从零到一学习中间件之Sharding-JDBC
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
ShardingSphere 源码地址:https://github.com/apache/shardingsphere
ShardingSphere 官方网站:https://shardingsphere.apache.org
文章描述 ShardingSphere 相关概念和知识,如无特别声明,均是 Apache ShardingSphere 5.3.2 版本。
🔥 SpringBoot Ladder:从零到一学习 SpringBoot 各种组件框架实战的项目,让 Demo 变得简单。咱们文章中的 ShardingSphere 示例也在这个项目。
分库分表背景
传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态性,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。 而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储至原生支持分布式的 NoSQL 的尝试越来越多。 但 NoSQL 对 SQL 的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中始终无法完成致命一击,而关系型数据库的地位却依然不可撼动。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分��片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
分库分表介绍
1. 什么是分库分表?
分库分表是一种数据库分片技术,用于解决大规模应用中单一数据库容量不足以支持高并发和大数据量的问题。它将一个大型的数据库拆分成多个小型数据库,每个小型数据库称为一个分片。每个分片存储部分数据,从而降低了单个数据库的负担。
简单来说,分库是将原本的单库拆分为多个库,分表是将原来的单表拆分为多个表。
很多情况下,分库分表并不是从系统设计开始就存在的,而是系统运行过程中,出现数据量庞大或者查询性能慢等问题延伸而来。
如果你在业务功能开发时,已经预知业务数据库量,应提前进行分库或者分表,做好分片规范,避免系统运行时拆分。
1.1 什么是分库?
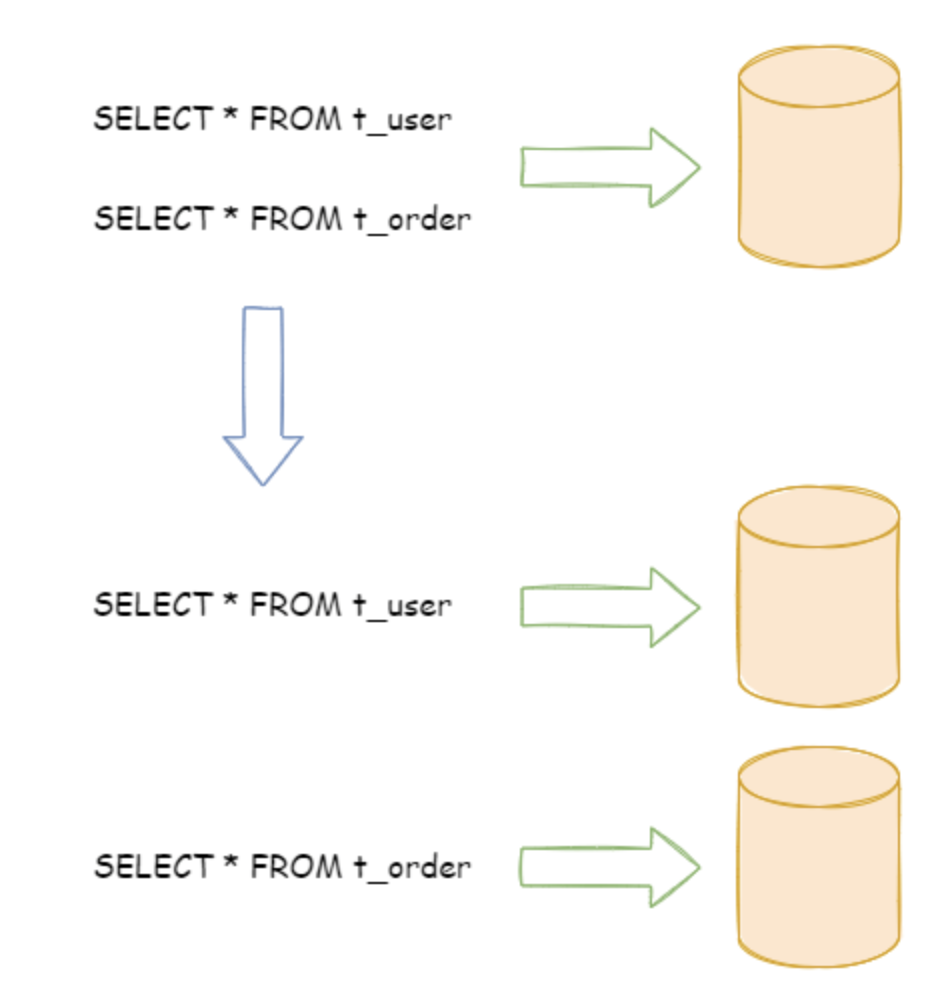
1)垂直分片
比如:电商库 mall_db,业务拆分后就是 user_db、order_db、pay_db...
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
优点:
- 可以针对不同业务场景优化数据库,提高性能。
- 提高了数据库的并发能力。
缺点:
- 需要处理分布式事务的问题。
- 增加了系统的复杂度。
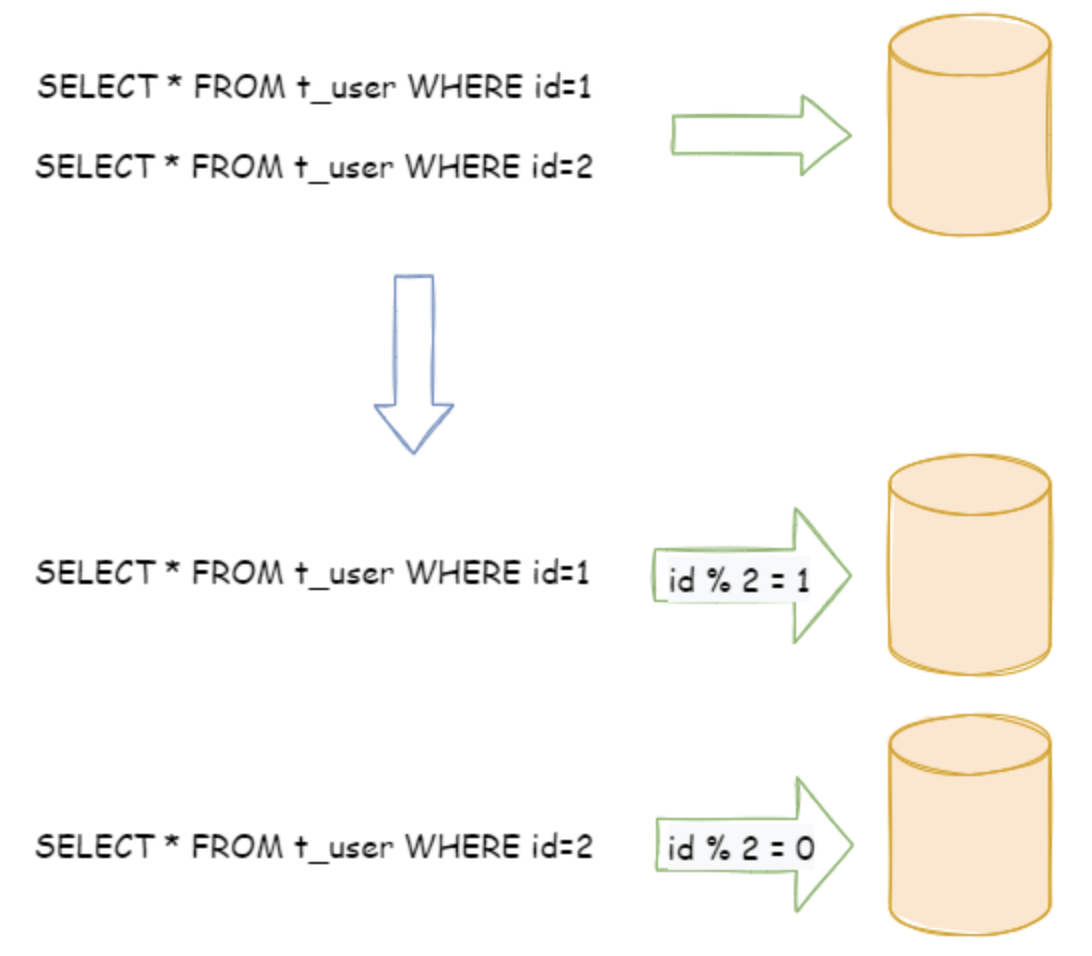
2)水平分片
比如:用户库 user_db,分片库后就是 user_db_0、user_db_1、user_db_xx。
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
优点:
- 提高了单库的读写性能,降低了单库数据量。
- 可以将库存储在不同的物理服务器上,提高了查询效率。
缺点:
- 需要处理跨库查询的问题。
- 对分库规则的设计需要谨慎,避免热点数据集中在某个库中。
1.2 什么是分表?
1)垂直分片
比如:订单�表 order_table,拆分后就是 order_table 以及 order_ext_table。
同分库的概念,只不过将数据库维度降低为数据库表维度。
优点:
- 拆分后每个表的数据量变小,查询时涉及的磁盘 I/O 次数相对减少,提高了查询效率。
- 每个小表的并发写入操作相对较少,减少了数据库锁的竞争,提高了并发能力。
缺点:
- 需要在应用层面处理跨表查询的逻辑,增加了开发的复杂性。
- 如果一个事务涉及多个小表,可能需要在应用层面进行事务管理,增加了代码的复杂性。
- 需要额外的措施来保证拆分后的小表之间的数据一致性。
2)水平分片
比如:订单表 order_table,拆分后就是 order_table_0、 order_table_1、order_table_xxx。
同分库的概念,只不过将数据库维度降低为数据库表维度。
优点:
-
可以根据数据量的增长动态地增加分表,从而扩展数据库的存储能力。
-
每个小表的数据量减少,可以提高查询速度,尤其是在频繁查询的场景下。
-
拆分后,每个小表的并发写入操作相对减少,降低了数据库锁的竞争,提高了并发性能。
缺点:
- 对业务存在一定限制,如果没有按照分片键查询,会造成读扩散问题。
- 对分表规则的设计需要谨慎,避免热点数据集中在某个表中。
2. 分库分表场景
2.1 什么场景分表?
数据量过大或者数据库表对应的磁盘文件过大。
Q:多少数据量进行分表?
A:单表 1000w 是否要分表?回答不够标准。假设一个表里 15 个字段,没有特别大的值(不包含 text 或其它超长度的列)数据量超过 5000 万了,依然很丝滑,因为走索引。
真正需要考虑的是:业务的增长量以及历史数量。
Q:物理文件过大,会有什么问题?
A:会影响公司对数据库表的一个备份。数据库表文件过大,也间接证明表数据过大,增加或删除字段导致锁表的时间过长。
2.2 什么场景分库?
当数据库的连接不够客户端使用时,可以考虑分库或读写分离。
如果说当数据库的 QPS 越来越高以及数据量越来越大的时候,就需要考虑分库分表。
Q:为什么说连接不够用?
A:假设 MySQL Server 能支持 4000 个数据库连接。我们有 10 个服务,40 个节点,一个节点呢数据库连接池最多 10 个。这样就把一个 MySQL Server 的连接数压榨干净了。
当 MySQL 连接不够用时,可能会报错 "Too many connections" 或者类似的错误。这是因为 MySQL 服务器同时可以处理的连接数量是有限制的,当连接数达到这个限制时,服务器就会拒绝新的连接请求,并返回这个错误消息。
2.3 什么场景分库分表?
- ��高并发写入场景:当应用面临高并发的写入请求时,单一数据库可能无法满足写入压力,此时可以将数据按照一定规则拆分到多个数据库中,每个数据库处理部分数据的写入请求,从而提高写入性能。
- 数据量巨大场景:随着数据量的不断增加,单一数据库的存储和查询性能可能逐渐下降。此时,可以将数据按照一定的规则拆分到多个表中,每个表存储部分数据,从而分散数据的存储压力,提高查询性能。
什么是 ShardingSphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
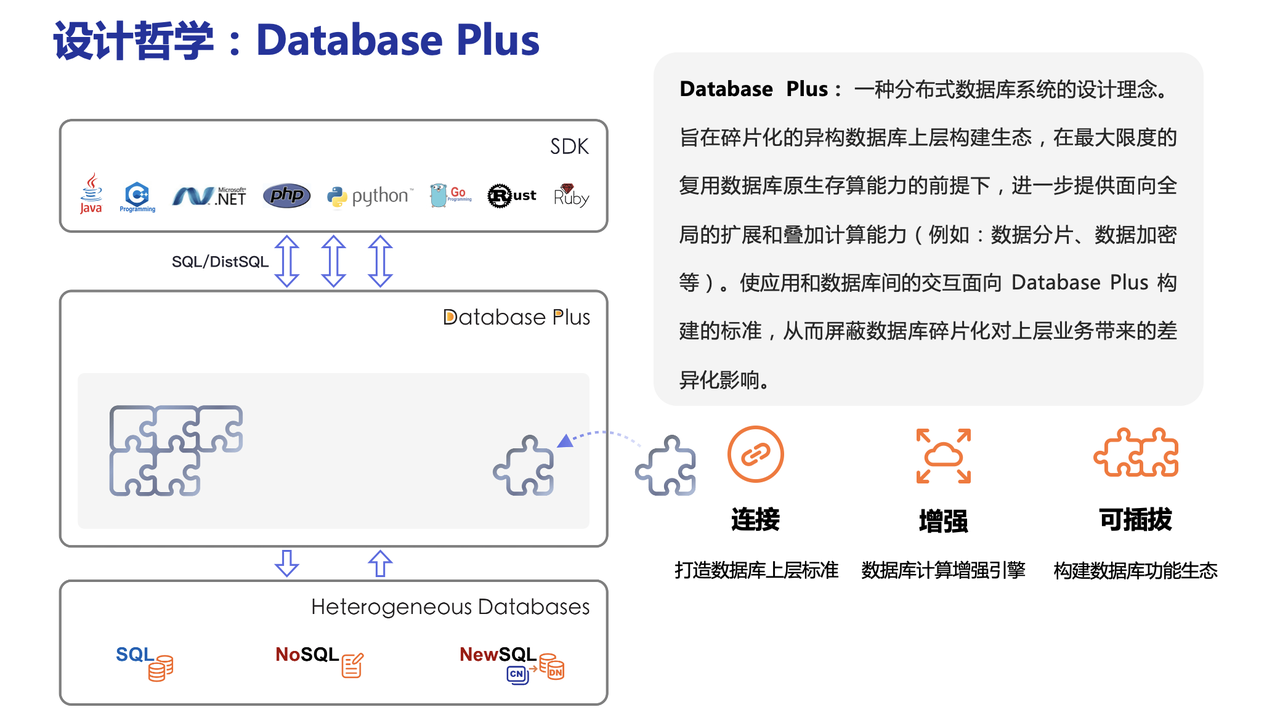
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingSphere 有两个产品在企业中广泛使用,分别是 ShardingSphere-JDBC 以及 ShardingSphere-Proxy。
1. ShardingSphere-JDBC
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 Jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用��于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
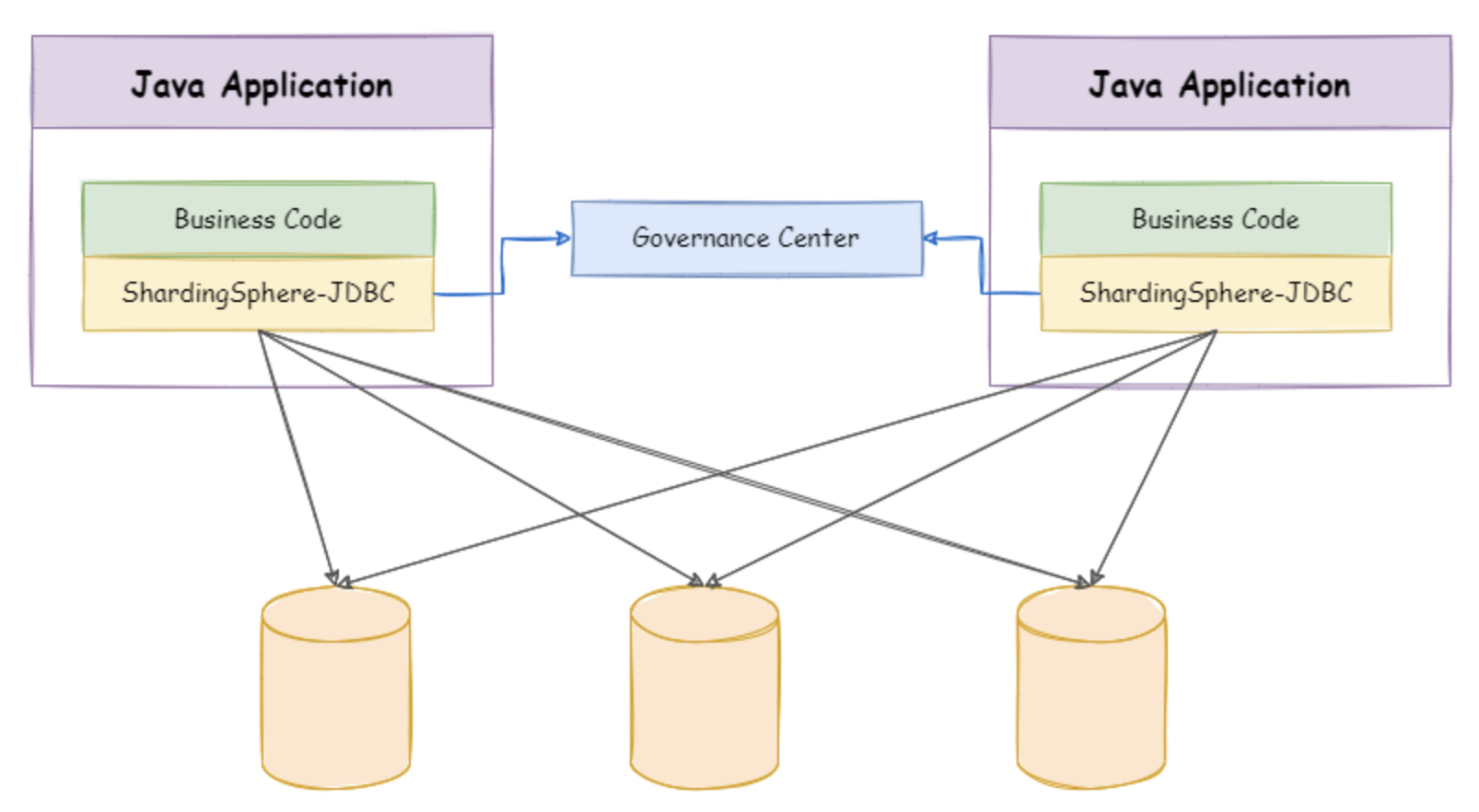
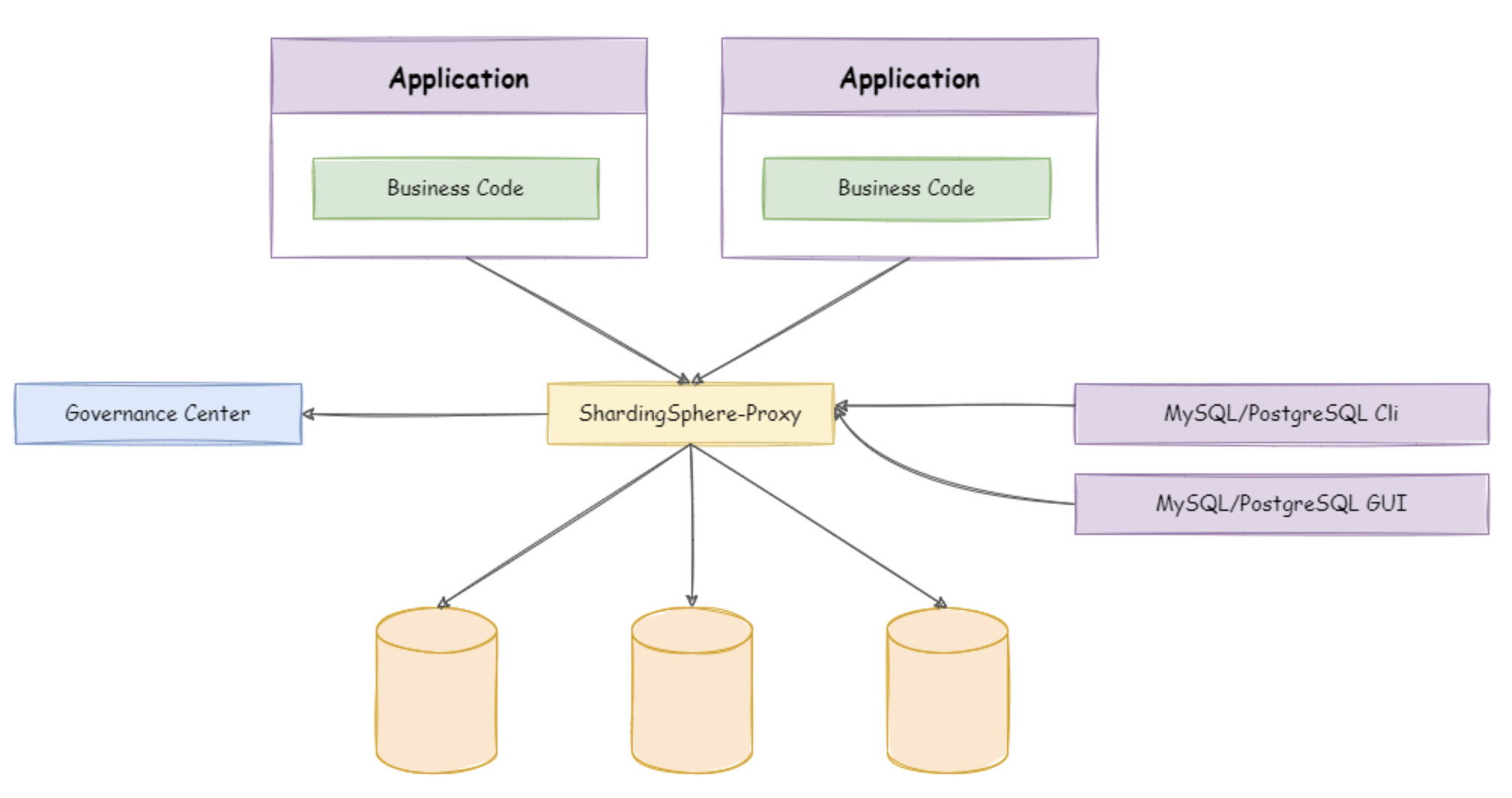
2. ShardingSphere-Proxy
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
3. 混合部署
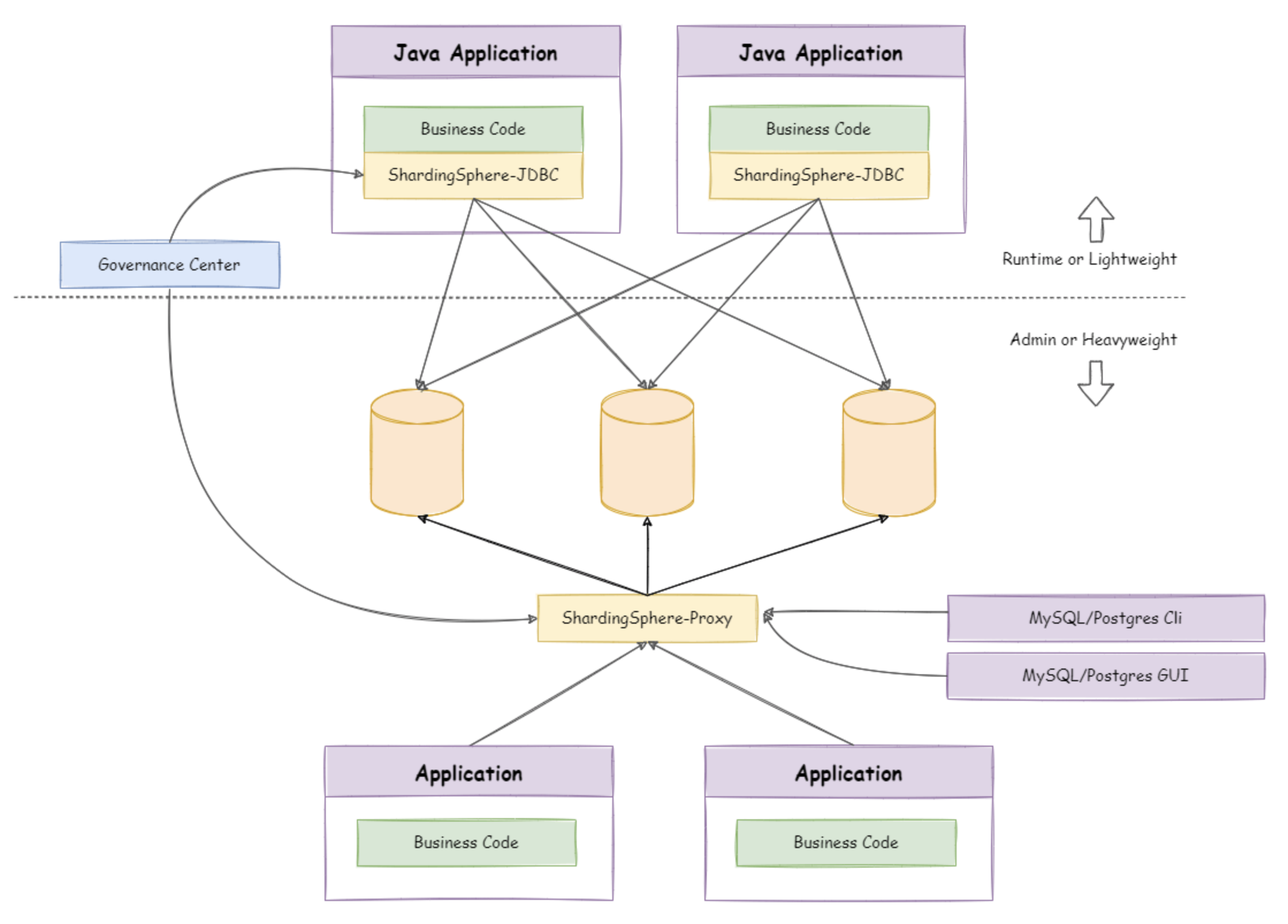
ShardingSphere-JDBC 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用; ShardingSphere-Proxy 提供静态入口以及异构语言的支持,独立于应用程序部署,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。
4. 产品功能
这里给大家列一些经常使用且入门门槛较低的功能,更多的功能大家可以去 ShardingSphere 官网发掘。
| 特性 | 定义 |
|---|---|
| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。 |
| 读写分离 | 读写分离,是应对高压力业务访问的手段。基于对 SQL 语义理解及对底层数据库拓扑感知能力,ShardingSphere 提供灵活的读写流量拆分和读流量负载均衡。 |
| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere 提供完整、透明、安全、低成本的数据加密解决方案。 |
| 影子库 | 在全链路压测场景下,ShardingSphere 支持不同工作负载下的数据隔离,避免测试数据污染生产环境。 |
| ...... | ...... |
4. 设计哲学
ShardingSphere 采用 Database Plus 设计哲学,该理念致力于构建数据库上层的标准和生态,在生态中补充数据库所缺失的能力。
数据分片核心概念
1. 表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
1.2 逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
1.3 真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。
1.4 绑定表
指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。 例如:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系,并且使用 order_id 进行关联后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
1.5 广播表
指所有的数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
1.6 单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
注意:符合以下条件的单表会被自动加载:
- 数据加密、数据脱敏等规则中显示配置的单表
- 用户通过 ShardingSphere 执行 DDL 语句创建的单表
其余不符合上述条件的单表,ShardingSphere 不会自动加载,用户可根据需要配置单表规则进行管理。
2. 数据节点
数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。 逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
2.1 均匀分布
指数据表在每个数据源内呈现均匀分布的态势, 例如:
db0
├─�─ t_order0
└── t_order1
db1
├── t_order0
└── t_order1
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
2.2 自定义分布
指数据表呈现有特定规则的分布, 例如:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
3. 分片
3.1 分片键
用于将数据库(表)水平拆分的数据库字段。 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
3.2 分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
3.3 自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
3.4 自定义分片算法
提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
-
标准分片算法:用于处理使用单一键作为分片键的
=、IN、BETWEEN AND、>、<、>=、<=进行分片的场景。 -
复合分片算法:用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
Hint 分片算法:用于处理使用
Hint行分片的场景。
3.5 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也�就是分片策略。
3.6 强制分片路由
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由。
4. 行表达式
行表达式是为了解决配置的简化与一体化这两个主要问题。在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。 通过行表达式可以有效地简化数据节点配置工作量。
对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
行表达式作为字符串由两部分组成,分别是字符串开头的对应 SPI 实现的 Type Name 部分和表达式部分。 以 <GROOVY>t_order_${1..3} 为例,字符 串<GROOVY> 部分的子字符串 GROOVY 为此行表达式使用的对应 SPI 实现的 Type Name,其被 <> 符号包裹来识别。而字符串 t_order_${1..3} 为此行表达式的表达式部分。当行表达式不指定 Type Name 时,例如 t_order_${1..3},行表示式默认将使用 InlineExpressionParser SPI 的 GROOVY 实现来解析表达式。
以下部分介绍 GROOVY 实现的语法规则。
��行表达式的使用非常直观,只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
${begin..end} 表示范围区间 ${[unit1, unit2, unit_x]} 表示枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
例如,以下行表达式:
${['online', 'offline']}_table${1..3}
最终会解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
5. 分布式主键
传统数据库�软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
动手实现数据分表
下文代码示例地址:SpringBoot-Ladder ShardingSphere 5.x 分库分表示例程序。
1. 准备数据库&表
MySQL 创建数据库 user_0,创建后,执行以下数据库表创建语句。
CREATE TABLE `t_user_0` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`username` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名',
`password` varchar(512) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '密码',
`real_name` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '真实姓名',
`region` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT '0' COMMENT '国家/地区',
`id_type` int(3) DEFAULT NULL COMMENT '证件类型',
`id_card` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '证件号',
`phone` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '手机号',
`telephone` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '固定电话',
`mail` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '邮箱',
`user_type` int(3) DEFAULT NULL COMMENT '旅客类型',
`verify_status` int(3) DEFAULT NULL COMMENT '审核状态',
`post_code` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '邮编',
`address` varchar(1024) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '地址',
`deletion_time` bigint(20) DEFAULT '0' COMMENT '注销时间戳',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1695720264773 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';
CREATE TABLE `t_user_1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`username` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名',
`password` varchar(512) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '密码',
`real_name` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '真实姓名',
`region` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT '0' COMMENT '国家/地区',
`id_type` int(3) DEFAULT NULL COMMENT '证件类型',
`id_card` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '证件号',
`phone` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '手机号',
`telephone` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '固定电话',
`mail` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '邮箱',
`user_type` int(3) DEFAULT NULL COMMENT '旅客类型',
`verify_status` int(3) DEFAULT NULL COMMENT '审核状态',
`post_code` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '邮编',
`address` varchar(1024) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '地址',
`deletion_time` bigint(20) DEFAULT '0' COMMENT '注销时间戳',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1695720264420 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';
2. 开发用户持久层代码
引入 MyBatisPlus 以及和 MySQL 相关依赖,开发普通的用户持久层代码逻辑。
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
创建用户持久层实体。
import com.baomidou.mybatisplus.annotation.FieldFill;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
/**
* 用户信息实体
*
* @公众号:马丁玩编程,回复:加群,添加马哥微信(备注:ladder)获取更多项目资料
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
@TableName("t_user")
public class UserDO {
/**
* id
*/
private Long id;
/**
* 用户名
*/
private String username;
/**
* 密码
*/
private String password;
/**
* 真实姓名
*/
private String realName;
/**
* 国家/地区
*/
private String region;
/**
* 证件类型
*/
private Integer idType;
/**
* 证件号
*/
private String idCard;
/**
* 手机号
*/
private String phone;
/**
* 固定电话
*/
private String telephone;
/**
* 邮箱
*/
private String mail;
/**
* 旅客类型
*/
private Integer userType;
/**
* 审核状态
*/
private Integer verifyStatus;
/**
* 邮编
*/
private String postCode;
/**
* 地址
*/
private String address;
/**
* 注销时间戳
*/
private Long deletionTime;
/**
* 创建时间
*/
@TableField(fill = FieldFill.INSERT)
private Date createTime;
/**
* 修改时间
*/
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
/**
* 删除标志
*/
@TableField(fill = FieldFill.INSERT)
private Integer delFlag;
}
创建用户实体对应的 MyBatis Mapper 持久层接口。
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.nageoffer.springbootladder.shardingspherecore.dao.entity.UserDO;
/**
* 用户信息持久层
*
* @公众号:马丁玩编程,回复:加群,添加马哥微信(备注:ladder)获取更多项目资料
*/
public interface UserMapper extends BaseMapper<UserDO> {
}
创建用户接口,为了避免重复代码,这里直接继承 MyBatisPlus 的 IService 通用接口,实现增删改查。
import com.baomidou.mybatisplus.extension.service.IService;
import com.nageoffer.springbootladder.shardingspherecore.dao.entity.UserDO;
/**
* 用户信息接口层
*
* @公众号:马丁玩编程,回复:加群,添加马哥微信(备注:ladder)获取更多项目资料
*/
public interface UserService extends IService<UserDO> {
}
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.nageoffer.springbootladder.shardingspherecore.dao.entity.UserDO;
import com.nageoffer.springbootladder.shardingspherecore.dao.mapper.UserMapper;
import org.springframework.stereotype.Component;
/**
* 用户信息接口实现层
*
* @公众号:马丁玩编程,回复:加群,添加马哥微信(备注:ladder)获取更多项目资料
*/
@Component
public class UserServiceImpl extends ServiceImpl<UserMapper, UserDO> implements UserService {
}
3. 引入 ShardingSphere-JDBC
引入 ShardingSphere-JDBC 的 Maven Jar 包,这里使用 5.3.2。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>
SpringBoot 和 ShardingSphere 配置文件的关联方式详情见下图。
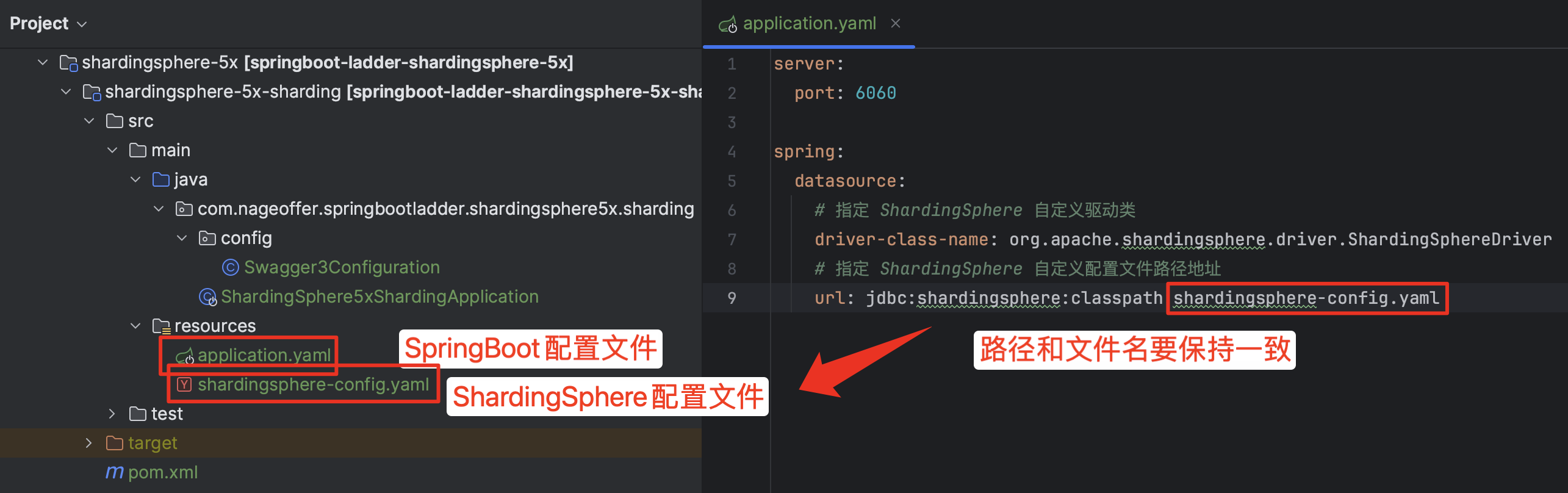
5.x.x 版本后,ShardingSphere-JDBC 的配置文件配置方式有了大的变化,从之前和 Spring 耦合变更为完全解耦,大家需要明确。
server:
port: 6060
spring:
datasource:
# 指定 ShardingSphere 自定义驱动类
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
# 指定 ShardingSphere 自定义配置文件路径地址
url: jdbc:shardingsphere:classpath:shardingsphere-config.yaml
创建 ShardingSphere 自定义分片配置文件 shardingsphere-config.yaml。
# 数据源集合
dataSources:
# 逻辑数据源名称
ds_0:
# 数据源类型
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
# 数据库驱动
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
# 用户名,如果本地数据库与这个不一致,需要修改
username: root
# 密码,如果本地数据库与这个不一致,需要修改
password: root
# ShardingSphere 规则配置,包含:数据分片、数据加密、读写分离等
rules:
- !SHARDING
# 需要数据分片的表集合
tables:
# 逻辑表名
t_user:
# 真实存在数据库的物理表集合
actualDataNodes: ds_0.t_user_${0..1}
# 分表策略
tableStrategy:
# 单分片键分表
standard:
# 自定义分片字段
shardingColumn: id
# 自定义分片算法名称,对应 {rules[0].shardingAlgorithms.user_table_hash_mod}
shardingAlgorithmName: user_table_hash_mod
# 数据分片算法定义集合
shardingAlgorithms:
# 自定义分片算法名称
user_table_hash_mod:
# 分片方式,HASH_MODE,按照 HASH 的方式对分片键进行操作,获取真实的物理表索引
type: HASH_MOD
props:
# 物理表分片数量
sharding-count: 2
props:
# 是否打印逻辑SQL和真实SQL,开发��测试环境建议开放,生产环境建议关闭
sql-show: true
4. 测试分表效果
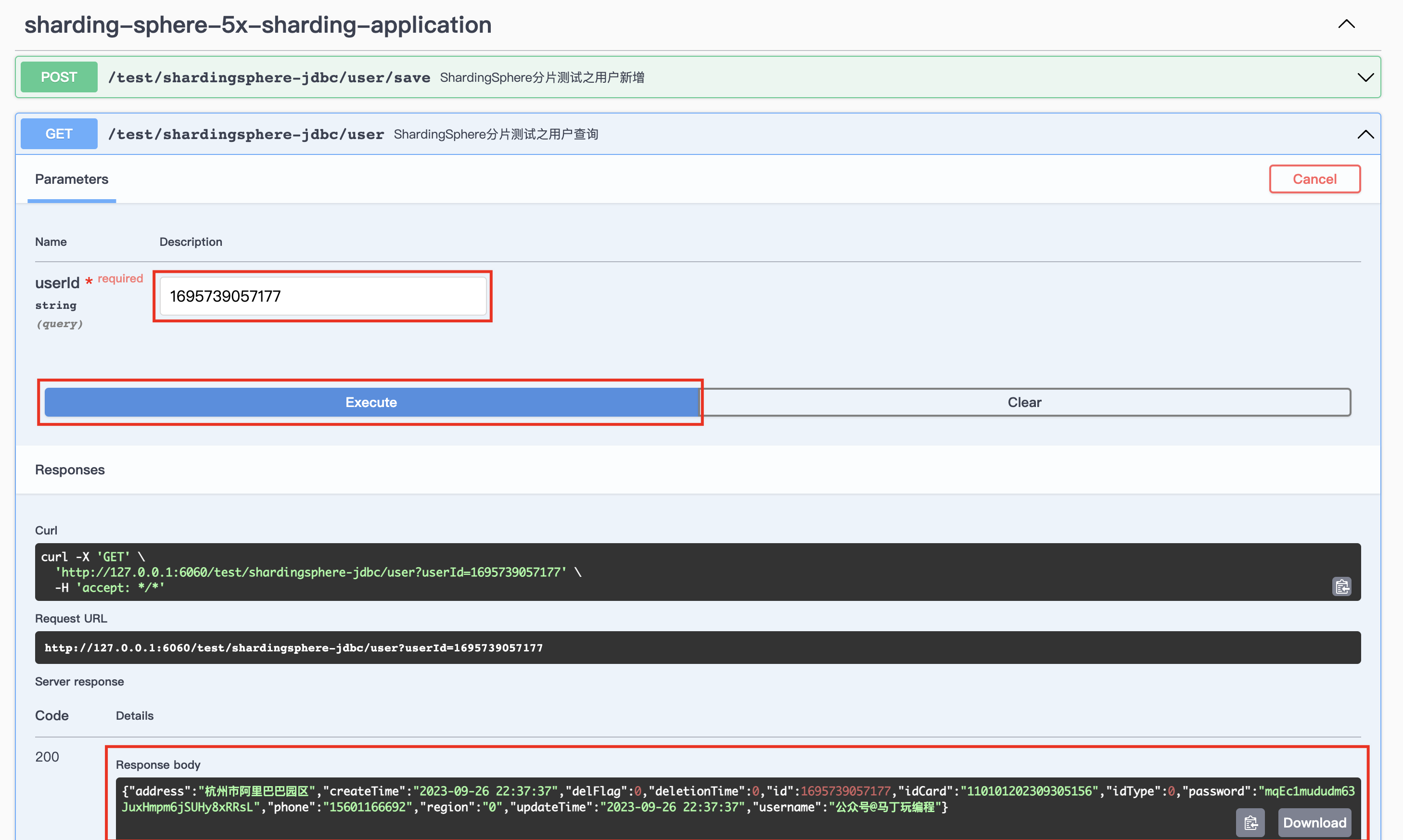
项目中引入了 Swagger3,通过界面 UI 发送一条消息测试效果。访问 http://127.0.0.1:6060/swagger-ui/index.html,调用定义的新增数据和查询数据方法。
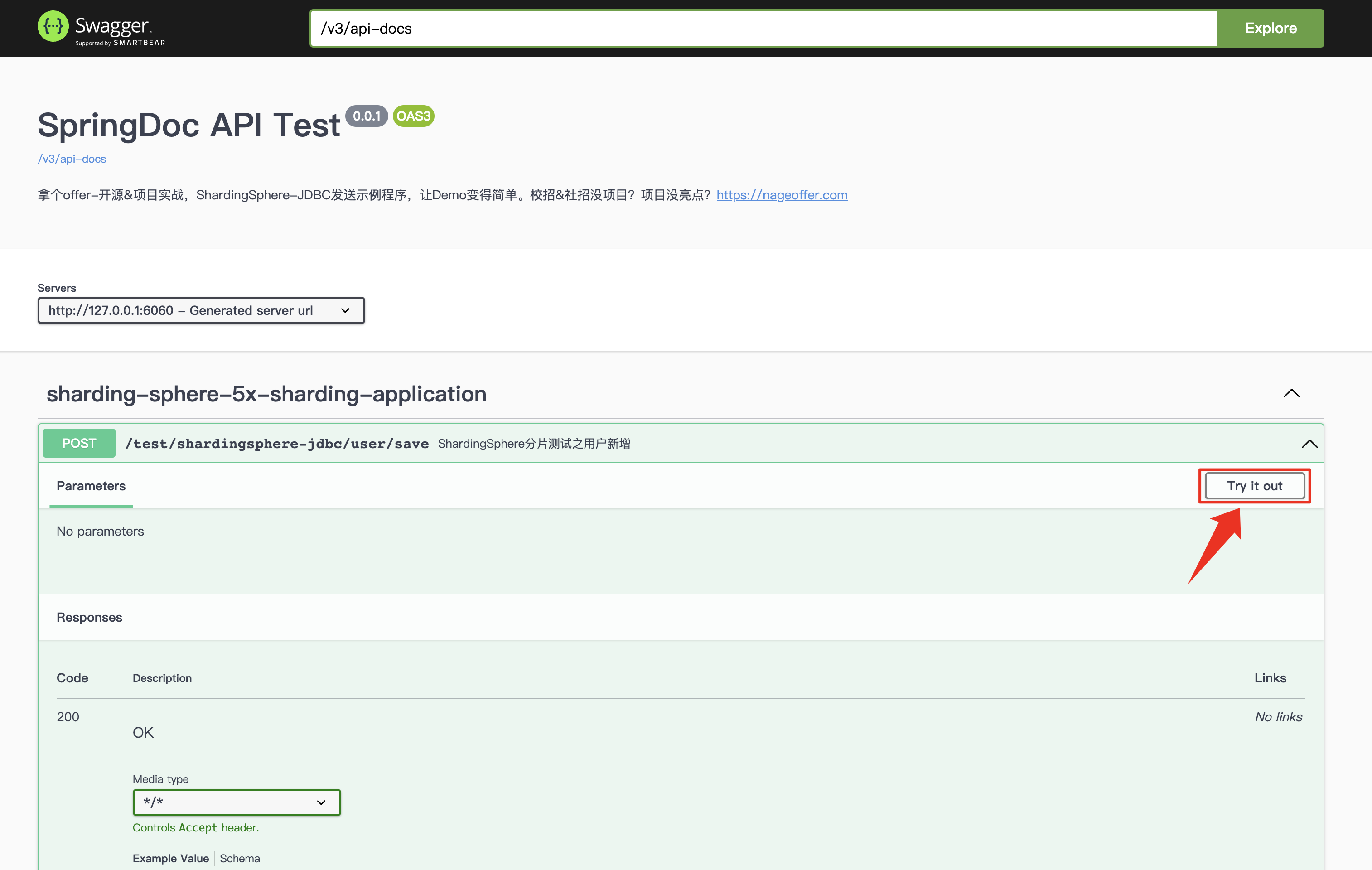
点击 Execute 执行方法调用。
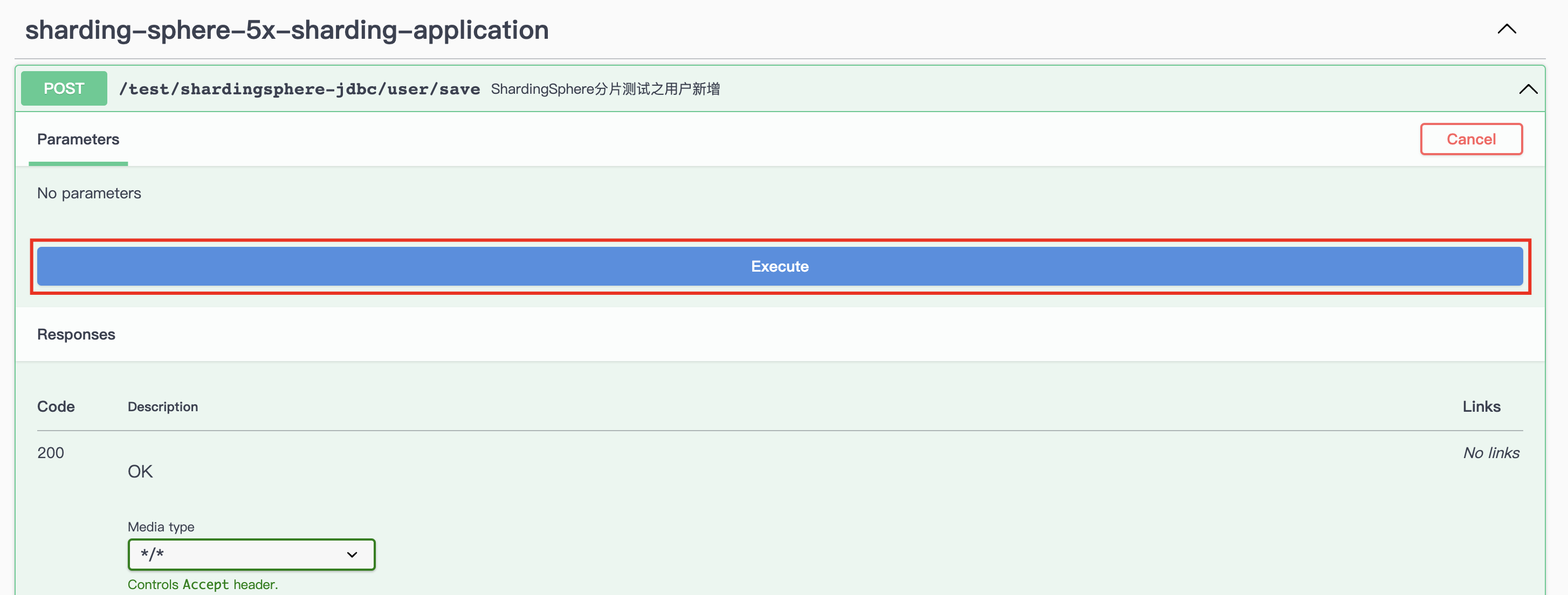
通过新增用户方法调用得知,返回数据为成功。并在返回信息中,添加了用户 ID,可以根据该 ID 去查询数据库记录。
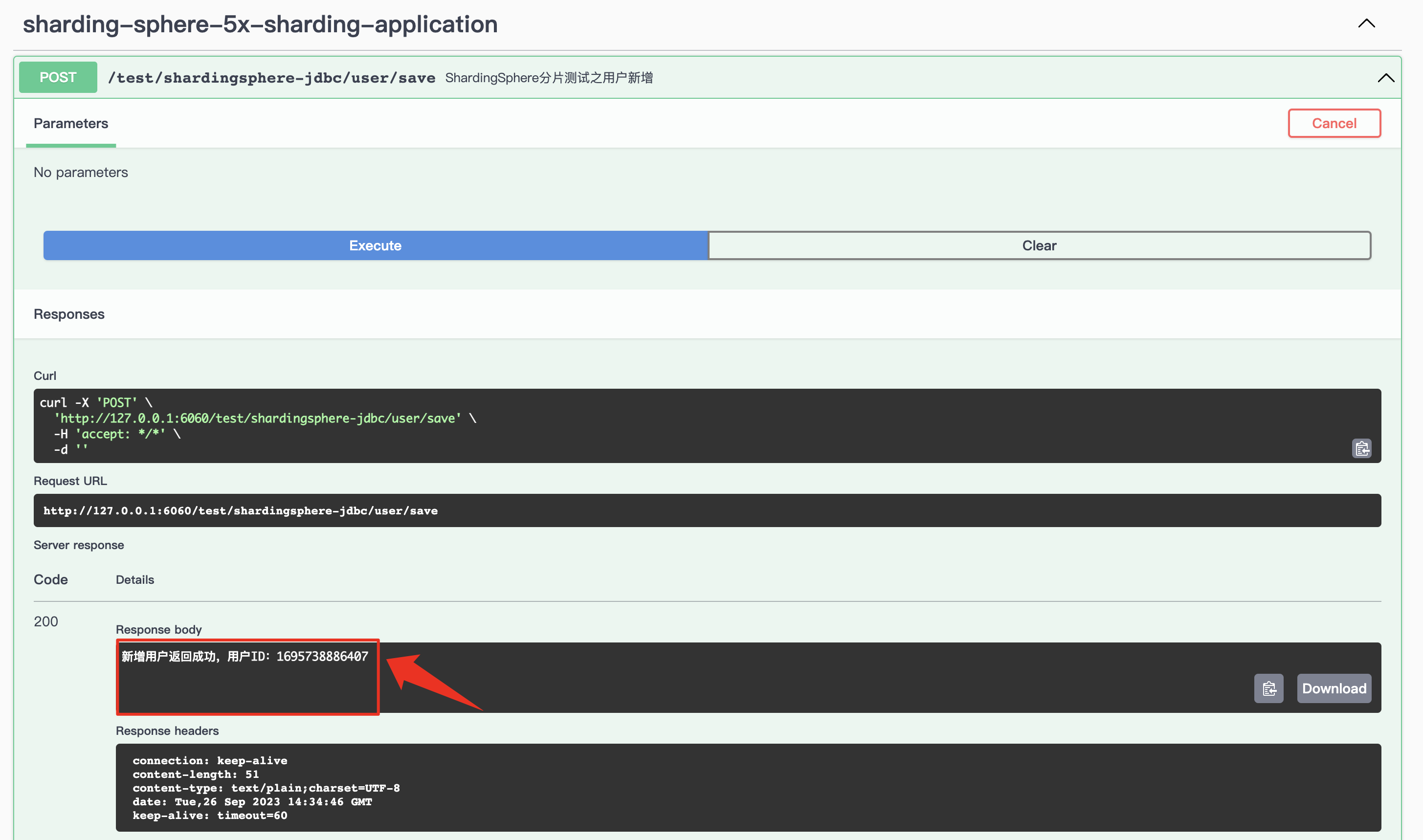
通过数据库日志得知,该数据被新增到 t_user_1 表中。
2023-09-26T22:34:46.413+08:00 INFO 78131 --- [nio-6060-exec-1] ShardingSphere-SQL : Actual SQL: ds_0 ::: INSERT INTO t_user_1 ( id,
username,
password,
id_type,
id_card,
phone,
address,
create_time,
update_time,
del_flag ) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) ::: [1695738886407, 公众号@马丁玩编程, mqEc1mududm63JuxHmpm6jSUHy8xRRsL, 0, 110101202309305156, 15601166692, 杭州市阿里巴巴园区, 2023-09-26 22:34:46.407, 2023-09-26 22:34:46.407, 0]
拿到刚才的方法返回 ID,根据 ID 查询这条数据的信息。