用分布式数据库?
具备代表性分布式数据库:
- 阿里云 PolarDB for MySQL。
- 腾讯云 TDSQL for MySQL。
- PingCAP TiDB。
以下说法谨代表我个人看法:
-
兼容性:部分分布式数据库并不能 100%兼容 MySQL,导致业务无法平滑迁移。
-
技术储备:需要有这方面的分布式数据库专家,平常使用谁都可以,线上出现了问题不知道怎么解决才是致命。
-
使用成本:阿里云和腾讯云没有开源版本,付费版本相对于 MySQL 成本偏高。TiDB 开源版本 Issue BUG 较多,商业未知。