一张车票引发的连锁反应
如果你正在为校招面试做准备,面临着简历上“烂大街”的项目,面试机会较少,或者希望将 12306 项目充实到简历中等问题,欢迎了解「拿个offer-开源&项目实战」知识星球。我们提供以下主要服务:
- 面试服务:获取完整项目文档与教学视频,涵盖项目从零到一的启动方法,如何在简历中突显 12306 项目经验,项目亮点解析,以及分享包含 12306 面试真题的大厂面试经验。
- 项目学习:向我1v1发起问题提问,包括但不限于 12306 项目,会认真对待每个问答;提供简历编写指南服务,同时使用星球内部公有云中间件环境,避免本地环境开发的繁琐配置。
列车余票如何扣减
下文�实战章节中我们以 12306 G35 趟高铁复兴号为大家举例。
高铁复兴号 G35 趟列车共有5个站点,北京南、济南西、南京南、杭州东、宁波,接下来会以这些内容为基础展开。
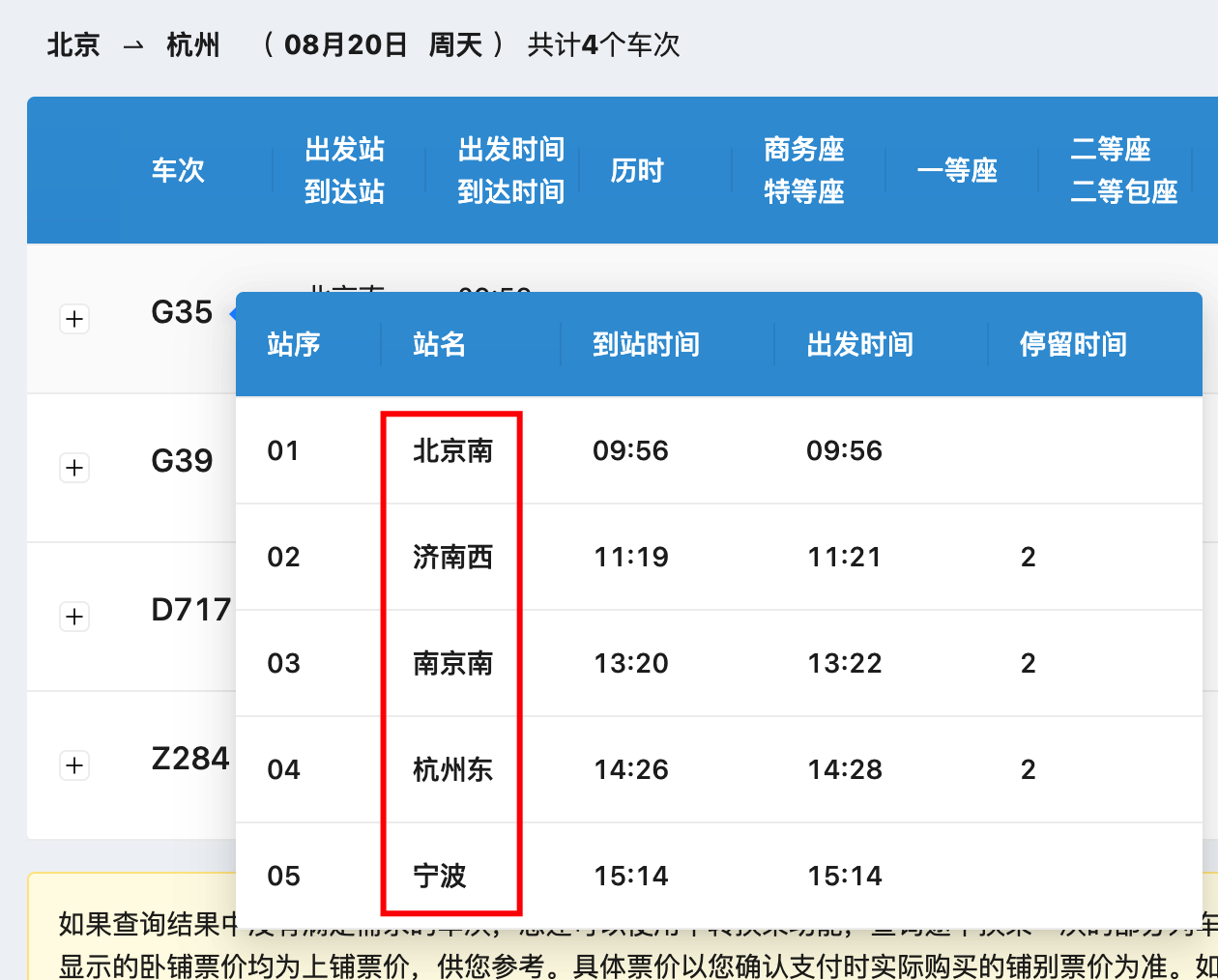
刚接触 12306 的大部分同学可能会误以为,如果购买了从北京南到南京南的车票,只会扣减北京南到南京南站点的车票。但实际情况并非如此。购买了北京南到南京南的列车票时,会扣减沿途站点的库存。
假设购买商务座,列车站点间的初始库存是一致的。下面是购买北京南到南京南车票的流程图示:
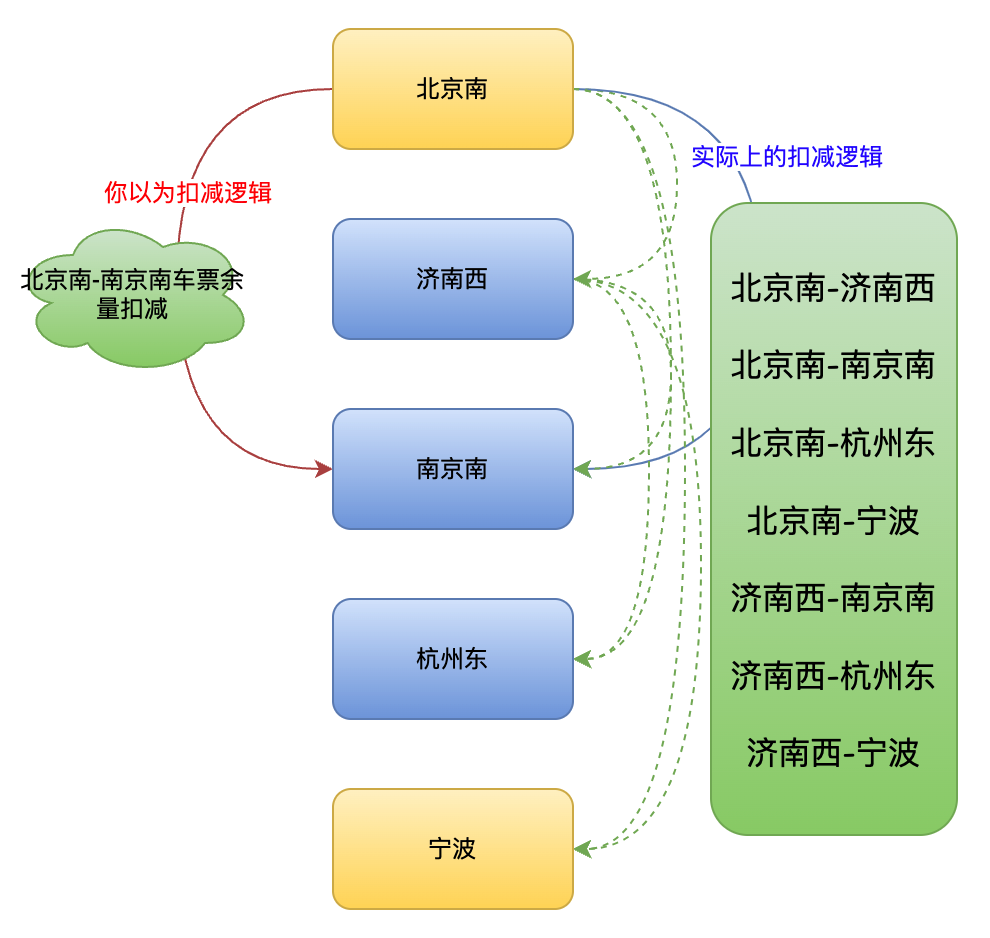
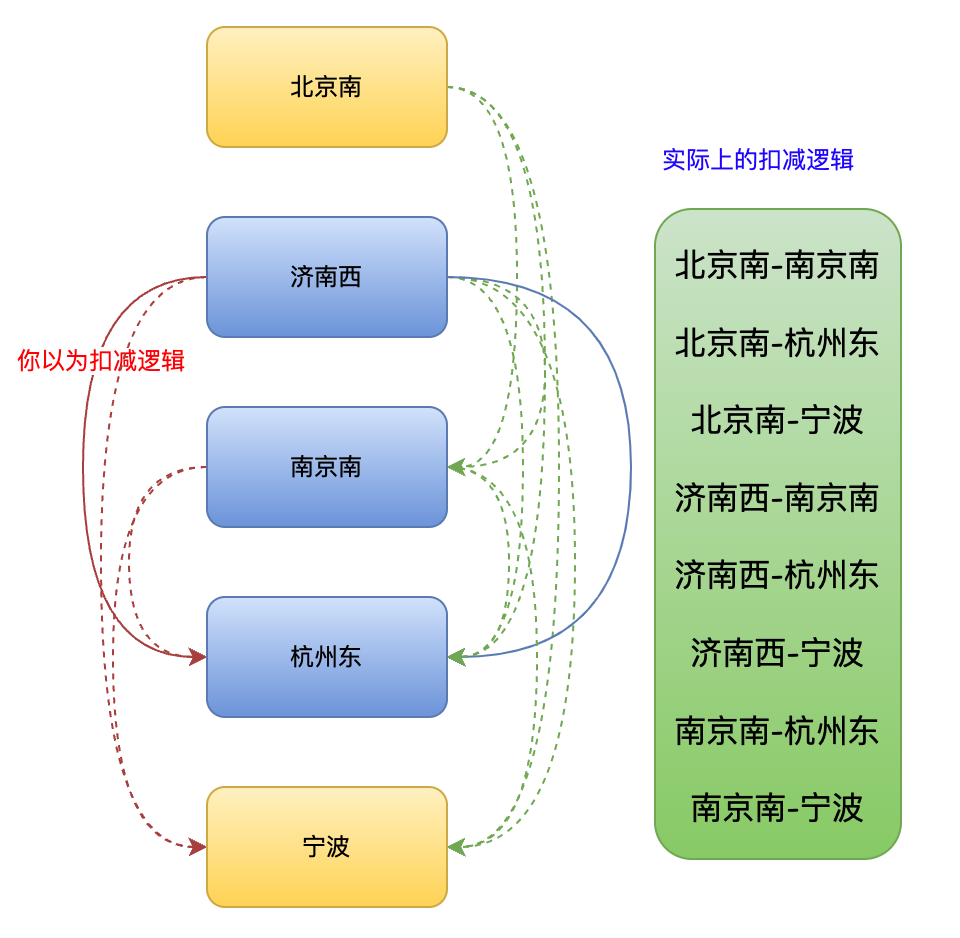
再来一个进阶版本的,如果购买济南西到杭州东的车票,流程图如下所示。大家可能会比较疑惑,为什么要扣减北京南到南京南、北京南到宁波、北京南到杭州东以及北京南到宁波?这是因为中间车票被购买了,北京南作为始发站,只能购买北京南到济南西的车票。
如何保证缓存一致性
为了满足用户对一趟列车不同站点不同座位类型的余量查询需求,我们采取了一种优化方案。我们将这些余量信息存储在缓存中,以便用户可以快速查询。
然而,在用户创建订单并完成支付时,我们需要同时从数据库和缓�存中扣减相应的列车站点余票。这种设计不仅提高了查询效率,也保证了数据的一致性,确保订单操作的准确性。
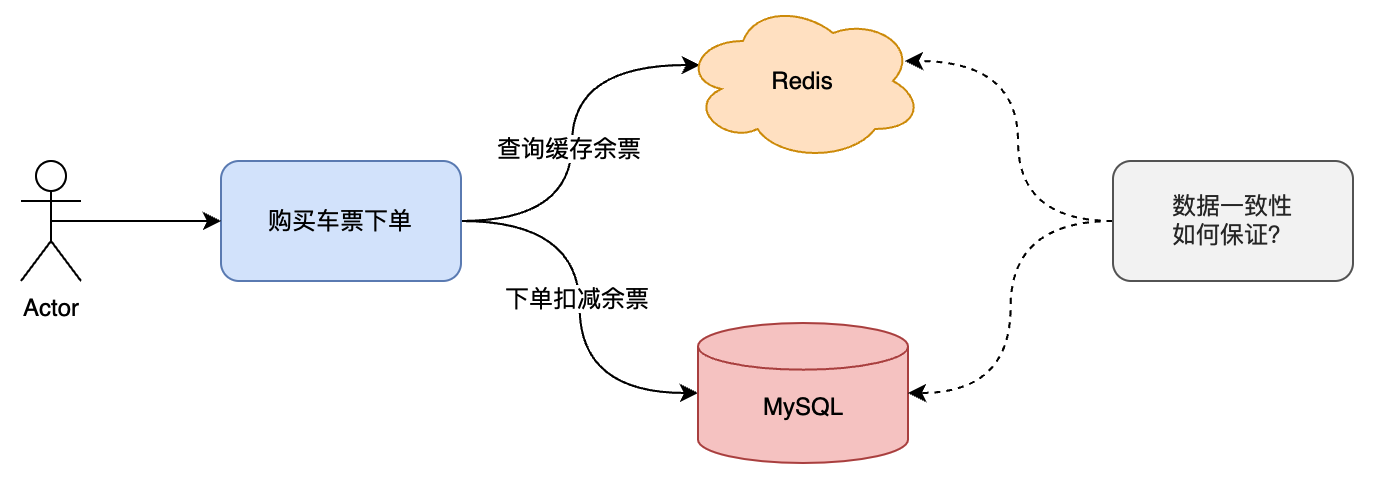
在这个业务场景中的缓存与数据库一致性如何保证?结合大家常在用的以及网上一些方案,给出一些我的思考以及咱们 12306 中实际的解决方案。
注意,下文中都是以多请求并发场景下的思考。
1. 先写缓存再写数据库
两个用户购买了车站余票,假设余票有 17 张,两个用户扣减完还剩 15 张票。
如图所示,多个请求并发写入缓存和数据库,写请求 A 先更新 Redis 余票为 16。此时,写请求 B 将余票缓存更新 Redis 为 15,紧接着执行数据库更新为 15。这个时候,写请求 A 继续执行更新数据库操作,余票数据更新为 16。
这样就导致了多请求并发场景下,执行结果和咱们预期的结果不相符。
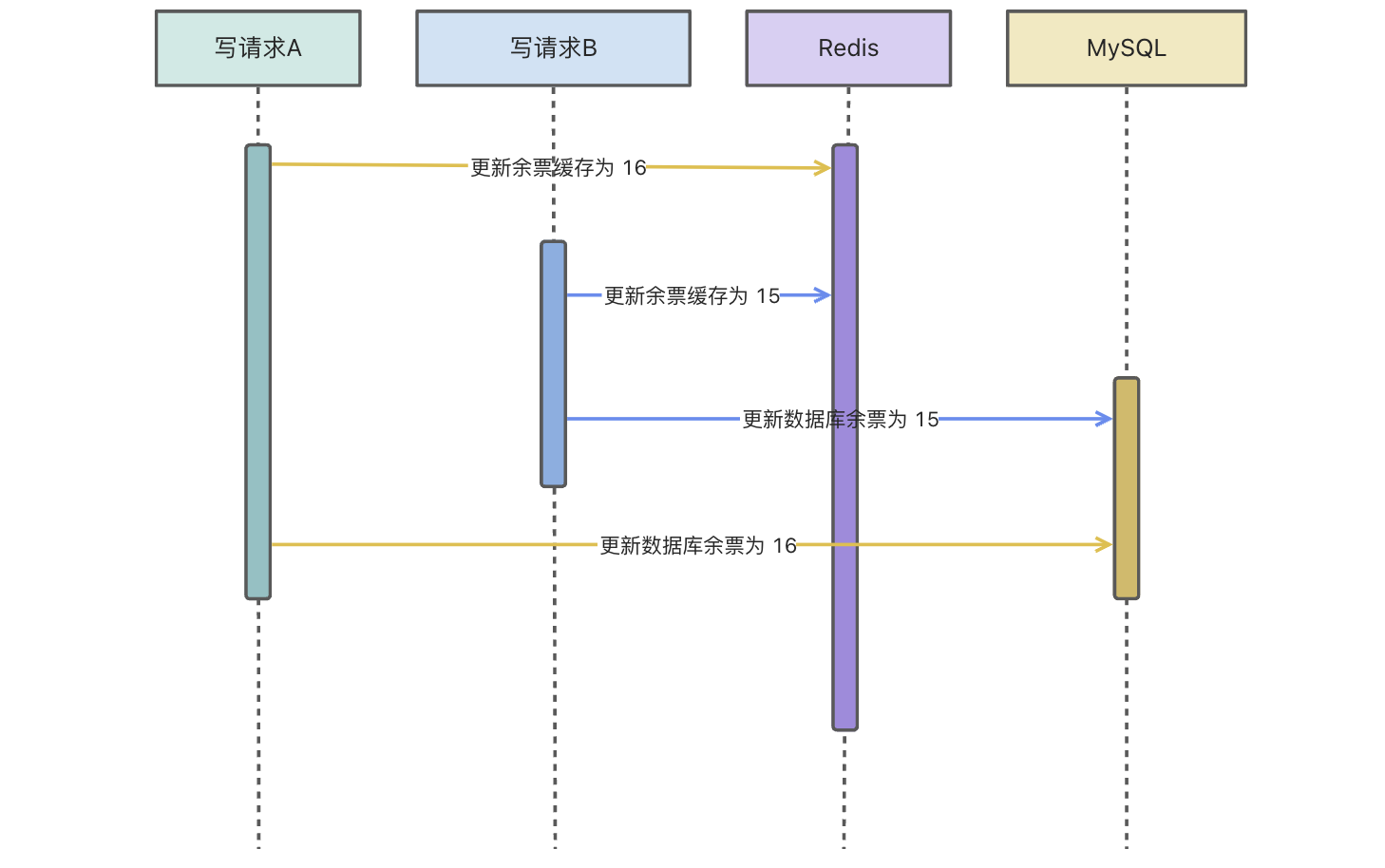
2. 先写数据库再写缓存
同上所诉,参考对应的业务场景和多请求并发场景,不同的是前者先更新缓存,后者先更新的是数据库,相同的是都存在并发问题,导致结果与预期并不相符。
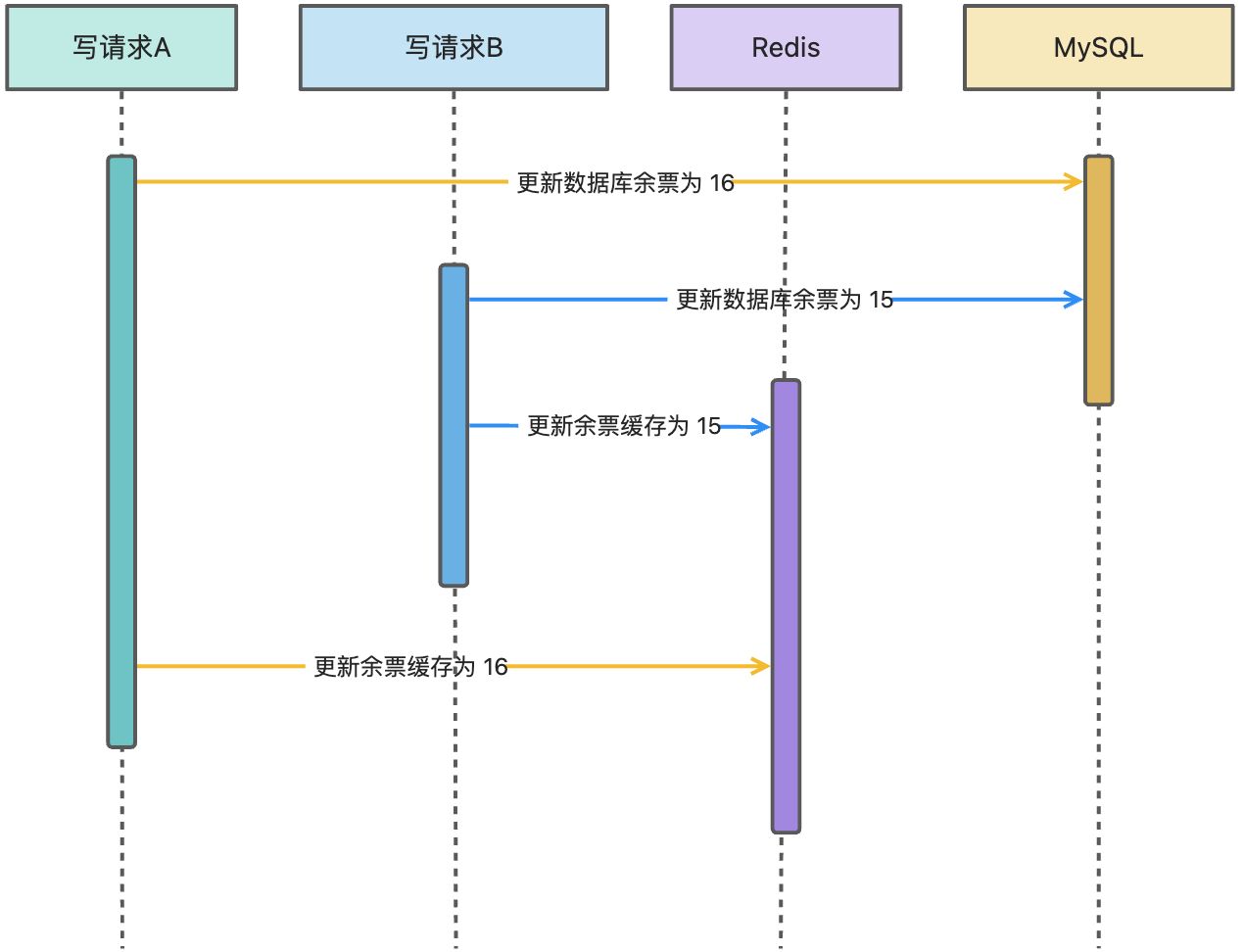
3. 先删除缓存再写数据库
假设有两个并发的读写操作,一个是写操作,另一个是读操作。
- 并发读写的情况下,写操作首先删除缓存,接下来需要执行更新数据库操作。
- 读操作发生,由于缓存已经被删除,读操作不得不从数据库中读取数据。然而,由于写操作尚未完成,数据库中的数据仍然是过时的。
- 写操作这时需要更新数据库中的值,更新后 MySQL 数据库是最新的值。
- 读操作将从数据库中查询到的过时数据再回写到缓存。
在这种情况下,读操作获取到的是过时的数据,尽管写操作已经完成。因为缓存被删除,读操作不得不从数据库中读取旧值,而不是最新的值。
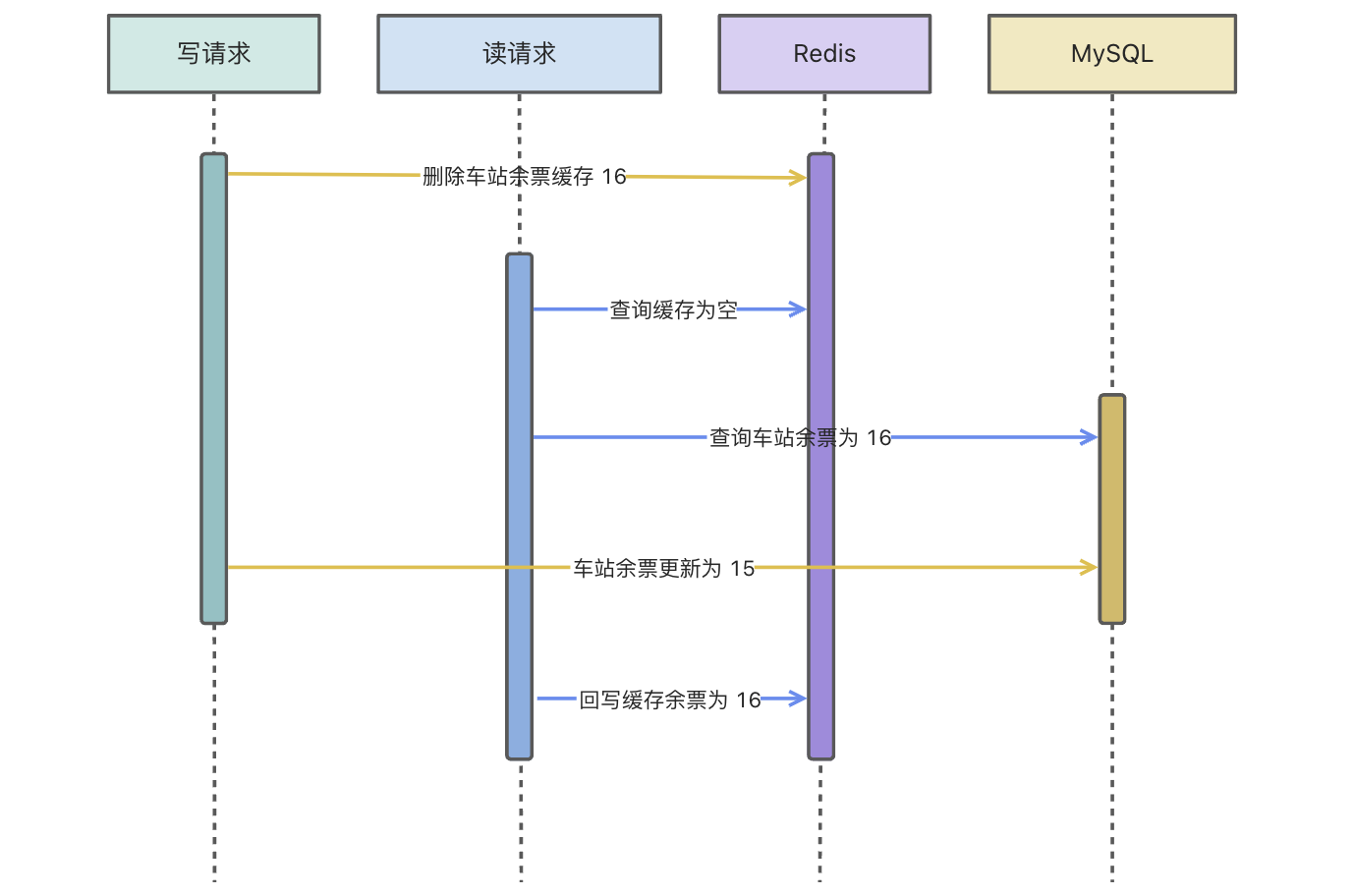
4. 先删除缓存再写数据库,再删除缓存
看着名字虽然有点长,但是如果换个词大家估计就懂了:缓存双删技术方案。
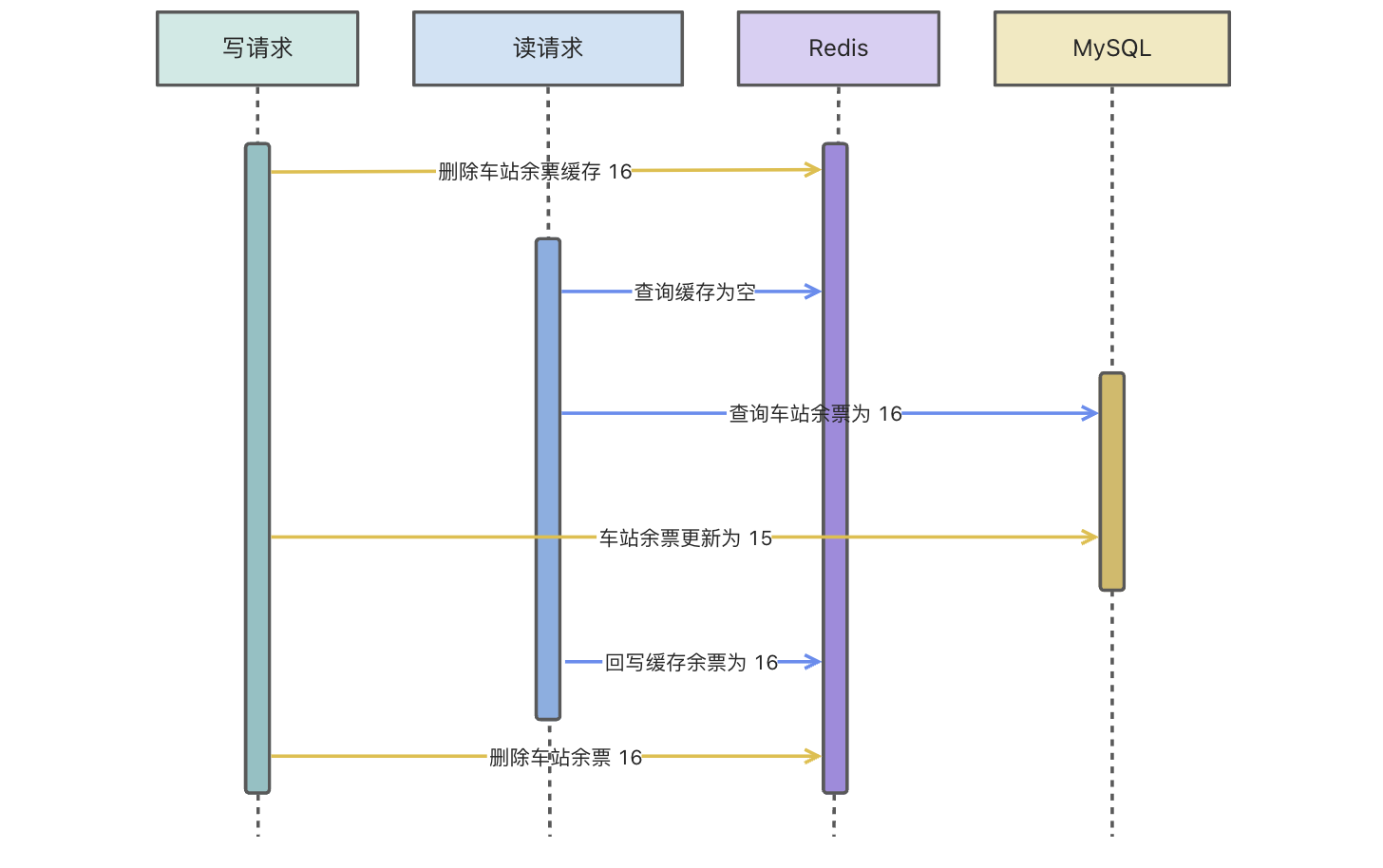
如果说上图的读请求回写缓存在写请求第二次删除缓存��之前,那这种技术方案是比较好的,而且也不用引入过多复杂的中间件。
问题就在于,第二次删除缓存,不一定在读请求回写缓存之后。所以我们需要保证第二次删除要在请求回写缓存之后。
假设读请求回写缓存大概需要 300ms,那我们是否可以在写请求第二次删除缓存前进行一个延迟操作,比如睡眠 500ms 后再删除?这样就可以规避读请求回写缓存在第二次删除之后了。
这种方案理论上是可以的,不过把这个睡眠操作使用延迟队列或者引入三方消息队列去做。
最新技术架构流程如下所示:
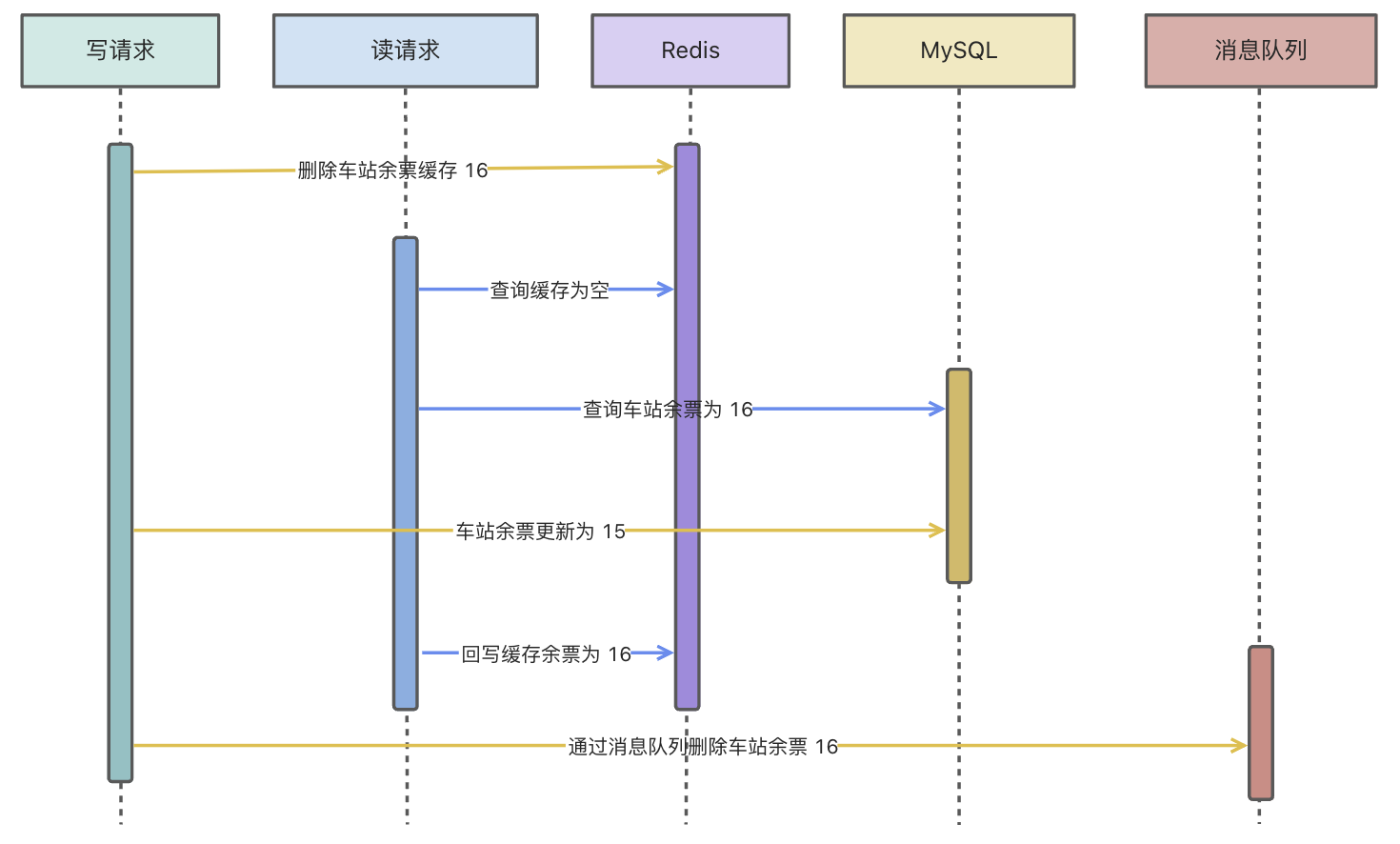
如果消息队列更新缓存失败了呢?其实这一点还好,凭借消息队列客户端消费的重试规则,如果更新失败次数都达到客户端重试阈值还是不行,那一定是数据或者缓存中间件有问题。
当然,如果重试次数多了,也必然会面临缓存与数据库不一致的时间变长了,这个是需要清楚的。
通过该技术方案,可以很好达到缓存与数据库最终一致性。
5. 先写数据库再删除缓存
读请求第一次查询时,会查询到一个错误的数据,因为写请求还没有更新到缓存,写请求写入 MySQL 成功后会删除缓存中的历史数据。后续读请求查询缓存没有值就会再请求数据库 MySQL 进行重新加载,并将正确的值放到缓存中。
也就是说这种模型会存在一个很小周期的缓存与数据库不一致的情况,不过对于绝大多数的情况来说,是可以容忍��的。除去一些电商库存、列车余票等对数据比较敏感的情况,比较适合绝大多数业务场景。
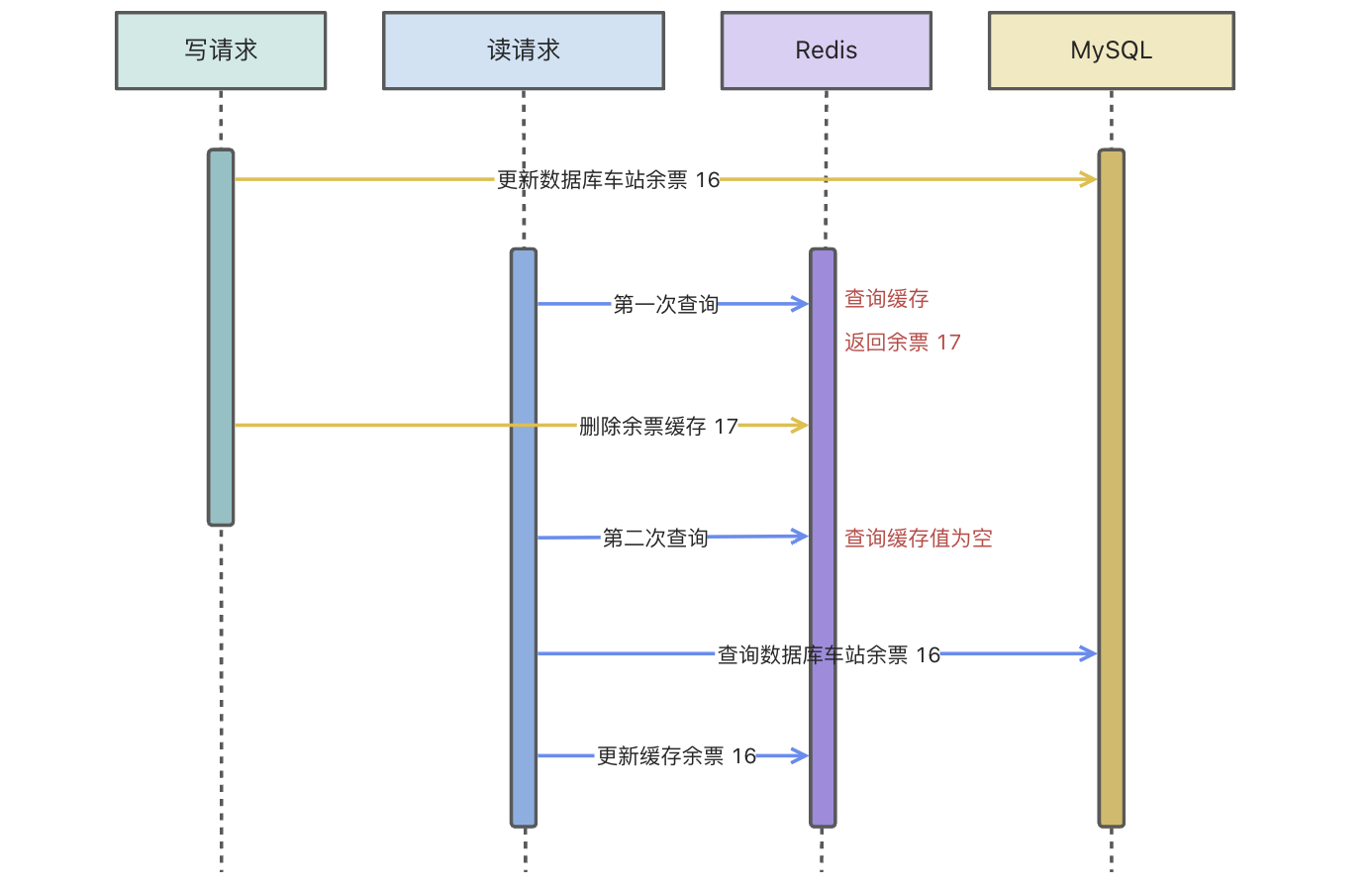
当然,这种模型也不是完全没问题,如果说恰巧读缓存失效了,就会出现这种情况。
 当缓存过期(可能是缓存正常过期也可能是 Redis 内存满了触发清理策略)条件满足,同时读请求的回写缓存 Redis 的执行周期在数据库删除之前,那么就有可能触发缓存数据库不一致问题。
当缓存过期(可能是缓存正常过期也可能是 Redis 内存满了触发清理策略)条件满足,同时读请求的回写缓存 Redis 的执行周期在数据库删除之前,那么就有可能触发缓存数据库不一致问题。
上面说的两种情况,缺一不可,不过能同时满足这两种情况概率极低,低到可以忽略这种情况。
6. 先写数据库,通过 BinLog 异步更新缓存
这种方案是我认为最终一致性最为值得尝试以及使用的。但是有一句话说的是没有绝对合适的技术,只有相对适合的技术,这种方案实现是也存在一些技术问题,稍后会给大家详细说明。
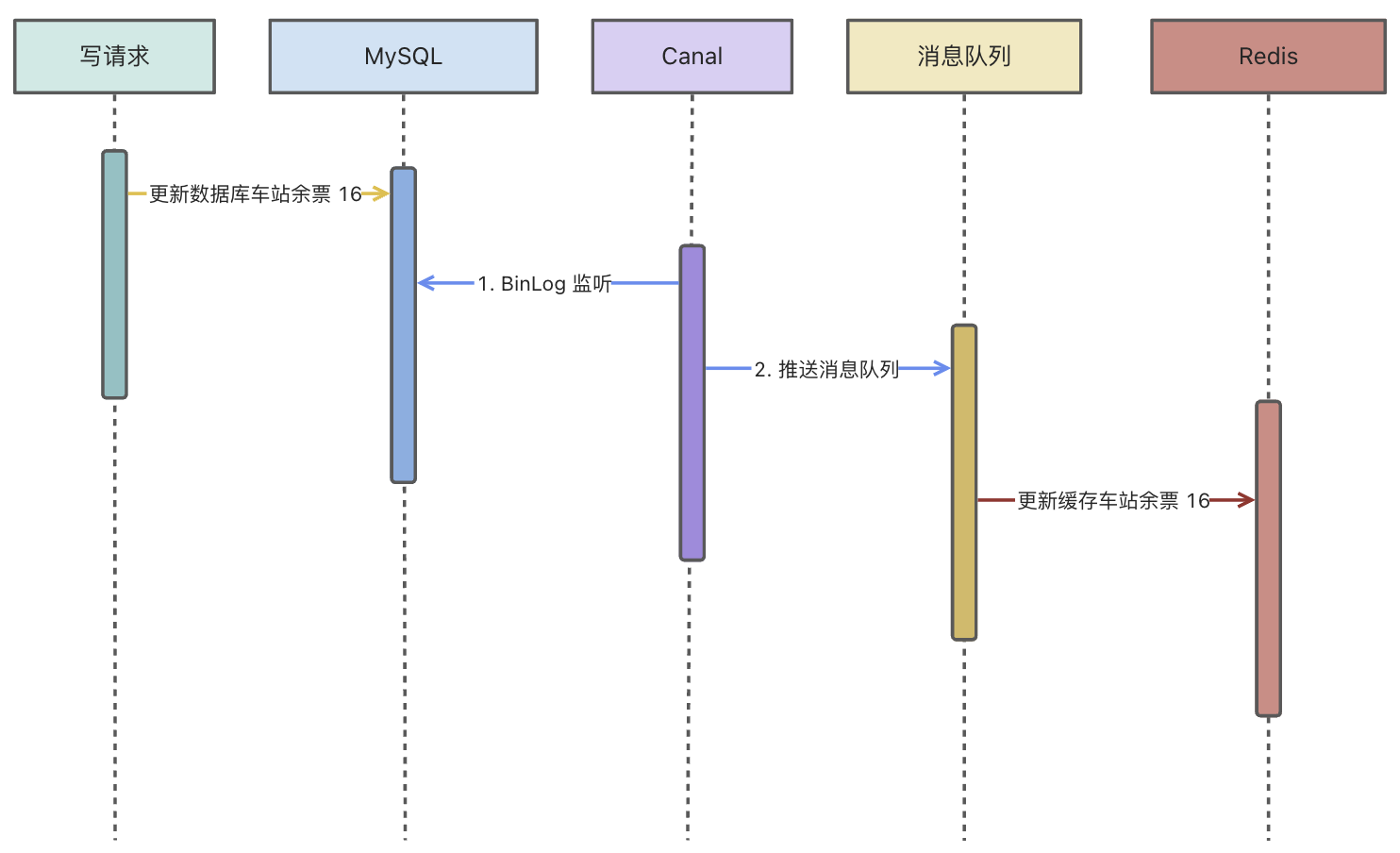
如果是扣减库存的方案,比如说你将列车余票扣减为 16,但是同时又有一个请求将列车余票扣减为 15,这个时候,扣减为 15 的这个请求先到消息队列执行,将缓存更新为余票 15,但是随之而来的是第一个请求余票为 16,会将缓存余票为 15 给覆盖掉。
类似于这种逻辑,会存在一些数据��一致性的问题,需要我们通过其它技术手段完善,比如数据库添加版本号,或者根据最后修改时间等技术规避这些问题。
另外,如果在写入数据库余票 16 前,同时有个查询请求,也会存在数据库不一致问题。比如在写入数据库余票 16 前,将数据库余票 17 获取到,然后等消息队列更新到缓存余票 16 后,再将数据库余票 17 更新到缓存。
这种出问题的概率比较小,因为跨的周期太长了。也是类似于存在一个很小周期的数据不一致性。
缓存一致性方案总结
1. 使用推荐
总结一下关于缓存与数据库一致性的方案:如果你想要最终一致性可以使用 Binlog 异步更新缓存方案,如果缓存实时性要求比较高,使用先写数据库再删缓存方案。
真实场景中根据具体业务需求和系统架构,可以选择适合的方案或组合多种方案。这些方案最终目的是在解决缓存与数据库之间的一致性问题,以确保数据的正确性和可靠性。
2. 缓存删除和 Binlog 异步处理有坑
挑一挑缓存删除以及 Binlog 异步处理的一些 “刺”,以及不同问题下的解决方案是什么。
�首先思考一个问题,缓存删除真的合适么?在涉及海量并发的场景中,如果程序删除了缓存,可能会导致缓存击穿问题,而更新频繁时则可能引发缓存雪崩。
因此,在考虑缓存一致性模型时,务必充分考虑业务场景是否属于高并发模型。如果是高并发场景,删除缓存可能并不合适,此时应采用最终一致性策略。
但是,Binlog 异步处理就没问题了么?也不尽然。需要看缓存中的数据是什么属于场景,比如你存储的是车票库存数量还是说某个车站信息。
需要额外注意的是,因为 Binlog 监听中用到了消息队列,就不得不考虑重复消费问题,需要添加幂等注解保证仅消费单次。
详情查看知识星球主题:https://articles.zsxq.com/id_4qznwlbkzx96.html
最终解决方案
我们采用了一种确保缓存和数据库一致性的方案,使用 Canal 监听 Binlog 模式。该方案将数据库的数据变更通过 Canal 转发给消息队列的特定 Topic。客户端应用程序可以监听该消息队列的 Topic,以保持缓存与数据库的一致性。
时序图如下所示:
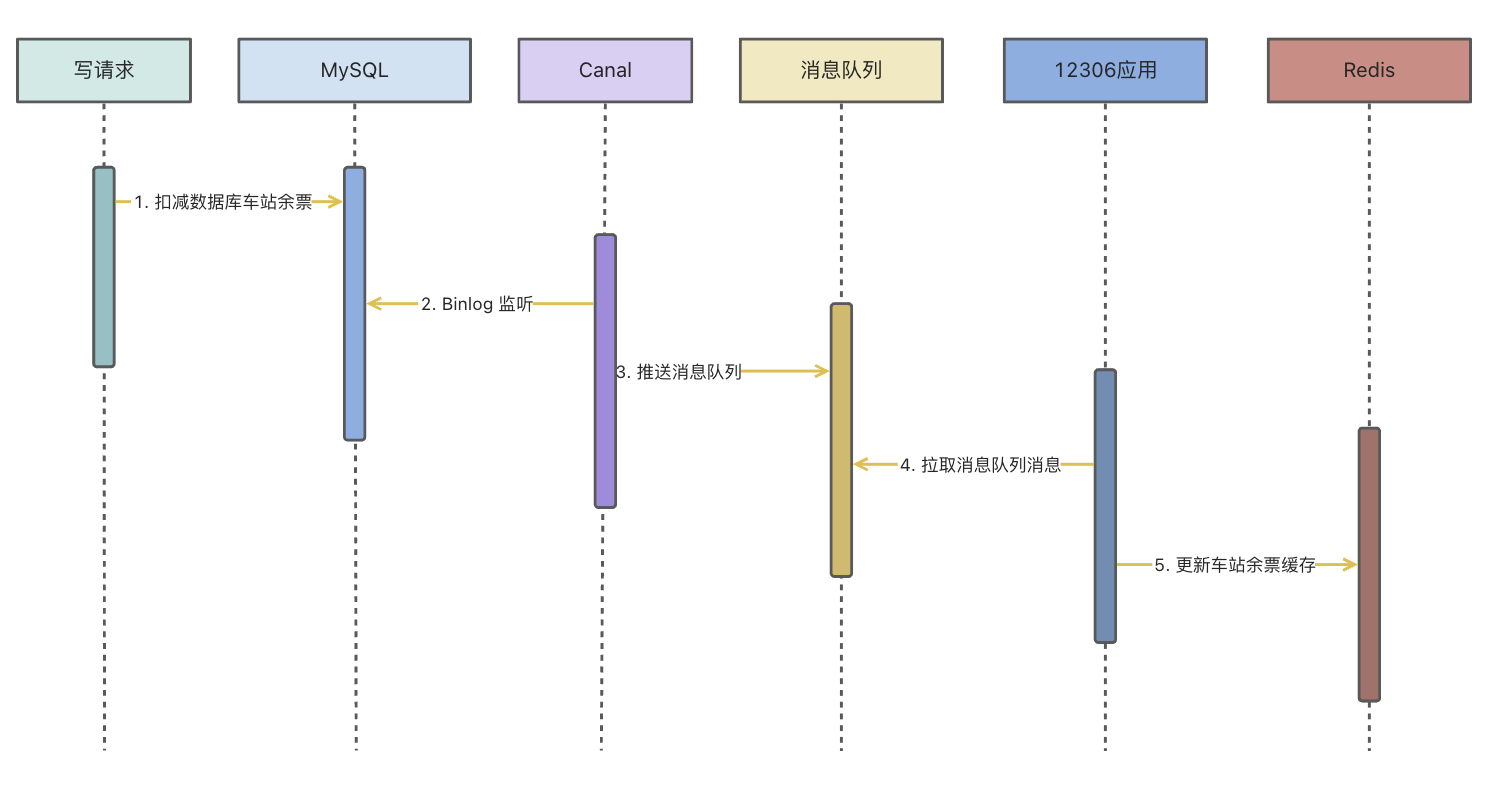
这套逻辑在应用层面上非常严谨,但存在一个问题,即复杂性较高。如果大家想进行测试,需要启动 Canal 监听并结合消息队列进行测试。
为了解决这个问题,我在代码中添加了两种缓存同步模型。其中一种是在业务代码中同步地操作缓存扣减,这种方案比较简单,可以帮助大家快速熟悉业务流程。但是,这种方案在中间或快结束时如果出现异常,可能会导致缓存数据出现问题。
问题答题Q&A
当大家根据代码已经掌握缓存与数据库一致性之后,可以尝试回答以下问题,判断自己是否真正掌握,以及是否能够在业务理解的基础上回答扩展问题。
- 为什么订阅 Canal 的消费者不用线程池?
- 为什么扣减数据库需要扣减沿途车站,而缓存扣减不需要?
- 为什么创建订单扣减库存而不是支付后扣减库存?