v1x性能与高可用增强
12306 铁路购票系统可以说是马哥最用心打磨的项目之一,我也真心希望它能走得更远。基于 1.0.0 版本的经验和沉淀,经过多次迭代提交,进一步打造了一个增强版 1.1.0。
相比之前的版本,除了在接口性能上有明显优化外,还特别新增了企业级实战专题,为使用者带来更全面、更深入的学习与实践体验。
相关文章如下所示(近4万字精品文档):
- 12306 适配 Redis 主从和 Cluster 集群架构
- 12306 购票接口 v2 版本压力测试
- 12306 高性能购票 v3 接口详解
- 12306 购票接口 v2 与 v3 压测性能对比
- 12306 分库分表后如何实现海量数据运维?
- 12306 基于 ShardingSphere 实现 MySQL 读写分离
- 12306 微服务如何提升故障排查的效率?
前言
铁路购票系统的价值焦点在“购票”这一刻:高峰期席位稀缺、流量陡增,任何微小的延迟都可能放大为链路瓶颈。我们先后演进了三版购票接口,本文聚焦 v2:在不牺牲业务完整性的前提下,如何系统性地提升吞吐与稳定性,并且用“更贴近真实”的压测方法验证优化是否有效。
总体架构与设计模式
-
分层视角 上层:购票流程的核心业务编排。 下层:数据流转与持久化(缓存、数据库、消息队列)。
-
可扩展性 采用 责任链 / 策略 / 模板方法 等模式,将“查余票→校验→锁座→下单→支付→关单”切分为可插拔步骤,保证后续增加新校验规则或更换实现细节时,业务改动可控、回归成本低。
高并发下的限流与一致性
1. 限流:令牌 + 缓存前置,挡住“无效流量”
- 在“票少人多”的场景,先用缓存侧的 令牌/配额 控制进入核心链路的流量,减少数据库直面洪峰的概率。
- 热点座次 优先:按车次/席别维度配置配额,优先保证热门车次的可用性。
2. 一致性:避免“票丢失 / 超卖”
典型问题与对策:
-
宕机导致的配额“扣了未落库”
- 通过 令牌缓存限流 搭配 “扣减失败延时刷新列车余票真实库存” 修复不一致。
-
数据库超卖
- 底层以 本地锁 + 分布式锁 以及数据库库存设计保证 “最多卖 N 张” 的硬边界。
-
订单超时未支付
- 引入 延时消息(RocketMQ 延时消息队列)自动关单,并 回补名额,避免 “锁而不用” 的资源浪费。
数据层:分库分表与多分片键查询
- 为应对席位与订单数据的持续增长,数据库采用 分库分表。
- 面对多维路由(如 用户ID + 订单ID)下的跨分片查询,使用“多分片键查询优化(基因分片算法和路由缓存)”降低路由开销,尽可能将查询控制在少量目标分片。
目标:有限的跨分片、可控的路由成本、可预期的读写放大。
v2 vs v3:接口侧的能力对比(简版)
| 维度 | v2(本篇主角) | v3(高峰场景更优) |
|---|---|---|
| 适用场景 | 常规流量、日常购票 | 假期/整点开售等极端高并发 |
| 并发模型 | 以缓存前置 + DB 保护为主 | 结合消息队列异步并发控制 |
| 一致性策略 | 标准事务/补偿 + 延时关单 | 同v2 |
| 吞吐/延迟(趋势) | 明显优于 v1,满足常规峰值 | 高峰更稳,尾延迟控制更好 |
结论:压测显示 v2 足以覆盖常规购票;v3 在大促/假期类的“极端峰值”表现更优。
贴近真实的压测:JMeter 动态参数化
静态参数(固定车次/席位)无法还原真实购票过程。我们在 JMeter 中使用 动态参数 组合请求:
-
维度:不同车次、席位类型、全程/半程、用户画像等。
-
方法:
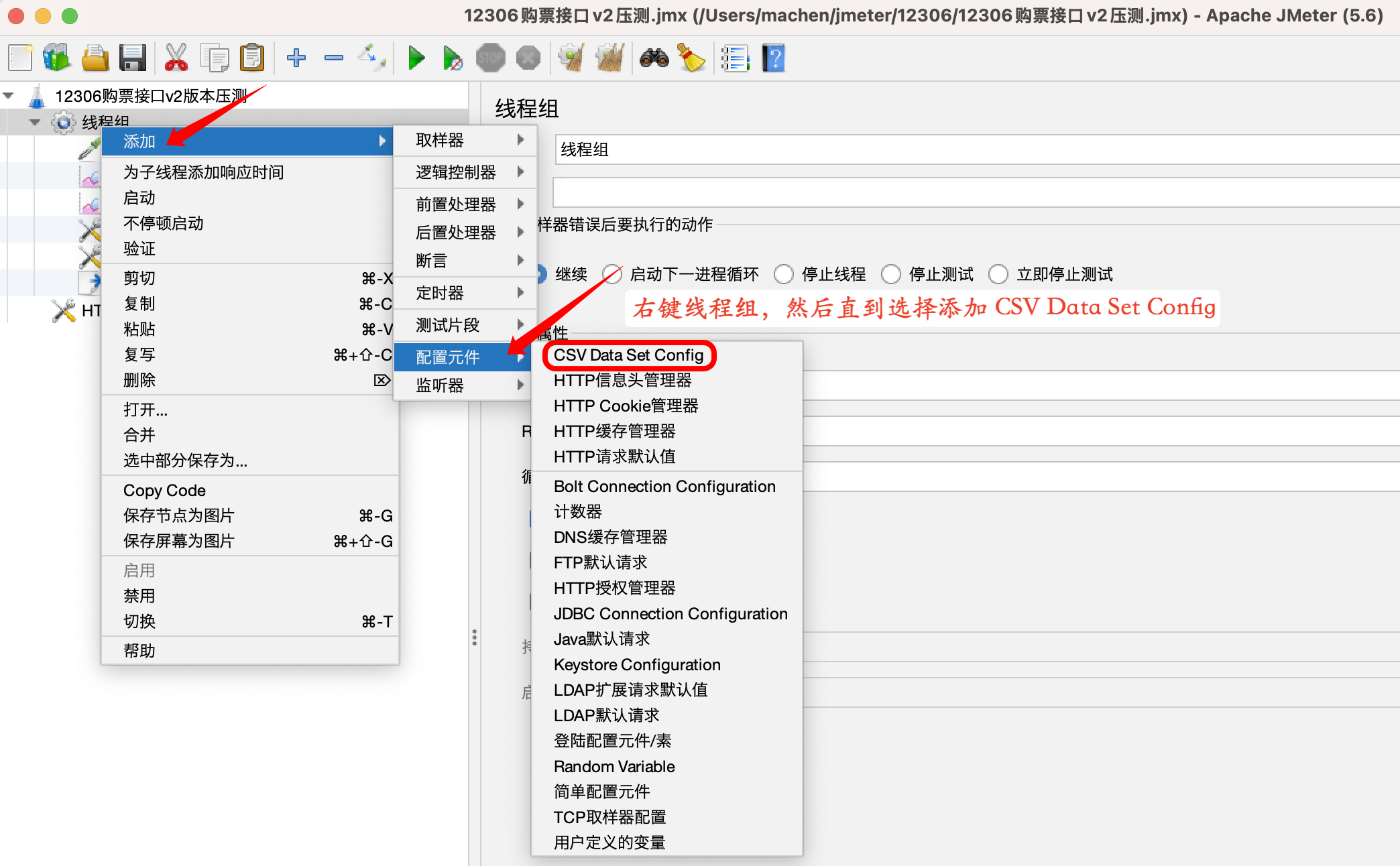
CSV Data Set Config承载候选集合;- 合理设置 思考时间(Think Time) 与 并发爬坡(Ramp-Up)曲线。
CSV Data Set Config:
需要构造动态变化的业务请求,可以通过参数化实现,CSV Data Set Config 是 JMeter 官方提供的配置元件,用于读取 CSV 文件中的数据并将它们拆分为变量。适用于处理大量变量的场景。
一套代码同时支持 Redis 主从 & Cluster
- 现实:Redis 单机可达十万级 QPS,但节假日热点依然需要 Cluster 与更稳的高可用策略。
- 痛点:购票的 Lua 扣减脚本 涉及 多个 Key;在 Cluster 模式下 不支持跨槽访问。
- 解法:使用 哈希标签(Hash Tag) 将相关 Key 放到 同一槽。
一套代码支持多种缓存架构原理
Hash 标签��通过让键名中的一部分参与哈希计算来实现这一目标。Redis 集群通过哈希标签确保多个包含相同哈希标签部分的键会被路由到相同的哈希槽,从而使这些键位于同一个节点。
Redisson 配置示例
clusterServersConfig:
nodeAddresses:
- "redis://127.0.0.1:6379"
- "redis://127.0.0.1:6380"
- "redis://127.0.0.1:6381"
- "redis://127.0.0.1:6382"
- "redis://127.0.0.1:6383"
- "redis://127.0.0.1:6384"
scanInterval: 2000 # Redis 集群状态扫描间隔(毫秒)
readMode: "SLAVE" # 读操作模式,优先从从节点读取(可选 MASTER/MASTER_SLAVE/SLAVE)
subscriptionMode: "SLAVE" # 订阅操作模式,从从节点订阅(可选 MASTER/MASTER_SLAVE/SLAVE)
retryAttempts: 3 # 命令失败重试次数
retryInterval: 1500 # 命令重试间隔(毫秒)
connectTimeout: 10000 # 连接超时时间(毫秒)
timeout: 3000 # 响应超时时间(毫秒)
masterConnectionMinimumIdleSize: 24 # 主节点最小空闲连接数
masterConnectionPoolSize: 64 # 主节点连接池大小
slaveConnectionMinimumIdleSize: 24 # 从节点最小空闲连接数
slaveConnectionPoolSize: 64 # 从节点连接池大小
loadBalancer:
class: "org.redisson.connection.balancer.RoundRobinLoadBalancer" # 负载均衡策略,默认轮询
threads: 16 # Redisson 工作线程数
nettyThreads: 32 # Netty IO 线程数
transportMode: "NIO" # 传输模式(NIO 或 EPOLL)
本次版本优化:修正早期代码中对多 Key 的不兼容点,确保在 Cluster 下稳定运行。
基于 ShardingSphere 实现读写分离
ToC 系统的一条硬规则:高流量接口尽量不直打主库。优先走缓存,其次是读写分离(Read 走从库 / Write 走主库)。
适用场景(三条准绳):
- 读多写少;
- 对 强一致性 要求不高(可接受主从延迟);
- 历史/归档 类查询。
在购票域的落点:订单记录、下单追踪、支付明细等都非常适合读写分离;既减轻主库压力,又提升查询并发。
分库分表后的海量数据运维
ShardingSphere 提供 JDBC / Proxy / 混合 三种形态,开发与运维各取所需。
| 形态 | 主要使用者 | 接入方式/成本 | 代码改造 | 可观测/运维 | 典型场景 | 注意点 |
|---|---|---|---|---|---|---|
| JDBC | 应用开发 | 直接引入依赖,配置规则 | 低 | 依赖应用侧埋点/日志 | 绝大多数日常开发 | SQL 定位库表需额外日志 |
| Proxy | DBA/开发(联调) | 中间代理层,应用连 Proxy | 中 | 透明观察路由与流量 | 排障、审计、热点库表定位 | 需部署与维护代理集群 |
| 混合 | 开发 + DBA | 开发期 JDBC、排障期走 Proxy | 中 | 两者优势叠加 | 开发效率与运维可观测兼得 | 规则一致性需管理 |
经验:
- 开发期以 JDBC 为主,轻量快速;
- 排障/巡检期切换到 Proxy,SQL 无需修改 即可透明观察“去了哪个库/哪张表”。
订单超时:延时关单与回补名额
- 为避免“锁座不支付”长期占用稀缺资源,使用 延时消息 定期扫描与关闭超时订单。
- 关闭后:回补库存/配额,并触发必要的 指标/告警,持续校正配额与真实售卖量。
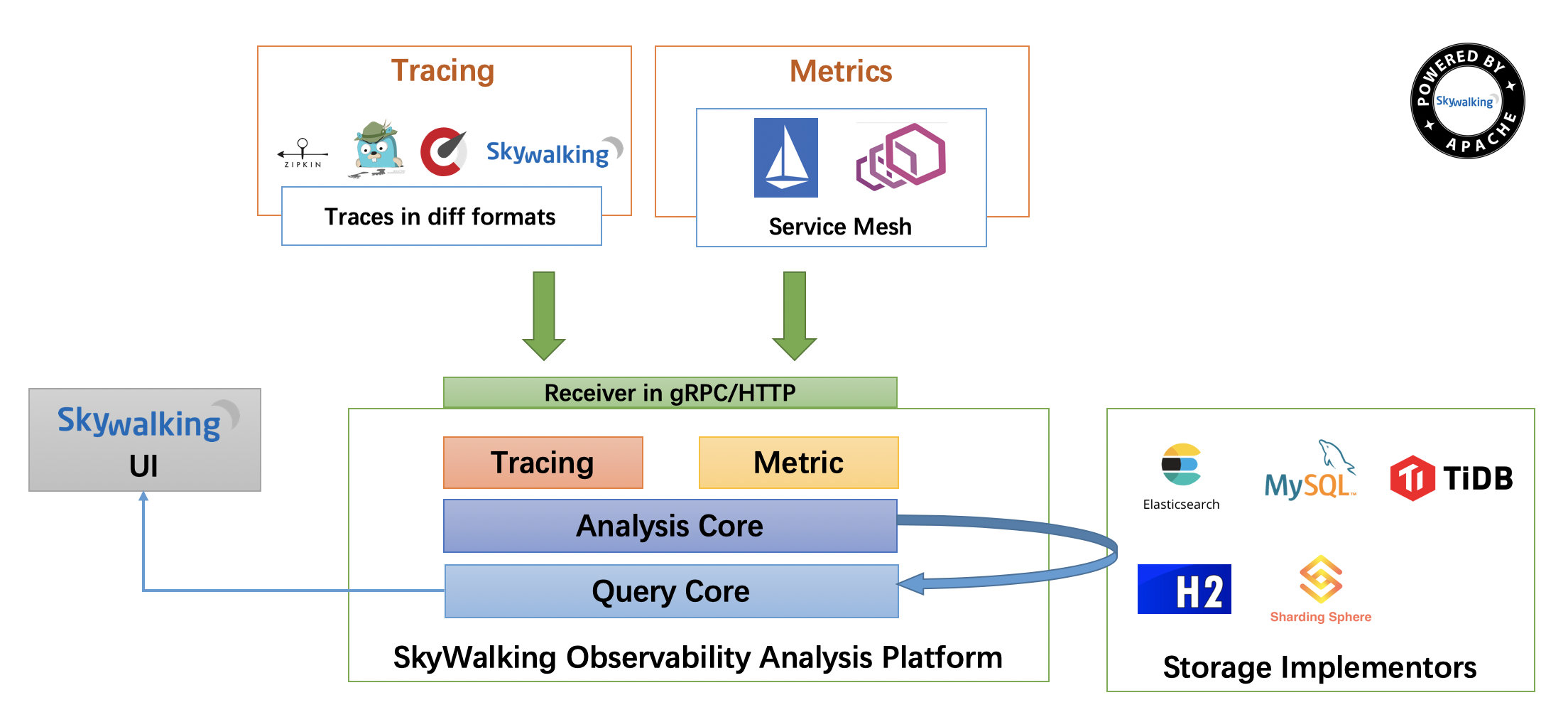
全链路定位:SkyWalking 链路追踪
微服务调用跨越多个服务与中间件,排障关键在于 可视化链路:
-
为什么用它:
- 跨服务出错时,快速定位是哪个服务/哪一步骤;
- 用户反馈“10 秒才返回”,但接口平均 200ms,需要还原真实瓶颈段(如外部依赖、DB、缓存、MQ)。
-
如何接入:在 JVM 启动参数挂载 Agent,基本 零侵入 获取 Trace/Span/指标。
小结
- v2 的定位:面向常规高峰,依赖“缓存前置 + 读写分离 + 分库分表”的三角支撑,配合延时关单与幂等补偿,实现吞吐与一致性的“工程化平衡”。
- 压测方法:一切以 “贴近真实” 为��准绳——动态参数、合理爬坡、热点刻意打压,结论才可信。
- 向 v3 演进:在极端峰值(如节假日整点开售)进一步强化批量化、热点拆分与尾延迟治理,保证“高峰也能稳住”。
只有在 “限流—一致性—观测—压测” 形成闭环后,购票核心链路才能在“票少人多”的现场持续稳态运行。